生成AIをGoogle Colaboratoryで簡単に 【Part8 画像生成AI Stable Diffusion 3 Medium編】
はじめに
今回は、初心者向けにGoogle Colaboratoryで、簡単に生成AIを使えるようにする環境を作ります。
(音声対話システムを作成するための個人的な忘備録の意味合いが強いです)
Part8の今回は、画像生成AIを使えるようにします。
今回利用する音声認識AIはStable Diffusion 3になります。
2024年7月時点で、最新の画像生成AIモデルです。
なお、今回Part8ですが、Part1~Part7の内容を読まなくても、わかるように記載しています。
画像生成AIということで、直接的には音声対話システムとは無関係な技術のように見えますが、AIの発話に合わせて適切な画像を表示するみたいなことに使えるかなと思い、勉強しています。
(過去に私が実装した音声対話システムは下記で紹介しています。興味があれば一読いただけますと嬉しいです)
初心者向けに無料版のGoogle Colaboratoryで動作可能な範囲内で実施しておりますので、気軽に試してみてください。
本記事では下記のように、拡散プロセス途中の潜在表現から画像を復元する実験などもしているため、興味がある方がいらっしゃれば最後までご覧いただけますと幸いです!
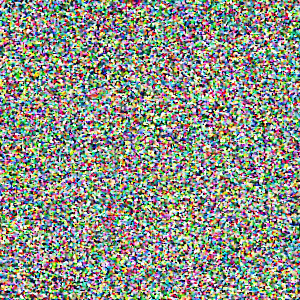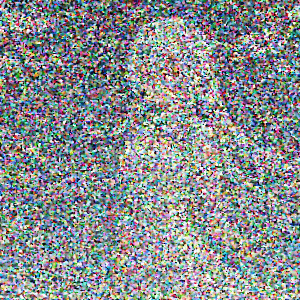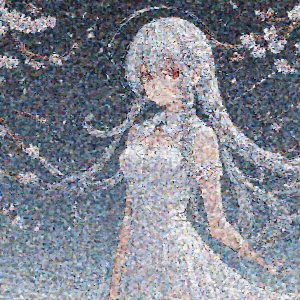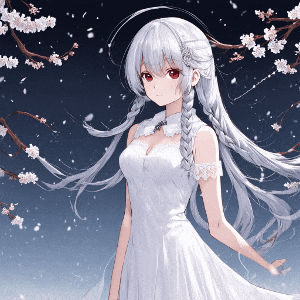
今回は下記の記事を参考に記載しています。
Stable Diffusion 3とは
Stable Diffusion 3(SD3)とは、Stability AI社が開発した画像生成AIの一つです。
2024年7月時点では、最新のモデルになっています。
Stable Diffusion 3には下記のとおり、複数のモデルがあります
- Stable Diffusion 3 Medium
- Stable Diffusion 3 Large
- Stable Diffusion 3 Large Turbo
- Stable Image Ultra
Stable Diffusion 3 Mediumは2Bのパラメータを持ち、Largeは8Bのモデルになります。
Large Turboというのは、公式曰く推論時間が短縮された8Bパラメータモデルとのことです。おそらくは、モデルパラメータは同じでも、推論step数が少なくなった蒸留モデルなのかな?と思っております。詳細は分かりません。
そしてStable Image Ultraというのは、厳密にはモデル名ではなくサービス名なのですが、現時点で最も最高の性能のモデルを利用して、画像生成を行うモデルだそうです。詳細はよくわかっていません。
上記の中で、最も綺麗な画像が生成できるのは、Stable Image Ultraになりますが、本サービスはAPIでしか提供しておらず、それはStable Diffusion 3 Large、Stable Diffusion 3 Large Turboに関しても同様です。
残念ながらローカルでは動かすことができないため、今回は、ローカルで動かすことができる(モデルの重みが公開されている)Stable Diffusion 3 Mediumについて触ってみたいと思います。
またもう一つ、Stable Diffusionを利用する場合、主流な使い方は、WebUIを利用するパターンだと思います。しかしながらGoogle ColabはWebUIの利用がNG(利用規約的に)のため、これまでと同様にPythonスクリプトの中で画像を生成していきます。
(Diffuserというライブラリを利用します)
なお、本記事では、以降Stable Diffusion 3 MediumのことをSD3と表記します。
成果物
下記のリポジトリをご覧ください。
今回の実験
今回は、私自身がSD3について初めて触るため、好奇心にしたがって様々な実験をしています。
(これまで紹介した技術は自分の中で結構使い込んでいたので、簡単な紹介しかしてなくて申し訳ないです)
下記に実施した実験の内容を記載します。実験結果については最後にご紹介しています。
-
実験1
- 記事にある通りの実装をそのまま試す。
- T5エンコーダのドロップ
-
guided_scaleが7.0 -
shiftが3.0など
- 記事にある通りの実装をそのまま試す。
-
実験2
-
guided_scaleを4.0に変更してみる
-
-
実験3-3.5
-
shiftを1.0や6.0に変更してみる
-
-
実験4
- モデルの
compileを試してみる
- モデルの
-
実験5
- T5をCPUオフロードで導入してみる
-
実験6
- T5を量子化して導入してみる
-
実験7
- T5を導入した状態で
compileを試してみる
- T5を導入した状態で
-
実験8
- 各プロセスでの潜在表現を確認してみる
-
実験9-12
- 生成step数を減少させてみて、生成画像を確認する
-
実験13-15
- 生成step数を増加させてみて、生成画像を確認する
事前準備
Hugging Faceのlogin tokenの取得と登録
SD3のモデルをローカルで利用可能にするために、Huggingfaceからログイン用のtokenを取得する必要があります。
ログインtokenの取得方法は下記の記事を参考にしてください。
また、取得したログインtokenをGoogle Colabに登録する必要があります。
下記の記事を参考に登録してください。
HF_LOGINという名前で登録してください。
SD3重みへのアクセス準備
続いて、HuggingfaceでStable Diffusionの重みにアクセスできるようにします。
上記のURLにアクセスします。

初めてアクセスした場合、上記のような画面になると思うので、作成したアカウントでログインしてください。
その後、入力フォームが表示されるかと思います。
そのフォームをすべて埋めて、提出することで、モデル重みにアクセスできるようになります。
解説
下記の通り、解説を行います。
まずは上記のリポジトリをcloneしてください。
git clone https://github.com/personabb/colab_AI_sample.git
