初めまして、アスエネでエンジニアをしている加藤です。前職ではドローンで撮影した4Kや6Kの画像をDeep Learningで解析するなどしていました。現職ではAI-OCRの性能改善に取り組んでいます。
さてみなさん、突然ですがPDFから文字情報を取得したり、PDFに含まれる画像を抽出することに興味はありませんか?この記事ではpypdfium2を使って文字情報を取得したり、画像に変換したりする方法を紹介します。
pypdfium2とは?
pypdfium2の正確な読み方は不明ですが、LibreOffice Conference 2018の動画を観ると「ぴーでぃーえふあいゆーぇむ」のように発音しているように聞こえます(正確なソースがあれば教えてください)。
pypdfium2はDifyというオープンソースのLLMアプリ開発プラットフォームでもPDF解析に使われており、ライセンス表記等は必要[1]なものの、商用としても利用しやすく高速に動作します。
pypdfium2に関する知識はネット上にも少なく、公式ドキュメントやissueを参考に試行錯誤しながら検証したので少しでも誰かの役に立てば幸いです。ハマりポイントも最後に記載しました。
注意点として、pypdfium2はPDFに埋め込まれた文字情報を取得できますが、画像からのOCRはできません。そのため、画像から文字を認識したい場合はTesseract等の別のライブラリを使用してください。
pypdfium2の使い方
使い方は簡単で、pip install pypdfium2でインストール完了です。この記事では簡単に利用できるように用意したGoogle Colabで利用できるプログラムを使って説明をします。
リンク先の「Open in Colab」ボタンを押していただければすぐに利用できますし、ローカルのスクリプト実行でもほぼコピペで動作するようになっているのでお好みにあわせて環境を構築してください。
1. 環境構築
まずは以下のセルを選択して、実行しましょう。環境構築が開始されます。
※実行方法は左上の▼を押しても良いですし、Ctrl+Enterでも良いです。
!pip install pypdfium2 # 今回使用するメインライブラリ
!apt install fonts-noto-cjk # 日本語を描画するのに必要
今回は日本語が含まれるPDFの日本語情報を扱う関係でフォントを追加でインストールしています[2]。
2. PDFアップロード
Googleドライブの機能を使って解析したいPDFをアップロードします。以下のセルを実行すると「ファイルの選択」ボタンが押せるようになるので、クリックして解析したいPDFをアップロードしてください。
from google.colab import files
uploaded = files.upload()
今回、例として使用しているのは「気象庁ガイドブック2024」の第一章「防災気象情報」ですが、各自好きなPDFをアップロードしてください[3]。
3. PDF解析デモ
解析デモはコピペでPythonスクリプトとしても動作するようになっています[2:1]。
次のセルを実行すると、アップロードされたPDFを画像に変換し、文字情報の位置を矩形で塗りつぶし、取得した文字を上書きするデモが動きます。
デモコードは規模が大きいため、重要な部分に絞って説明していきます。
まずmain関数から順に説明していきます。
PDFはアップロードされてカレントディレクトリ直下(Path.cwd())に置かれます。そのため、glob("*.pdf")でPDFを探索してload_pdfに入力します。scaleは大きければ大きいほど生成される画像の解像度が上がります。
def main(pdf_dir: Path) -> None:
"""
指定ディレクトリ内にある全てのPDFを読み込み、処理を行います。
Parameters
----------
pdf_dir : Path
PDFファイルが格納されたディレクトリのパス。
"""
# ディレクトリ内の "*.pdf" ファイルを全て処理
for pdf_path in pdf_dir.glob("*.pdf"):
print(f"Loading PDF: {pdf_path.stem}")
load_pdf(pdf_path, scale=4)
# 実行エントリポイント
if __name__ == "__main__":
main(Path.cwd())
load_pdf関数は以下のようになっています。
def load_pdf(
pdf_path: Path,
scale: int = 1,
convert_grayscale: bool = False
) -> int:
"""
指定したPDFファイルを読み込み、ページ画像を生成してテキストを抽出・表示します。
Parameters
----------
pdf_path : Path
PDFファイルのパス。
scale : int, optional
レンダリングスケール (数値が大きいほど高解像度), デフォルトは1。
convert_grayscale : bool, optional
TrueにするとPDFのレンダリングをグレースケールで行う, デフォルトはFalse。
Returns
-------
int
終了ステータス(ここでは常に0を返す)。
"""
# PDFを読み込み
pdf = pdfium.PdfDocument(pdf_path)
# PDF バージョンおよびページ数の確認
version = pdf.get_version()
n_pages = len(pdf) - 1 # ページ数(0始まり前提で最後のページindexを表示したい?)
