RAG×グラフ:RGLが切り拓く次世代の検索拡張生成
RGL: A Graph-Centric, Modular Framework for Efficient Retrieval-Augmented Generation on Graphs
はじめに
RAG(Retrieval Augmented Generation)とは大規模言語モデル(LLM)が自身の訓練データだけに依存せず、外部データを取り込むことで、より正確で最新の応答を実現するというものです。通常、外部データはテキスト形式が一般的ですが、もしその情報が、ソーシャルネットワークやEコマース、引用データベース、ナレッジグラフのように複雑な関係性の中に埋もれていたらどうでしょう?
そんなときに威力を発揮するのが、グラフ検索拡張生成(RoG: RAG-on-Graphs) です。これは、グラフの構造—つまりノード、エッジ、接続関係—を活用して、LLMにとってより有益なコンテキストを効率的に検索しようというアプローチです。たとえば、ショッピングサイトにおけるユーザー行動に関する質問に答える場合や、研究論文ネットワークから関連性の高い内容を抽出して要約するようなケースで、RoGは非常に大きな可能性を秘めています。
しかし、これまでRoGを実用的に活用するのは容易ではありませんでした。従来のアプローチは固定的な構成が多く、特に大規模グラフを扱う際にはパフォーマンスの問題や膨大なエンジニアリングコストが壁となっていました。
この課題を解決するべく登場したのが、Yuan Li氏、Jun Hu氏、Jiaxin Jiang氏、Zemin Liu氏、Bryan Hooi氏、Bingsheng He氏による研究論文「RGL: A Graph-Centric, Modular Framework for Efficient Retrieval-Augmented Generation on Graphs」です。
