AI Scientist-v2の詳細解説:AIによる自律的な科学論文作成プロセスとは
イントロダクション
人工知能(AI)は、私たちが複雑な問題に取り組む方法を急速に変えつつあり、科学的発見もその例外ではありません。データを分析するだけでなく、仮説を立て、実験を設計・実行し、結果を解釈し、さらにはその発見に関する科学論文を執筆する――これらすべてを自律的に行うシステムこそが、Sakana AIによってパブリッシュされた今回の研究論文「THE AI SCIENTIST-V2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search」が取り組んでいる目標です。
この記事では、科学的なワークフローの自動化を目指して設計されたエンドツーエンドシステム、AI Scientist-v2について詳しく解説します。先行バージョン(v1)を基盤とするv2は、自律性と探索能力において大幅な進歩を遂げました。特筆すべきは、v2が生成した原稿が、権威ある機械学習ワークショップ(ICLRのICBINB - "I Can't Believe It's Not Better")での査読プロセスを経て採択されたことです。これは、AI駆動型科学における重要なマイルストーンと言えます。
ソフトウェアエンジニアにとって、この研究は科学的な意味合いだけでなく、そのエージェントシステムの設計、コード生成と推論のための大規模言語モデル(LLM)の利用、フィードバックのための視覚言語モデル(VLM)の統合、そして複雑な実験ワークフローを管理するために用いられる新しい木探索(Tree Search)手法といった点でも非常に興味深いものになっています。本記事では、AI Scientist-v2がどのように機能し、何を達成し、そしてその潜在的な影響と制約について解説していきます。
The Core Problem
科学的発見を自動化するという考え自体は新しいものではありませんが、エンドツーエンドで自律的に動作するシステムを作る上では、依然として大きな課題があります。以前のバージョンであるAI Scientist-v1は、実験の実行から論文を書き上げるまでのワークフローを自動化できる可能性を示されましたが、同時に大きな制約も抱えていました。
- テンプレートへの依存: AI Scientist-v1は、特定の研究分野ごとに人間が作成したコードテンプレートに大きく依存していました。新しい科学的トピックに対応するためには、適切なベースラインとなるコードテンプレートを作成するために、かなりの手作業が必要でした。これは、システムの自律性と、すぐに利用できる(out-of-the-box)汎用性を著しく制限していました。エンジニアの方々は、少し異なる種類のアプリケーションごとに事前に構築されたプロジェクトの骨組みが必要になるようなものだと考えると、新しい問題領域への迅速な展開が妨げられる状況が想像できます。
