こんにちは、inadyです。
atama+では2022年の夏から2023年の春にかけて、Herokuで稼働しているアプリケーションをAWSに移行するプロジェクトを実施しました。
その中で、「Heroku SchedulerをどうやってAWSへ移行するか?」ということが課題の1つでした。
Heroku Schedulerの移行はうまくいき、移行してから1年ほど経ちますが、課題なく安定して稼働しています。
この記事は、AWSでどのようにHeroku Schedulerの代わりを構築したのか、その設計や、途中の試行錯誤をまとめたものです。
Heroku移行の背景
atama+ではこれまでHerokuを使ってアプリケーションを運用してきました。
しかし、Herokuは年間契約であるためコスト管理が難しいこと、事業の成長とともにインフラに対する要望が増加しており、より柔軟なインフラを構築できる環境を求めていました。
そこで、SREチームは全てのアプリケーションをAWSに移行することにしました。
Heroku移行全体の話は、AWSお客様事例の記事 atama plus、主要アプリケーションの環境を AWS へ移行 コストを 4 割削減するとともに、開発や運用に関する生産性の向上も実現に書かれています。
ご興味があれば、合わせてご覧ください。
Heroku Schedulerとは?
まず、Heroku Schedulerが何かを簡単に説明します。
Heroku Schedulerは、Heroku上で定期的に実行するタスク(バッチジョブ)を簡単に管理するためのツールです。
UIを使って、任意のcronスケジュール、コマンド、インスタンスサイズを設定するだけで、バッチジョブを登録できます。
Heroku Schedulerの大きなメリットは、その使いやすさとシンプルさにあります。
エンジニアが細かい設定をすることなく、直感的にバッチジョブを管理できるため、スタートアップや小規模なチームにとっては大変便利なツールです。
AWSへ移行するうえでのハードルは?
AWSではHeroku Schedulerの機能を完全にカバーするようなサービスはありません。
具体的には、簡単にバッチの設定ができて、cron・コマンド・インスタンスサイズを設定できるものが欲しいということです。
さらに追加の要件として、2つありました。
- バッチの実行時間が想定より長くかかっている場合はSlackに通知したい
- 再実行で解消する可能性がある場合はバッチをリトライをしたい
アーキテクチャを考える
ここからは、要件を満たすためにどのような設計を考えていったかを解説します。
バッチの登録
まずは「簡単にバッチの設定ができて、cron・コマンド・インスタンスサイズを設定できるもの」を実装していきます。
