はじめに
本記事では、AdjustのrawデータをBigQuery経由でスプレッドシートに自動連携する仕組みを紹介します。
「マーケチームから広告の学習データが欲しいと言われたけど、どうやって整備すればいい?」
そんな悩みを持っている方に役立つ内容になればと思います。
背景
マーケティングチームからの具体的な依頼は、「ユーザーがどの広告経由で、アプリ内でどんな行動をしたか」という時系列データ(rawデータ)を、Google広告の機械学習に利用したい、というものでした。
マーケチームからの要件は以下の3点です。
- Google広告の学習に使える直近3ヶ月分の最新データがほしい
- 1時間に1回更新される仕組みにしたい(常に最新のデータを見れる状態であれば良い)
- SQLを書けなくても スプレッドシートで結果を確認できるようにしたい
上記要件に加えて、広告効果の分析手法は日々変わるため、開発者が都度対応するのではなく、マーケティングチーム自身が柔軟にデータを扱える状態を目指す必要がありました。
当初の想定
前提
Adjustの公式データ連携機能(Raw Data Export)を利用しているため、計測されたイベントのRawデータは自動的にGoogle Cloud Storageに保存されるようにしています。
その都合上、Adjustからエクスポートされるデータは 広告の経路ごとに5分ごとのまとまりでCloud Storageに保存されます。
詳細
当初、私たちが検討していたのは次のような構成です。
- Cloud Run FunctionsでBigQueryからデータを抽出し、CSV を生成する処理を実装
- Google Apps Script (GAS) をスプレッドシートに設定し、①の Functions を定期的に実行
この構成でも要件自体は満たせます。
しかし「分析手法の変化に柔軟に対応する」という観点では、大きな懸念がありました。
例えば、マーケティングチームから「新しいカラムを追加してほしい」という要望が来た場合、
1. Cloud Run Functions の SQL と処理を修正
2. デプロイ
3. GAS 側の処理も確認・調整
といった改修作業が毎回発生します。
これでは分析スピードが落ち、機会損失に繋がりかねません。
さらに、Cloud Storage 上のデータを独自に整形し、スプレッドシートに「1時間ごとに直近3ヶ月分を更新表示する処理」を作り込む場合、どうしても不具合の発生率が高くなります。結果として、誤ったデータに基づく分析が行われるリスクがありました。
こうした背景から私たちは、なるべく独自コードを減らし、Google Cloudが提供するマネージド機能で完結させる方針を選びました。
そこで採用したのが、BigQueryとスプレッドシートの標準連携機能である 「データコネクタ」 です。
やったこと
最終的に、私たちは以下の構成にしました。
構成図とそれぞれの役割
▼構成図
