はじめに
社内のデータ利活用を推進するため、Streamlit を用いたデータアプリケーションを簡単にデプロイできる環境を Cloud Run で実現しました。
自由度とセキュリティを両立するため、Platform 設計・実装面で工夫した点について紹介します。
※ Streamlit を単純構成でデプロイする問題点については、以下の記事にわかりやすく記載されているのでこちらもご参照ください。
こんな人向け
- 複数人で利用する Streamlit 環境を作って組織内のデータ利活用を推進したい方
- 許可された人だけがアクセスできるデータアプリケーションをセキュアに公開したい方
全体構成
最初に構築した Platform の全体像をお見せします。
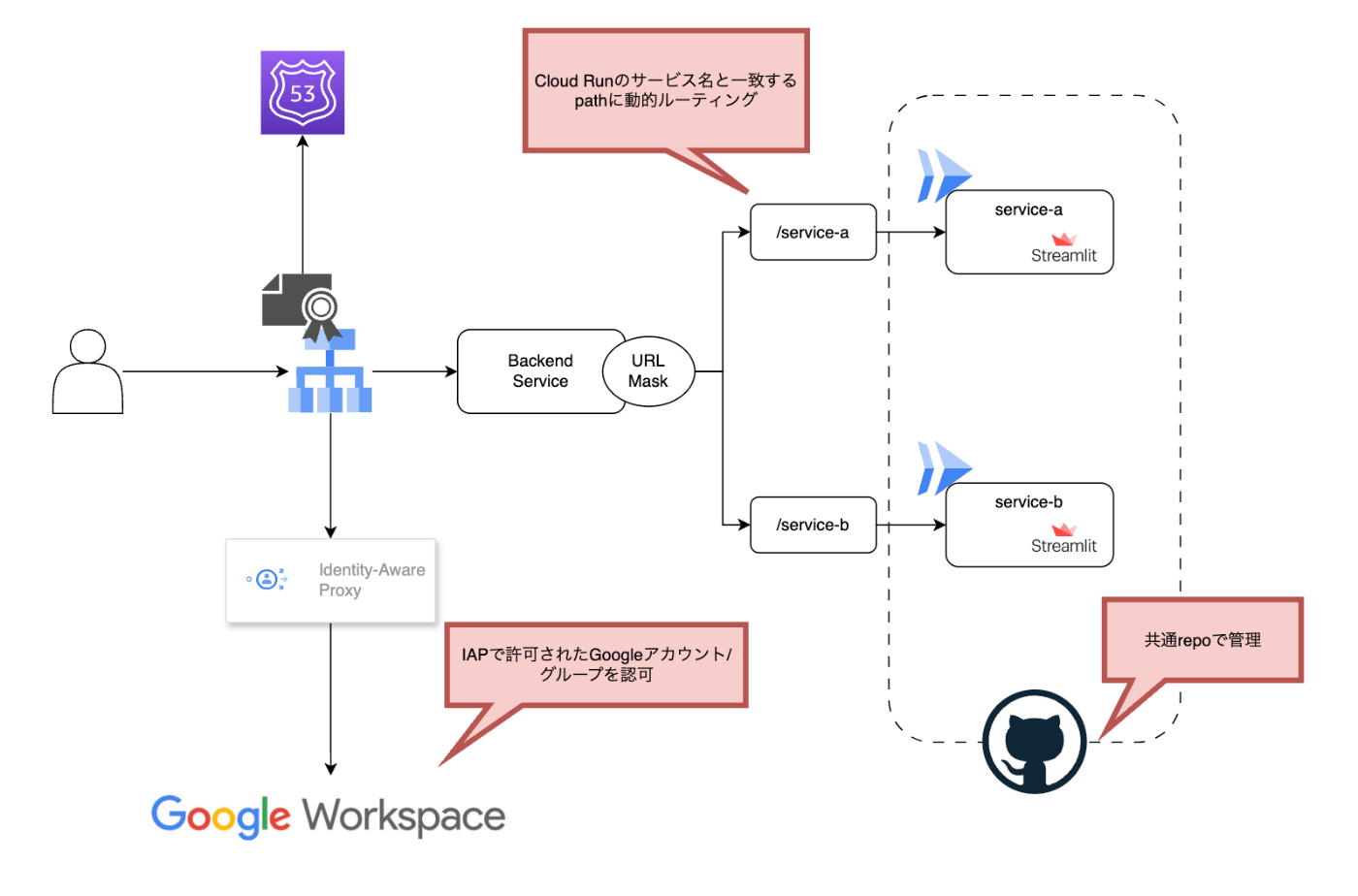
個別の特徴・工夫点について以下で解説していきます。
Platform の実装ポイント
Cloud Run での実行環境
Streamlit で実装されたアプリケーションはコンテナ化され、Cloud Run にデプロイされます。
Cloud Run では許可されたネットワーク、今回の場合だと LoadBalancer 経由のトラフィックのみを許可するよう、Ingress Controlを Internal and Cloud Load Balancing に設定します。
gcloud run deploy << service-a >> \
--region "us-central1" \
--platform managed \
--ingress internal-and-cloud-load-balancing \
--source .
また、Streamlit はデフォルトではドメイン直下へのアクセスを受け付ける構成となっています。
しかし、今回は単一ドメインの下で後述する URL Mask を用いて個別の Service ごとに Path ベースのルーティングを実行したいため、Streamlit に Request Path と同じ Path で応答するように設定する必要がありました。
具体的には、 .streamlit/config.toml に以下を記述します。
[server]
baseUrlPath = "/service-a"
これにより、ローカルでは http://0.0.0.0:8080/service-a 、デプロイ環境では https://DOMAIN_NAME/service-name で Streamlit アプリケーションにアクセスできるようになります。