彼らは、RGL(RAG-on-Graphs Library) というツールキットを提案しています。これは、RoGシステムをより効率的かつ柔軟に構築できるように設計された、開発者向けの強力なフレームワークです。RAGとグラフデータを活用する際の開発コストを大きく下げることを目的としています。
解決すべきコアの課題
RGLが取り組む問題は、グラフベースのRAGシステムの構築において開発者が直面しがちな、以下のような課題です。
-
硬直的な設計と限定的な適用範囲
多くの既存ツールは、特定のユースケース(例えば、ナレッジグラフ構築)を前提として設計されています。GraphRAGやLightRAGなどはテキストベースの入力を前提としており、ソーシャルグラフや推薦システムといった構造化グラフへの対応が困難です。コンポーネントの入れ替えや異なる形式への対応が難しく、応用範囲が限られてしまうのです。 -
実装コストの高さ
既存のツールが適合しない場合、RoGパイプライン全体をゼロから構築する必要があります。図1に示されるように、以下のステップが含まれます:- インデックス作成:ノードを効率的に検索できるよう整理
- ノード検索:クエリに関連するノードの抽出(意味ベースの検索も含む)
- グラフ検索:ノード周辺の構造を探索(近傍・パス・サブグラフなど)
- トークン化:検索結果をLLMが扱える形式に変換
- 生成:LLMへの入力と出力の生成
とくにグラフ検索部分の実装はコストが高く、アプリケーションロジックに集中できない原因になります。

-
パフォーマンスのボトルネック
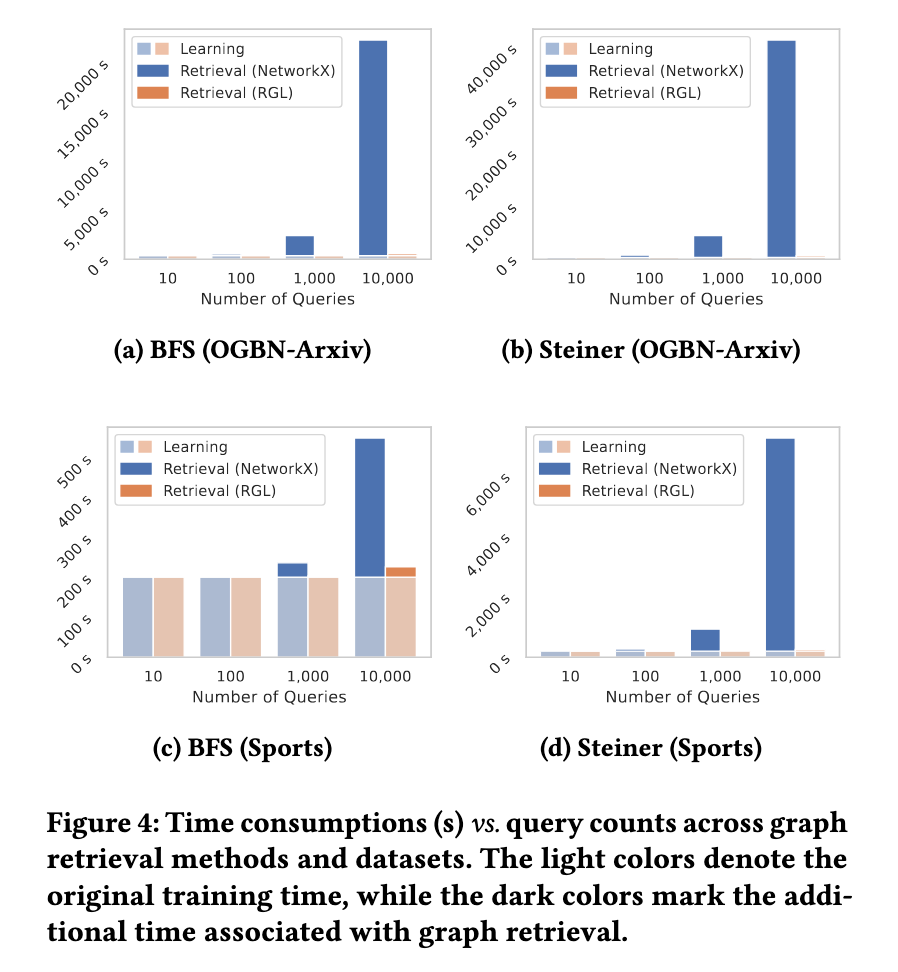
既存のライブラリ(例:NetworkX)を使った単純な実装では、大規模グラフでは極端に遅くなります。図2に示されている通り、クエリ数が増えると計算コストが急増し、学習処理よりも検索処理に時間がかかる事態すら発生します。

-
グラフデータベース分野の知見が活かされていない
RoGの領域では、長年の研究により確立されたグラフデータベース技術(最適化されたクエリ処理、インデックス作成)を十分に活用できていないのが現状です。