╔══════════════════════════════════════╗
║ Adjust Raw Data ║
║ (Export by Adjust) ║
╚══════════════════════════════════════╝
↓
╔══════════════════════════════════════╗
║ Google Cloud Storage ║
║ (rawファイルを保存) ║
╚══════════════════════════════════════╝
↓
╔══════════════════════════════════════╗
║ Cloud Run Functions ║
║ (整形して BigQuery へロード) ║
╚══════════════════════════════════════╝
↓
╔══════════════════════════════════════╗
║ BigQuery ║
║ (Viewで直近3ヶ月分を抽出) ║
╚══════════════════════════════════════╝
↓
╔══════════════════════════════════════╗
║ Spreadsheet ║
║ (Data Connectorで参照・更新) ║
╚══════════════════════════════════════╝
- Google Cloud Storage (GCS)
- Adjustから送られてくるrawデータを保管するデータレイク。
- Cloud Run Functions
- GCSに保存された複数ファイルを定期的にBigQueryのテーブルにロードするETL処理。
- BigQuery
- rawデータテーブル
- 全期間のデータが格納されている場所。
- VIEW
- 直近3ヶ月分 個人情報をマスクなど、マーケティングチームが必要な形に整えた仮想テーブル。データコネクタからはこのVIEWのみを参照させる。
- rawデータテーブル
- スプレッドシート(データコネクタ)
- BigQueryのVIEWに接続し、データを表示・抽出する。マーケティング担当者が好きなタイミングで「更新」ボタンを押すだけで、最新のデータが取得できる。
この構成の最大のメリットは、それぞれのサービスが単一の責任を持っていることです。
データの流れが一方通行で非常にシンプルになり、問題発生時の切り分けが容易になりました。
具体的な実現方法
1. Cloud Run Functionsの処理内容
弊社ではすでに分析周りを管理するリポジトリがあるため、そちらに連携処理を作成しました。
ディレクトリ構成
src/assignCareerChange/
├── functions/
│ └── adjustCsvImport.ts # HTTP関数のエントリーポイント
├── services/