「簡単に設定ができ」の部分として、まずSRE(インフラ)チームにてバッチに必要なリソースをTerraformでmoduleとして定義します。バッチごとの設定は、設定ファイルとして書くだけでインフラが構築されるようにしました。
そして、アプリケーションエンジニアは、バッチの設定ファイルだけをメンテナンスします。
こうすることで、アプリケーションエンジニアが詳細なバッチ基盤の実装を知らなくても、任意のバッチを簡単に追加できます。
具体的には次のように記述します。
"batch01" = {
is_enabled = true
command = "python manage.py batch01"
schedule = "cron(0 21 * * ? *)"
ecs_task_size = "2CPU-4GMem"
estimated_max_execution_time_minutes = 30
}
"batch02" = {
is_enabled = true
command = "python manage.py batch02"
schedule = "cron(0 9 * * ? *)"
ecs_task_size = "4CPU-8GMem"
estimated_max_execution_time_minutes = 120
}
裏側ではCI/CD環境を構築しており、バッチの設定を書いてもらってGitHubにpushすると、自動的にAWS環境にデプロイされます。
基本的なインフラ構成
続いて、AWSインフラ部分の設計にうつります。設計の初期段階として、まずはシンプルなインフラ構成を考えてみました。
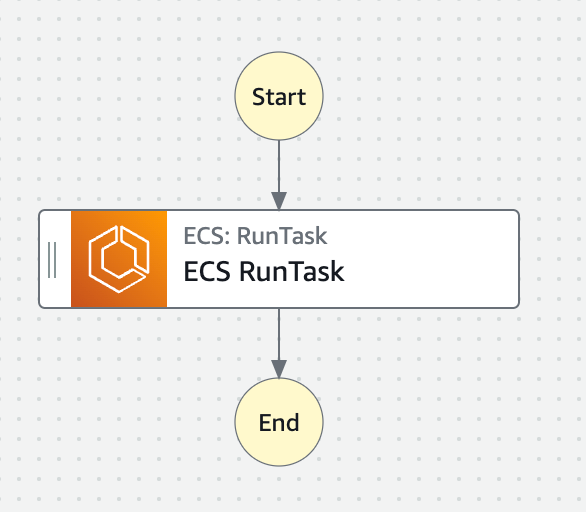
commandの渡し方
ワークフロー全体の管理にStep Functions(SFn)を利用し、そこでECS RunTaskを実行します。
その際、ECS RunTaskのContainerOverrides(ECSタスク定義を一部上書きする機能)で、 ECSタスク定義のデフォルトのcommandを設定ファイル(tasks.tfvars)のcommandで上書きしています。
タスクサイズの渡し方
ECSタスクのサイズ(CPU/メモリ)は設定ファイル(tasks.tfvars)のecs_task_sizeで指定しています。
裏側では2CPU-4GMemや4CPU-8GMemなど、いくつかのパターンで事前にECSタスク定義を作成しておきます。
そして、タスク定義名をscheduled-task-2CPU-4GMemやscheduled-task-4CPU-8GMemなどとしておきます。
あとは、ECS RunTaskを実行する際に、設定ファイル(tasks.tfvars)のecs_task_sizeをそのままタスク定義名のsuffixにすればタスクサイズをコントロールできます。
