はじめに
こんにちは、atama plus SREチームの小路です。
この記事は atama plus Advent Calendar 2023 の22日目の記事です。
昨日は弊社QA @ikegagagami の「開発プロセスでPlaywrightを活用して自動化を進めている話」が公開されました。
本記事では、その流れに乗って SREチームで運用している負荷試験を Playwright と k6 で刷新した話 を紹介します。①社内の負荷試験の目的を再整理したこと、②刷新にあたり工夫した点と学び、を主に書いており前日の記事で紹介された Playwright そのものについてはほぼ触れません。
前提
そもそも負荷試験とは
私の以前のイメージでは「大規模なリリースに際してシステム性能が期待通りに発揮されるか確認するテスト」だと思っていました[1]。今回の刷新でさまざまな情報に触れ、一言に「負荷」といっても試験の目的によって多様であることを学びました。いまの atama plus では、そういった異なる性質の試験もまとめて負荷試験と呼んでいます[2]。
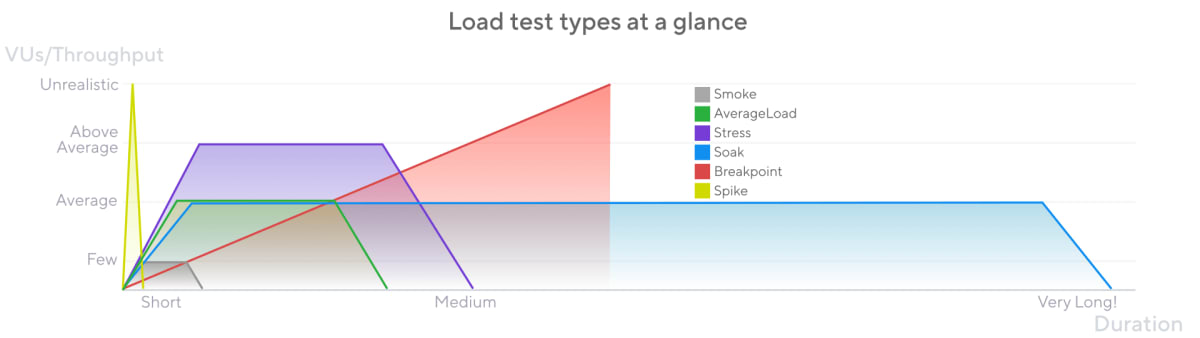
Load test types
k6 の公式ドキュメントにある情報[3]は、今回の刷新を進めるなかで目的を再考するにあたり非常に助けになりました。
atama plus のリリースサイクルと負荷試験の在り方
リリースサイクル
まず、生徒さんの学習を止めないという大前提を達成するため、リリースブランチをチェックアウトしてリリーステストを実施するフェーズがあります。導入いただいているクライアント様などの業務影響を最小限にするため、プロダクトの仕様変更・追加・切り戻しの検討は慎重に行う必要があります。
そのため、機能をまとめてリリースせざるを得なかったり、リリースした内容を切り戻すのが難しかったりすることがあります[4]。「カナリアリリースして本番環境のレイテンシを監視、著しく悪化したら切り戻す」ような運用が難しいのです。
負荷試験の在り方
SREチームでは、このような事業の実態に即して監視・負荷試験を整備しています。
特に負荷試験に絞ると、以下のようなテストを行ってきました。
- ブレークポイントテスト:現構成がユーザー増加をどこまで許容できるか確認
- ストレステスト:DBなどインフラ構成に大規模な変更を加えた際に影響を確認する
- アベレージロードテスト:コード変更によるAPIのレイテンシ変化を定常的に確認する
定期的な負荷試験実行
この3点目のアベレージロードテストについてさらに詳しく解説します。
主な流れは以下で、これを毎日定時に自動実行していました。
- 変更の加わったコードを試験用サーバー環境にデプロイ
- 負荷をかける側の環境をAWS CDKで自動構築
- Locust のシナリオを動かしてサーバーのAPIのエンドポイントに対して負荷がけ
- 主要なAPIのレイテンシが悪化していないかを確認
社内で主に使われる Python でコーディングができるという理由で Locust を利用していました。SREチームがテストシナリオコードのメンテナです。
今回やったこと
これまでの運用上の課題
上記のように負荷試験を運用していましたが、以下のような課題感が顕在化しました。
SREチームが運用にリソースを割けず、生徒さんの重要な体験である学習に関する部分だけ、最低限の負荷試験に留まっていました。一方でプロダクトの進化は早く、生徒さんの学習に関連する箇所ですら、新たな学習方式の追加や教科の拡充などに十分に追従できていませんでした。
課題への対応: Playwright x k6
冒頭述べたように、QA チームが Playwright の導入を圧倒的なスピードで遂行し、シナリオを拡充していました。この社内の Playwright の波に乗ること、負荷がけに k6 を用いることなどで「もろもろ解決できるのでは?」となり刷新に動きました。
いくつか、思案したポイントをまとめます。
【対応1.】 負荷試験ツールの再選定
まずは運用にかかる工数やインフラの費用、周辺ライブラリの充実度など様々な観点のもと、もともと使用していた Locust も含めて比較検討しました。(比較軸みたいなものはウェブ上にたくさんあるので割愛)
各ツールに特徴があるなか、性能よく[5]CIにそのまま乗せられるゆえ課題であったインフラのコスト・保守性が改善する k6 を選定しました。あとは単純に、比較的新しく勢いのありそうな(※ 個人の感想です)ものを使いたかったのもある...