│ └── adjustCsvService.ts # CSV処理の業務ロジック
├── utils/
│ └── adjustCsvUtils.ts # 日付処理/フィルタ等
└── constants/
└── adjust_config.ts # 設定値
処理の流れ
- テーブル存在確認・処理方式決定
- テーブルの存在確認
- 未作成の場合
- 初回処理モード(全ファイル対象)
- 既存の場合
- スキーマ比較実行
- スキーマ変更なし → 増分処理モード
- スキーマ変更あり → 全件再構築モード(全ファイル対象)
- スキーマ比較実行
- Cloud Storageのバケットを読み込む
- 増分処理
- 最近2日分のCSVファイル(日付プレフィックスフィルタ)
- 全件処理
- 全てのCSVファイル(初回・スキーマ変更時のみ)
- 増分処理
- 既存処理済みファイルの確認
- logテーブルから処理済みファイル一覧取得
- 未処理ファイルのみを対象に絞り込み
- 全件処理時
- 新規データとして追加(ログテーブルはクリアしない)
- CSVファイルのダウンロードと解析
- タブ区切りCSV解析(ヘッダー行付き)
- 動的フィールドマッピング
- 1行目のヘッダーからフィールド名を取得
- 可変フィールド数対応
- フィールド数に関係なく自動処理
- 空文字列のnull変換処理
- UNIXタイムスタンプのJST変換(created_atフィールド)
- CSVファイル内の中括弧({})の除去処理
- BigQueryテーブル準備
- 初回作成時
- 最新CSVファイル(作成日時順ソートで最新)のヘッダーからスキーマ取得
- ヘッダー情報でテーブル作成
- 動的フィールドマッピングにより全データ対応
- スキーマ変更時
- テーブル再作成(既存BigQueryService活用)
- 増分処理時
- 既存テーブルを使用
- 初回作成時
- BigQueryへのデータ挿入
- GCS経由のLoad Job方式でバルク挿入
- 全件処理時
- WRITE_TRUNCATEモード(既存データを置換)
- 増分処理時
- WRITE_APPENDモード(既存データに追加)
- テーブルに格納
- 処理ログの記録
- 処理結果をlogテーブルに記録
- ファイル名と処理日時のみ記録(ステータスやエラー詳細は記録しない)
- 重複処理防止のためのチェックポイントとして使用
2. BigQueryのviewテーブル作成
BigQuery上でViewテーブルを作るには、
- CLIで直接実行する方法
- BigQueryのGUI(コンソール)で実行する方法
- GitHubなどでクエリを管理してデプロイする方法
がありますが、いずれにしてもクエリを作成する必要があります。
弊社ではBigQueryのクエリをGitHubのリポジトリで管理しています。(この運用方法は別記事で紹介予定です)
Viewテーブルを作成するクエリ例は以下です
