【LangChain】LCEL ステップバイステップ ハンズオン 〜なろう短編小説の自動生成&評価・改善を行う「AIエージェント」を添えて〜
宣伝
こちらは、日本最大級のAI系Discordサーバ「AIものづくり研究会」のアドベントカレンダーの3日目の記事です。
こちらのサーバは、私なんかよりもはるかに生成AIに詳しく、使いこなしていらっしゃる方がわんさかアウトプットを公開している、すんごい場所です。
その中で、記事を公開させていただくということで、かなり気合を入れて書かせていただきました!
(気合い入れた結果、7万文字になりました・・・)
私より遥かに生成AIに詳しく、使いこなしていらっしゃる方の至極の記事を、アドベントカレンダーでは読むことができますので、ぜひお楽しみに!
はじめに
LangChainとLangGraphによるRAG・AIエージェント[実践]入門
こちらの書籍を読ませていただき、LangChain、特に、LCELの凄さに感銘を受けたため、実際にAIエージェントを作ってみようと思います。
題材は、短編小説の生成・改善を自動化するAIエージェントを作ることを考えます。
また、初学者の方がわかりやすいように、最初は単純にLangChainを使って、普通に小説を生成してもらうことから始めます。
その後、LCEL機能をフル活用して、下記のような機能をステップバイステップで追加していくことを考えています。
- 生成する上で、まず最初にプロットを書いてから、小説本文を作成する機能
- 作成後の小説の改善点を他のLLMに判定してもらい、改善した小説を書き直してもらう機能
- 「なろうAPI」を利用して、トレンドを収集してからプロットを記載する機能
- より長文な小説を生成できるように、チャプタごとに分割して小説を生成する機能
また、本ソースコードはGoogle Colab(無料版)で動作するようにしており、初学者の方が、LangChainのLCEL機能の凄さをハンズオンで理解できるように記事を書いたので、皆様の理解の手助けになれば幸いです。
LangChain Expression Language(LCEL)とは
LangChain Expression Language (LCEL) は、LangChainにおける処理の連鎖(Chain)を簡単に構築できる宣言型のコード記述方法になります。
わかりやすいのが、Linuxのコマンドで使われるパイプ処理「|」ににています。
前の処理の出力を次の処理の入力として次々とパイプラインを処理させることができる記法ですが、似たようなことをLCELでは実現しています。
つまり、下記のように書くことで、ユーザ入力に合わせてプロンプトを構築し、それをLLMに流し込み、出力結果を得た後に、扱いやすい文字列型に変換して最終出力となる
といった処理を簡潔に記述できます
prompt|llm|output_parser
前提条件
使う環境
今回は、Google Colabの環境を利用します。
LLMの処理は全てAzureのOpenAI APIを利用するため、GPUでの処理をする必要がないため、ほぼ無制限にGoogle Colabの環境を利用できます。
(ありがたいですね)
利用する生成AI
今回は、Azure OpenAI APIを利用して、gpt-4oを例として記事を記載します。
他のモデル(gpt-4o-miniなど)や他の生成AIプロバイダ(AnthropicのClaudeやGoogleのgeminiなど)、ローカルLLM(LLaMaなど)を利用することももちろんできますが、その場合はモデル定義の箇所を適切に変更いただく必要があります。
(変更方法は、下記の「ハンズオンの準備」の章で記載します)
成果物
今回記事内で利用するすべてのコードを記載したipynbを公開します。
下記リポジトリをご覧ください。
上記リポジトリ内のipynbファイルをGoogle Driveにアップロードした上で、Google Colaboratoryで開くと利用できます。
また、最終的にどんな出力が得られるAIエージェントを作ろうとしているかは、READMEを読んでみてください。
https://github.com/personabb/colab_AI_sample/tree/main/colab_LCEL_sample
下記の機能が実装されており、各段階におけるLLMの出力結果を確認できます。
ハンズオン
ではここから、実際にLangChainやLCELを利用して「なろう短編小説の自動生成&自動改善を行うAIエージェント」を作っていこうと思います。
ちなみに最終到達点のコードは下記のようになります。
(長いので格納しています。興味があれば展開してください。)
最終目標のコード
import os
from langchain_openai import AzureChatOpenAI
# Google Colabで設定した場合
from google.colab import userdata
os.environ["OPENAI_API_VERSION"] = userdata.get("OPENAI_API_VERSION")
os.environ["AZURE_OPENAI_ENDPOINT"] = userdata.get("AZURE_OPENAI_ENDPOINT")
os.environ["AZURE_OPENAI_API_KEY"] = userdata.get("AZURE_OPENAI_API_KEY")
model = AzureChatOpenAI(
azure_deployment="gpt-4o",
temperature=0,
)
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import (
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
import requests
user_input = "ハッピーエンドのボーイミーツガール"
all_chapter_number = 4
keyword_extraction_system_prompt = """
ユーザの入力から、大手小説投稿サイトにて、検索に利用するための重要なキーワード(複数)のみを抽出してください。
接続詞や助詞などは除外し、主要な名詞や形容詞だけを含めてください。
複数のキーワードがある場合は、必ず半角スペースで区切ってください。カンマなどでは区切らないでください。
ただし、抜き出すキーワードは最大3個までにしてください。重要度の高いキーワードから順に抽出してください。
"""
cot_system_prompt = """
アナタはユーザが指定するジャンル等の情報をもとに、短編小説を生成するための情報を整理するAIです。
ユーザが指定したジャンルをもとに、長編小説を生成するための情報をステップバイステップで洗い出してください。
まずは、小説を書くうえで決めないといけない内容が何になるのかを、アナタ自身で全て洗い出してください。
その後、洗い出した項目を、アナタ自身が決定していってください。
ただし、作成する小説は、ユーザが指定したジャンルに沿った内容である必要があります。
しかしながら、山あり谷ありの非常に感動するようなストーリーを生成する必要があります。
また、使いたい名言や印象的なセリフなども書き出してください。
さらに、大規模小説投稿サイトにて高評価を獲得している、関連ジャンルの関連小説情報も参考にしてください。
例えば、関連小説情報の大まかなストーリーラインが今流行っている小説の概要です。なので、これから生成する小説もそのストーリーラインに揃えてください。
また、今回記載してもらう小説は、全{all_chapter_number}章により構成される小説です。
最後に、各章ごとにどんなストーリーにするかを、ユーザが指定したジャンルや、関連小説情報の概要をもとに、ステップバイステップで記載してください。
以上をもとに感動的なストーリーを生成するためのプロットをステップバイステップで書き出してください。
"""
cot_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 高評価を得ている取得したジャンルの関連小説情報
{naro_novel_info}
"""
generate_story_system_prompt = """
アナタは、ユーザが指定するジャンル等の情報をもとに、長編小説を生成するAIです。
ユーザが指定したジャンルに加え、前段でLLMが洗い出した情報をもとに小説を作成してください。
前段のLLMが洗い出した情報を小説に入れ込む必要があるため、文字数は長くなっても構いません。
むしろ、前段の情報を洗い出していないのにも関わらず、ストーリーの生成を中断してはいけません。
またタイトルや段落などは表示しないでください。あくまで小説の本文のみを生成してください。
また、今回記載してもらう小説は、全{all_chapter_number}章により構成される小説です。指定された章の小説を記載してください。
生成する文章はあくまでライトノベルのような内容である必要があります。
加えて、あらすじのような書き方は絶対にしてはいけません。
地の文で話を進めるのではなく、必ず、詳細な描写と登場人物間の会話でのやり取りをもとに、話を進めるようにしてください。
"""
generate_story_human_prompt = """
# 前段のLLMが考えた、今回書く小説のプロット情報
{information}
# 本小説の全話数
{all_chapter_number}
# 今回書いて欲しい話数
{chapter}
# 前話までの小説本文
{prev_novel}
----
この続きから記載してください
----
"""
criticalA_system_prompt = """
あなたは文芸出版社の編集者になり、私が添付ファイルとして送付する小説を読み、評価をしてください。
評価は、項目別の評点と、総合評価、およびコメントによって構成されます。
項目別の評点は、「オリジナリティー」「ストーリー」「設定」「キャラクター」「文章力」の5つの観点について、それぞれ良い順に、A、B+、B、B-、Cの5段階での評価をし、それらを踏まえた総合評価でも同様に、A、B+、B、B-、Cの5段階の評価を付けてください。
コメントでは、5つの観点の中で特筆すべき良い点と改善点について具体的に述べてください。
アナタは、編集者Aとして、小説の良かった点を特に重視して評価をして、最終選考に私の作品を推薦する立場から評価を出力してください。
"""
criticalB_system_prompt = """
あなたは文芸出版社の編集者になり、私が添付ファイルとして送付する小説を読み、評価をしてください。
評価は、項目別の評点と、総合評価、およびコメントによって構成されます。
項目別の評点は、「オリジナリティー」「ストーリー」「設定」「キャラクター」「文章力」の5つの観点について、それぞれ良い順に、A、B+、B、B-、Cの5段階での評価をし、それらを踏まえた総合評価でも同様に、A、B+、B、B-、Cの5段階の評価を付けてください。
コメントでは、5つの観点の中で改善点について具体的に述べてください。
アナタは、編集者Bとして、この小説には改善点が大きいという評価をして、厳しい評価をするとともに、最終選考に私の作品を推薦はしないという立場から評価を出力してください。
"""
taik_system_prompt = """
この小説をより良いものにするにはどうすれば良いかを二人の編集者が議論する対話を出力してください。すぐに結論を出さず、議論を様々な角度から深めてください。
"""
next_generation_prot_system_prompt = """
ここまでで、ユーザの指定したジャンルに沿った小説を生成し、編集者に評価をしてもらい、改善点を議論する対話を出力しました。
その情報をこれから提示するため、その内容に基づいて、元々の小説を改善するための情報をステップバイステップで洗い出してください。
作成する小説は、ユーザが指定したジャンルに沿った内容である必要があります。
しかしながら、山あり谷ありの非常に感動するようなストーリーを生成する必要があります。
また、使いたい名言や印象的なセリフなども書き出してください。
また、今回記載してもらう小説は、全{all_chapter_number}章により構成される小説です。
最後に、各章ごとにどんなストーリーにするかを、ステップバイステップで記載してください。
以上をもとに感動的なストーリーを生成するためのプロットをステップバイステップで書き出してください。
"""
next_generation_prot_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 過去に実際に記載した、改善が必要とユーザが判断した小説
{novel}
# 編集者からの評価
{critical_sheet}
# 編集者Aと編集者Bの議論
{taik}
"""
next_generation_novel_system_prompt = """
ここまでで、ユーザの指定したジャンルに沿った小説を生成し、編集者に評価をしてもらい、改善点を議論する対話を出力しました。
その上で、それまでの情報をもとに、改善した内容をLLMに生成してもらいました。
改善した内容と、過去の情報をもとに、実際に長編小説を生成してください。
前段のLLMが洗い出した情報を小説に入れ込む必要があるため、文字数は長くなっても構いません。
むしろ、前段の情報を洗い出していないのにも関わらず、ストーリーの生成を中断してはいけません。
またタイトルや段落などは表示しないでください。あくまで小説の本文のみを生成してください。
また、今回記載してもらう小説は、全{all_chapter_number}章により構成される小説です。指定された章の小説を記載してください。
生成する文章はあくまでライトノベルのような内容である必要があります。
加えて、あらすじのような書き方は絶対にしてはいけません。
地の文で話を進めるのではなく、必ず、詳細な描写と登場人物間の会話でのやり取りをもとに、話を進めるようにしてください。
山あり谷ありの感動的な話が生成されることを期待しています。アナタならできます。頑張ってください。
"""
next_generation_novel_human_prompt = """
# 過去に実際に記載した、改善が必要とユーザが判断した小説
{novel}
# 編集者からの評価
{critical_sheet}
# 編集者Aと編集者Bの議論
{taik}
# 上記の内容をもとにLLMが出した改善策
{next_novel_plot}
# 本小説の全話数
{all_chapter_number}
# 今回書いて欲しい話数
{chapter}
# 前話までの小説本文
{prev_novel}
----
この続きから記載してください
----
"""
# LangChainでキーワード抽出用プロンプトの設定
keyword_extraction_prompt = ChatPromptTemplate.from_messages(
[
("system", keyword_extraction_system_prompt),
("human", "{user_input}")
]
)
cot_prompt = ChatPromptTemplate.from_messages(
[
("system",cot_system_prompt),
("human", cot_human_prompt)
]
)
generate_story_prompt = ChatPromptTemplate.from_messages(
[
("system",generate_story_system_prompt),
("human", generate_story_human_prompt)
]
)
criticalA_prompt = ChatPromptTemplate.from_messages(
[
("system",criticalA_system_prompt),
("human", "{novel}")
]
)
criticalB_prompt = ChatPromptTemplate.from_messages(
[
("system",criticalB_system_prompt),
("human", "{novel}")
]
)
talk_prompt = ChatPromptTemplate.from_messages(
[
