はじめに
Model Context Protocol (MCP) は、AIモデルとユーザーのデータソースを安全に接続するための規格です。
この記事では、MCP Serverの実装を通じて学んだ、MCPの技術概要や通信の仕様について解釈してみます。
MCPの技術的概要と通信インターフェース
MCPとは何か
Model Context Protocol (MCP) は、AIアシスタントと外部データソース・ツールを接続するための標準プロトコルです[1]。
ClaudeやCursorなどのAIアシスタントが、ユーザーの許可したデータにアクセスできるようにする橋渡し役を担います。
Core Architecture
MCPはClient-Serverモデルのアーキテクチャに準拠しています[2]。
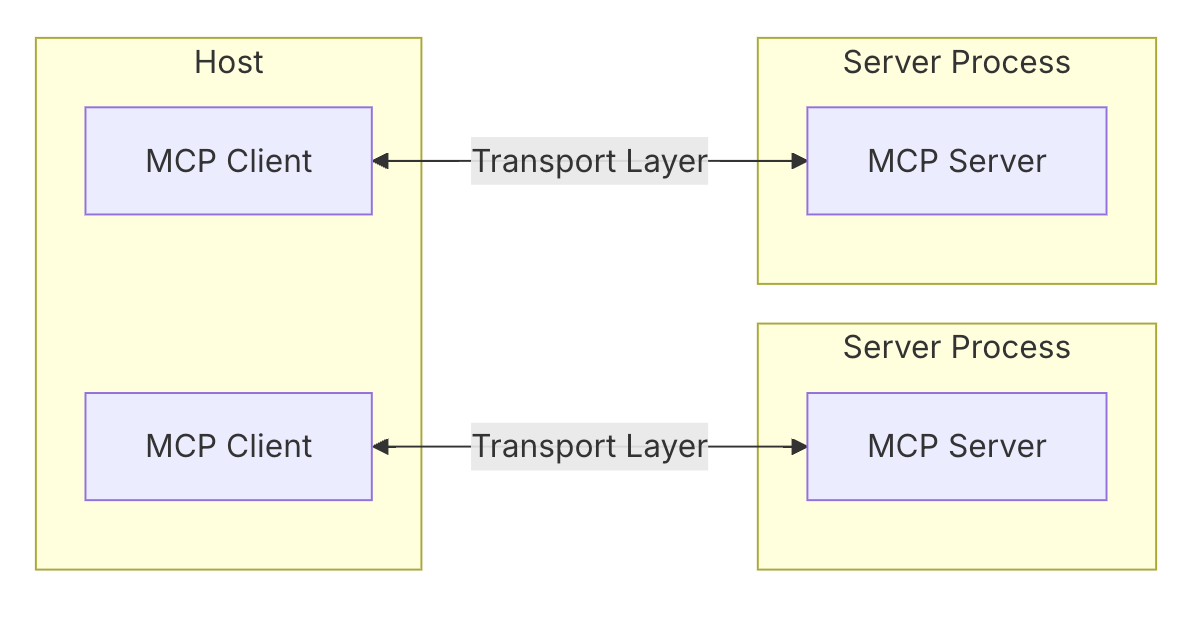
- ホスト(Hosts): Claude DesktopやCursor IDEなどのLLMアプリケーションで、接続を開始する役割
- クライアント(Clients): ホストアプリケーション内でサーバーと1対1の接続を維持する役割
- サーバー(Servers): クライアントに対して、コンテキスト、ツール、プロンプトを提供する役割
さらに、Core Componentとして以下が定義されています。
- プロトコル層(Protocol layer): メッセージのフレーミング、リクエスト/レスポンスの関連付け、高レベルな通信パターンを扱う
- トランスポート層(Transport layer): クライアントとサーバー間の実際の通信を扱う
- メッセージタイプ: リクエスト(Request): 応答を期待するメッセージ。method とオプションの params を含む
エラーコードなどは、後述するJSON-RPCの標準エラーコードが使用されます。
通信の仕組み
MCPは基本的にJSON-RPC[3]を基盤としています。クライアント(AIアシスタント)とサーバー(データソース)間で、以下のような通信が行われます:
- リソース探索: データソースが持つリソース(テーブル、ビュー等)の一覧取得
- リソース読み取り: 特定のリソースの内容取得
- ツール呼び出し: 特定の機能(クエリ実行等)の呼び出し
通信は標準入出力(stdin/stdout)を通じて行われ、JSON形式のメッセージをやり取りします。例えば、リソース一覧を取得するリクエストは以下のようになります:
{
"jsonrpc": "2.0", // JSON-RPCプロトコルのバージョン(固定)
"id": "request-123", // リクエストを識別するID(レスポンスで同じIDが返される)
"method": "resources/list", // 呼び出すメソッド名
"params": {} // メソッドのパラメータ(メソッドによって異なる)
}
例えば、クライアントが resources/list を呼び出してアクセス可能なリソース一覧を取得しようとした際、以下のようなschemaのレスポンスが返ってきます:
{
"jsonrpc": "2.0",
"id": "request-123",
"result": {
"resources": [
{
"uri": "bigquery://project-id/dataset/table/schema",
"mimeType": "application/json",
"name": "dataset.table schema"
}
]
}
}
MCPで利用される主要なメソッドには以下のようなものがあります。
MCPでは、以下の主要なメソッドが定義されています:
サーバー情報と初期化関連
-
serverInfo: サーバーの情報を取得 -
initialize: クライアントとサーバー間の初期化処理を実行
リソース関連
-
resources/list: 利用可能なリソース一覧を取得 -
resources/read: 特定のリソースの内容を読み取る
参考:https://modelcontextprotocol.io/docs/concepts/resources#resource-discovery
ツール関連
-
tools/list: 利用可能なツール一覧を取得 -
tools/call: 特定のツールを呼び出して実行
参考:https://modelcontextprotocol.io/docs/concepts/tools#overview
MCP Serverの実装
実装の基本
MCPサーバーの実装には、公式のSDKが用意されているのでそれを利用できます。
TypeScript[4]やPython[5]など、多くの言語のものが公式に用意されています。
ここではTypeScript版を利用してMCP Serverを実装していく例を書きます。