CREATE OR REPLACE VIEW `sample_dataset.recent_3months_data` AS
SELECT *
FROM `sample_dataset.raw_data_table`
WHERE TIMESTAMP_SECONDS(created_at) >= TIMESTAMP(DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTH));
- WHERE句では「直近3ヶ月分のみ」を返すために、created_at(UNIXタイム)を基準に絞り込んでいます。
- CREATE OR REPLACE を使うことで、テーブルが存在しない場合は新規作成、存在する場合は上書きされます。
- REPLACE を付けない場合、既存Viewがある状態でCREATEを実行するとAlready Exists: View sample_dataset.recent_3months_dataというエラーが表示されます
3. スプレッドシートデータコネクタ
-
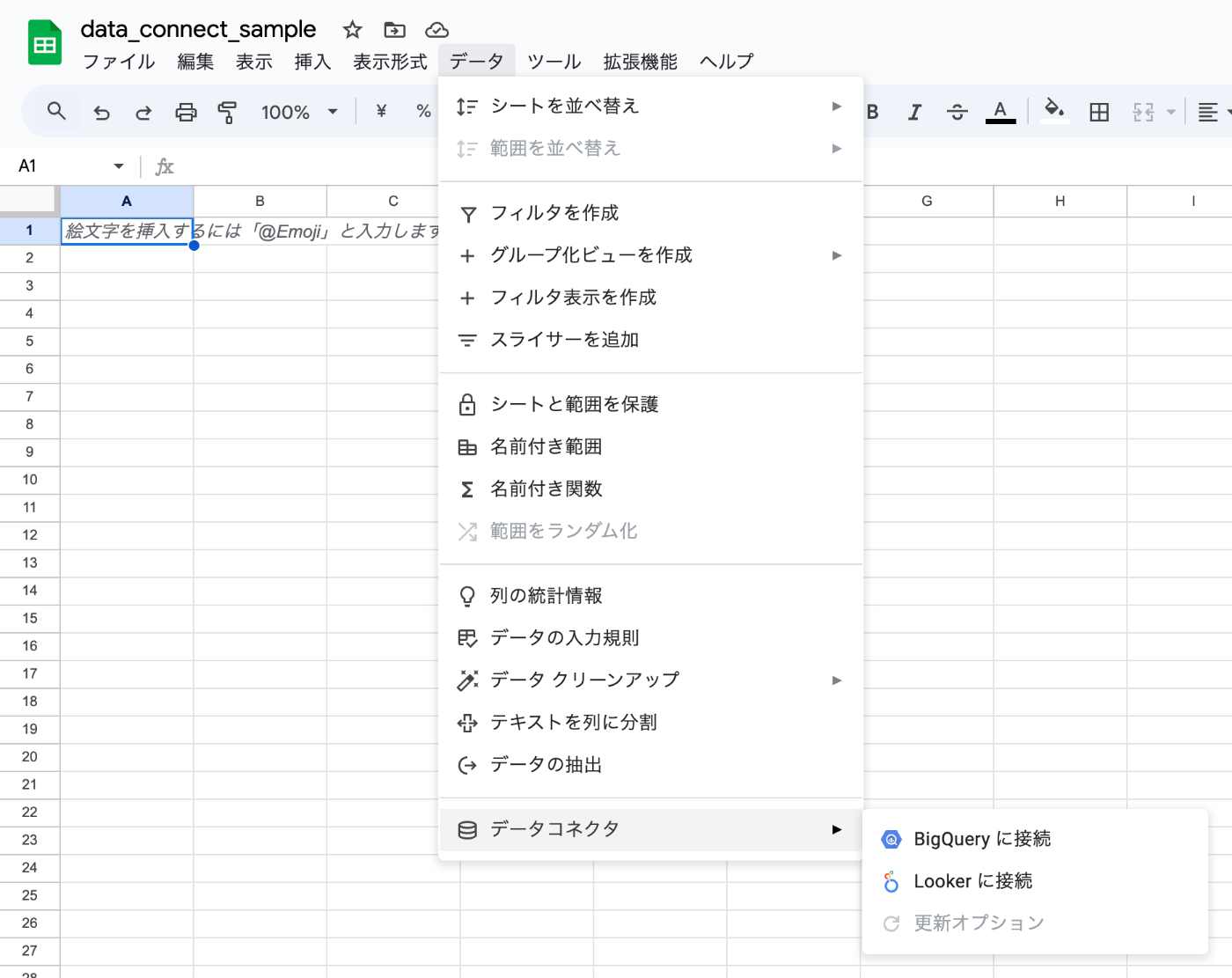
メニューから接続を開始
スプレッドシート上で [データ] → [データコネクタ] → [BigQuery] を選択します。
-
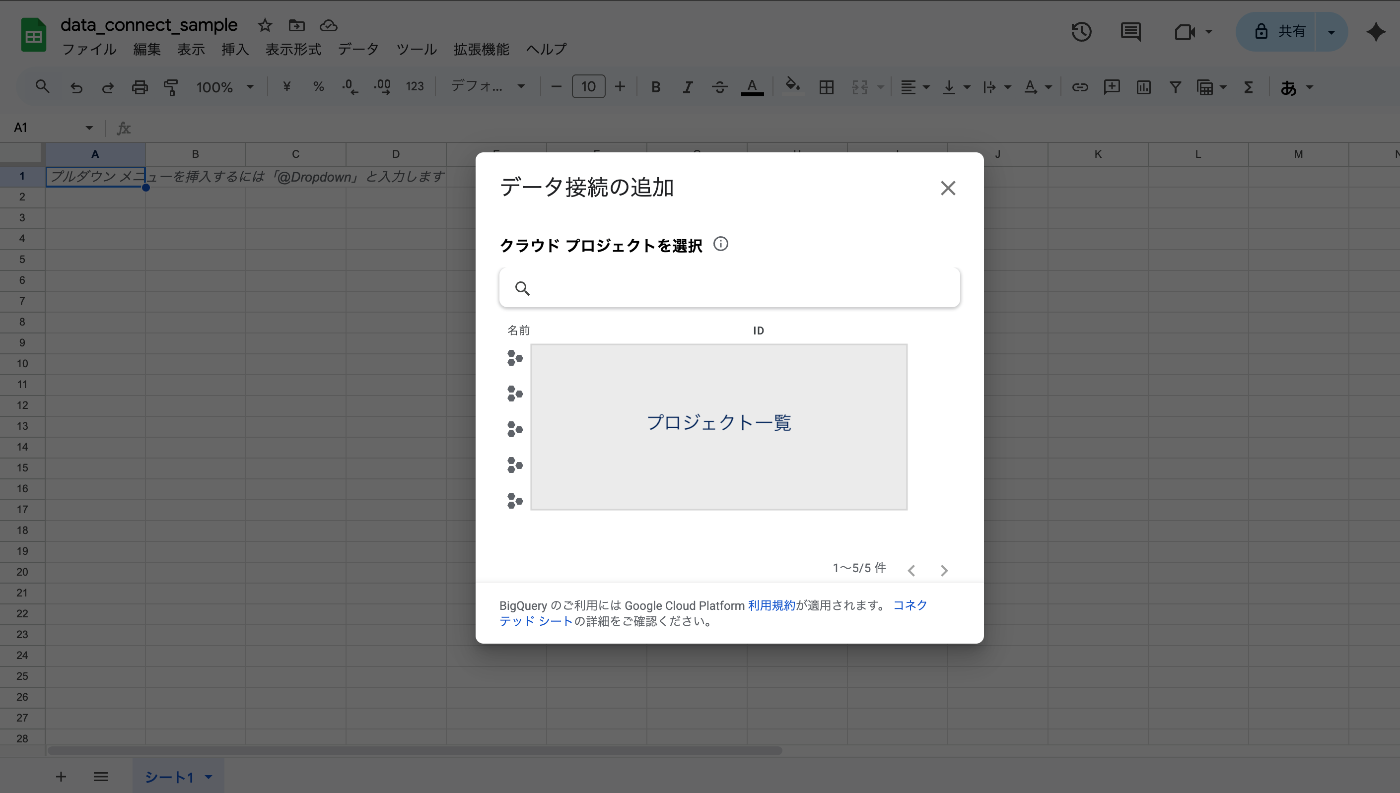
プロジェクトを選択
接続可能なプロジェクト一覧が表示されるので、対象のデータセットがあるプロジェクトを選択します。
-
データセットを選択
接続したいデータセットを選びます。ここで、先ほど作成したView(例:recent_3months_data)を指定できます。

-
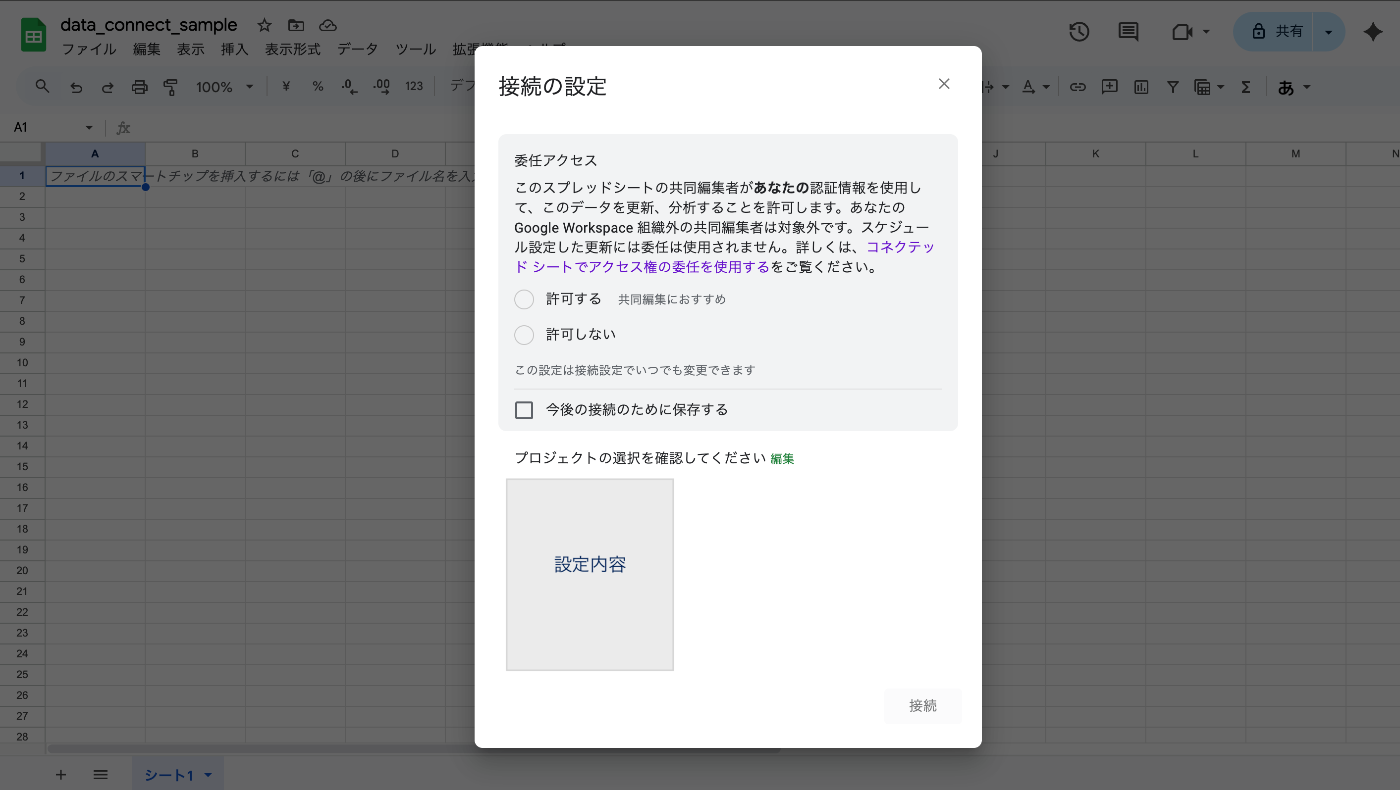
権限の確認
初回接続時は「委任アクセス」の確認が表示されます。
委任アクセスは、シートに所有者の BigQuery 権限を委任する設定です。
シートの閲覧者/編集者が BigQuery 権限を直接持っていなくても、このシートからのプレビュー/抽出/更新を実行可能になります。
実行時の課金・監査は所有者のプロジェクト/資格情報に紐づきます。
機密データはシートの共有範囲に従って閲覧できる点に注意してください。
-
接続完了 & 更新方法
接続が完了すると、スプレッドシート上にプレビューが表示されます。
このままではシート関数やVLOOKUPの対象にはならないため、
実際に使う場合は、サイドバーから 「抽出を作成」 を実行し、列/フィルタ/件数を指定してセルにデータを落とし込んでください。
左下の矢印アイコンをクリックすると、BigQueryから最新データを取得して更新されます。
データコネクタには自動更新機能もあり、スケジュールを設定して常に最新データを保つことも可能です。

安定性と柔軟性を両立させるために工夫した点