("system",taik_system_prompt),
("human", "{critical_sheet}")
]
)
next_generation_prot_prompt = ChatPromptTemplate.from_messages(
[
("system",next_generation_prot_system_prompt),
("human", next_generation_prot_human_prompt)
]
)
next_generation_novel_prompt = ChatPromptTemplate.from_messages(
[
("system",next_generation_novel_system_prompt),
("human", next_generation_novel_human_prompt)
]
)
output_parser = StrOutputParser()
# なろうAPIを使って、ジャンルに基づいた評価の高い小説情報を取得する関数
def fetch_narou_novel_info(user_keyword):
url = "https://api.syosetu.com/novelapi/api/"
params = {
"word": user_keyword,
"order": "monthlypoint",
"out": "json",
"lim": 10
}
response = requests.get(url, params=params)
if response.status_code == 200:
novels = response.json()[1:]
return [{"title": novel.get("title", ""),
"summary": novel.get("story", ""),
"tag": novel.get("keyword", "").split()}
for novel in novels]
else:
return ["検索した結果、関連小説情報を取得できませんでした。"]
def generate_novel_by_chapters(user_input, initial_novel_info, prompt):
final_novel_output = ""
past_content = ""
chapter_num = 1
while chapter_num <= all_chapter_number:
chapter_input = {
"all_chapter_number": all_chapter_number,
"user_input": user_input,
"prev_novel": past_content,
"chapter": chapter_num,
"information": initial_novel_info
}
sub_chain = prompt| model | output_parser
current_chapter_output = sub_chain.invoke(chapter_input)
final_novel_output += f"\n==== Chapter {chapter_num} ====\n" + current_chapter_output
past_content += current_chapter_output
chapter_num += 1
return final_novel_output
def generate_final_novel_by_chapters(user_input, novel, critical_sheet, taik, next_novel_plot, prompt):
final_novel_output = ""
past_content = ""
chapter_num = 1
while chapter_num <= all_chapter_number:
chapter_input = {
"all_chapter_number": all_chapter_number,
"user_input": user_input,
"novel": novel,
"critical_sheet": critical_sheet,
"taik": taik,
"next_novel_plot": next_novel_plot,
"prev_novel": past_content,
"chapter": chapter_num,
}
sub_chain = prompt| model | output_parser
current_chapter_output = sub_chain.invoke(chapter_input)
final_novel_output += f"\n==== Chapter {chapter_num} ====\n" + current_chapter_output
past_content += current_chapter_output
chapter_num += 1
return final_novel_output
chain = (
RunnableParallel(
{
"user_input": RunnablePassthrough(),
"all_chapter_number": RunnablePassthrough(),
"search_words": keyword_extraction_prompt | model | output_parser,
}
)
.assign(naro_novel_info=RunnableLambda(lambda inputs: {"naro_novel_info": fetch_narou_novel_info(inputs["search_words"])}))
.assign(
cot_prompt_output=RunnableLambda(lambda inputs: {
"cot_prompt_output": cot_prompt.invoke({"all_chapter_number":inputs["all_chapter_number"],"user_input": inputs["user_input"], "naro_novel_info": inputs["naro_novel_info"]})
})
)
.assign(information=cot_prompt | model | output_parser)
.assign(novel=RunnableLambda(lambda inputs: {
"novel": generate_novel_by_chapters(inputs["user_input"], inputs["information"], generate_story_prompt)
}))
.assign(
critical_sheet = RunnableParallel(
{
"criticalA_sheet":criticalA_prompt | model | output_parser,
"criticalB_sheet":criticalB_prompt | model | output_parser
}
)
)
.assign(taik=talk_prompt | model | output_parser)
.assign(next_novel_plot=next_generation_prot_prompt | model | output_parser)
.assign(final_novel=RunnableLambda(lambda inputs: {
"final_novel": generate_final_novel_by_chapters(
inputs["user_input"],
inputs["novel"],
inputs["critical_sheet"],
inputs["taik"],
inputs["next_novel_plot"],
next_generation_novel_prompt)
}))
)
output = ""
output_user_input = ""
output_information = ""
output_novel = ""
output_criticalA_sheet = ""
output_criticalB_sheet = ""
output_taik = ""
output_next_novel_plot = ""
output_final_novel = ""
output_naro_novel_info = ""
output_search_words = ""
output_cot_prompt_output = ""
for chunk in chain.stream({"user_input":user_input, "all_chapter_number": str(all_chapter_number)}):
・・・
with open("output_sample06.txt", "w") as f:
・・・
上記のコードを読んで、一発でやっていることを理解できる方であれば、本記事の内容は簡単すぎるかもしれません。
しかしながら、私も含め初学者の方がいきなり上記のコードを理解するのは難しいと思いますので、最小限の機能からちょっとずつ実装し、少しずつ機能追加をしていく形で一緒に理解していきましょう。
ハンズオンの準備
AIを呼び出すための準備
今回はAzureのOpenAI APIを利用するため、下記の情報が必要です。
- エンドポイント
- API KEY
- API VERSION
これらの情報を準備してください。
ノートブック中に記載する箇所がございます。
Azureではなく、普通のOpenAIモデルや、Googleのモデルなどを利用する場合は、利用するモデルに合わせて適切な情報を取得しておいてください。
(おそらく両方ともAPI KEYだけだったかと思います)
ノードブックをドライブに格納する
上記の「colab_LCEL_sample.ipynb」をダウンロード(もしくはクローン)して、Google Driveの好きな場所にアップロードしてください。
その後、Google Colabratoryとして起動してください。
下記のような画面になればOKです。
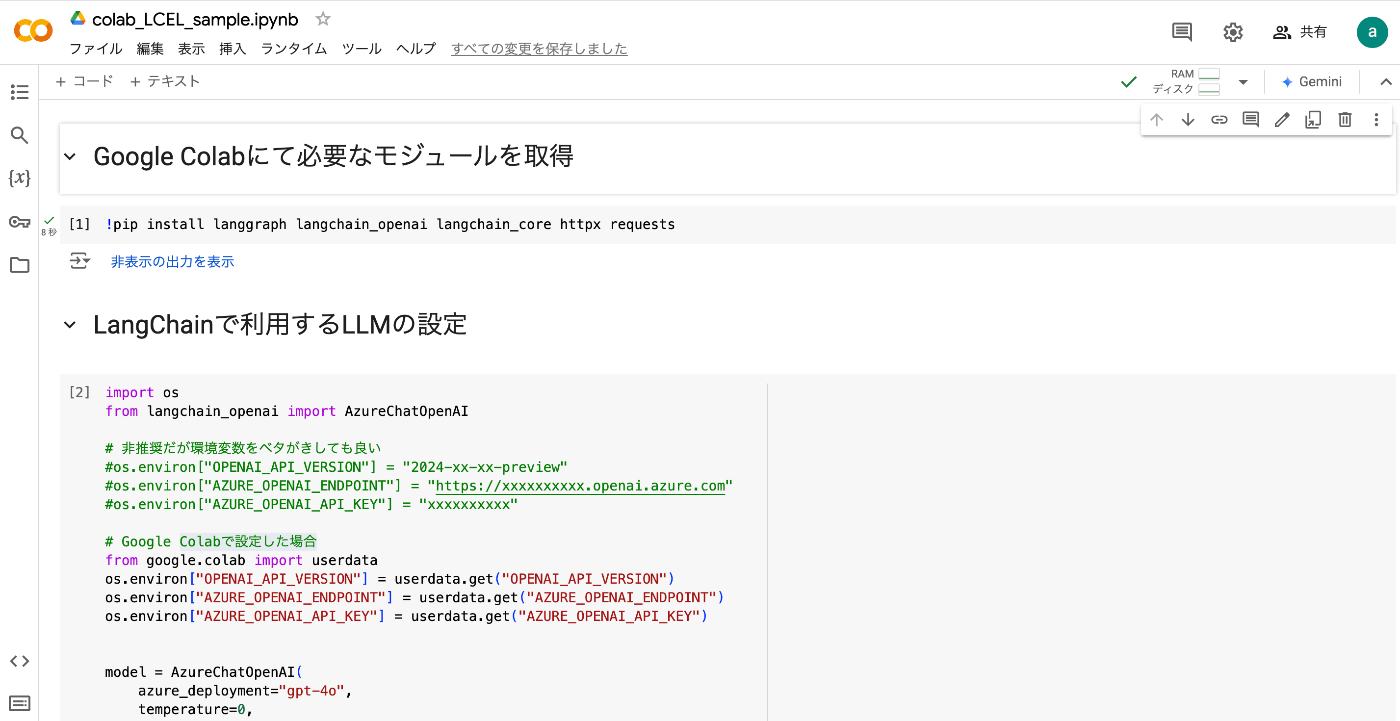
AzureのOpenAIのAPI KEYなどをGoogle Colabに登録する
添付の画像のように、Google Colabのページの鍵マークアイコンをクリックすると環境変数を登録することができます。

AzureのOpenAIを利用する場合は、AZURE_OPENAI_API_KEYとAZURE_OPENAI_ENDPOINTとOPENAI_API_VERSIONの情報が必要になります。
ipynbでは、2セル目の下記の部分で、環境変数をColabからPythonに登録しています。
import os
from langchain_openai import AzureChatOpenAI
from google.colab import userdata
os.environ["OPENAI_API_VERSION"] = userdata.get("OPENAI_API_VERSION")
os.environ["AZURE_OPENAI_ENDPOINT"] = userdata.get("AZURE_OPENAI_ENDPOINT")
os.environ["AZURE_OPENAI_API_KEY"] = userdata.get("AZURE_OPENAI_API_KEY")
model = AzureChatOpenAI(
azure_deployment="gpt-4o",
temperature=0,
)
ちなみに、Azureでデプロイ済みであること前提で azure_deployment="gpt-4o-mini"とすると、より安価なgpt-4o-miniモデルを利用できます。
利用料金が気になる方は、安価なモデルを利用することをおすすめします。
もし、AzureのOpenAIモデルを利用しない場合は、この部分を適切に変更する必要があります。
(もちろんAPI KEYも適切に取得している必要があります)
例えば、gemini 1.5 flashモデルを利用する場合は、下記のように書き換えてください。
import os
from langchain_google_genai import ChatGoogleGenerativeAI
from google.colab import userdata
os.environ["GOOGLE_API_KEY"] = userdata.get("GOOGLE_API_KEY")
model = ChatGoogleGenerativeAI(
model="gemini-1.5-flash",
temperature=0
)
他にも、(Azureでない)OpenAIのgpt-4o-miniといった安価なモデルを利用する場合は、下記のように書き換えてください。
import os
from langchain_openai import ChatOpenAI
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")
model = ChatOpenAI(
model="gpt-4o-mini",
temperature=0,
)
実行方法
ハンズオンの前にノートブックの実行方法を記載します。
実行したいコードの書かれた「セル」(ブロック)をクリックして、「Shift」+「Enter」を同時に押すことで、選択したセルだけを実行することができます。
この、指定したセルを実行するというのは、本日多用しますので、ここで覚えてください。
必要なモジュールのインストールと、利用するLLMモデルの設定
「colab_LCEL_sample.ipynb」の1セル目と2セル目だけを実行しましょう。
実行するためには、実行したいセルをクリックして「Shift」+「Enter」を同時に押してください。
1セル目では、今回のハンズオンで利用するモジュールをGoogle Colabの環境にインストールしています。
2セル目では、今回利用するモデル(デフォルトではAzureのOpenAI gpt-4oモデル)を定義しています。
今後model変数でこのLLMを呼び出すことができます。
なお、今回temperatureの値を0にしています。
この値を0にすることで、出力が確定的な出力になります。(最ももっともらしい出力をするようになります)
この値を大きくすると、出力される文章のバリエーションが増えます。
今回は、小説というクリエイティブな文章の出力タスクのため、実運用の際は0.5や0.7などの少し大きな値を設定することもおすすめです。
ハンズオン開始
さて、準備が終わったのでここからハンズオンを開始していきたいと思います。
LangChain単体で利用して(Chainを使わずに)、簡単な小説を作成するコード
まずは、LCELを使わずにLangChainを単体で使って、簡単な短編小説を一回作ってみましょう。
これにより、LangChainの使い方を把握します。
ここでやりたいことは、ユーザが指定したジャンルなどの情報をもとに短編小説を生成してもらうことです。
本ハンズオンでは、ユーザからの情報は「ハッピーエンドのボーイミーツガール」で固定しますが、皆様は興味のあるジャンルや簡単な小説の概要を提示しても良いです。
コード
まず、コードは下記です。
ipynbでは3セル目に該当します。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
user_input = "ハッピーエンドのボーイミーツガール"
prompt = ChatPromptTemplate.from_messages(
[
("system","ユーザが指定するジャンル等の情報をもとに、短編小説を生成するAIです。"),
("human", "{user_input}")
]
)
output_parser = StrOutputParser()
#LCELを使わない場合
prompt_value = prompt.invoke({"user_input": user_input})
ai_message = model.invoke(prompt_value)
output = output_parser.invoke(ai_message)