その後、cloneしたフォルダ「colab_AI_sample」をマイドライブの適当な場所においてください。
ディレクトリ構造
Google Driveのディレクトリ構造は下記を想定します。
MyDrive/
└ colab_AI_sample/
└ colab_SD3_sample/
├ configs/
| └ config.ini
├ outputs/
├ module/
| └ module_sd3.py
└ StableDiffusion3_sample.ipynb
-
colab_AI_sampleフォルダは適当です。なんでも良いです。1階層である必要はなく下記のように複数階層になっていても良いです。MyDrive/hogehoge/spamspam/hogespam/colab_AI_sample
-
outputsフォルダには、生成後の画像が格納されます。最初は空です。- 連続して生成を行う場合、過去の生成内容を上書きするため、ダウンロードするか、名前を変えておくことをオススメします。
使い方解説
StableDiffusion3_sample.ipynbをGoogle Colabratoryアプリで開いてください。
ファイルを右クリックすると「アプリで開く」という項目が表示されるため、そこからGoogle Colabratoryアプリを選択してください。
もし、ない場合は、「アプリを追加」からアプリストアに行き、「Google Colabratory」で検索してインストールをしてください。
Google Colabratoryアプリで開いたら、StableDiffusion3_sample.ipynbのメモを参考にして、一番上のセルから順番に実行していけば、問題なく最後まで動作して、画像生成をすることができると思います。
また、最後まで実行後、パラメータを変更して再度実行する場合は、「ランタイム」→「セッションを再起動して全て実行する」をクリックしてください。
コード解説
主に、重要なStableDiffusion3_sample.ipynbとmodule/module_sd3.pyについて解説します。
StableDiffusion3_sample.ipynb
該当のコードは下記になります。
下記に1セルずつ解説します。
1セル目
#SD3 で必要なモジュールのインストール
!pip install -Uqq diffusers transformers ftfy accelerate bitsandbytes
ここでは、必要なモジュールをインストールしています。
Google colabではpytorchなどの基本的な深層学習パッケージなどは、すでにインストール済みなため上記だけインストールすれば問題ありません。
2セル目
#Google Driveのフォルダをマウント(認証入る)
from google.colab import drive
drive.mount('/content/drive')
from huggingface_hub import login
from google.colab import userdata
HF_LOGIN = userdata.get('HF_LOGIN')
login(HF_LOGIN)
# カレントディレクトリを本ファイルが存在するディレクトリに変更する。
import glob
import os
pwd = os.path.dirname(glob.glob('/content/drive/MyDrive/**/colab_SD3_sample/StableDiffusion3_sample.ipynb', recursive=True)[0])
print(pwd)
%cd $pwd
!pwd
ここでは、Googleドライブの中身をマウントしています。
マウントすることで、Googleドライブの中に入っているファイルを読み込んだり、書き込んだりすることが可能になります。
マウントをする際は、Colabから、マウントの許可を行う必要があります。
ポップアップが表示されるため、指示に従い、マウントの許可を行なってください。
また、Google Colabに登録されたHF_LOGINtokenを読み込み、HuggingFaceにログインします。
また、続けて、カレントディレクトリを/から/content/drive/MyDrive/**/colab_SD3_sampleに変更しています。
(**はワイルドカードです。任意のディレクトリ(複数)が入ります)
カレントディレクトリは必ずしも変更する必要はないですが、カレントディレクトリを変更することで、これ以降のフォルダ指定が楽になります
3セル目
#モジュールをimportする
from module.module_sd3 import SD3
import time
module/module_sd3.pyのSD3クラスをモジュールとしてインポートします。
この中身の詳細は後の章で解説します。
また、実行時間の計測のためtimeモジュールも読み込んでいます。
4セル目
#モデルの設定を行う。
config_text = """
[SD3]
device = auto
n_steps=28
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 7.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = False
"""
with open("configs/config.ini", "w", encoding="utf-8") as f:
f.write(config_text)
このセルでは、設定ファイルconfigs/config.iniの中身をconfig_textの内容で上書きしています。
SD3は上記の設定に併せて動作をします。
以降の章で説明する各種実験は、この設定ファイルを少しずつ変更して実験しています。
それぞれの設定内容に関して簡単に説明します。
-
device = auto- GPUを利用するかCPUを利用するかの設定。
-
autoに設定しておけば、GPUが利用できる場合は必ずGPUを利用してくれるので基本変更不要
-
n_steps=28- 拡散処理のステップ数の設定。デフォルトは28
-
seed=42- 乱数のシード値。この値を固定することで同じ画像を生成できる
-
shift = 3.0-
FlowMatchEulerDiscreteSchedulerに入力される値の一つ- おすすめとして提示されている値が3である