- 直線的で深掘りしない探索: v1における実験プロセスは、安直に進められていました。各々の新しい実験は、直前の実験を逐次的に修正したものであったため、複雑な仮説により深く構造化された探索、後戻り、あるいは異なる研究ブランチの並行調査が妨げられていました。
これらの制約は、v1が画期的であったとはいえ、本当の意味で自律的ではなく、複雑な科学的問いを深く掘り下げることができなかったことを意味します。AI Scientist-v2は、これらの制約を克服するために特別に設計され、科学的探求におけるより大きな自律性、柔軟性、そして深さを目指しています。
提案されたソリューション/アルゴリズム
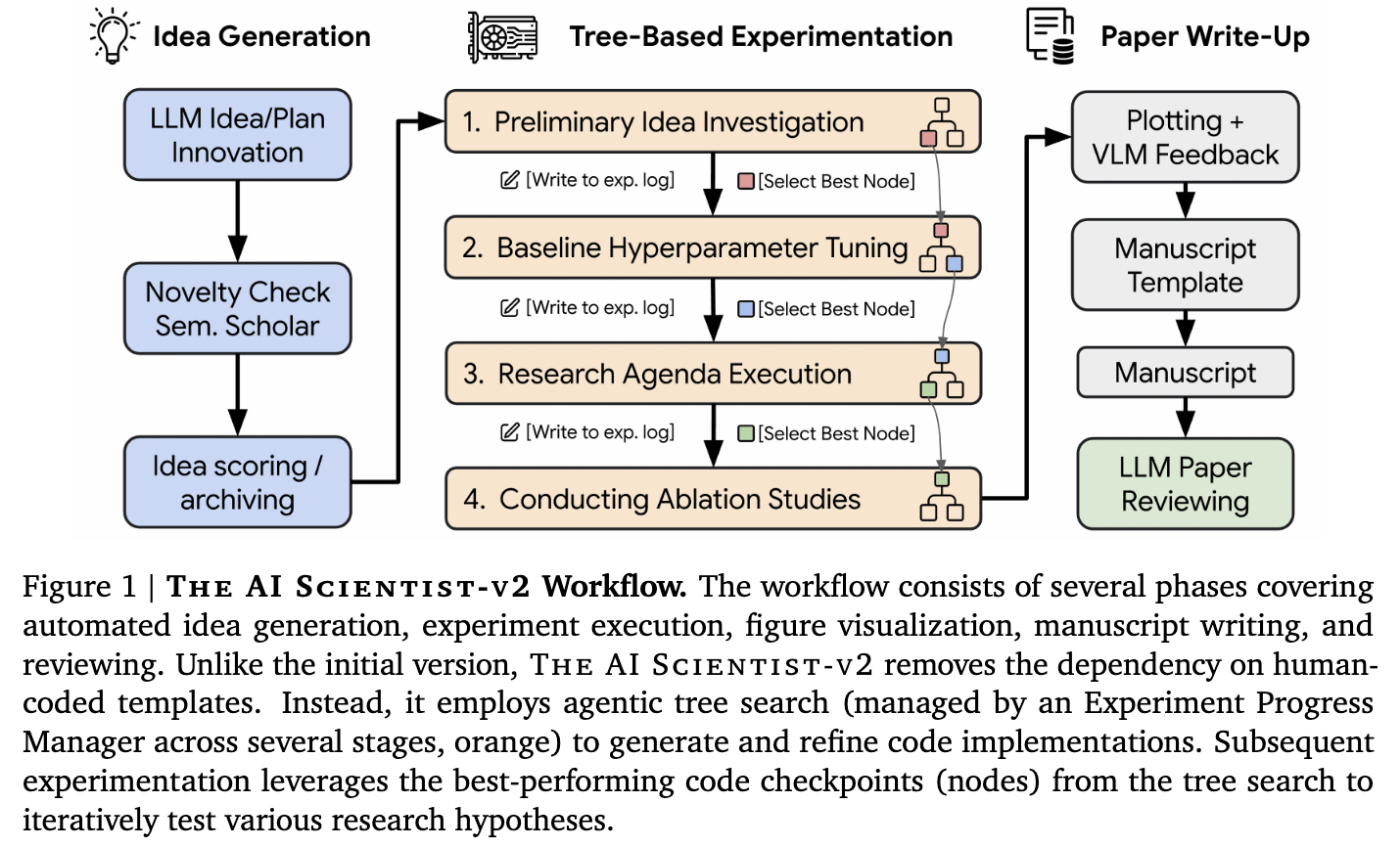
AI Scientist-v2は、v1から大幅なアーキテクチャの進化を遂げています。人間が提供するテンプレートへの依存を排除し、エージェントによる木探索によって管理され、VLMフィードバックループによって強化された、より洗練された多段階の実験プロセスを導入されています。
主要なコンポーネントとイノベーションを分解してみましょう。
1. 汎用的なアイデア生成(コードテンプレートを超えて)
特定のコード修正から始める代わりに、v2はより高い抽象レベルから開始します。
- オープンエンドなコンセプト: システムは、コードを一切書く前に、研究のアブストラクトや助成金申請書を起草するのと同様に、潜在的な研究の方向性、仮説、実験計画について幅広く考えるよう促されます。
- 文献の統合: 重要なのは、このフェーズがSemantic Scholarのようなツールと統合されている点です。システムは、アイデア形成中に文献データベースを照会し、提案されたコンセプトの新規性を評価し、既存の科学的知識に基づいたものにすることができます。これにより、車輪の再発明や行き止まりの追求を避け、事後チェックのみに依存していたv1の純粋な生成アプローチよりも、初期のアイデアがより情報に基づいたものになります。
2. エージェントによる木探索を通じたテンプレート不要の実験
これが、v1のテンプレート依存と直線的なワークフローを置き換える中核的なイノベーションです。システムは、抽象的なアイデアに基づいてゼロからコードを生成し、明確なステージにわたって管理される木構造を使用して実験空間を探索します。
-
実験進行マネージャー (Experiment Progress Manager): 現実世界の研究を模倣し、「実験進行マネージャー」エージェントがプロセスを4つの定義されたステージを通じてガイドします。
- ステージ1: 初期調査 (Preliminary Investigation): 初期の実現可能性を確立します。生成されたアイデアに基づき、最小限の動作プロトタイプを稼働させます。目標:基本的なアイデアがそもそも実行可能か?