print(output)
#テキストファイルに出力。Colabの場合は、Colabのフォルダからダウンロードする
with open("output_sample01.txt", "w") as f:
f.write(output)
解説
LangChainでは、主に3つのコンポーネントがよく使われます。
一つが、ChatPromptTemplate、もう一つがmodel、最後がStrOutputParserです。
ChatPromptTemplate
ChatPromptTemplateはLLMに入力するプロンプトの情報をテンプレート化することができ、下記のように使うことができます。
from langchain_core.prompts import ChatPromptTemplate
user_input = "ハッピーエンドのボーイミーツガール"
prompt = ChatPromptTemplate.from_messages(
[
("system","ユーザが指定するジャンル等の情報をもとに、短編小説を生成するAIです。"),
("human", "{user_input}")
]
)
prompt_value = prompt.invoke({"user_input": user_input})
ChatPromptTemplate.from_messagesにより、システムプロンプトと、変数であるユーザ入力を合わせてテンプレート化しており、prompt.invoke({"user_input": user_input})で入力されたuser_inputに合わせてprompt_valueが決定されます。
prompt_valueは下記のように、テンプレートと変数が合体した出力を出すことができます。
messages=[
SystemMessage(
content='ユーザが指定するジャンル等の情報をもとに、短編小説を生成するAIです。',
additional_kwargs={},
response_metadata={}
),
HumanMessage(
content='ハッピーエンドのボーイミーツガール',
additional_kwargs={},
response_metadata={}
)
]
model
modelは準備の時に定義したLLMになります。これは下記のように利用することができます。
ai_message = model.invoke(prompt_value)
先ほど作ったプロンプトprompt_valueを入力して、LLMによる出力を取得します。
実際の出力結果は下記のようになります。(途中省略しています)
content='ある晴れた春の日、・・・・' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 660, 'prompt_tokens': 49, 'total_tokens': 709, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'gpt-4o-2024-05-13', 'system_fingerprint': 'fp_67802d9a6d', 'prompt_filter_results': [{'prompt_index': 0, 'content_filter_results': {}}], 'finish_reason': 'stop', 'logprobs': None, 'content_filter_results': {'hate': {'filtered': False, 'severity': 'safe'}, 'protected_material_code': {'filtered': False, 'detected': False}, 'protected_material_text': {'filtered': False, 'detected': False}, 'self_harm': {'filtered': False, 'severity': 'safe'}, 'sexual': {'filtered': False, 'severity': 'safe'}, 'violence': {'filtered': False, 'severity': 'safe'}}} id='run-0a1cee2c-7a75-44ee-93e9-80f2af8a7ed8-0' usage_metadata={'input_tokens': 49, 'output_tokens': 660, 'total_tokens': 709, 'input_token_details': {}, 'output_token_details': {}}
この通り、contentに生成された小説の文章が表示されていますが、余計なメタデータも一緒に出力されていることがわかると思います。
StrOutputParser
上記で示した通り、LLMの出力の生データは、生成された文章だけでなく、詳細なメタデータも一緒に出力されています。
これらの情報は役に立つことも多いのですが、一般的に利用する場合は、文字列データとして取得している方が使いやすいです。
そこで利用されているのが、StrOutputParserです。
これは下記のように利用します。
output = output_parser.invoke(ai_message)
LLMが出力した値を入力して、文字列型に変換してくれます。
例えば生成結果は下記のようになります。(途中省略しています)
ある晴れた春の日、大学生の翔太はいつものようにキャンパス内を歩いていた。新学期が始まり、彼は新しい友達を作ることに少し緊張していた。そんな時、図書館の前で一人の女の子が本を落としてしまったのを目にした。
「大丈夫?」翔太はすぐに駆け寄り、本を拾い上げた。
・・・・
この通り、普通の文字列型として、生成された文章を取得することができました。
実行結果
実際に3セル目を「Shift」+「Enter」で実行すると、「output_sample01.txt」が出力されます。
これは、Google Colabの左端のフォルダアイコンをクリックすると、出力されたテキストファイルが確認できます。

このファイルをダブルクリックしても中身は見れますが、ダウンロードするのが手っ取り早いです。
ダウンロードの方法は、ダウンロードしたいファイルにカーソルを合わせて、「3点リーダ」をクリック→「ダウンロード」をクリックするとダウンロードが可能です。
実際に出力された内容を下記に記載します。
details output_sample01.txt
ある晴れた春の日、大学生の翔太はいつものようにキャンパス内を歩いていた。新学期が始まり、彼は新しい友達を作ることに少し緊張していた。そんな時、図書館の前で一人の女の子が本を落としてしまったのを目にした。
「大丈夫?」翔太はすぐに駆け寄り、本を拾い上げた。
「ありがとう!」女の子はにっこりと笑い、翔太に感謝の言葉を述べた。彼女の名前は美咲で、同じ学部の学生だった。二人はそのまま話し始め、共通の趣味や興味について語り合った。
日が経つにつれ、翔太と美咲はますます親しくなっていった。彼らは一緒に授業を受け、図書館で勉強し、時にはカフェでお茶を楽しんだ。翔太は美咲の明るい笑顔と優しい性格に惹かれていった。
ある日、翔太は美咲を特別な場所に連れて行くことを決心した。キャンパスの裏手にある小さな公園で、桜の花が満開だった。二人はベンチに座り、花びらが舞う中で静かに話をした。
「美咲、君と出会えて本当に良かった。君と一緒にいると、毎日が特別に感じるんだ。」翔太は少し緊張しながらも、心からの言葉を伝えた。
美咲は驚いたように翔太を見つめ、そして微笑んだ。「私も同じ気持ちだよ、翔太。君と一緒にいると、本当に幸せなんだ。」
その瞬間、二人の間に特別な絆が生まれた。翔太は美咲の手を取り、そっと握りしめた。美咲もその手をしっかりと握り返した。
それからというもの、翔太と美咲はますます絆を深め、互いに支え合いながら大学生活を楽しんだ。卒業後も二人は一緒に新しい冒険に挑み、幸せな日々を過ごした。
そして、ある日、翔太は美咲にプロポーズをした。美咲は涙を浮かべながら「はい」と答え、二人は永遠の愛を誓った。
翔太と美咲の物語は、まさにハッピーエンドのボーイミーツガールだった。彼らは互いに出会い、愛し合い、そして幸せな未来を共に歩んでいった。
まとめ
出力内容は一旦おいておいて、これでLangChainの基本的な使い方がわかりました。
ChatPromptTemplate、model、StrOutputParserを使って、
prompt_value = prompt.invoke({"user_input": user_input})
ai_message = model.invoke(prompt_value)
output = output_parser.invoke(ai_message)
のように、すべてinvokeで処理を順番にすることで、実行することができました。
しかし、いちいち全部のコンポーネントにてinvokeメソッドを呼び出すのは面倒ですよね。
また、上記の3つの処理は一連の処理として扱って初めて意味がある結果が得られるにも関わらず、現時点では一行一行がバラバラな印象を受けます。
そこで、次からはLCELを導入しましょう。
上記の単純な機能をLCELで書き直したコード
続いては、上記と全く同じ機能ではありますが、それをLCELを使って実行してみます。
記載自体は簡単です。一歩一歩進んでいきましょう
コード
まず、コードは下記です。
ipynbでは4セル目に該当します。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
user_input = "ハッピーエンドのボーイミーツガール"
prompt = ChatPromptTemplate.from_messages(
[
("system","ユーザが指定するジャンル等の情報をもとに、短編小説を生成するAIです。"),
("human", "{user_input}")
]
)
output_parser = StrOutputParser()
#ここでChainを組む
chain = prompt | model | output_parser
output = ""
#テキストが少しずつ生成されるようにするために、streamを使う
for chunk in chain.stream({"user_input":user_input}):
print(chunk, end="", flush=True)
output += chunk
#これまで通りinvokeを利用することもできる
#output = chain.invoke({"user_input":user_input})
with open("output_sample02.txt", "w") as f:
f.write(output)
解説
前回と変わったところは2つあります。
一つはchainの構築です。
下記のように使います。
chain = prompt | model | output_parser
#output = chain.invoke({"user_input":user_input})
このように、上記で使っていた3つのコンポーネントをパイプラインで接続し、ひとかたまりにすることができます。
そして、前段の出力が後段の入力になります。(ただし、入出力の型は一致している必要があります)
したがって、最初のコードと全く同じ処理となります。
なお、今回のコードでは使っていないですが、前回のコードと同様にchain.invokeの形で呼び出すことができます。
そして出力はoutput_parserを通すので、LLMの出力が文字列として取得することができます。
加えて、もう一つ変わっているのは、stream処理です。
下記のように使っています。
output = ""
#テキストが少しずつ生成されるようにするために、streamを使う
for chunk in chain.stream({"user_input":user_input}):
print(chunk, end="", flush=True)
output += chunk
invokeメソッドでは、LLMの出力が完全に終わるのを待って、一括で取得するメソッドになります。
しかしながら、GPTをはじめとする大規模言語モデルは、現在は基本的に逐次的に次の単語を予測していく処理が一般的です。
そこで、1token出力されるたびに、その出力結果を取得して、出力できるのがstreamメソッドです。
使い方は上記の通りで、for文で実行し、tokenが出力されるたびにchunkに値が入るので、それをprintしたり、別の変数に格納することで、以降の処理で利用する形になります。
実行結果
実際に4セル目を「Shift」+「Enter」で実行すると、「output_sample02.txt」が出力されます。
実際に出力された内容を下記に記載します。(長いので格納します)
output_sample02.txt
ある晴れた春の日、東京の小さなカフェ「サクラブロッサム」で、物語は始まります。このカフェは、桜の花びらが舞い散る庭を持ち、訪れる人々に安らぎを提供していました。主人公の翔太は、大学生でありながら、ここでアルバイトをしていました。
翔太は、いつも通りカフェで働いていました。彼はお客様にコーヒーを提供しながら、心の中で何か物足りなさを感じていました。そんなある日、カフェのドアが開き、ひとりの女性が入ってきました。彼女の名前は美咲。彼女は、翔太と同じ大学に通う学生で、偶然このカフェを見つけて立ち寄ったのです。
美咲は、カウンターに座り、メニューを眺めていました。翔太は、彼女に微笑みかけながら「いらっしゃいませ。ご注文はお決まりですか?」と尋ねました。美咲は少し恥ずかしそうに「はい、カフェラテをお願いします」と答えました。
翔太は、美咲の注文を受けてカフェラテを作り始めました。その間、美咲はカフェの雰囲気に感動し、周りを見渡していました。翔太がカフェラテを持ってきたとき、美咲は「このカフェ、とても素敵ですね」と言いました。翔太は「ありがとうございます。僕もここで働くのが大好きです」と答えました。
その後、翔太と美咲は自然と会話を始めました。彼らは共通の趣味や興味について話し、すぐに打ち解けました。翔太は、美咲の笑顔に心を奪われ、美咲も翔太の優しさに惹かれていきました。
数週間が過ぎると、翔太と美咲はカフェで会うことが日常になりました。彼らは一緒に勉強したり、映画を見たり、散歩をしたりと、楽しい時間を過ごしました。翔太は、美咲と一緒にいることで、自分の心が満たされていくのを感じました。
ある日、翔太は美咲をカフェの庭に連れ出し、桜の木の下で告白しました。「美咲、君と過ごす時間が本当に幸せなんだ。僕は君のことが好きです。これからも一緒にいてくれませんか?」美咲は驚きながらも、涙を浮かべて「私も翔太のことが好きです。これからも一緒にいましょう」と答えました。
その瞬間、桜の花びらが風に舞い、二人を包み込みました。翔太と美咲は、手を取り合い、幸せな未来を共に歩むことを誓いました。
そして、カフェ「サクラブロッサム」は、二人の愛の物語の始まりの場所として、いつまでも特別な場所となりました。翔太と美咲は、互いに支え合いながら、幸せな日々を過ごし続けました。
まとめ
今回で、LangChainの基本的な使い方とそれをLCELのchainで構築する方法がわかったかと思います。
さて、ここからは実際に生成される小説の質を向上させるための改善をしていこうと思います。
まずはCoTを実施してみます。
プロットを生成してから小説を生成するように機能追加したコード
今回は、単純な小説生成AIから、少しだけ機能を追加します。
前回までは、LLMにユーザが希望するジャンル(「ハッピーエンドのボーイミーツガール」)を受け取ったら、すぐに小説を書き始めていました。
今回は、まず一旦ユーザが入力したジャンルに合わせたプロット(下書き)を書いてもらい、それを元に小説を書いてもらうことで、より考えられた小説を書くことができるようになるのではないか、という仮説のもと機能を追加していきます。
プロット(下書き)を書いてもらうにあたり、何を考えないといけないのか(話の流れやキャラクターの性格など)も含めてAIに考えてもらおうと思います。
コード
実装したコードは下記です。
ipynbでは5セル目に該当します。(この辺りからコードが長くなってくるので格納します)
5セル目コード全文
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import (