LoadBalancer を用いた各 Service へのルーティング
Cloud Run へのアクセスはCloud Load Balancingを用いて、単一のドメインで複数の Service パスにルーティングできるよう構成しました。
ここで、各実装者が Service 追加ごとに新しい Path ルールを設定しないといけないのは煩雑です。
そこで Serverless NEG のURL masksという機能を利用します。
ドキュメントを参照すると
サービスごとに個別のサーバーレス NEG バックエンドを作成する代わりに、カスタム ドメイン(例:
example.com/service)用の汎用 URL マスクで単一のサーバーレス NEG を作成し、NEG がリクエストの URL からサービス名を抽出できるようにします。
と記載されており、要するに URL masks を設定することで、Cloud Run の Service 名へのルーティングを Cloud Load Balancing がよしなに行ってくれます。
なので、利用者は Cloud Load Balancing にアタッチされるように Cloud Run の Service をデプロイすることで、その Service 名での Path ベースルーティングが自動で行われるようになります。
IAP/Google 認証
Streamlit アプリケーションへのアクセス制御に、Google Cloud の機能であるIdentity-Aware Proxy(以下:IAP)を利用しました。
IAP を利用することで、アプリケーションにアクセスするユーザーの認証を強化し、許可された Google アカウントを持つユーザーのみがアクセスするように制御することができます。
Cloud Load Balancer + IAP の設定方法については詳細に手順を公開してくれている記事があるので、そちらをご参照ください。
ここでは、社内向けのデータアプリケーションが不用意に外部公開されないよう、IAP を用いた認証を実現していることだけ触れておきます。
Platform 利用者向けの工夫ポイント
リポジトリ構成
Streamlit を用いたデータアプリケーションのコード管理は単一のリポジトリで行うように構成しています。
リポジトリの下に、サンプルディレクトリを作成し、各実装者はサンプルディレクトリを参考にしながら自身のアプリケーションを実装していけるように構成しています。
リポジトリ内の構成は以下のようになっています。
.