- ステージ2: ハイパーパラメータチューニング (Hyperparameter Tuning): 堅牢な実験ベースラインを確立するために、重要なパラメータ(学習率、エポック数など)を最適化して初期実装を洗練します。目標:コアアイデアのための安定した設定を見つける。
- ステージ3: 研究課題の実行 (Research Agenda Execution): チューニングされたベースラインに基づいて、初期アイデアから導出された中核的な仮説を体系的に実装し、テストします。目標:主要な研究課題を探求する。
-
ステージ4: アブレーションスタディ (Ablation Studies): 実験のさまざまなコンポーネントや仮定の重要性を体系的に評価し、主要な発見に対する厳密な裏付けを提供します。目標:メソッドのどの部分が実際に貢献しているかを理解する。
各ステージには停止基準があります(例:ステージ1では動作プロトタイプ、ステージ2では安定した結果、ステージ3および4では予算枯渇)。各ステージの後、LLM評価者が次のステージのシードとなる最もパフォーマンスの高い「ノード」(実験)を選択します。マネージャーはまた、統計的な堅牢性のために、最終的な最良の実験の複数回の実行(複製)をトリガーします。
-
並列化されたエージェントによる木探索 (Parallelized Agentic Tree Search): 直線的なシーケンスの代わりに、実験は木構造のノードとして編成されます。
-

-
ノード定義: 各ノードは特定の実験を表し、以下を含みます:
- 実験計画(テキスト記述)。
- 実験を実装するPythonスクリプト。
- 実行エラーのトレース(もしあれば)。
- 実行時間とパフォーマンスメトリクス。
- スクリプト/結果に対するLLMフィードバック。
- 可視化スクリプトと生成された図へのパス。
- 図に対するVLMフィードバック。
- 最終ステータス:「バグあり (
buggy)」または「バグなし (non-buggy)」。
-
実行サイクル:
- LLMがノードの計画とPythonコードを生成します。
- コードが実行されます。エラーが発生した場合、ノードは「バグあり」とマークされ、エラーが記録されます。
- 実行が成功した場合、結果(メトリクス、損失)がNumPyファイルに保存されます。
- プロットスクリプトが保存された結果から可視化を生成します。
- 可視化が視覚言語モデル(VLM)に渡されます。
- VLMがプロットを批評します(明瞭さ、ラベル、凡例、潜在的な問題)。問題が見つかった場合、ノードは「バグあり」とマークされ、フィードバックが保存されます。
- 実行とVLMレビューが成功した場合、ノードは「バグなし」と指定されます。
-
木探索の展開: 各イテレーションで、システムは並列に展開する複数のノードを選択します。
- ノード選択: 確率的に「バグあり」ノードの修正を優先します。「バグなし」ノードについては、メトリクス、トレーニングダイナミクス、プロットの品質に基づいてノードを評価するLLMによってガイドされる最良優先探索(best-first search)戦略を使用します。
- 展開: 新しい子ノードが作成されます。親が「バグあり」だった場合、子は保存されたエラー/フィードバックを使用してデバッグを試みます。親が「バグなし」だった場合、子は実験の洗練または改善を試みます。LLMがこれらの新しいノードの計画/コードを生成します。
- 並列実行: 新しく作成されたすべてのノードは同時に実行され、v1の逐次アプローチと比較して探索が大幅に高速化されます。
-
特殊化されたノードタイプ: 木構造およびステージ内の特定の実験ニーズに合わせて調整されたノードバリアントが導入されています。
-
Hyperparameter Nodes(ステージ2): ハイパーパラメータ設定を体系的に探索し、冗長なチェックを回避します。 -
Ablation Nodes(ステージ4): 実験の根底にある特定のコンポーネントや仮定の重要性を評価し、テストされた条件を追跡します。 -
Replication Nodes: 異なるランダムシードを使用して親実験の複製を実行します。通常、実験結果の統計的指標(平均および標準偏差)の計算を可能にするために複数の複製ノードが作成され、結果の堅牢性が向上します。 -
Aggregation Nodes: 複製ノードの結合された結果を統合し、可視化するための特別なノードです。他のノードタイプとは異なり、集約ノードは新しい実験を行わず、単に以前の結果を集約して要約するPythonスクリプトを生成し、平均と標準偏差を明示的に示す図を作成します。