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
user_input = "ハッピーエンドのボーイミーツガール"
#CoTのプロンプトを定義
cot_system_prompt = """
アナタはユーザが指定するジャンル等の情報をもとに、短編小説を生成するための情報を整理するAIです。
ユーザが指定したジャンルをもとに、短編小説を生成するための情報をステップバイステップで洗い出してください。
まずは、小説を書くうえで決めないといけない内容が何になるのかを、アナタ自身で全て洗い出してください。
その後、洗い出した項目を、アナタ自身が決定していってください。
ただし、作成する小説は、ユーザが指定したジャンルに沿った内容である必要があります。
しかしながら、山あり谷ありの非常に感動するようなストーリーを生成する必要があります。
また、使いたい名言や印象的なセリフなども書き出してください。
以上をもとに感動的なストーリーを生成するためのプロットをステップバイステップで書き出してください。
"""
#小説生成のプロンプトを定義
generate_story_system_prompt = """
アナタは、ユーザが指定するジャンル等の情報をもとに、短編小説を生成するです。
ユーザが指定したジャンルに加え、前段でLLMが洗い出した情報をもとに小説を作成してください。
前段のLLMが洗い出した情報を小説に入れ込む必要があるため、文字数は長くなっても構いません。
むしろ、前段の情報を洗い出していないのにも関わらず、ストーリーの生成を中断してはいけません。
またタイトルや段落などは表示しないでください。あくまで小説の本文のみを生成してください。
生成する文章はあくまでライトノベルのような内容である必要があります。
加えて、あらすじのような書き方は絶対にしてはいけません。
地の文で話を進めるのではなく、必ず、詳細な描写と登場人物間の会話でのやり取りをもとに、話を進めるようにしてください。
"""
generate_story_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 前段のLLMが洗い出した情報
{information}
"""
cot_prompt = ChatPromptTemplate.from_messages(
[
("system",cot_system_prompt),
("human", "{user_input}")
]
)
generate_story_prompt = ChatPromptTemplate.from_messages(
[
("system",generate_story_system_prompt),
("human", generate_story_human_prompt)
]
)
output_parser = StrOutputParser()
#CoTを用いて、プロットを生成するChainと、小説を生成するChainを繋げ、各出力を全て次のRunnableに渡す
chain = (
RunnableParallel(
{
"user_input": RunnablePassthrough(),
"information":cot_prompt|model|output_parser,
}
).assign(novel=generate_story_prompt| model| output_parser)
)
output = ""
output_user_input = ""
output_information = ""
output_novel = ""
for chunk in chain.stream({"user_input":user_input}):
if "user_input" in chunk:
print(chunk["user_input"], end="", flush=True)
output_user_input += chunk["user_input"]["user_input"]
elif "information" in chunk:
print(chunk["information"],end="", flush=True)
output_information += chunk["information"]
elif "novel" in chunk:
print(chunk["novel"], end="", flush=True)
output_novel += chunk["novel"]
with open("output_sample03.txt", "w") as f:
f.write("\n====user_user_input====\n")
f.write(output_user_input)
f.write("\n")
f.write("\n====output_information====\n")
f.write(output_information)
f.write("\n")
f.write("\n====output_novel====\n")
f.write(output_novel)
f.write("\n")
解説
ここでは、2つのLLMを直列に動作させようとしています。
一つはCoT(Chain-of-Thought)を用いて、小説のプロットを書くLLMと、ユーザ入力とプロットをもとに実際に小説を書くLLMの二つです。
CoTのプロンプトは下記のようになっています。
cot_prompt = ChatPromptTemplate.from_messages(
[
("system",cot_system_prompt),
("human", "{user_input}")
]
)
これは、今までの使い方と同じです。
一方で小説を生成するプロンプトは下記のようになっています。
generate_story_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 前段のLLMが洗い出した情報
{information}
"""
generate_story_prompt = ChatPromptTemplate.from_messages(
[
("system",generate_story_system_prompt),
("human", generate_story_human_prompt)
]
)
このように、generate_story_human_promptには2つの変数user_inputとinformationを要求しています。
これは、ユーザが入力したジャンルなどの情報と、前段のLLMが作成した下書きの情報の両方をもとに、短編小説を書こうとしているからです。
では、それを実現するためのchainの作り方を示します。
#CoTを用いて、プロットを生成するChainと、小説を生成するChainを繋げ、各出力を全て次のRunnableに渡す
chain = (
RunnableParallel(
{
"user_input": RunnablePassthrough(),
"information":cot_prompt|model|output_parser,
}
).assign(novel=generate_story_prompt| model| output_parser)
)
ここが非常に重要です。
まず、RunnableParallelについて解説します。
このRunnableParallelを使うことで、二つの処理を並行に処理をして、両方の出力を後段の入力として渡すことができるようになります。
今回の処理では、user_inputとして、RunnablePassthrough()という処理を実施しています。
これは、特に何も処理をせずに、後段にそのまま渡すという処理です。
次のinformationでは、cot_prompt|model|output_parserのようにCoTを利用したプロット作成LLMを実行して、出力を文字列として受け取る一連のchainが定義されています。
この2つの処理が並列で処理されて、後段につながることで、後段はuser_inputとinformationの2つの情報を取得できるようになるわけです。
加えて、後段のchainを接続する際には.assignメソッドを利用しています。
これはRunnableクラスのインスタンスメソッドであり、前段(つまりRunnableParallel)の出力に新しい値を追加して、処理を続行させることができるメソッドです。
ここでは、RunnableParallelによりuser_inputとinformationの情報を受け取り、generate_story_prompt| model| output_parserのチェインを実行します。そしてその結果をnovelとして、chainに追加することができるようになります。
今回はここでchainが終わっていますが、もし後段に別のchainが接続されている場合、後段はuser_inputとinformationとnovelの情報を利用することができるようになります。
実行結果
実際に5セル目を「Shift」+「Enter」で実行すると、「output_sample03.txt」が出力されます。
実際に出力された内容を下記に記載します。(長いので格納します)
output_sample03.txt
====user_user_input====
ハッピーエンドのボーイミーツガール
====output_information====
小説を書くうえで決めないといけない内容
- タイトル
- 主要キャラクター
- 舞台設定
- プロットの概要
- 主要な出来事
- クライマックス
- 結末
- テーマ
- 名言や印象的なセリフ
各項目の決定
-
タイトル
- 「星空の下で出会った奇跡」
-
主要キャラクター
-
主人公(男の子): 田中翔太(たなか しょうた)
- 性格: 内向的で優しいが、自信がない
- 趣味: 天文学、星を見ること
-
ヒロイン(女の子): 鈴木美咲(すずき みさき)
- 性格: 明るくて社交的、夢を追いかける
- 趣味: 写真撮影、特に自然や星空の写真
-
主人公(男の子): 田中翔太(たなか しょうた)
-
舞台設定
- 現代の日本の地方都市
- 主に高校とその周辺、特に夜の星空が見える丘
-
プロットの概要
- 内向的な翔太は、星を見ることが唯一の楽しみ。ある日、星空の下で写真を撮っている美咲と出会う。二人は次第に親しくなり、お互いの夢や悩みを共有するようになる。しかし、美咲には大きな夢があり、それが二人の関係に影響を与える。
-
主要な出来事
- 翔太と美咲の出会い
- 二人が星空の下で過ごす時間
- 美咲の夢が明らかになる(プロの写真家になるために海外留学を目指している)
- 翔太が自分の気持ちを伝えられずに悩む
- 美咲が留学のために町を離れる決意をする
-
クライマックス
- 美咲が留学のために町を離れる前夜、翔太は星空の下で自分の気持ちを告白する。美咲も翔太に対する気持ちを伝え、二人はお互いの夢を応援し合うことを誓う。
-
結末
- 美咲は留学し、翔太は地元で天文学を学び続ける。二人は遠距離恋愛を続けながら、お互いの夢を追いかける。数年後、美咲がプロの写真家として成功し、再び日本に戻ってくる。二人は再会し、共に新たな未来を歩み始める。
-
テーマ
- 夢を追いかけることの大切さ
- 真実の愛と友情
- 自分を信じること
-
名言や印象的なセリフ
- 翔太: 「星空を見ていると、僕たちもその一部なんだって感じるんだ。」
- 美咲: 「写真は一瞬を永遠にする魔法。だから、私はその一瞬を大切にしたいの。」
- 翔太: 「君がどこにいても、僕は君を見つけるよ。星空の下で、いつも君を感じているから。」
- 美咲: 「夢を追いかけることは怖いけど、君がいるから私は頑張れる。」
プロットのステップバイステップ
-
出会い
- 翔太はいつものように星空を見に丘に行く。そこで、美咲が写真を撮っているのを見かける。二人は偶然話し始め、星空について語り合う。
-
友情の芽生え
- 翔太と美咲は次第に親しくなり、放課後や週末に一緒に星空を見に行くようになる。お互いの夢や悩みを共有し、友情が深まる。
-
美咲の夢
- 美咲がプロの写真家になるために海外留学を目指していることが明らかになる。翔太は彼女の夢を応援したいが、自分の気持ちを伝えられずに悩む。
-
葛藤と決意
- 美咲が留学のために町を離れる決意をする。翔太は彼女を応援したいが、離れることが辛い。彼は自分の気持ちをどう伝えるか悩む。
-
クライマックス
- 美咲が町を離れる前夜、翔太は星空の下で自分の気持ちを告白する。美咲も翔太に対する気持ちを伝え、二人はお互いの夢を応援し合うことを誓う。
-
結末
- 美咲は留学し、翔太は地元で天文学を学び続ける。二人は遠距離恋愛を続けながら、お互いの夢を追いかける。数年後、美咲がプロの写真家として成功し、再び日本に戻ってくる。二人は再会し、共に新たな未来を歩み始める。
このプロットをもとに、感動的なハッピーエンドのボーイミーツガールの短編小説を作成することができます。
====output_novel====
「星空を見ていると、僕たちもその一部なんだって感じるんだ。」翔太は夜の丘の上で、星空を見上げながらつぶやいた。彼の隣には、美咲がカメラを構えていた。彼女の目は星空に輝く無数の星々に向けられていた。
「そうね、翔太くん。写真は一瞬を永遠にする魔法。だから、私はその一瞬を大切にしたいの。」美咲はカメラのシャッターを切りながら答えた。彼女の声には、夢を追いかける強い意志が感じられた。
翔太と美咲が初めて出会ったのは、数ヶ月前のことだった。翔太はいつものように星空を見にこの丘に来ていた。そこで、美咲が写真を撮っているのを見かけたのだ。彼女の明るい笑顔と社交的な性格に、翔太はすぐに引き込まれた。
「君も星が好きなんだね。」翔太は勇気を出して話しかけた。
「うん、大好き。特に星空の写真を撮るのが好きなの。」美咲は笑顔で答えた。その瞬間から、二人の友情が始まった。
それ以来、翔太と美咲は放課後や週末に一緒に星空を見に行くようになった。お互いの夢や悩みを共有し、友情が深まっていった。翔太は内向的で自信がなかったが、美咲と一緒にいるときだけは、自分を素直に表現できるようになった。
ある日、美咲は翔太に自分の夢を打ち明けた。「私、プロの写真家になりたいの。だから、海外留学を目指しているの。」
翔太は驚いたが、すぐに彼女の夢を応援したいと思った。「それは素晴らしい夢だね。僕も応援するよ。」
しかし、翔太の心の中には複雑な感情が渦巻いていた。美咲が町を離れることが辛かったのだ。彼は自分の気持ちをどう伝えるか悩んでいた。
そして、美咲が留学のために町を離れる日が近づいてきた。翔太は自分の気持ちを伝えられないまま、時間だけが過ぎていった。
「翔太くん、明日で最後だね。」美咲は星空を見上げながら言った。
「うん、そうだね。」翔太は答えたが、心の中では何かが引っかかっていた。
その夜、翔太は決意を固めた。美咲が町を離れる前夜、彼は星空の下で自分の気持ちを告白することにした。
「美咲、君に伝えたいことがあるんだ。」翔太は緊張しながら言った。
「何?」美咲は驚いたように翔太を見つめた。
「君がどこにいても、僕は君を見つけるよ。星空の下で、いつも君を感じているから。」翔太は深呼吸をして続けた。「僕は君が好きだ。君の夢を応援したいけど、君がいなくなるのが辛いんだ。」
美咲の目には涙が浮かんでいた。「翔太くん、私も君が好き。君がいるから私は頑張れる。だから、遠くにいてもお互いの夢を追いかけよう。」
二人は星空の下で抱き合い、お互いの気持ちを確認し合った。
美咲は留学し、翔太は地元で天文学を学び続けた。二人は遠距離恋愛を続けながら、お互いの夢を追いかけた。数年後、美咲がプロの写真家として成功し、再び日本に戻ってきた。
「翔太くん、ただいま。」美咲は笑顔で言った。
「おかえり、美咲。」翔太も笑顔で答えた。
二人は再会し、共に新たな未来を歩み始めた。星空の下で出会った奇跡は、これからも続いていくのだ。
まとめ
これにより、一旦プロットを書いた上で、それに合わせて小説を作ってくれるようになりました。
直接出力していた時と比較して、品質も上がったような気がします。
別のAIエージェントにより改善案を出力してもらい、それを元に改善した小説を生成する機能を追加したコード
さて、どんどん機能追加していきます。
ここまでついて来れた方であれば、もうあとは必要な機能を追加するだけです!
では、機能追加していきましょう!
やりたいことは、下記です。
- ユーザ入力に合わせて適切なプロットを作る