今回の仕組みを構築する上で、特に工夫した点を2つ紹介します。
1. Cloud Run Fucntionsの処理
- “スキーマが動く”前提のロード
- AdjustのRawデータは分析要件によってフィールドの増減が起きやすいため、autodetectをtrueにし、BigQueryがロード対象ファイルのヘッダーを読み取り、自動的にカラム名・データ型を判定してスキーマを作成/更新することでフィールドの増減にも対応
- 大量ファイル処理への対応
- 1 日あたり数百〜数千ファイルに対応するため、日付(更新時刻)で増分選別
- 1 ファイル失敗でも止めない ファイル単位の try-catch + 継続
- コスト最適化
- BigQuery は View で直近 3 ヶ月に限定
- Spreadsheet は オンデマンド更新で毎時課金を防止
- 観測性(後から原因を特定できる)
- 構造化ログ([LOAD_ERROR] fileName ... 等)で失敗点が一目でわかる
- サマリー(OK/NG 件数・モード)を HTTP レスポンスで返し、運用の可視化を担保
- テストユーザー除外
- 取込後の View で WHERE user_id NOT IN (テストユーザー) / AND env <> 'staging' など、分析に効く除外を一箇所に集約
2. BigQuery:VIEWによる「責務の分離」と「コスト管理」
- BigQuery + データコネクタによる責務の分離
• Rawデータの整形やフィルタリングは BigQuery側(SQL/View) に集約。
• スプレッドシートはあくまで データの参照と共有 に限定し、加工ロジックをシート側に持たせない。 - viewテーブルをコネクトすることによるオンデマンド更新の実現
- スプレッドシートが直接Rawテーブルを読むと、データ量が多すぎてクエリコストが高騰しやすいため、BigQueryに「直近3ヶ月分だけを返す View」を用意し、スプレッドシートのデータコネクタはこのViewに接続し、不要な古いデータを読み込まないようにする。
- スプレッドシート側では 「更新」ボタンを押したタイミングのみクエリが走る(オンデマンド実行) ため、無駄な定期実行を避けつつ必要なときに最新データを取れる。
- 自動更新を有効化することで、日次・時間単位での定期リフレッシュにも対応可能。
結果
今回の仕組みによって、データ連携処理を シンプルかつサービスごとに責務を分離 できたため、不具合の特定が容易になりました。
実際、当初は「3ヶ月分が欲しいのに最新1日分しか取れない」という不具合がありましたが、原因がCloud Run Functionsにあるとすぐに切り分けでき、迅速に修正できました。
また、コスト面でも改善があり、「毎時間クエリを実行する」形ではなく、必要なときにオンデマンドで最新データを取得する方式にしたことで、無駄な実行を避けつつ効率的に運用できています。