-
Schedulerとは常微分方程式をとくSolverのことである。- 拡散モデルはその処理自体が常微分方程式を解くことと一致するため、常微分方程式のSolverを利用して、画像の生成を行うことができる
- ちなみにSD3(Diffuser)で使えるSolverは上記のものしか知らないので、他にも使えるSolverがあれば教えて欲しい。
-
DPMSolverMultistepSchedulerも使ってみたが、画像にならなかった。
-
-
-
model_path = stabilityai/stable-diffusion-3-medium-diffusers- SD3で利用するモデルを提示します。
- もし新しくDiffuserのSD3で利用可能なモデルがあれば、ここに指定することで利用可能になります。
- 良いモデルがあれば、教えて欲しいです。
-
guided_scale = 7.0- CFGスケールのことです。Classifier Free Guidanceにおけるプロンプトの追従力を表現しています。
- 記事では7.0を利用しているが、SD3を試してみた他の有識者の記事などでは3.5-4.5が推奨されているらしいです。(後述する実験で試す予定)
-
width = 1024とheight = 1024- 画像の解像度を示します。基本的にはこの値が推奨です。縦長の画像とかにしたい場合などに変更することは可能です。
-
use_cpu_offload = False- CPUオフロードを利用するかどうか。
Trueにしたら使用します。- T5という大規模なText Encoderを利用した場合、VRAMに全てのモデルが収まらないため、利用される。その場合は、VRAMの代わりに大きなRAMが必要
- CPUオフロードを利用するかどうか。
-
use_text_encoder_3 = False- T5という大規模なText Encoderを利用するかどうか。
Trueで使用します。- T5は非常に長いpromptも読み取れる高性能なEncoderです。
- 使わない場合は、残りの2つのCLIPという従来のモデルでも使われていたText Encoderが利用される
- その場合は、promptは77tokenに制限される。
- T5という大規模なText Encoderを利用するかどうか。
-
use_t5_quantization = False- T5という大規模なText Encoderを8bitに量子化して利用するかどうか。
Trueで量子化します。 - 量子化することで、小規模なVRAMでも利用できる可能性があります。
- 量子化した場合は、自動的にCPUオフロードされるため、
use_cpu_offload = Falseは機能しません。
- T5という大規模なText Encoderを8bitに量子化して利用するかどうか。
-
use_model_compile = False- モデルをコンパイルするかどうか。
Trueでコンパイルします。 - コンパイルすると計算を最適化できるため、計算時間が削減できます
-
use_cpu_offload = Trueやuse_t5_quantization = Trueなどを指定しており、CPUオフロードが機能している場合は、(基本的には)コンパイルできないです。- コンパイルする方法もあるので、記事中で簡単に言及しています。
- モデルをコンパイルするかどうか。
-
save_latent = False- 拡散プロセス途中の潜在表現から画像を再構成するかどうか。
Trueで再構成して保存します。 - これを
Trueにすることで、記事上部のようなGif画像を作成できます。- 実際には、
n_steps枚数の画像が保存されます。(完全ノイズから生成画像まで)
- 実際には、
- 拡散プロセス途中の潜在表現から画像を再構成するかどうか。
ちなみに、実は、巷でよく言われている設定である、schedulerのshiftを3にすると良いという設定は、すでにStableDiffusion3Pipelineでは設定済みのため、別途指定して変更する必要はないらしいです。デフォルトのまま利用すれば、勝手に3になっているらしい。
(私は実験している途中で気づきました。)
(ドキュメントを見るとFlowMatchEulerDiscreteSchedulerのshiftのデフォルト値は1.0になっているので混乱しますが、下記のような形で確認するとshiftが3.0になっていることが確認できます。)
(下記のコードは、後々紹介しますが、先出しで提示します)
class SD3:
・・・
def preprepare_model(self):
・・・
if self.use_cpu_offload:
pipe.enable_model_cpu_offload()
else:
pipe = pipe.to("cuda")
print(pipe.scheduler.config)
5セル目
#モデルの設定を行う。
#読み上げるプロンプトを設定する。
main_prompt = """
Anime style, An anime digital illustration of young woman with striking red eyes, standing outside surrounded by falling snow and cherry blossoms. Her long, flowing silver hair is intricately braided, adorned an accessory made of lace, white tripetal flowers, and small, white pearls, cascading around her determined face. She wears a high-collared, form-fitting white dress with intricate lace details and cut-out sections on the sleeves, adding to the air of elegance and strength. The background features out-of-focus branches dotted with vibrant pink blossoms, set against a clear blue sky speckled with snow and bokeh, creating a dreamlike, serene atmosphere. The lighting casts a soft, almost divine glow on her, emphasizing her resolute expression. The artwork captures her from the waist up. Image is an anime style digital artwork. trending on artstation, pixiv, anime-style, anime screenshot