print(f"PDF version: {version}")
print(f"Number of pages: {n_pages}")
# PDF内の全ページについて処理
for i, page in enumerate(pdf):
# ページの幅と高さを取得(ここでは高さのみ利用)
_, h0 = page.get_size()
# このページに対応するテキストを管理するオブジェクトを取得
textpage = page.get_textpage()
# ページ画像のレンダリング(scaleを反映可能)
raw_image = page.render(
scale=scale,
rotation=0,
grayscale=convert_grayscale,
).to_numpy()
# 画像サイズ
h, w = raw_image.shape[:2]
# ページ全体のテキストを取得(余白を2pxだけ除外)
text_part = get_text_bounded(textpage, left=2, bottom=2, right=w - 2, top=h - 2)
print(f"### page {i}/{n_pages}, width={w}, height={h} ###")
print(text_part)
print("#" * 20)
# グレースケール変換した画像を用意
image = cvt_grayscale(raw_image)
# ページ中の各オブジェクト(文字列領域)を走査
for j, obj in enumerate(page.get_objects()):
# obj.get_pos() で得られる座標はPDF上(左下原点)の座標系
# OpenCV上(左上原点)で扱うために高さ方向を反転する必要がある
x0, y0, x1, y1 = [coord + 0.25 for coord in obj.get_pos()] # 余裕を持たせるため+0.25
# 異常に大きいテキスト領域をスキップ (高さがPDF全体の10%以上)
if h0 * 0.1 < abs(y1 - y0):
continue
# テキストを抽出 (このバウンディングボックスに文字列があるか)
text_part = get_text_bounded(textpage, left=x0, bottom=y0, right=x1, top=y1)
if not text_part:
continue
# OpenCV 用に描画座標をスケール調整 & PDF座標系から変換
x0, y0, x1, y1 = [int(coord * scale) for coord in obj.get_pos()]
top_left = (x0, h - y0)
bottom_right = (x1, h - y1)
# 領域を長方形で囲む
image = rectangle(image, top_left, bottom_right)
# テキストをオブジェクト枠付近に描画
text_height = abs(y1 - y0)
font_size = min(30, int(text_height * 0.66))
image = puttext(image, text_part, (x0, h - y1), font_size)
# 処理結果を side-by-side で表示 (左: 生画像, 右: 加工画像)
combined_image = np.hstack((raw_image, image))
cv2_imshow(combined_image)
cv2.waitKey(1)
return 0
pdf = pdfium.PdfDocument(pdf_path)でPDFのパスからpdf情報にアクセスするためのオブジェクトを生成します。pdf.get_version()でバージョン情報を取得できたり、 pdf[0]で0ページ目にアクセスしたり 、for文で全ページ探索など様々な処理ができます。
また、以下のように記載することで全ページを画像化できます。
# PDF内の全ページについて処理
for i, page in enumerate(pdf):
# ページの幅と高さを取得(ここでは高さのみ利用)
_, h0 = page.get_size()
# このページに対応するテキストを管理するオブジェクトを取得
textpage = page.get_textpage()
# ページ画像のレンダリング(scaleを反映可能)
raw_image = page.render(
scale=scale,
rotation=0,
grayscale=convert_grayscale,
).to_numpy()
.to_numpy()でnumpy形式の画像を取得できます。ここではtextpageにテキスト情報を、raw_imageに画像情報を格納しています。画像情報は事前に回転させたり、グレースケールに変換することも可能です。