具体的には、Terraformで次のように定義しています。
task_definition_family = "scheduled-task-${var.ecs_task_size}"
別の方法としては、TaskOverrideを使い、ECS RunTask実行時にCPUやメモリの割当量を動的に設定するという設計も考えられます。
ただし、その場合はサイドカーコンテナに割り当てるCPUやメモリ量を計算するロジックをあいだに入れる必要があり、構成がやや複雑になるので採用しませんでした。
cronの実行方法
最後に、SFnをどうやって設定ファイル(tasks.tfvars)のscheduleで定義した間隔で実行するかですが、これはAmazon EventBridgeを利用しています。
TerraformのEventBridgeの定義部分で、scheduleに書いてあるcronを参照して構築します。
これで、基本的な部分の設計は完了です。
いくつか工夫は必要でしたが、とくに困ったことはありませんでした。
バッチの終了時間監視
基本的な設計が完了したので、次に「バッチの終了時間監視」の設計に移ります。
いくつかボツになった案があるので、紹介します。
【ボツ】TimeoutSecondsで実現する
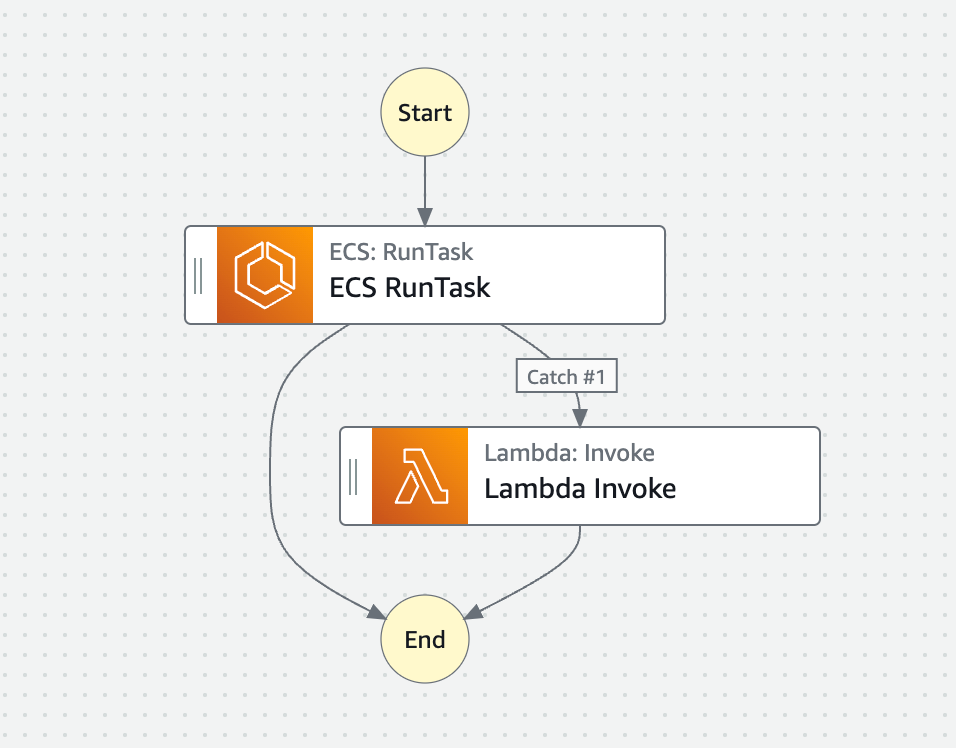
SFnではTimeoutSeconds を設定できます。
指定した時間を過ぎると、タスクをStates.Timeoutというステータスにして、次のステップに流すことができるので、この機能を使ってみることとしました。
設定ファイル(tasks.tfvars)のestimated_max_execution_time_minutesをTimeoutSecondsに設定します。
設定した時間が過ぎ、つまり期待したバッチの終了時間を超えたらStates.Timeoutが発生し、それをLambdaでキャッチして、Slackに「バッチがまだ終わっていないこと」を通知します。
しかしながら、この案はボツになりました。
States.Timeoutが発生しても、ECS Task(バッチ)はまだ実行中です。
一方でSFnのほうは、States.Timeoutが発生した時点で、Lambdaが実行され、そのあと「完了」のステータスになります。
つまり、SFnの実行結果画面を見ただけでは、バッチが終了しているのか? まだ実行中なのか? がわからないということです。
運用上たいへん不便なので、この案はボツになりました。
【ボツ】バッチが完了するまでループして待つ
次に、SFnの実行時間とECS Taskの実行時間を一致させる方法を考えました。
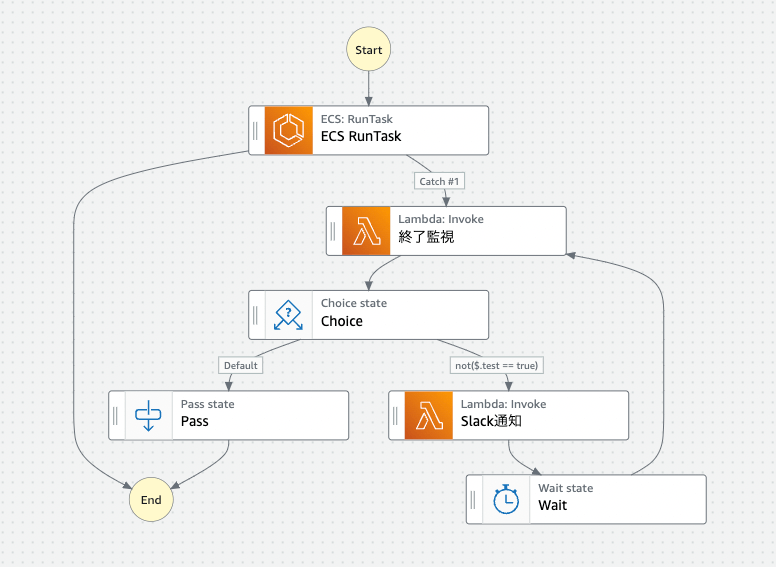
States.Timeoutが発生したら、Lambdaでキャッチして、Slackにバッチがまだ終わっていないことを通知します。