"""
negative_prompt=""
ここでは生成されるpromptを指定しています。
下記のポストにて、公開してくださっているプロンプトを使わせていただいております。ありがとうございます。
SD3では、ネガティブプロンプトを指定する必要はないため、空文字に設定しています。
また、main_promptは非常に長いプロンプトを指定しています。
その結果、今回のプロンプトを利用して、モデルの画像生成部分を実行すると、下記のようなワーニングが出ます。
Token indices sequence length is longer than the specified maximum sequence length for this model (188 > 77). Running this sequence through the model will result in indexing errors
The following part of your input was truncated because CLIP can only handle sequences up to 77 tokens: ['with intricate lace details and cut - out sections on the sleeves, adding to the air of elegance and strength. the background features out - of - focus branches dotted with vibrant pink blossoms, set against a clear blue sky speckled with snow and bokeh, creating a dreamlike, serene atmosphere. the lighting casts a soft, almost divine glow on her, emphasizing her resolute expression. the artwork captures her from the waist up. image is an anime style digital artwork. trending on artstation, pixiv, anime - style, anime screenshot']
これは、3つあるText_Encoderの最初の2つで使われているCLIPというモデルが、77tokenしか処理できないため、プロンプトの後半を切り捨てますというワーニングです。
一方で、3つ目のText_EncoderであるT5は、非常に長いプロンプトを処理できるため、T5を利用する場合はプロンプトのすべてが問題なく処理できます。
T5を使う場合を使わない場合で、どのように出力が変化するのかも実験で試す予定です。
6セル目
sd = SD3()
ここで、SD3クラスのインスタンスを作成します。
7セル目
for i in range(3):
start = time.time()
image = sd.generate_image(main_prompt, neg_prompt = negative_prompt)
print("generate image time: ", time.time()-start)
image.save("./outputs/SD3_result_{}.png".format(i))
ここではSD3で画像を生成します。
3回for文を回すことで、3枚の画像を生成し、outputsフォルダに保存します。
また、1枚生成するのにかかる時間を計測して表示しています。
実行結果(生成される画像)などは、のちの実験結果の章で提示します。
画像はoutputsフォルダに保存されますが、実行のたびに同じ名前で保存されるので、過去に保存した画像は上書きされるようになりますので注意してください。
(seed値という乱数表の値を変更しない限り、実行のたびに必ず同じ画像が生成されます。seedは設定ファイルで変更できます。)
module/module_sd3.py
続いて、StableDiffusion3_sample.ipynbから読み込まれるモジュールの中身を説明します。
下記にコード全文を示します。
コード全文
import torch
from diffusers import StableDiffusion3Pipeline, AutoencoderTiny , FlowMatchEulerDiscreteScheduler, DPMSolverMultistepScheduler
from diffusers.pipelines.stable_diffusion_3.pipeline_output import StableDiffusion3PipelineOutput
from transformers import T5EncoderModel, BitsAndBytesConfig
from PIL import Image
import os
import configparser
# ファイルの存在チェック用モジュール
import errno
import time
class SD3config:
def __init__(self, config_ini_path = './configs/config.ini'):
# iniファイルの読み込み
self.config_ini = configparser.ConfigParser()
# 指定したiniファイルが存在しない場合、エラー発生
if not os.path.exists(config_ini_path):