├── README.md
├── .circleci
│ ├── config.yml
│ └── continue_config.yml
└── workspace-sample
├── .streamlit
│ └── config.toml
├── .python-version
├── Procfile
├── main.py
└── requirements.in
ここで、 workspace-sample ディレクトリをコピーして自身の実装ディレクトリを作成し、Streamlit アプリケーションを実装していきます。
Streamlit 実装
.streamlit/config.toml には、前述したようにアプリケーションが応答する Path を指定します。Serverless NEG の URL masks が反応するように、ここは Cloud Run の Service 名と一致する必要があります。
Procfile には Buildpacksを利用してコンテナイメージの作成に必要な設定を記述します。
Buildpacks を用いてコンテナ定義を記述する場合、Dockerfile の記述は不要で、今回のようなシンプルな Python アプリケーションであれば、Buildpacks が自動で Python のイメージを選択し、requirements.txt から依存ライブラリを解決し、Procfile を読んでアプリケーションの起動方法を判別します。
Procfileには以下のように Streamlit の起動コマンドを記述しておきます。
web: streamlit run main.py --server.port ${PORT:-8080}
Service ごとの CI/CD
単一リポジトリ内の複数サービス(例えば service-aとservice-b)の実装者は基本的に異なるケースが多いです。
各サービスを好きな人が好きにデプロイできる基盤を作っているためです。
しかし、そうすると service-a を更新してデプロイしたいだけなのに、全てのサービスに対して単一の CI/CD を実装すると、 service-b までデプロイされてしまい、意図しない事故を誘発してしまう恐れがあります。
そこで、CircleCI のDynamic Configを用いて各サービス単体でのデプロイを可能にします。
まず CircleCI の基本設定として、Dynamic Config の Path Filtering を用いて、リポジトリ内のサブディレクトリ内における変更をトリガーに workflow がキックされる構成とします。
version: 2.1
setup: true
orbs:
path-filtering: circleci/path-filtering@1.0.0
workflows:
always-run:
jobs:
- path-filtering/filter:
name: check-updated-files
# サブディレクトリ内の変更をキャッチしてパラメータを変更
mapping: |
service-a/.* run-service-a true
service-b/.* run-service-b true
base-revision: main
config-path: .circleci/continue_config.yml
filters:
branches:
only: main
ここでは、 service-a/.* において変更があった場合は run-service-a というパラメータを true にする、ということが設定され、その設定の元で .circleci/continue_config.yml の定義を実行するように記述しています。
具体的なデプロイコマンドは .circleci/continue_config.yml 内に記述します。
version: 2.1
# サブディレクトリ内の変更によりトリガーされるパラメータを設定
parameters:
run-service-a:
type: boolean
default: false
run-service-b:
type: boolean
default: false
executors:
cloud-sdk:
docker:
- image: google/cloud-sdk:latest
jobs:
deploy-service:
executor: cloud-sdk
parameters:
service-name:
type: string
memory:
# https://cloud.google.com/sdk/gcloud/reference/run/deploy#--memory
type: string
default: "2Gi"
cpu:
# https://cloud.google.com/sdk/gcloud/reference/run/deploy#--cpu
# Cloud Run (fully managed) supports values 1, 2 and 4.
# For Cloud Run (fully managed), 4 cpus also requires a minimum 2Gi --memory value. Examples 2, 2.0, 2000m
type: string
default: "1"
steps:
- checkout
# デプロイのため、Google Cloud SDKの設定を初期化
- run:
name: Init Google Cloud SDK
command: |
echo $GCLOUD_SERVICE_KEY | gcloud auth activate-service-account --key-file=-
gcloud --quiet config set project ${GOOGLE_PROJECT_ID}
# Cloud Runのデプロイコマンド
# 基本的に上述したingress設定を含むコマンドに、リソースパラメータなどを追加
- run:
name: Deploy to Cloud Run
command: |
cd << parameters.service-name >>
gcloud run deploy << parameters.service-name >> \
--region "us-central1" \
--project ${GOOGLE_PROJECT_ID} \
--platform managed \
--ingress internal-and-cloud-load-balancing \
--memory << parameters.memory >> \
--cpu << parameters.cpu >> \
--service-account <SERVICE_ACCOUNT_NAME> \
--source .