RGLの提案と構成
RGLは、単なるアルゴリズムではなく、RoGワークフロー全体をカバーする包括的かつモジュール型のフレームワークです。図3に示されているように、4つの主要コンポーネントにより構成されています:
- カーネル(中核ロジック)
- ランタイム(実行・管理)
- API(開発者インターフェース)
- アプリケーション(実証例)
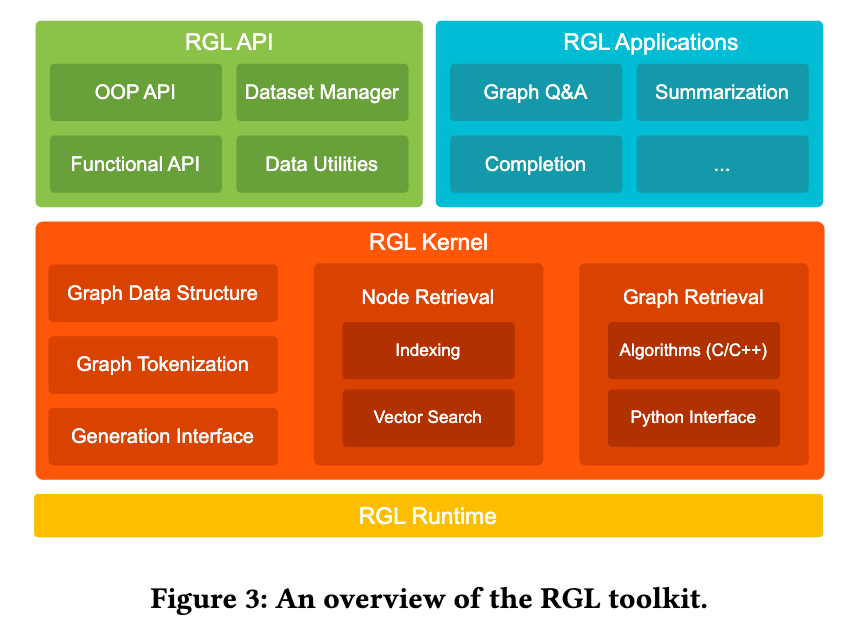
2.1 RGLカーネル:演算のエンジン
- グラフ構造管理:DGLやPyGとの互換性あり。再実装不要。
- 意味ベースのノード検索:ベクトル検索を用いて意味的に関連するノードを抽出。
- グラフ検索:BFSやSteiner Tree、Dense Subgraphなど複数のアルゴリズムに対応。計算コストの高い処理はC++で最適化されており、Pythonとはpybind11で接続。
- 生成インターフェース:グラフ構造をトークン化し、OpenAIやDeepSeekなどのLLMと連携。
2.2 RGLランタイム:全体の指揮官
リソース管理、キャッシング、並列化を担当し、GNNとの統合や分散処理の抽象化もサポート。
2.3 RGL API:開発者向けインターフェース
- OOP API:RoGの一連の流れをクラスで扱う。
- 関数型API:より柔軟にカスタムロジックを構築可能。
- データセットマネージャーも用意され、データ前処理や属性管理が容易。
2.4 RGLアプリケーション:すぐに使える実例
- 補完:欠損特徴量の補完に対応。
- 要約:グラフに基づく要約文の生成。
- Graph Q&A:構造に関する質問応答に対応。
主な成果と評価
3.1 効率性:RGL vs. NetworkX
- スケーラビリティの差:NetworkXはクエリが多いと極端に遅くなる(例:10,000クエリで11時間)。一方、RGLは同条件で5分未満。
-
オーバーヘッドの差:RGLはLLMの推論時間に対してほとんど影響を与えないが、NetworkXは主なボトルネックになる。