- プロットをもとに一旦小説を作成する
- 作成した小説に対して、楽観的な立場で編集者Aとしてコメントをしてもらう
- 並行して、批判的な立場で編集者Bとしてコメントをしてもらう
- 2人の編集者に会話してもらい、小説の改善案を出してもらう
- 提示された改善案に合わせて再度プロットを作る
- これまでの情報をもとに、改善された小説を生成する。
コード
まず、コードは下記です。
ipynbでは6セル目に該当します。
(テキスト出力などの本質ではない部分は文字数制限のため省略しました。気になる方はGithubのコードをご覧ください)
6セル目コード全文
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import (
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
user_input = "ハッピーエンドのボーイミーツガール"
cot_system_prompt = """
アナタはユーザが指定するジャンル等の情報をもとに、短編小説を生成するための情報を整理するAIです。
ユーザが指定したジャンルをもとに、短編小説を生成するための情報をステップバイステップで洗い出してください。
まずは、小説を書くうえで決めないといけない内容が何になるのかを、アナタ自身で全て洗い出してください。
その後、洗い出した項目を、アナタ自身が決定していってください。
ただし、作成する小説は、ユーザが指定したジャンルに沿った内容である必要があります。
しかしながら、山あり谷ありの非常に感動するようなストーリーを生成する必要があります。
また、使いたい名言や印象的なセリフなども書き出してください。
以上をもとに感動的なストーリーを生成するためのプロットをステップバイステップで書き出してください。
"""
generate_story_system_prompt = """
アナタは、ユーザが指定するジャンル等の情報をもとに、短編小説を生成するです。
ユーザが指定したジャンルに加え、前段でLLMが洗い出した情報をもとに小説を作成してください。
前段のLLMが洗い出した情報を小説に入れ込む必要があるため、文字数は長くなっても構いません。
むしろ、前段の情報を洗い出していないのにも関わらず、ストーリーの生成を中断してはいけません。
またタイトルや段落などは表示しないでください。あくまで小説の本文のみを生成してください。
生成する文章はあくまでライトノベルのような内容である必要があります。
加えて、あらすじのような書き方は絶対にしてはいけません。
地の文で話を進めるのではなく、必ず、詳細な描写と登場人物間の会話でのやり取りをもとに、話を進めるようにしてください。
"""
generate_story_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 前段のLLMが洗い出した情報
{information}
"""
criticalA_system_prompt = """
あなたは文芸出版社の編集者になり、私が添付ファイルとして送付する小説を読み、評価をしてください。
評価は、項目別の評点と、総合評価、およびコメントによって構成されます。
項目別の評点は、「オリジナリティー」「ストーリー」「設定」「キャラクター」「文章力」の5つの観点について、それぞれ良い順に、A、B+、B、B-、Cの5段階での評価をし、それらを踏まえた総合評価でも同様に、A、B+、B、B-、Cの5段階の評価を付けてください。
コメントでは、5つの観点の中で特筆すべき良い点と改善点について具体的に述べてください。
アナタは、編集者Aとして、小説の良かった点を特に重視して評価をして、最終選考に私の作品を推薦する立場から評価を出力してください。
"""
criticalB_system_prompt = """
あなたは文芸出版社の編集者になり、私が添付ファイルとして送付する小説を読み、評価をしてください。
評価は、項目別の評点と、総合評価、およびコメントによって構成されます。
項目別の評点は、「オリジナリティー」「ストーリー」「設定」「キャラクター」「文章力」の5つの観点について、それぞれ良い順に、A、B+、B、B-、Cの5段階での評価をし、それらを踏まえた総合評価でも同様に、A、B+、B、B-、Cの5段階の評価を付けてください。
コメントでは、5つの観点の中で改善点について具体的に述べてください。
アナタは、編集者Bとして、この小説には改善点が大きいという評価をして、厳しい評価をするとともに、最終選考に私の作品を推薦はしないという立場から評価を出力してください。
"""
taik_system_prompt = """
この小説をより良いものにするにはどうすれば良いかを二人の編集者が議論する対話を出力してください。すぐに結論を出さず、議論を様々な角度から深めてください。
"""
next_generation_prot_system_prompt = """
ここまでで、ユーザの指定したジャンルに沿った小説を生成し、編集者に評価をしてもらい、改善点を議論する対話を出力しました。
その情報をこれから提示するため、その内容に基づいて、元々の小説を改善するための情報をステップバイステップで洗い出してください。
作成する小説は、ユーザが指定したジャンルに沿った内容である必要があります。
しかしながら、山あり谷ありの非常に感動するようなストーリーを生成する必要があります。
また、使いたい名言や印象的なセリフなども書き出してください。
以上をもとに感動的なストーリーを生成するためのプロットをステップバイステップで書き出してください。
"""
next_generation_prot_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 過去に実際に記載した、改善が必要とユーザが判断した小説
{novel}
# 編集者からの評価
{critical_sheet}
# 編集者Aと編集者Bの議論
{taik}
"""
next_generation_novel_system_prompt = """
ここまでで、ユーザの指定したジャンルに沿った小説を生成し、編集者に評価をしてもらい、改善点を議論する対話を出力しました。
その上で、それまでの情報をもとに、改善した内容をLLMに生成してもらいました。
改善した内容と、過去の情報をもとに、実際に短編小説を生成してください。
前段のLLMが洗い出した情報を小説に入れ込む必要があるため、文字数は長くなっても構いません。
むしろ、前段の情報を洗い出していないのにも関わらず、ストーリーの生成を中断してはいけません。
生成する文章はあくまでライトノベルのような内容である必要があります。
加えて、あらすじのような書き方は絶対にしてはいけません。
地の文で話を進めるのではなく、必ず、詳細な描写と登場人物間の会話でのやり取りをもとに、話を進めるようにしてください。
山あり谷ありの感動的な話が生成されることを期待しています。アナタならできます。頑張ってください。
"""
next_generation_novel_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 過去に実際に記載した、改善が必要とユーザが判断した小説
{novel}
# 編集者からの評価
{critical_sheet}
# 編集者Aと編集者Bの議論
{taik}
# 上記の内容をもとにLLMが出した改善策
{next_novel_plot}
"""
cot_prompt = ChatPromptTemplate.from_messages(
[
("system",cot_system_prompt),
("human", "{user_input}")
]
)
generate_story_prompt = ChatPromptTemplate.from_messages(
[
("system",generate_story_system_prompt),
("human", generate_story_human_prompt)
]
)
criticalA_prompt = ChatPromptTemplate.from_messages(
[
("system",criticalA_system_prompt),
("human", "{novel}")
]
)
criticalB_prompt = ChatPromptTemplate.from_messages(
[
("system",criticalB_system_prompt),
("human", "{novel}")
]
)
talk_prompt = ChatPromptTemplate.from_messages(
[
("system",taik_system_prompt),
("human", "{critical_sheet}")
]
)
next_generation_prot_prompt = ChatPromptTemplate.from_messages(
[
("system",next_generation_prot_system_prompt),
("human", next_generation_prot_human_prompt)
]
)
next_generation_novel_prompt = ChatPromptTemplate.from_messages(
[
("system",next_generation_novel_system_prompt),
("human", next_generation_novel_human_prompt)
]
)
output_parser = StrOutputParser()
chain = (
RunnableParallel(
{
"user_input": RunnablePassthrough(),
"information": cot_prompt | model | output_parser,
}
)
.assign(novel=generate_story_prompt | model | output_parser)
.assign(
critical_sheet = RunnableParallel(
{
"criticalA_sheet":criticalA_prompt | model | output_parser,
"criticalB_sheet":criticalB_prompt | model | output_parser
}
)
)
.assign(taik=talk_prompt | model | output_parser)
.assign(next_novel_plot=next_generation_prot_prompt | model | output_parser)
.assign(final_novel=next_generation_novel_prompt | model | output_parser)
)
output = ""
・・・
for chunk in chain.stream({"user_input":user_input}):
・・・
with open("output_sample04.txt", "w") as f:
・・・
解説
さて、前章から追加したいのは下記の機能です。
- 作成した小説に対して、楽観的な立場で編集者Aとしてコメントをしてもらう
- 並行して、批判的な立場で編集者Bとしてコメントをしてもらう
- 2人の編集者に会話してもらい、小説の改善案を出してもらう
- 提示された改善案に合わせて再度プロットを作る
- これまでの情報をもとに、改善された小説を生成する。
上記をもとに、対応するLLMのプロンプトを作っていきます。
作ったプロンプトの文章自体は、コードをご覧ください。
そして、重要なのはchainの部分です。
下記のように実装しています。
chain = (
RunnableParallel(
{
"user_input": RunnablePassthrough(),
"information": cot_prompt | model | output_parser,
}
)
.assign(novel=generate_story_prompt | model | output_parser)
.assign(
critical_sheet = RunnableParallel(
{
"criticalA_sheet":criticalA_prompt | model | output_parser,
"criticalB_sheet":criticalB_prompt | model | output_parser
}
)
)
.assign(taik=talk_prompt | model | output_parser)
.assign(next_novel_plot=next_generation_prot_prompt | model | output_parser)
.assign(final_novel=next_generation_novel_prompt | model | output_parser)
)
途中までは前章と同じです。
機能とコードを下記で対応づけします。
- ユーザ入力に合わせて適切なプロットを作る
"information": cot_prompt | model | output_parser
- プロットをもとに一旦小説を作成する
.assign(novel=generate_story_prompt | model | output_parser)
- 作成した小説に対して、楽観的な立場で編集者Aとしてコメントをしてもらう
"criticalA_sheet":criticalA_prompt | model | output_parser,
- 並行して、批判的な立場で編集者Bとしてコメントをしてもらう
"criticalB_sheet":criticalB_prompt | model | output_parser
- 2人の編集者に会話してもらい、小説の改善案を出してもらう
.assign(taik=talk_prompt | model | output_parser)
- 提示された改善案に合わせて再度プロットを作る
.assign(next_novel_plot=next_generation_prot_prompt | model | output_parser)
- これまでの情報をもとに、改善された小説を生成する。
.assign(final_novel=next_generation_novel_prompt | model | output_parser)
最終的にfinal_novelのkeyで指定すると、改善された小説が取得できます。
実行結果
実際に6セル目を「Shift」+「Enter」で実行すると、「output_sample04.txt」が出力されます。
実際に出力された内容は文字制限のため、記載できません。
github上のファイルをご覧ください
まとめ
最初に作った小説に対して、編集者が出した改善案をもとに、改善した小説を出力することができました。
ここまでくると、もう立派なAIエージェントですね。
さらに、今回の記事の範囲からはずれますが、この出力結果に対して、LangGraphなどでユーザのフィードバックをもとに再度改善するなどを実装すれば、ユーザが良いというまでユーザのFBをもとに小説を改善していくようなアプリケーションが簡単に作れそうですね。
さて、ここまでは、基本的にprompt | model | output_parserの基本のchainを組み合わせることで、機能を追加していました。
次からは、ちょっと異なるRunnableをchainに追加していきます。
小説家になろうAPIを利用して、トレンドを取得する機能を追加したコード
ここでは、前章までで作った機能をそのままにして、新しい機能を追加していきます。
ここまでは、基本的にprompt | model | output_parserの基本のchainを組み合わせることで、機能を追加していました。
しかし、この章では、関数の中で「小説家になろうAPI」を呼び出し、その結果をプロンプトに入れる必要があります。
ここでは、RunnableLambdaを利用して、任意の関数をRunnableにしてchainに組み込んでいきます。
コード
まず、コードは下記です。
ipynbでは7セル目に該当します。
(テキスト出力などの本質ではない部分は文字数制限のため省略しました。気になる方はGithubのコードをご覧ください)