# IAPの設定コマンド
# IAP経由での認証をトリガーにCloud Runサービスをinvokeする許可設定を入れる
- run:
name: Add INvoke Role to IAP
command: |
gcloud run services add-iam-policy-binding << parameters.service-name >> \
--member=<IAP_SERVICE_ACCOUNT_NAME> \
--role="roles/run.invoker" \
--platform managed \
--region="us-central1" \
--project=${GOOGLE_PROJECT_ID}
# サービスごとのWorkflow設定
# path filteringでparmeterがtrueになっているworkflowだけが実行される
workflows:
deploy-service-a:
when: << pipeline.parameters.run-service-a >>
jobs:
- deploy-service:
context: gcp-internal-dashboard-deploy
service-name: service-a
deploy-service-b:
when: << pipeline.parameters.run-service-b >>
jobs:
- deploy-service:
context: gcp-internal-dashboard-deploy
service-name: service-b
# 必要に応じてCloud Runのリソースを個別に設定する
memory: "32Gi"
cpu: "8"
ここの処理についてはインラインコメントで記載しましたが、大まかな流れとしては
- path filtering によってサブディレクトリ内の変更を検知
- 変更されたサブディレクトリに対応するパラメータを
trueに設定 - パラメータが
trueになっている workflow が実行され、共通化された deploy job をキックする - deploy job の中で、Cloud Run のデプロイ、Cloud Load Balancing への紐付け、IAP の許可を自動で行う
というものになっておりますが、実装者は細かいことを気にせず、サンプルの CI 定義を追記すればレギュレーションに則って Streamlit アプリケーションを安全にデプロイできるようになっています。
社内での利用例
では、この Platform を用いてどのようなデータアプリケーションが展開されているのか、事例を紹介したいと思います。
機能リリース後の利用状況のモニタリング
プロダクト開発において、リリースした機能がどれくらい使われているか、正しく使われているかのモニタリングは重要な要素です。
シンプルなモニタリングであれば Google Analytics やデータベースのレコードのモニタリングでもいいかもしれませんが、少し複雑なモニタリングになると、なんらかのダッシュボードがあると便利なケースもあり、そういった用途で気軽に利用してもらえるようになっています。
これにより、プロダクト開発の継続的な改善サイクルを支援していくことを狙っています。
ユーザーの N1 情報に Dive Deep するアプリケーション
ユーザーがどのようにプロダクトを利用しているかは、全体傾向だけでなく、個々のユーザーの利用状況を深く知ることが有用なケースも多くあります。
その際に毎回クエリを作成して実行するのは効率的ではないので、汎用的にユーザーごとの詳細な利用データを取得できるようなデータアプリケーションを社内向けに提供しています。
データ基盤の利用情報をモニタリング
社内でのデータ基盤の利用状況を把握できるモニタリングアプリケーションを開発しています。データ基盤として、データウェアハウスやデータマートなど、多数のテーブルを作成してデータ利用者が簡単にクエリを実行できる環境を提供しています。
利用頻度が低いテーブルはメンテナンスコストを節約するために削除を検討し、非効率なクエリが継続的に実行されている場合は、テーブルチューニングやクエリチューニングを支援して、効率的なデータ管理を推進しています。
さいごに
社内のデータ利活用を推進するため、Streamlit を用いたデータアプリケーションを簡単にデプロイできる環境を Cloud Run で実現した話について、技術的に工夫した点を記載しました。
データを用いて教育サービスを開発していきたい方を募集中です!興味がある方はご連絡いただけると嬉しいです!

Discussion