-
-
ノード定義: 各ノードは特定の実験を表し、以下を含みます:
3. Hugging Face Hubによるデータセット処理
ほとんどのML研究が標準データセットを使用していることを認識し、v2は可能な限りHugging Face Hub(datasets.load_dataset)を活用するようにされています。これにより、データセットへのアクセスが標準化および簡素化されますが、すべてのデータセットがそこで利用できるわけではないため、このアプローチはある程度アドホックであると論文はしています。
4. 強化された視覚言語モデル(VLM)レビュアー
v1とは異なり、v2は研究ワークフローの2つの重要なフェーズでVLM(GPT-4oなど)を組み込んでいます。
- 実験中: 上述のノード実行サイクルの一部として、VLMは生成された図がドラフトに入る前に、その品質と明瞭さについて即座にフィードバックを提供します。これにより、凡例の欠落や不明瞭なラベルなどの問題が早期に発見されます。
- 論文執筆中: 論文執筆のリフレクション(内省)フェーズで、システムは図、そのキャプション、および関連するテキスト参照を抽出します。VLMは品質チェックを実行します:キャプションは図と一致しているか?視覚的な明瞭さの問題はあるか?図が本文と付録で重複していないか?この反復的なフィードバックにより、最終的な原稿の視覚的な品質が大幅に向上します。
5. 論文執筆
論文執筆フェーズは、v1のインクリメンタルなAiderベースのアプローチと比較して簡素化されています。V2は、シングルパス生成アプローチを採用し、その後、OpenAIのo1のような強力な推論モデルを活用した別のリフレクションステージを実行します。システムは、(ワークショップの4ページ制限など)ターゲットとなるページ長をプロンプトとして与えられ、手動編集なしで最終的な出力が提出ガイドラインに準拠するようにします。
主要な結果
報告された最も印象的な結果は、AIが生成した原稿が正式な査読プロセスを成功裏に通過したことです。
実験:
- 設定: チームはAI Scientist-v2を使用して、ICLR 2025の「I Can't Believe It's Not Better」(ICBINB)ワークショップのテーマ(ネガティブな結果、予期せぬ発見、実世界の落とし穴に焦点を当てる)に沿った広範なトピックプロンプトに基づき、3つの完全な原稿を生成しました。
- 自律性: 初期の高レベルなトピック定義の後、各論文の全科学ワークフロー – 仮説形成、実験設計、コーディング、実行、分析、可視化、および論文執筆 – は、AI Scientist-v2によって自律的に実行されました。重要なのは、提出された原稿のコード、結果、図、または最終テキストを人間が一切編集しなかったこと。
-
人間の役割(メタセレクション): 人間はメタプロセスにおいて以下の役割があります。:
- 初期のワークショップテーマのプロンプトを提供すること。
- AIが生成した約20のアイデアの中から、有望な初期アイデアを3つ選択すること。
- 選択された各アイデアについて、完全なAI Scientist-v2パイプラインを(異なるシードで)複数回実行すること。
- これらの複数回の実行から、提出のための最良の完成原稿を1つ選択すること。これは、教授がどの学生プロジェクトが提出準備ができているかを選択するのに似ています。
- 査読: 3つのAI生成論文は、人間が執筆した論文とともにICBINBワークショップに提出されました(合計43件)。査読者は、一部の提出物がAI生成である可能性があることを事前に知らされ(そしてオプトアウトも可能でした)、しかしどれがそうであるかは知らされず、査読されました。
- 結果: 3つのAI生成原稿のうち1つが、査読者スコア6、6、および7(平均6.33/10)を獲得し、ワークショップの採択閾値を超えました。これは、提出物全体の上位約45%にランク付けされました。他の2つのAI生成論文は不採択となりました。
- 倫理的対応: ICLRのリーダーシップおよびワークショップ主催者との事前の合意に基づき(そしてIRBの承認を得て)、採択されたAI生成論文は、査読プロセス後、しかし出版前に取り下げられました。これは、より広範なコミュニティでの議論と合意なしに、純粋なAI生成研究が公式な科学記録に入るという前例を時期尚早に設定することを避けるために行われました。査読者には、レビュー完了後にのみ実験の性質について知らされました。
採択された論文:

- トピック: 特定の種類の「構成的正則化(compositional regularization)」(時間経過に伴う埋め込み表現の変化をペナルティ化する)を用いて、ニューラルシーケンスモデル(LSTM)が見たことのある要素の新しい組み合わせにどれだけうまく汎化するか(構成的汎化、compositional generalization)を改善できるかを調査しました。
- 手法: トレーニング中の損失関数に明示的な正則化項を追加することを提案しました。これを合成算術式データセット(例:「3+4」や「7*2」の評価)で評価しました。
- 発見(ネガティブな結果): 初期の仮説に反して、実験はこの特定の正則化手法が汎化性能を著しく改善せず、時にはパフォーマンスを損なうことさえあることを示しました。算術式の複雑さを増すと、正則化の有無にかかわらず、汎化性能は悪化しました。
- 意義: 論文は、この種の構成的構造を正則化によって単に強制することは十分ではないかもしれず、主要な学習目標と矛盾する可能性があると結論付けられる結果となりました。
査読者のフィードバック:
-
ワークショップ査読者(人間):
- 肯定的側面: 論文が重要な問題(構成的汎化)に取り組んでいること、ネガティブな結果を明確に提示していること(ワークショップのテーマに合致)、そして探求が洞察に富んでいることを評価しました。
- 改善点: 提案された正則化がなぜ機能するはずなのかについてのより明確な正当化や直感を要求し、実験がLSTMと合成データに限定されていることを指摘し(Transformerや実世界のタスクでの試行を提案)、正則化とタスクの複雑さとの関連性についてより明確な議論が必要だと感じました。ワークショップへの採択は推奨しましたが、主要な会議レベルにはさらなる作業が必要であると評価しました。
-
内部評価(論文著者):
- 肯定的側面: 時間的一貫性正則化の探求は興味深く、合成タスクは適切であることに同意しました。
- 弱点: 正則化項の記述が不明瞭(LSTMの隠れ状態でなく入力埋め込みに適用されると誤解される可能性がある)であること、重要な参考文献(オリジナルのLSTM論文など)が欠落していること、図のキャプションと分析に不正確さがあること(例:図5ではAttentionがLSTMを上回っているが、テキストでは同等と主張)、実験評価が限定的(短いシーケンス、合成データ)であることを見つけました。
- コードレビューの問題: データセットの重複の潜在的な問題(再生成テストで訓練セットとテストセット間に約57%の重複)、用語の混乱(「埋め込み状態」対「隠れ状態」)、そしてAttentionモデルの報告された100%精度の疑問(タスクの単純さによる可能性が高いと判断)を特定しました。
- 全体として: 技術的には健全であるが、ワークショップでの採択はボーダーラインであり、本格的な会議での採択にはより深い内容と厳密さが必要だと考えました。また、時折見られる「ハルシネーション(幻覚)」による引用(既知のLLMの問題)も指摘しました。
この詳細な評価は、能力(一貫性があり、査読に値するワークショップ論文を、興味深いがネガティブな結果とともに生成する能力)と現在の限界(深い新規性の欠如、時折の不正確さ、より良い正当化の必要性、トップレベルの人間の研究と比較した場合の実験範囲の限界)の両方を浮き彫りにしています。
実用的な意味合いとlimitation
意味合い:
- 科学の加速: AI Scientist-v2のようなシステムは、特に体系的な実験、アブレーションスタディ、既存のアイデアの結果を探求するといった、研究サイクルの特定の側面を劇的に加速させる可能性があります。
- 研究のスケーリング: 自動化により、研究グループは手動で行うよりもはるかに多くの仮説やパラメータ設定を探求できるようになるかもしれません。
- ネガティブな結果の探求: このシステムは、仮説を調査し、ネガティブな結果を一貫性を持って報告する能力を示しました。これは、人間主導の研究ではしばしば見過ごされがちですが、科学の進歩にとって不可欠です。ワークショップでの採択はこの能力を裏付けています。
- 複雑なワークフローの自動化: エージェントによる木探索と多段階管理アプローチは、科学研究以外の他の複雑な多段階プロセス、例えばソフトウェアエンジニアリング、設計、複雑なシステム分析などの自動化にも応用できる可能性があります。
- 民主化? このようなツールは、最終的に特定の種類の研究を行うための障壁を下げる可能性があるでしょうか(ただし、現在はかなりの計算資源と専門知識が必要です)?