その後、ループに入ります。ループの中でECS Taskのステータスを確認し、まだ終了していなかったらWaitで60秒待ちます。このステータス確認とWaitのループを繰り返します。
もし、ECS Taskが終了していたら、ループを抜けてSFnを終了させるという案でした。
しかし、この案もボツになりました。理由はいくつかあります。
ECS Taskが終了していることをLambdaから確認するには、ECS TaskのIDが必要です。
しかし、SFnの仕様で、Lambdaの引数にECS TaskのIDを渡すことができませんでした。
また、Workflow全体が複雑になるというデメリットもありました。
【採用】監視を別のSFnに分ける
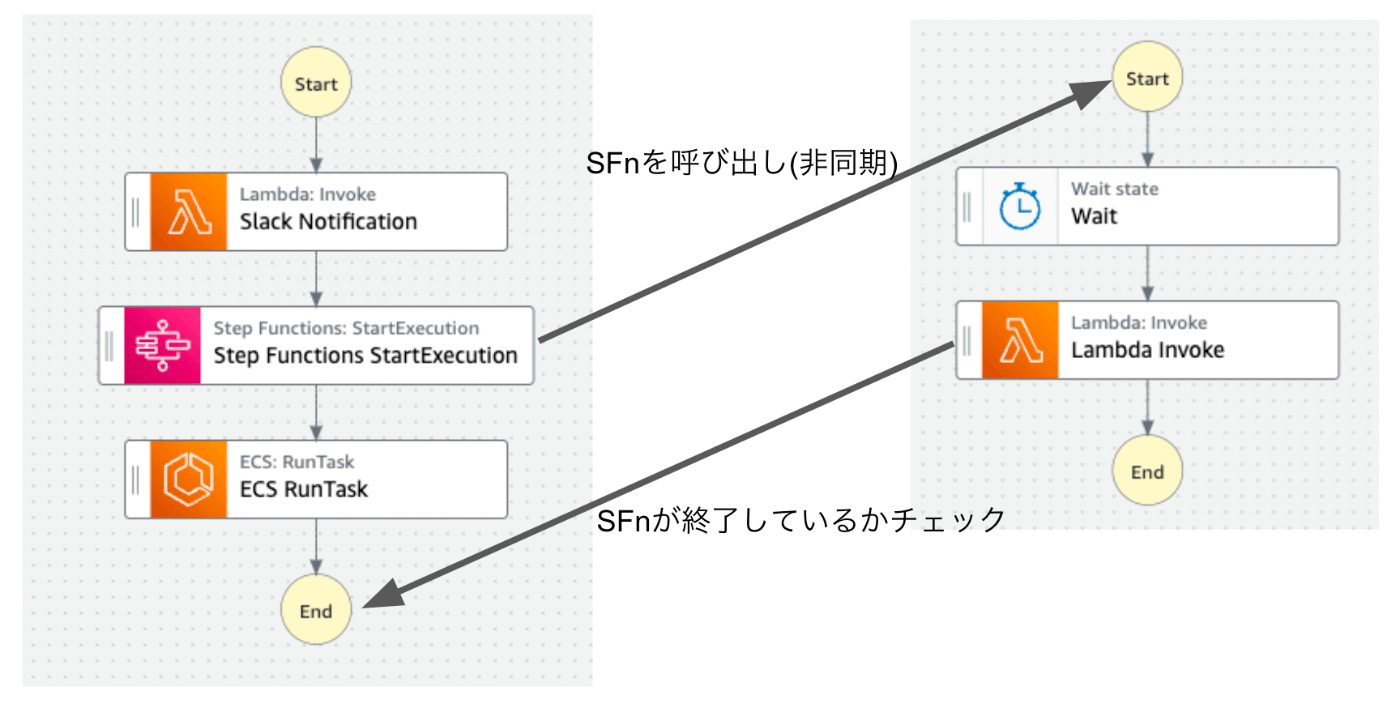
最終的に採用したのは、終了時間の監視を別のSFnに分けるという案でした。
まずは、TimeoutSecondsの採用をやめました。そうすることで、SFnの終了時間とECS Task(バッチ)の終了時間が一致します。
SFnの実行結果画面を見ただけで、バッチが終了しているか確認できるようになります。
ECS RunTaskを実行する前に、監視用の別のSFnを非同期で呼び出します。
呼び出しの引数に、バッチのSFnの実行IDと設定ファイル(tasks.tfvars)のestimated_max_execution_time_minutesを渡します。
監視用SFnは、バッチが終了していてほしい時間だけWaitして、Lambdaを実行します。
LambdaはバッチのSFnのIDを使って、SFnが終了しているかをチェックします。
そして終了していなかったら、Slackに通知するような実装になっています。

この設計のメリットは次のとおりです。
監視用SFnでは長時間Waitします。長いものだと4時間ほどWaitしています。
しかし、SFnでは何時間Waitしても、いっさいお金がかかりません。
1つ前の「ループして待つ」実装と違い、Lambdaを何度も実行する必要もありません。
また、Workflowが非常にシンプルです。どちらのSFnも分岐がなく、非常にわかりやすいフローになっています。
監視用SFnは汎用的なWorkflowになっているので、他のバッチの実行時間監視でも同じSFnを利用できます。
リトライ処理
この設計でしばらく稼働していたのですが、たまにバッチが失敗するという事象が発生していました。
バッチ失敗を検知したら、エラー内容を確認して、手動で再実行するという運用を実施していましたが、これを自動化することにしました。
実装は次のようになっています。

まず「InitRetryCounter」で$.RetryCounterという変数を定義し、値は0にします。