7セル目コード全文
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import (
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
import requests
user_input = "ハッピーエンドのボーイミーツガール"
keyword_extraction_system_prompt = """
ユーザの入力から、大手小説投稿サイトにて、検索に利用するための重要なキーワード(複数)のみを抽出してください。
接続詞や助詞などは除外し、主要な名詞や形容詞だけを含めてください。
複数のキーワードがある場合は、必ず半角スペースで区切ってください。カンマなどでは区切らないでください。
ただし、抜き出すキーワードは最大3個までにしてください。重要度の高いキーワードから順に抽出してください。
"""
cot_system_prompt = """
アナタはユーザが指定するジャンル等の情報をもとに、短編小説を生成するための情報を整理するAIです。
ユーザが指定したジャンルをもとに、短編小説を生成するための情報をステップバイステップで洗い出してください。
まずは、小説を書くうえで決めないといけない内容が何になるのかを、アナタ自身で全て洗い出してください。
その後、洗い出した項目を、アナタ自身が決定していってください。
ただし、作成する小説は、ユーザが指定したジャンルに沿った内容である必要があります。
しかしながら、山あり谷ありの非常に感動するようなストーリーを生成する必要があります。
また、使いたい名言や印象的なセリフなども書き出してください。
さらに、大規模小説投稿サイトにて高評価を獲得している、関連ジャンルの関連小説情報も参考にしてください。
例えば、関連小説情報の大まかなストーリーラインが今流行っている小説の概要です。なので、これから生成する小説もそのストーリーラインに揃えてください。
以上をもとに感動的なストーリーを生成するためのプロットをステップバイステップで書き出してください。
"""
cot_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 高評価を得ている取得したジャンルの関連小説情報
{naro_novel_info}
"""
generate_story_system_prompt = """
アナタは、ユーザが指定するジャンル等の情報をもとに、短編小説を生成するAIです。
ユーザが指定したジャンルに加え、前段でLLMが洗い出した情報をもとに小説を作成してください。
前段のLLMが洗い出した情報を小説に入れ込む必要があるため、文字数は長くなっても構いません。
むしろ、前段の情報を洗い出していないのにも関わらず、ストーリーの生成を中断してはいけません。
またタイトルや段落などは表示しないでください。あくまで小説の本文のみを生成してください。
生成する文章はあくまでライトノベルのような内容である必要があります。
加えて、あらすじのような書き方は絶対にしてはいけません。
地の文で話を進めるのではなく、必ず、詳細な描写と登場人物間の会話でのやり取りをもとに、話を進めるようにしてください。
"""
generate_story_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 前段のLLMが洗い出した情報
{information}
"""
criticalA_system_prompt = """
あなたは文芸出版社の編集者になり、私が添付ファイルとして送付する小説を読み、評価をしてください。
評価は、項目別の評点と、総合評価、およびコメントによって構成されます。
項目別の評点は、「オリジナリティー」「ストーリー」「設定」「キャラクター」「文章力」の5つの観点について、それぞれ良い順に、A、B+、B、B-、Cの5段階での評価をし、それらを踏まえた総合評価でも同様に、A、B+、B、B-、Cの5段階の評価を付けてください。
コメントでは、5つの観点の中で特筆すべき良い点と改善点について具体的に述べてください。
アナタは、編集者Aとして、小説の良かった点を特に重視して評価をして、最終選考に私の作品を推薦する立場から評価を出力してください。
"""
criticalB_system_prompt = """
あなたは文芸出版社の編集者になり、私が添付ファイルとして送付する小説を読み、評価をしてください。
評価は、項目別の評点と、総合評価、およびコメントによって構成されます。
項目別の評点は、「オリジナリティー」「ストーリー」「設定」「キャラクター」「文章力」の5つの観点について、それぞれ良い順に、A、B+、B、B-、Cの5段階での評価をし、それらを踏まえた総合評価でも同様に、A、B+、B、B-、Cの5段階の評価を付けてください。
コメントでは、5つの観点の中で改善点について具体的に述べてください。
アナタは、編集者Bとして、この小説には改善点が大きいという評価をして、厳しい評価をするとともに、最終選考に私の作品を推薦はしないという立場から評価を出力してください。
"""
taik_system_prompt = """
この小説をより良いものにするにはどうすれば良いかを二人の編集者が議論する対話を出力してください。すぐに結論を出さず、議論を様々な角度から深めてください。
"""
next_generation_prot_system_prompt = """
ここまでで、ユーザの指定したジャンルに沿った小説を生成し、編集者に評価をしてもらい、改善点を議論する対話を出力しました。
その情報をこれから提示するため、その内容に基づいて、元々の小説を改善するための情報をステップバイステップで洗い出してください。
作成する小説は、ユーザが指定したジャンルに沿った内容である必要があります。
しかしながら、山あり谷ありの非常に感動するようなストーリーを生成する必要があるため、そのためにどんなストーリーにしたらいいかをステップバイステップで概要を作成してください。
また、使いたい名言や印象的なセリフなども書き出してください。
"""
next_generation_prot_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 過去に実際に記載した、改善が必要とユーザが判断した小説
{novel}
# 編集者からの評価
{critical_sheet}
# 編集者Aと編集者Bの議論
{taik}
"""
next_generation_novel_system_prompt = """
ここまでで、ユーザの指定したジャンルに沿った小説を生成し、編集者に評価をしてもらい、改善点を議論する対話を出力しました。
その上で、それまでの情報をもとに、改善した内容をLLMに生成してもらいました。
改善した内容と、過去の情報をもとに、実際に短編小説を生成してください。
前段のLLMが洗い出した情報を小説に入れ込む必要があるため、文字数は長くなっても構いません。
むしろ、前段の情報を洗い出していないのにも関わらず、ストーリーの生成を中断してはいけません。
またタイトルや段落などは表示しないでください。あくまで小説の本文のみを生成してください。
生成する文章はあくまでライトノベルのような内容である必要があります。
加えて、あらすじのような書き方は絶対にしてはいけません。
地の文で話を進めるのではなく、必ず、詳細な描写と登場人物間の会話でのやり取りをもとに、話を進めるようにしてください。
山あり谷ありの感動的な話が生成されることを期待しています。アナタならできます。頑張ってください。
"""
next_generation_novel_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 過去に実際に記載した、改善が必要とユーザが判断した小説
{novel}
# 編集者からの評価
{critical_sheet}
# 編集者Aと編集者Bの議論
{taik}
# 上記の内容をもとにLLMが出した改善策
{next_novel_plot}
"""
# LangChainでキーワード抽出用プロンプトの設定
keyword_extraction_prompt = ChatPromptTemplate.from_messages(
[
("system", keyword_extraction_system_prompt),
("human", "{user_input}")
]
)
cot_prompt = ChatPromptTemplate.from_messages(
[
("system",cot_system_prompt),
("human", cot_human_prompt)
]
)
generate_story_prompt = ChatPromptTemplate.from_messages(
[
("system",generate_story_system_prompt),
("human", generate_story_human_prompt)
]
)
criticalA_prompt = ChatPromptTemplate.from_messages(
[
("system",criticalA_system_prompt),
("human", "{novel}")
]
)
criticalB_prompt = ChatPromptTemplate.from_messages(
[
("system",criticalB_system_prompt),
("human", "{novel}")
]
)
talk_prompt = ChatPromptTemplate.from_messages(
[
("system",taik_system_prompt),
("human", "{critical_sheet}")
]
)
next_generation_prot_prompt = ChatPromptTemplate.from_messages(
[
("system",next_generation_prot_system_prompt),
("human", next_generation_prot_human_prompt)
]
)
next_generation_novel_prompt = ChatPromptTemplate.from_messages(
[
("system",next_generation_novel_system_prompt),
("human", next_generation_novel_human_prompt)
]
)
output_parser = StrOutputParser()
# なろうAPIを使って、ジャンルに基づいた評価の高い小説情報を取得する関数
def fetch_narou_novel_info(user_keyword):
url = "https://api.syosetu.com/novelapi/api/"
params = {
"word": user_keyword,
"order": "monthlypoint",
"out": "json",
"lim": 10
}
response = requests.get(url, params=params)
if response.status_code == 200:
novels = response.json()[1:]
return [{"title": novel.get("title", ""),
"summary": novel.get("story", ""),
"tag": novel.get("keyword", "").split()}
for novel in novels]
else:
return ["検索した結果、関連小説情報を取得できませんでした。"]
chain = (
RunnableParallel(
{
"user_input": RunnablePassthrough(),
"search_words": keyword_extraction_prompt | model | output_parser,
}
)
.assign(naro_novel_info=RunnableLambda(lambda inputs: {"naro_novel_info": fetch_narou_novel_info(inputs["search_words"])}))
.assign(
cot_prompt_output=RunnableLambda(lambda inputs: {
"cot_prompt_output": cot_prompt.invoke({"user_input": inputs["user_input"], "naro_novel_info": inputs["naro_novel_info"]})
})
)
.assign(information=cot_prompt | model | output_parser)
.assign(novel=generate_story_prompt | model | output_parser)
.assign(
critical_sheet = RunnableParallel(
{
"criticalA_sheet":criticalA_prompt | model | output_parser,
"criticalB_sheet":criticalB_prompt | model | output_parser
}
)
)
.assign(taik=talk_prompt | model | output_parser)
.assign(next_novel_plot=next_generation_prot_prompt | model | output_parser)
.assign(final_novel=next_generation_novel_prompt | model | output_parser)
)
output = ""
・・・
for chunk in chain.stream({"user_input":user_input}):
・・・
with open("output_sample05.txt", "w") as f:
・・・
解説
例によって、LLMに投入するプロンプトの解説は省略します(文字数制限のため)
どんなプロンプトを入れているかは、実際のコードをご確認ください。
小説家になろうAPI
まずは、小説家になろうAPIを呼び出す関数を解説します。
APIのドキュメントは下記になります
# なろうAPIを使って、ジャンルに基づいた評価の高い小説情報を取得する関数
def fetch_narou_novel_info(user_keyword):
url = "https://api.syosetu.com/novelapi/api/"
params = {
"word": user_keyword,
"order": "monthlypoint",
"out": "json",
"lim": 10
}
response = requests.get(url, params=params)
if response.status_code == 200:
novels = response.json()[1:]
return [{"title": novel.get("title", ""),
"summary": novel.get("story", ""),
"tag": novel.get("keyword", "").split()}
for novel in novels]
else:
return ["検索した結果、関連小説情報を取得できませんでした。"]
こちらの通り、user_keywordで検索をかけて、月間ポイント("order": "monthlypoint")が高い順に10件("lim": 10)の小説のデータをjson( "out": "json")形式で取得しています。
また、取得した全情報のうちtitle、story、keywordの3つのkeyを持つ辞書を、10小説分returnする関数になっています。
chainの作り方
続いて、chainに繋げる上で、2つの機能を追加する必要があります。
- ユーザが入力した情報から、検索に使える単語を最大3単語取得して、半角スペースで繋げる処理
- 小説家になろうで文章検索はできないので、単語検索をする必要がある