ページのほぼ全領域からテキスト情報を取得するには以下のようにします。文字情報の座標情報が不要な場合はこれが一番簡単です。
# 画像サイズ
h, w = raw_image.shape[:2]
# ページ全体のテキストを取得(余白を2pxだけ除外)
text_part = get_text_bounded(textpage, left=2, bottom=2, right=w - 2, top=h - 2)
以下のような結果が得られます(一部省略しています)。
### page 0/5, width=1191, height=1679 ###
2024年2月6日 午後10時33分 GUIDEBOOK2024_P001-006_2k<P1>
防災気象情報の伝達手段
気象庁が発表する大雨警報や津波警報などの防災気象情報
は、様々な伝達手段を用いて防災機関や住民へ伝達されます。
(中略)
ージ、SNS 等を通じて広く国民に発表しています。
1
Ⅰ 防災気象情報 Ⅰ 防災気象情報
####################
しかし、文字の座標を取得したいこともあるでしょう。我々も普段から領収書をAI-OCRで解析しており、その際は文字の座標が重要な情報源となります。そのような場合はpage.get_objects()を使用します。これにより文字情報がobjectsという塊で取得できます。この塊をobjとして定義し、そしてobj.get_pos()で各塊の座標を取得し、get_text_bounded()によりその座標の文字を取得できます。
試しに、以下のように座標(obj.get_pos())と文字(text_part)を出力してみます。
print(obj.get_pos(), text_part)
先ほどページ全体のテキスト抽出をした時の先頭の文字が取得できていることがわかります。
(185.53744506835938, 429.76507568359375, 270.7655334472656, 438.2700500488281) GUIDEBOOK2024_P001-006_2k<P1>
PDFの構成もあるので必ずではないですが、おおむねPDFの上から順に取得できることが多いです。
注意点としては取得される座標は画像の左下を原点としており、OpenCV(=右上が原点)と組み合わせて文字情報を描画したい場合は高さ方向を反転させる必要があります。
# グレースケール変換した画像を用意
image = cvt_grayscale(raw_image)
# ページ中の各オブジェクト(文字列領域)を走査
for j, obj in enumerate(page.get_objects()):
# obj.get_pos() で得られる座標はPDF上(左下原点)の座標系
# OpenCV上(左上原点)で扱うために高さ方向を反転する必要がある
x0, y0, x1, y1 = [coord + 0.25 for coord in obj.get_pos()] # 余裕を持たせるため+0.25
# 異常に大きいテキスト領域をスキップ (高さがPDF全体の10%以上)
if h0 * 0.1 < abs(y1 - y0):
continue
# テキストを抽出 (このバウンディングボックスに文字列があるか)
text_part = get_text_bounded(textpage, left=x0, bottom=y0, right=x1, top=y1)
if not text_part:
continue
# OpenCV 用に描画座標をスケール調整 & PDF座標系から変換
x0, y0, x1, y1 = [int(coord * scale) for coord in obj.get_pos()]
top_left = (x0, h - y0)
bottom_right = (x1, h - y1)
# 領域を長方形で囲む
image = rectangle(image, top_left, bottom_right)
# テキストをオブジェクト枠付近に描画
text_height = abs(y1 - y0)
font_size = min(30, int(text_height * 0.66))
image = puttext(image, text_part, (x0, h - y1), font_size)
※OpenCVで日本語テキストを扱う方法については末尾のおまけの章を参照ください。
抽出した文字を画像中に描画するサンプルをGIFで用意しました。緑色の矩形が検知済みのエリアで、赤い矩形が新規検知したエリアになります。