npm install @modelcontextprotocol/sdk
SDKを使用したサーバーの基本構造は以下の通りです:
import { Server } from "@modelcontextprotocol/sdk/server/index.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import {
CallToolRequestSchema,
ListResourcesRequestSchema,
ListToolsRequestSchema,
ReadResourceRequestSchema,
} from "@modelcontextprotocol/sdk/types.js";
// サーバーの初期化
const server = new Server(
{ name: "mcp-server/bigquery", version: "0.1.0" },
{ capabilities: { resources: {}, tools: {} } }
);
// リクエストハンドラーの登録
server.setRequestHandler(ListResourcesRequestSchema, async () => {
// リソース一覧取得の処理
});
// サーバー起動
async function runServer() {
const transport = new StdioServerTransport();
await server.connect(transport);
}
runServer().catch(console.error);
BigQueryを題材にしたMCP Server実装例
では実際にBigQueryにアクセスするMCP Serverを作ってみましょう。
プロジェクト構成
mcp-bigquery/
├── src/
│ └── index.ts # メインコード
├── test/
│ └── connectivity-test.js # 疎通テスト
├── package.json
└── tsconfig.json
主要コンポーネントの実装
- サーバー設定と初期化:
// コマンドライン引数からの設定取得
function parseArgs(): ServerConfig {
// プロジェクトID、ロケーション等のパース
}
// BigQueryクライアントの初期化
const config = parseArgs();
const bigquery = new BigQuery({
projectId: config.projectId
});
// ベースURLの設定
const resourceBaseUrl = new URL(`bigquery://${config.projectId}`);
- リソース一覧取得ハンドラー:
server.setRequestHandler(ListResourcesRequestSchema, async () => {
try {
const [datasets] = await bigquery.getDatasets();
const resources = [];
for (const dataset of datasets) {
const [tables] = await dataset.getTables();
for (const table of tables) {
const [metadata] = await table.getMetadata();
const resourceType = metadata.type === 'VIEW' ? 'view' : 'table';
resources.push({
uri: new URL(`${dataset.id}/${table.id}/schema`, resourceBaseUrl).href,
mimeType: "application/json",
name: `"${dataset.id}.${table.id}" ${resourceType} schema`,
});
}
}
return { resources };
} catch (error) {
throw error;
}
});
- ツール一覧取得ハンドラー:
server.setRequestHandler(ListToolsRequestSchema, async () => {
return {
tools: [
{
name: "query",
description: "読み取り専用のBigQuery SQLクエリを実行する",
inputSchema: {
type: "object",
properties: {
sql: { type: "string" },