limitation:
- ワークショップ対会議レベル: コンテキストを理解することが重要です。この論文はワークショップで査読を通過しました。ワークショップは通常、採択率が高く(60-80%)、予備的または焦点の絞られた結果に焦点を当てています。これに対し、トップティアの主要会議(ICLR本体、NeurIPS、ICMLなど、採択率20-30%)は、より高い新規性、厳密性、影響力を要求します。AI Scientist-v2は、まだ最高水準を満たす研究を一貫して生み出すには至っていません。
- 一貫性: 提出された3つの論文のうち1つしか採択されなかったことは、生成される出力の品質と堅牢性にばらつきがあることを示しています。
- 新規性と洞察: v2はよりオープンエンドなアイデアを目指していますが、真に斬新で影響力の大きい仮説を立て、画期的な実験方法論を設計することは、純粋に自動化されたシステムにとっては依然として困難であると論文は認めています。採択された論文は、既存の概念(正則化)を特定の方法で探求したものであり、パラダイムシフトを提案したわけではありません。深い専門知識と創造的な飛躍は、依然として人間中心であるように思われます。
- メタプロセスにおける人間の役割: 詳述したように、人間は依然として追求すべき初期アイデアの選択と、提出のための最終的な原稿ランの選択において重要な役割を果たしました。漠然としたテーマから、一切の人間の判断を介さずに提出される論文までの真のエンドツーエンドの自律性はまだ達成されていません。
- LLM/VLMの限界: システムは、事実誤認(引用における「ハルシネーション」)、バイアス、そして注意深いプロンプトエンジニアリングの必要性など、基盤となるモデルの限界を継承します。
- スケーラビリティとコスト: 完全なパイプライン、特に並列実行とノードごとの複数のLLM/VLM呼び出しを伴う木探索を実行することは、計算集約的です。
- 悪用の可能性: 能力が向上するにつれて、このようなシステムが低品質な論文で学会を溢れさせたり、査読システムをゲーム化したり、出版記録を人為的に水増ししたりするために使用されるリスクがあります。責任を持って管理されなければ、科学プロセスを損なう可能性があります。
倫理的考慮事項:
著者らは透明性と責任ある実験を強調しています。彼らはIRBの承認を得て、査読者にAI提出の可能性を通知し、オプトアウトを許可し、前例を設定する前にコミュニティの議論を促進するために、採択された論文を出版前に取り下げました。彼らは、AI生成コンテンツの明確なラベリングと、科学出版におけるAIの規範確立に関する継続的な対話を提唱しています。開示のタイミング(査読前か後か?)や、厳密さを維持しつつバイアスなくAIの研究を公正に評価する方法については、重要な疑問が残っています。
結論
AI Scientist-v2は、自動化された科学的発見における重要な一歩が示されました。人間が作成したテンプレートへの依存をなくし、実験マネージャーによって監督され、VLMフィードバックによって強化された洗練されたエージェントによる木探索手法を導入することで、先行バージョンよりも大幅に高い自律性と探索能力を実現しました。
権威あるMLワークショップで査読を通過した原稿を成功裏に生成したことは特筆すべきマイルストーンであり、AIが一貫性のある評価可能な研究成果の生成を含む、科学ワークフローのますます複雑な部分を扱えるようになっていることを示しています。
しかし、この研究はまた、現在のシステムの限界も明確に浮き彫りにしています。トップティアの会議出版に必要な厳密性、新規性、一貫性を達成することは、依然として大きな課題です。今後の道筋は、AIが真に画期的な仮説を生成する能力、より革新的な実験を設計する能力を向上させ、より大きな堅牢性と一貫性を確保し、AI生成科学の複雑な倫理的状況を乗り越えることにかかっています。
完全に自律的な「AIアインシュタイン」からはまだ程遠いかもしれませんが、AI Scientist-v2のようなシステムは、AIがますます人間と協力して発見のペースを加速させてくれることでしょう。
Call to Action: より深く知りたい方は、元の論文の[https://github.com/SakanaAI/AI-Scientist-v2]で公開されているオープンソース実装をしてみてください。
Discussion