「ECS RunTask」でStates.TaskFailedが発生したら、ResultPathに$.ErrorInfoを詰めて「Cause to Json」でキャッチします。
「Cause to Json」の中身は次のようになっており、inputを整理して次に流す役割を担っています。
{
"Cause.$": "States.StringToJson($.ErrorInfo.Cause)",
"RetryCounter.$": "$.RetryCounter"
}
「Retry or Finish」では、ECS Taskをリトライするか、終了するかを分岐しています。
条件分岐は、優先度順に次のようになっています。
-
RetryCounterが3以上だったらFail -
Causeが"CannotPullContainerError: context deadline exceeded"だったらRetry -
Causeが"Capacity is unavailable at this time"だったらRetry -
CauseがTimeout waiting for EphemeralStorage provisioning to completeだったらRetry - それ以外はFail
ECSでよく発生し、再実行すれば解消できる可能性があるエラーをキャッチしてリトライするようにしています。
しかしながら、3回以上失敗した場合や、それ以外のエラーの場合はリトライしないようにしています。
最後に「Retry」ですが、RetryCounterに1を足して、「ECS RunTask」に遷移するように設定しています。
{
"RetryCounter.$": "States.MathAdd($.RetryCounter, 1)"
}
このリトライ処理を導入したことで、手動でバッチを再実行することはほぼなくなりました。
現在のところ、この設計に落ち着いています。
感想
Heroku SchedulerからAWSへの移行プロジェクトは、バッチジョブの管理と監視、リトライ処理の自動化など、多くの課題をクリアしながら進めていきました。
この移行によって、より柔軟で拡張性の高いインフラ環境が整い、今後の事業成長に対応できる基盤を構築できたと考えています。
AWSでHeroku Scheduler相当のものを実現するには、色々なAWSサービスを組み合わせて設計する必要がありました。
(もちろん、AWSでもより簡単な設計でバッチジョブ環境を構築可能ですが、拡張性や運用の容易さなどを考慮すると、どうしても複雑になっていきます)
Heroku Schedulerはたいへん便利なサービスだったのだと改めて感じました。
今までatama+のバッチジョブを支えてくれたHeroku Schedulerに感謝!

Discussion