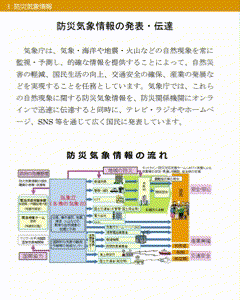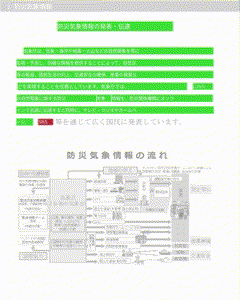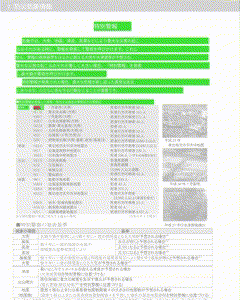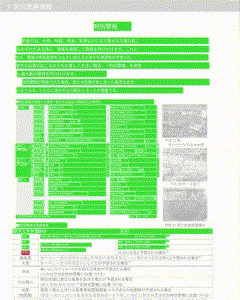
GIFは解像度が低いため、生成された画像のキャプチャを次に紹介します。左側が画像として取得した結果で、右側は左側の画像をグレースケールし、その上から取得できた矩形と文字で上書きしています。文字情報を取得できていないエリア(「平時の活動」や「大雨等の災害時の活動」)については文字ではなく純粋な画像としてPDFに埋め込まれているため情報を取得できていません。

最後に(注意点)
pypdfium2は非常に優秀なライブラリで、画像情報や文字情報を簡単に取得できます。その一方で私の利用ケースではメモリリークが発生するという問題もありました。一部のPDFを解析していると*Cannot close object, library is destroyed. This may cause a memory leak!というような文言がターミナル上に出てくることがありました。PDFは様々な方法で作成が可能なため、pypdfium2が想定しないPDFだったのかもしれません。そのような場合はpage.close()やobj.close()、gc.collect()を追加しないとエラーが消えなかったりして苦労することもあるので注意しましょう。
おまけ
OpenCV4で日本語情報を扱うのは難しいです。OpenCV5ではこの問題は解消されているので5の正式リリースが待ち遠しいですね。今回は以下に示すように一度PIL形式に変換してから日本語フォントを書き込み、numpy形式に変換することで日本語を描画しています。多分これが一番簡単です。
def puttext(
img: NDArray[np.uint8],
text: str,
point: tuple[int, int],
font_size: int = 30,
color: tuple[int, int, int] = (250, 250, 250),
font_path: str = "/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc",
debug: bool = False,
) -> NDArray[np.uint8]:
"""
画像(OpenCV形式)に指定した文字列を描画します。
Parameters
----------
img : NDArray[np.uint8]
描画対象の画像 (BGR形式)。
text : str
描画したい文字列。
point : tuple[int, int]
テキストの描画開始座標 (左上基準)。
font_size : int, optional
フォントサイズ, デフォルトは30。
color : tuple[int, int, int], optional
テキストの色 (B, G, R形式), デフォルトは(250, 250, 250)。
font_path : str, optional
TrueTypeフォントファイルのパス, デフォルトはNotoSansCJK-Regular。
(環境によってはフォントパスを変更してください)
debug : bool, optional
デバッグ出力を行うかどうか, デフォルトはFalse。
Returns
-------
NDArray[np.uint8]
テキストが描画された画像 (BGR形式)。
"""
# font_path が文字列型またはパス形式でない場合は警告して元の画像を返す
if not isinstance(font_path, (str, os.PathLike)):
print(f"font_path は文字列型またはPath-likeで指定してください: {font_path}")
return img
# debugフラグが立っていれば描画に使う情報を出力
if debug:
print(f" - text={text}, point={point}, color={color}, font_path={font_path}")
# OpenCV 画像を PIL 画像に変換
pil_image = Image.fromarray(img)
# PIL で描画するためのオブジェクトを生成
draw = ImageDraw.Draw(pil_image)
# PIL でテキストを描画(フォントサイズ・色を指定)
pil_font = ImageFont.truetype(font_path, font_size)
draw.text(point, text, font=pil_font, fill=color)
# PIL 画像を再び OpenCV 形式 (NumPy array) に変換して返す
return np.array(pil_image)

Discussion