3.2 下流タスクでの性能評価
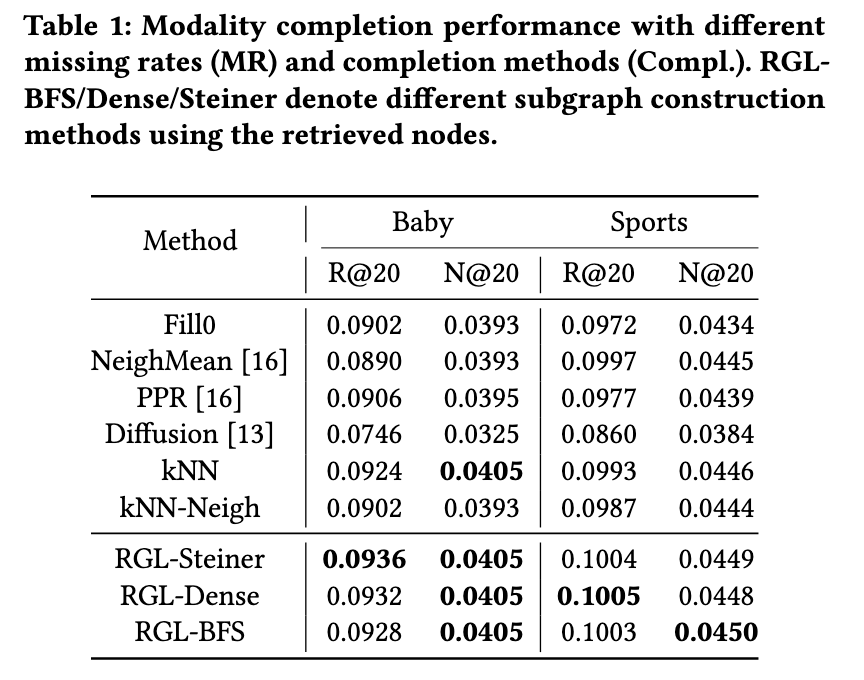
モダリティ補完(推薦システム)
- データセット:Baby、Sports
- 欠損率40%の条件下でも、RGLベースの手法が他のベースライン手法を全て上回る結果を達成(Recall@20、NDCG@20)。
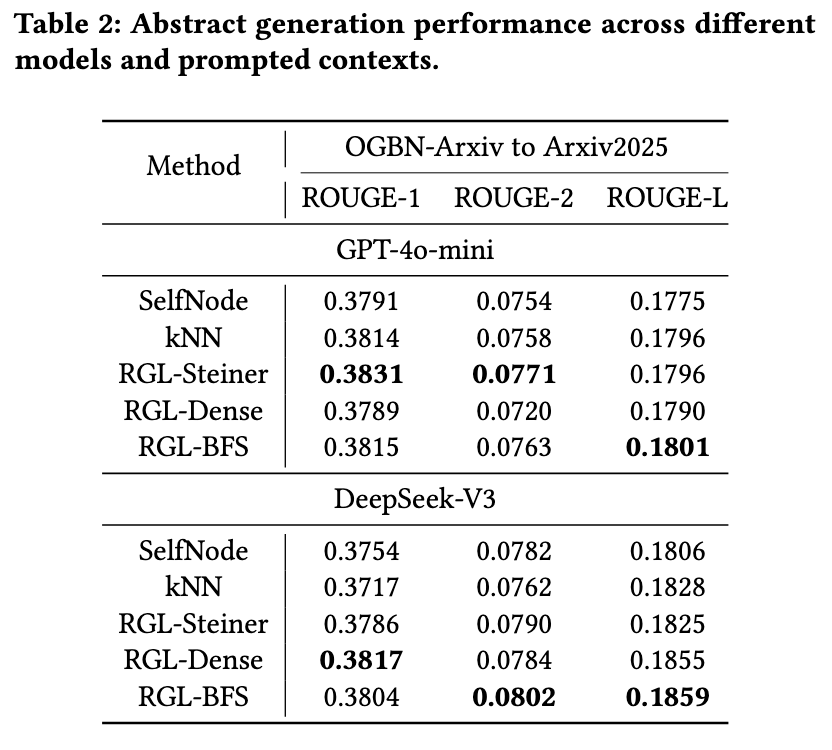
抄録生成(Arxiv論文)
- テストセット:2025年の新しい論文(ゼロショット設定)
- LLM:GPT-4o-mini, DeepSeek-V3
- RGLはどの検索手法を使ってもベースラインより良いROUGEスコアを達成。検索アルゴリズムの選択はLLMやタスクにより最適解が異なる可能性も示唆。
実用上の意義と限界
意義
- 迅速な開発:RGLのモジュール設計により、実装工数を大幅に削減。
- 柔軟性とカスタマイズ性:多様なドメインへの応用が可能。必要に応じてカスタムアルゴリズムも組み込み可能。
- コスト削減の可能性:精密なサブグラフ抽出により、トークン数を抑え、高コストなLLMの利用を最適化。
限界と今後の課題
実例の拡充、ユーザビリティ向上、さらなる大規模検証、グラフDBとの統合が今後の課題とされています。
結論
RoGは、構造化されたグラフ情報を活かしてLLMを強化する上で非常に有望な手法です。しかし、従来は技術的な障壁が高く、実用に至るのは困難でした。
RGLは、それらの障壁を取り払い、グラフ検索やトークン化といったパイプライン上のボトルネックを最適化し、RoG開発の高速化と高性能化を実現します。
構造化データとLLMを組み合わせた応用を考えているエンジニアにとって、RGLは頼れる基盤となるでしょう。
🔗 コードはこちら:https://github.com/PyRGL/rgl
📄 論文はこちら:[https://arxiv.org/pdf/2503.19314]
Discussion