さらに、マーケティング側はスプレッドシートから直接データを扱えるため、エンジニアが毎回調整作業を行う必要がなくなり、シームレスに分析を進められる環境が整いました。
今後の展望
今回マーケチームからの依頼でデータ連携処理を作成しましたが、これはデータ活用の第一歩にすぎません。
意思決定を確かなデータに基づいて行える体制を整えることは、今後プロダクトを成長させていくことにおいて非常に重要であると考えています。
定性的なインサイトと定量的なデータの双方を活用し、バランスの取れた分析基盤を築くことが欠かせない中で、データを正確かつ安全に収集・活用できる仕組みを整えることが重要であると考えており、
この目標を達成するために、今後はCloud SQLとBigQueryのシームレスな連携、およびBigQuery上のクエリや分析ロジックの体系的な管理を進め、組織全体で再現性と信頼性の高いデータ分析が実現できる環境を目指していきたいと考えています。
具体的には、以下の3点に注力していきます。
-
データソースの拡充:Cloud SQLとの連携による、より深いユーザー理解
現在はマーケティングチャネルのデータが分析の中心ですが、今後はプロダクトDBであるCloud SQLに格納されているマスターデータ(ユーザーの契約プランや主要機能の利用状況など)とBigQueryを連携させます。
これにより、「この広告から流入したユーザーは、どのプランを契約しやすいのか?」といった、事業の意思決定に直結する、より解像度の高い分析が可能になります。 -
データの可視化:Looker活用による、セルフサービス分析の実現
データがBigQueryに集約されても、スプレッドシートだけではインタラクティブな深掘り分析に限界があります。そこで、BIツールであるLooker(またはLooker Studio)を導入し、各種KPIを可視化するダッシュボードを構築します。
これにより、エンジニアやアナリストに依頼せずとも、ビジネスサイドの担当者自身がデータをドリルダウンし、必要なインサイトを迅速に得られるセルフサービス分析の文化を醸成します。 -
分析プロセスの標準化:dbt/Dataform導入による「信頼できるデータ」の提供
データ分析が活発になるほど、「この指標、誰がどんな計算で作ったんだっけ?」という指標の属人化やブラックボックス化が起こりがちです。
そこで、dbtやDataformのようなデータ変換ツールを導入し、BigQuery上の分析ロジックを体系的に管理します。これにより、組織全体で「信頼できる単一の真実(Single Source of Truth)」を構築し、誰でも再現可能で、信頼性の高いデータ分析が行える環境を整備します。
これらの施策を通じて、データドリブンな文化を醸成し、プロダクトをさらなる高みへと導いていきたいです。
最後までお読みいただきありがとうございました!
この記事が、同じような課題を持つ誰かの一助となれば幸いです。
参考資料

Discussion