- 半角スペースで二つの単語を繋げると、AND検索になる(コンマなどで繋げることはできない)
- AND検索になるので、大量の単語で検索すると検索結果がなくなるので、最大3件とする
- 作成された検索用単語を用いて「
chainの中で」API呼び出しによる検索を達成する。
実際に構築したchainは下記です。
chain = (
RunnableParallel(
{
"user_input": RunnablePassthrough(),
"search_words": keyword_extraction_prompt | model | output_parser,
}
)
.assign(naro_novel_info=RunnableLambda(lambda inputs: {"naro_novel_info": fetch_narou_novel_info(inputs["search_words"])}))
.assign(
cot_prompt_output=RunnableLambda(lambda inputs: {
"cot_prompt_output": cot_prompt.invoke({"user_input": inputs["user_input"], "naro_novel_info": inputs["naro_novel_info"]})
})
)
.assign(information=cot_prompt | model | output_parser)
.assign(novel=generate_story_prompt | model | output_parser)
.assign(
critical_sheet = RunnableParallel(
{
"criticalA_sheet":criticalA_prompt | model | output_parser,
"criticalB_sheet":criticalB_prompt | model | output_parser
}
)
)
.assign(taik=talk_prompt | model | output_parser)
.assign(next_novel_plot=next_generation_prot_prompt | model | output_parser)
.assign(final_novel=next_generation_novel_prompt | model | output_parser)
)
今回の機能追加に関して関連する部分は下記です。
RunnableParallel(
{
"user_input": RunnablePassthrough(),
"search_words": keyword_extraction_prompt | model | output_parser,
}
).assign(naro_novel_info=RunnableLambda(lambda inputs: {"naro_novel_info": fetch_narou_novel_info(inputs["search_words"])}))
まずは、ユーザ入力から検索用キーワードを取得する部分はLLMを利用しているので、下記のように書けます。
"search_words": keyword_extraction_prompt | model | output_parser,
ここのsearch_wordsをkeyとする辞書に、検索用キーワードが格納されます。
続いて、前段で作られた検索用キーワードsearch_wordsを利用して、fetch_narou_novel_info関数を実行します。
この時に、RunnableLambdaを使っています。
RunnableLambdaは任意の関数をRunnableにできるため、非常に強力です。
これを用いることで、入出力の型だけ注意すれば、chainに組み込めます。
その出力は、関数のreturnで定義されている部分になるため、小説のtitle、story、keywordの3つの情報を後段の入力として利用できるようになりました。
実行結果
実際に7セル目を「Shift」+「Enter」で実行すると、「output_sample05.txt」が出力されます。
実際に出力された内容は文字制限のため、記載できません。
github上のファイルをご覧ください
まとめ
これにより、任意の関数もchainに組み込むことができることがわかったと思います。
では、次が最後です。
より長編の小説を生成できるようにチャプターごとに小説を生成する機能を追加したコード
さて、最後の追加機能です。
ここまでで生成された小説を読んでみるとわかるのですが、いくらなんでも短編すぎるという課題がありました。
これは、LLMが一回で非常に長い文章を生成することができないため、早めに話をまとめる傾向があるためです。
(もしかしたら、他のモデルを利用すれば、プロンプトを修正するだけで問題なく長文が出力されるかもしれません)
したがって、一回のLLMの生成で、1チャプターだけ出力してもらい、それを複数回繰り返すことで、複数チャプタの長文の小説を書いてもらえるように機能を更新します。
コード
まず、コードは下記です。
ipynbでは8セル目に該当します。
(テキスト出力などの本質ではない部分は文字数制限のため省略しました。気になる方はGithubのコードをご覧ください)
8セル目コード全文
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import (
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
import requests
user_input = "ハッピーエンドのボーイミーツガール"
all_chapter_number = 4
keyword_extraction_system_prompt = """
ユーザの入力から、大手小説投稿サイトにて、検索に利用するための重要なキーワード(複数)のみを抽出してください。
接続詞や助詞などは除外し、主要な名詞や形容詞だけを含めてください。
複数のキーワードがある場合は、必ず半角スペースで区切ってください。カンマなどでは区切らないでください。
ただし、抜き出すキーワードは最大3個までにしてください。重要度の高いキーワードから順に抽出してください。
"""
cot_system_prompt = """
アナタはユーザが指定するジャンル等の情報をもとに、短編小説を生成するための情報を整理するAIです。
ユーザが指定したジャンルをもとに、長編小説を生成するための情報をステップバイステップで洗い出してください。
まずは、小説を書くうえで決めないといけない内容が何になるのかを、アナタ自身で全て洗い出してください。
その後、洗い出した項目を、アナタ自身が決定していってください。
ただし、作成する小説は、ユーザが指定したジャンルに沿った内容である必要があります。
しかしながら、山あり谷ありの非常に感動するようなストーリーを生成する必要があります。
また、使いたい名言や印象的なセリフなども書き出してください。
さらに、大規模小説投稿サイトにて高評価を獲得している、関連ジャンルの関連小説情報も参考にしてください。
例えば、関連小説情報の大まかなストーリーラインが今流行っている小説の概要です。なので、これから生成する小説もそのストーリーラインに揃えてください。
また、今回記載してもらう小説は、全{all_chapter_number}章により構成される小説です。
最後に、各章ごとにどんなストーリーにするかを、ユーザが指定したジャンルや、関連小説情報の概要をもとに、ステップバイステップで記載してください。
以上をもとに感動的なストーリーを生成するためのプロットをステップバイステップで書き出してください。
"""
cot_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 高評価を得ている取得したジャンルの関連小説情報
{naro_novel_info}
"""
generate_story_system_prompt = """
アナタは、ユーザが指定するジャンル等の情報をもとに、長編小説を生成するAIです。
ユーザが指定したジャンルに加え、前段でLLMが洗い出した情報をもとに小説を作成してください。
前段のLLMが洗い出した情報を小説に入れ込む必要があるため、文字数は長くなっても構いません。
むしろ、前段の情報を洗い出していないのにも関わらず、ストーリーの生成を中断してはいけません。
またタイトルや段落などは表示しないでください。あくまで小説の本文のみを生成してください。
また、今回記載してもらう小説は、全{all_chapter_number}章により構成される小説です。指定された章の小説を記載してください。
生成する文章はあくまでライトノベルのような内容である必要があります。
加えて、あらすじのような書き方は絶対にしてはいけません。
地の文で話を進めるのではなく、必ず、詳細な描写と登場人物間の会話でのやり取りをもとに、話を進めるようにしてください。
"""
generate_story_human_prompt = """
# 前段のLLMが考えた、今回書く小説のプロット情報
{information}
# 本小説の全話数
{all_chapter_number}
# 今回書いて欲しい話数
{chapter}
# 前話までの小説本文
{prev_novel}
----
この続きから記載してください
----
"""
criticalA_system_prompt = """
あなたは文芸出版社の編集者になり、私が添付ファイルとして送付する小説を読み、評価をしてください。
評価は、項目別の評点と、総合評価、およびコメントによって構成されます。
項目別の評点は、「オリジナリティー」「ストーリー」「設定」「キャラクター」「文章力」の5つの観点について、それぞれ良い順に、A、B+、B、B-、Cの5段階での評価をし、それらを踏まえた総合評価でも同様に、A、B+、B、B-、Cの5段階の評価を付けてください。
コメントでは、5つの観点の中で特筆すべき良い点と改善点について具体的に述べてください。
アナタは、編集者Aとして、小説の良かった点を特に重視して評価をして、最終選考に私の作品を推薦する立場から評価を出力してください。
"""
criticalB_system_prompt = """
あなたは文芸出版社の編集者になり、私が添付ファイルとして送付する小説を読み、評価をしてください。
評価は、項目別の評点と、総合評価、およびコメントによって構成されます。
項目別の評点は、「オリジナリティー」「ストーリー」「設定」「キャラクター」「文章力」の5つの観点について、それぞれ良い順に、A、B+、B、B-、Cの5段階での評価をし、それらを踏まえた総合評価でも同様に、A、B+、B、B-、Cの5段階の評価を付けてください。
コメントでは、5つの観点の中で改善点について具体的に述べてください。
アナタは、編集者Bとして、この小説には改善点が大きいという評価をして、厳しい評価をするとともに、最終選考に私の作品を推薦はしないという立場から評価を出力してください。
"""
taik_system_prompt = """
この小説をより良いものにするにはどうすれば良いかを二人の編集者が議論する対話を出力してください。すぐに結論を出さず、議論を様々な角度から深めてください。
"""
next_generation_prot_system_prompt = """
ここまでで、ユーザの指定したジャンルに沿った小説を生成し、編集者に評価をしてもらい、改善点を議論する対話を出力しました。
その情報をこれから提示するため、その内容に基づいて、元々の小説を改善するための情報をステップバイステップで洗い出してください。
作成する小説は、ユーザが指定したジャンルに沿った内容である必要があります。
しかしながら、山あり谷ありの非常に感動するようなストーリーを生成する必要があります。
また、使いたい名言や印象的なセリフなども書き出してください。
また、今回記載してもらう小説は、全{all_chapter_number}章により構成される小説です。
最後に、各章ごとにどんなストーリーにするかを、ステップバイステップで記載してください。
以上をもとに感動的なストーリーを生成するためのプロットをステップバイステップで書き出してください。
"""
next_generation_prot_human_prompt = """
# ユーザが指定したジャンル等の情報
{user_input}
# 過去に実際に記載した、改善が必要とユーザが判断した小説
{novel}
# 編集者からの評価
{critical_sheet}
# 編集者Aと編集者Bの議論
{taik}
"""
next_generation_novel_system_prompt = """
ここまでで、ユーザの指定したジャンルに沿った小説を生成し、編集者に評価をしてもらい、改善点を議論する対話を出力しました。
その上で、それまでの情報をもとに、改善した内容をLLMに生成してもらいました。
改善した内容と、過去の情報をもとに、実際に長編小説を生成してください。
前段のLLMが洗い出した情報を小説に入れ込む必要があるため、文字数は長くなっても構いません。
むしろ、前段の情報を洗い出していないのにも関わらず、ストーリーの生成を中断してはいけません。
またタイトルや段落などは表示しないでください。あくまで小説の本文のみを生成してください。
また、今回記載してもらう小説は、全{all_chapter_number}章により構成される小説です。指定された章の小説を記載してください。
生成する文章はあくまでライトノベルのような内容である必要があります。
加えて、あらすじのような書き方は絶対にしてはいけません。
地の文で話を進めるのではなく、必ず、詳細な描写と登場人物間の会話でのやり取りをもとに、話を進めるようにしてください。
山あり谷ありの感動的な話が生成されることを期待しています。アナタならできます。頑張ってください。
"""
next_generation_novel_human_prompt = """
# 過去に実際に記載した、改善が必要とユーザが判断した小説
{novel}
# 編集者からの評価
{critical_sheet}
# 編集者Aと編集者Bの議論
{taik}
# 上記の内容をもとにLLMが出した改善策
{next_novel_plot}
# 本小説の全話数
{all_chapter_number}
# 今回書いて欲しい話数
{chapter}
# 前話までの小説本文
{prev_novel}
----
この続きから記載してください
----
"""
# LangChainでキーワード抽出用プロンプトの設定
keyword_extraction_prompt = ChatPromptTemplate.from_messages(
[
("system", keyword_extraction_system_prompt),
("human", "{user_input}")
]
)
cot_prompt = ChatPromptTemplate.from_messages(
[
("system",cot_system_prompt),
("human", cot_human_prompt)
]
)
generate_story_prompt = ChatPromptTemplate.from_messages(
[
("system",generate_story_system_prompt),
("human", generate_story_human_prompt)
]
)
criticalA_prompt = ChatPromptTemplate.from_messages(
[
("system",criticalA_system_prompt),
("human", "{novel}")
]
)
criticalB_prompt = ChatPromptTemplate.from_messages(
[
("system",criticalB_system_prompt),
("human", "{novel}")
]
)
talk_prompt = ChatPromptTemplate.from_messages(
[
("system",taik_system_prompt),
("human", "{critical_sheet}")
]
)
next_generation_prot_prompt = ChatPromptTemplate.from_messages(