maximumBytesBilled: {
type: "string",
description: "課金される最大バイト数(デフォルト: 1GB)",
optional: true
}
},
},
},
],
};
});
- SQLクエリ実行ハンドラー:
server.setRequestHandler(CallToolRequestSchema, async (request) => {
if (request.params.name === "query") {
let sql = request.params.arguments?.sql as string;
let maximumBytesBilled = request.params.arguments?.maximumBytesBilled || "1000000000";
// 読み取り専用クエリであることを検証
const forbiddenPattern = /\b(INSERT|UPDATE|DELETE|CREATE|DROP|ALTER)\b/i;
if (forbiddenPattern.test(sql)) {
throw new Error('読み取り操作のみが許可されています');
}
try {
const [rows] = await bigquery.query({
query: sql,
location: config.location,
maximumBytesBilled: maximumBytesBilled.toString(),
});
return {
content: [{ type: "text", text: JSON.stringify(rows, null, 2) }],
isError: false,
};
} catch (error) {
throw error;
}
}
throw new Error(`不明なツール: ${request.params.name}`);
});
認証情報の渡し方と注意点
MCP Serverでは、特にクラウドサービスへの接続において認証情報の管理が重要です。
ローカル開発での認証
開発環境では、Google Cloud CLIを使った認証が簡単です:
gcloud auth application-default login
これにより、 ~/.config/gcloud/application_default_credentials.json に認証情報が保存されます。
Claude Desktopでの設定と注意点
Claude Desktopで使用する場合、設定ファイルに絶対パスを指定する必要があります:
{
"mcpServers": {
"bigquery": {
"command": "node",
"args": [
"/absolute/path/to/dist/index.js",
"--project-id",
"YOUR_PROJECT_ID",
"--location",
"us"
],
"env": {
"GOOGLE_APPLICATION_CREDENTIALS": "/absolute/path/to/your/credentials.json"
}
}
}
}
デバッグと疎通テスト
MCP Serverの動作確認には、標準入出力を介してJSON-RPCメッセージを送信するテストスクリプトが有効です:
// 簡易的な疎通テストツール
const server = spawn('node', [
'dist/index.js',
'--project-id', 'YOUR_PROJECT_ID',
'--location', 'us'
], { stdio: ['pipe', 'pipe', 'pipe'] });
// テストリクエスト(リソース一覧取得)
const request = {
jsonrpc: '2.0',
id: '1',
method: 'resources/list',
params: {}
};
// リクエスト送信
server.stdin.write(JSON.stringify(request) + '\n');
このようなテストスクリプトを用意しておくことで、Claude Desktop環境に依存せずにMCP Serverの動作確認ができます。
今回作成したMCP Serverの全体はこちらです:
まとめ
MCPを使うことで、AIアシスタントと各種データを直接接続できるようになり、自然言語でデータ分析や探索が可能になります。
今回勉強のために(Claudeに手伝ってもらいながら)MCP Serverを実装してみましたが、SDKを用いて比較的少ないコード量で実現でき、他のツールにもいろいろ応用が効きそうでした!
MCPも仕組みを理解すれば怖くなく利用できます!いいMCPライフを送りましょう!

Discussion