【対応2.】 負荷シナリオコードを Playwright から自動生成
2-1. Playwright (HAR) からシナリオコードへ変換
Playwright のテストシナリオ実行するとき、その記録として HAR ファイルを作成できます。この HAR を負荷試験のシナリオ作成に使います。
こちらを非常に参考にさせてもらいました。というか、この事例を見たから Playwright に乗っかる発想に至った、が正確な表現です。感謝です。
k6 / Locust ともに HAR ファイルからシナリオコードへ変換を行うOSSライブラリが提供されています。ただ、結果的にこの変換は自前実装で行うことになりました(後述)
2-2. レスポンスに依存したシナリオ作成:Jinja での解決
あるリクエストに対して返却されたレスポンスのデータを用いて、次のリクエストのデータを構成するのはよくある流れです。このレスポンスデータがリクエスト毎に変化し再利用できない値だと、Playwright で生成される HAR ファイルのデータは、そのままではシナリオ再現できないものになってしまいます[6]。
ログインのセッション保持など一部は k6 のライブラリで対応できますが、プロダクトでは同じような処理を行うものの対応できない箇所が複数ありました。公式の har-to-k6 でも調査時には未対応でした。
そのような箇所に対応するため、Jinja のテンプレートエンジンを挟んで k6 シナリオ(JavaScript)コードに変換するようにしました。私ではなく SRE チームの同僚が一瞬でやってくれました。
なお、私は同じ処理をやるのに大量の sed コマンドで苦し紛れに文字列置換を試みたことをここに懺悔しておきます。
結果
よかったこと
テストシナリオのコード、負荷試験環境のインフラともにメンテナンスがしやすい形になりました 🎉
やってみての気づき
E2E テストと負荷テストの目的の違いについて、十分に考慮できていなかったのは反省点でした。E2E では、例えば "暗記すべき項目を定着させる" 学習シナリオについて、近しい学習体験の構造からなる「日本史」と「世界史」で区別する必要はありません。
別の例を挙げると、弊社プロダクトの多くの教科に存在する "講義動画を観る → 講義のまとめ問題を解く" というシナリオについて、E2E テストではどれか一教科で確認できれば目的を達成できています。
「日本史」「世界史」の区別や、ある学習形式に対する教科の差分について、いい意味で関心がないのです。
これに対して負荷試験では、以下のようなことを考慮して教科による違いをテストしたいことがあります。
- 裏で異なるアルゴリズムが動いている(In/Out はユニット or 統合テストで保証される)
- DB のレコード数や静的ファイルのサイズなどの多寡でパフォーマンスが変化する
これらは性能の変化をモニタリングしたいがゆえに生じる観点であり、E2E には不要なはずのシナリオを必要とします。負荷試験のシナリオ運用は、楽をすることができても完全に逃れることはできないかもしれないですね。
これから
- 上述した「テストの目的の違い」によるシナリオの差分を埋める
- 従来の「生徒さんの学習シナリオ」を超え Playwright ベースの負荷試験シナリオを広げる
この辺りを進めていきたいと考えています。QA でも Playwright のシナリオ拡充、開発プロセスへの組み込みに動いているので、連携して E2E テスト・負荷テストそれぞれの改善を目指していきます。
まとめ
目的に応じた負荷試験について再定義して、そのメンテナンスをSREを超えたチームで進められるようにしました。
Playwirght の果たすテスト目的との違いにより、完全にメンテナンスフリーな状態にはまだできていません。一方で、品質を高めていくという大きな目的のもとに、E2E / 負荷テストを両方とも発展させられるよう同じ方向を向けたのはよかったと思います。
明日は、@pandineer の「自動テストを充実させるためにやったこと」です。お楽しみに 🐼
-
先日の FFXIV の公開負荷テスト みたいなイメージ ↩︎
-
ISTQBテスト技術者資格制度 Foundation Level Specialist シラバス 性能テスト担当者 日本語版 Version 2018.J01にもこのあたりの定義が整理されています ↩︎
-
仮説検証を効果的に行うため、atama plus には小さく頻度高いリリースを志す価値観があり、現在進行形でも最適なリリースの形を模索していることも補足しておきます。 ↩︎
-
少し古く、ポジショントーク感も拭えないですが... Open source load testing tool review 2020 ↩︎

Discussion