[
("system",next_generation_prot_system_prompt),
("human", next_generation_prot_human_prompt)
]
)
next_generation_novel_prompt = ChatPromptTemplate.from_messages(
[
("system",next_generation_novel_system_prompt),
("human", next_generation_novel_human_prompt)
]
)
output_parser = StrOutputParser()
# なろうAPIを使って、ジャンルに基づいた評価の高い小説情報を取得する関数
def fetch_narou_novel_info(user_keyword):
url = "https://api.syosetu.com/novelapi/api/"
params = {
"word": user_keyword,
"order": "monthlypoint",
"out": "json",
"lim": 10
}
response = requests.get(url, params=params)
if response.status_code == 200:
novels = response.json()[1:]
return [{"title": novel.get("title", ""),
"summary": novel.get("story", ""),
"tag": novel.get("keyword", "").split()}
for novel in novels]
else:
return ["検索した結果、関連小説情報を取得できませんでした。"]
def generate_novel_by_chapters(user_input, initial_novel_info, prompt):
final_novel_output = ""
past_content = ""
chapter_num = 1
while chapter_num <= all_chapter_number:
chapter_input = {
"all_chapter_number": all_chapter_number,
"user_input": user_input,
"prev_novel": past_content,
"chapter": chapter_num,
"information": initial_novel_info
}
sub_chain = prompt| model | output_parser
current_chapter_output = sub_chain.invoke(chapter_input)
final_novel_output += f"\n==== Chapter {chapter_num} ====\n" + current_chapter_output
past_content += current_chapter_output
chapter_num += 1
return final_novel_output
def generate_final_novel_by_chapters(user_input, novel, critical_sheet, taik, next_novel_plot, prompt):
final_novel_output = ""
past_content = ""
chapter_num = 1
while chapter_num <= all_chapter_number:
chapter_input = {
"all_chapter_number": all_chapter_number,
"user_input": user_input,
"novel": novel,
"critical_sheet": critical_sheet,
"taik": taik,
"next_novel_plot": next_novel_plot,
"prev_novel": past_content,
"chapter": chapter_num,
}
sub_chain = prompt| model | output_parser
current_chapter_output = sub_chain.invoke(chapter_input)
final_novel_output += f"\n==== Chapter {chapter_num} ====\n" + current_chapter_output
past_content += current_chapter_output
chapter_num += 1
return final_novel_output
chain = (
RunnableParallel(
{
"user_input": RunnablePassthrough(),
"all_chapter_number": RunnablePassthrough(),
"search_words": keyword_extraction_prompt | model | output_parser,
}
)
.assign(naro_novel_info=RunnableLambda(lambda inputs: {"naro_novel_info": fetch_narou_novel_info(inputs["search_words"])}))
.assign(
cot_prompt_output=RunnableLambda(lambda inputs: {
"cot_prompt_output": cot_prompt.invoke({"all_chapter_number":inputs["all_chapter_number"],"user_input": inputs["user_input"], "naro_novel_info": inputs["naro_novel_info"]})
})
)
.assign(information=cot_prompt | model | output_parser)
.assign(novel=RunnableLambda(lambda inputs: {
"novel": generate_novel_by_chapters(inputs["user_input"], inputs["information"], generate_story_prompt)
}))
.assign(
critical_sheet = RunnableParallel(
{
"criticalA_sheet":criticalA_prompt | model | output_parser,
"criticalB_sheet":criticalB_prompt | model | output_parser
}
)
)
.assign(taik=talk_prompt | model | output_parser)
.assign(next_novel_plot=next_generation_prot_prompt | model | output_parser)
.assign(final_novel=RunnableLambda(lambda inputs: {
"final_novel": generate_final_novel_by_chapters(
inputs["user_input"],
inputs["novel"],
inputs["critical_sheet"],
inputs["taik"],
inputs["next_novel_plot"],
next_generation_novel_prompt)
}))
)
output = ""
・・・
for chunk in chain.stream({"user_input":user_input, "all_chapter_number": str(all_chapter_number)}):
・・・
with open("output_sample06.txt", "w") as f:
・・・
解説
チャプター数の指定
まず、今回生成するチャプター数は下記で決定します。
all_chapter_number = 4
本来であれば8-10章くらいで進めたいですが、コストもあるので、一旦4章で設定しています。
チャプタごとの小説生成
前の章で、任意の関数をRunnableに変換してchainに組み込むことができるRunnableLambdaについて紹介しました。
そこで、今回の設計の方針として、関数内でLangChainを利用し、4章分をfor文で連続で生成し、chainとして繋げることを考えます。
その関数は下記です。
(初回の改善前の小説を生成する関数です)
def generate_novel_by_chapters(user_input, initial_novel_info, prompt):
final_novel_output = ""
past_content = ""
chapter_num = 1
while chapter_num <= all_chapter_number:
chapter_input = {
"all_chapter_number": all_chapter_number,
"user_input": user_input,
"prev_novel": past_content,
"chapter": chapter_num,
"information": initial_novel_info
}
sub_chain = prompt| model | output_parser
current_chapter_output = sub_chain.invoke(chapter_input)
final_novel_output += f"\n==== Chapter {chapter_num} ====\n" + current_chapter_output
past_content += current_chapter_output
chapter_num += 1
return final_novel_output
while chapter_num <= all_chapter_number: により、設定したチャプター数分だけ繰り返し処理がなされます。
その一回一回において、sub_chain.invoke(chapter_input)により、文章を生成しています。
それを、まとめたfinal_novel_outputをreturnしています。
また、最終的なchainは下記のようになります。
chain = (
RunnableParallel(
{
"user_input": RunnablePassthrough(),
"all_chapter_number": RunnablePassthrough(),
"search_words": keyword_extraction_prompt | model | output_parser,
}
)
.assign(naro_novel_info=RunnableLambda(lambda inputs: {"naro_novel_info": fetch_narou_novel_info(inputs["search_words"])}))
.assign(
cot_prompt_output=RunnableLambda(lambda inputs: {
"cot_prompt_output": cot_prompt.invoke({"all_chapter_number":inputs["all_chapter_number"],"user_input": inputs["user_input"], "naro_novel_info": inputs["naro_novel_info"]})
})
)
.assign(information=cot_prompt | model | output_parser)
.assign(novel=RunnableLambda(lambda inputs: {
"novel": generate_novel_by_chapters(inputs["user_input"], inputs["information"], generate_story_prompt)
}))
.assign(
critical_sheet = RunnableParallel(
{
"criticalA_sheet":criticalA_prompt | model | output_parser,
"criticalB_sheet":criticalB_prompt | model | output_parser
}
)
)
.assign(taik=talk_prompt | model | output_parser)
.assign(next_novel_plot=next_generation_prot_prompt | model | output_parser)
.assign(final_novel=RunnableLambda(lambda inputs: {
"final_novel": generate_final_novel_by_chapters(
inputs["user_input"],
inputs["novel"],
inputs["critical_sheet"],
inputs["taik"],
inputs["next_novel_plot"],
next_generation_novel_prompt)
}))
)
重要なポイントとして、下記の箇所にて、上で説明した関数をRunnableに変換してchainに組み込んでいます。
.assign(novel=RunnableLambda(lambda inputs: {
"novel": generate_novel_by_chapters(inputs["user_input"], inputs["information"], generate_story_prompt)
}))
また、改善後の小説を書く段階も同様に、別の関数を定義して、下記の形でchainに組み込んでいます。
.assign(final_novel=RunnableLambda(lambda inputs: {
"final_novel": generate_final_novel_by_chapters(
inputs["user_input"],
inputs["novel"],
inputs["critical_sheet"],
inputs["taik"],
inputs["next_novel_plot"],
next_generation_novel_prompt)
}))
実行結果
実際に8セル目を「Shift」+「Enter」で実行すると、「output_sample06.txt」が出力されます。
実際に出力された内容は文字制限のため、記載できません。
github上のファイルをご覧ください
まとめ
ここまででついに、タイトルの「なろう短編小説の自動生成&自動改善を行うAIエージェント」の構築が完了しました。
ここまでで実装した機能は下記になります。
- ユーザが作って欲しい小説の情報を入力する
- 入力された情報から「小説家になろう」の月刊評価が高い作品を検索し、情報を取得
- ステップバイステップで、AIが小説のプロットを構築
- AIがチャプタごとに小説を作成し、複数チャプタの長編小説を生成
- 生成した小説に対して、2名の編集者が並列で評価する
- 楽観的な編集者A
- 批判的な編集者B
- 二人の編集者の会話形式により、小説の改善案を洗い出す
- 上記の改善案を受けて、ステップバイステップで改善後の小説のプロットを構築
- AIがチャプタごとに改善した小説を生成。複数チャプタの長編の改善小説を生成する
このように記載すると、かなり機能の多いAIエージェントを組めたと思います!
まとめ
ここまで読んでくださってありがとうございました!
かなり長くなってしまいましたが、LangChainを使うと、かなり複雑な処理の流れを簡単に作ることができてとても感動しました!
そして、それに気づかせてくれた良本に感謝です。
参考文献
LangChain(LCML)に関して
LangChainとLangGraphによるRAG・AIエージェント[実践]入門
プロンプトを参考
Discussion