raise FileNotFoundError(errno.ENOENT, os.strerror(errno.ENOENT), config_ini_path)
self.config_ini.read(config_ini_path, encoding='utf-8')
SD3_items = self.config_ini.items('SD3')
self.SD3_config_dict = dict(SD3_items)
class SD3:
def __init__(self,device = None, config_ini_path = './configs/config.ini'):
SD3_config = SD3config(config_ini_path = config_ini_path)
config_dict = SD3_config.SD3_config_dict
if device is not None:
self.device = device
else:
device = config_dict["device"]
self.device = "cuda" if torch.cuda.is_available() else "cpu"
if device != "auto":
self.device = device
self.n_steps = int(config_dict["n_steps"])
self.seed = int(config_dict["seed"])
self.generator = torch.Generator(device=self.device).manual_seed(self.seed)
self.width = int(config_dict["width"])
self.height = int(config_dict["height"])
self.guided_scale = float(config_dict["guided_scale"])
self.shift = float(config_dict["shift"])
self.use_cpu_offload = config_dict["use_cpu_offload"]
if self.use_cpu_offload == "True":
self.use_cpu_offload = True
else:
self.use_cpu_offload = False
self.use_text_encoder_3 = config_dict["use_text_encoder_3"]
if self.use_text_encoder_3 == "True":
self.use_text_encoder_3 = True
else:
self.use_text_encoder_3 = False
self.use_T5_quantization = config_dict["use_t5_quantization"]
if self.use_T5_quantization == "True":
self.use_T5_quantization = True
else:
self.use_T5_quantization = False
self.use_model_compile = config_dict["use_model_compile"]
if self.use_model_compile == "True":
self.use_model_compile = True
else:
self.use_model_compile = False
self.save_latent = config_dict["save_latent"]
if self.save_latent == "True":
self.save_latent = True
else:
self.save_latent = False
self.model_path = config_dict["model_path"]
if self.use_model_compile:
self.pipe = self.preprepare_compile_model()
else:
self.pipe = self.preprepare_model()
def preprepare_model(self):
pipe = None
sampler = FlowMatchEulerDiscreteScheduler(
shift = self.shift
)
if self.use_text_encoder_3:
if self.use_T5_quantization:
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
text_encoder = T5EncoderModel.from_pretrained(
self.model_path,
subfolder="text_encoder_3",
quantization_config=quantization_config,
)
pipe = StableDiffusion3Pipeline.from_pretrained(
self.model_path,
scheduler = sampler,
text_encoder_3=text_encoder,
device_map="balanced",
torch_dtype=torch.float16
)
else:
pipe = StableDiffusion3Pipeline.from_pretrained(self.model_path, scheduler = sampler, torch_dtype=torch.float16)
else:
pipe = StableDiffusion3Pipeline.from_pretrained(
self.model_path,
scheduler = sampler,
text_encoder_3=None,
tokenizer_3=None,
torch_dtype=torch.float16)
if self.use_T5_quantization:
pass
elif self.use_cpu_offload:
pipe.enable_model_cpu_offload()
else:
pipe = pipe.to("cuda")
print(pipe.scheduler.config)
return pipe
def preprepare_compile_model(self):
torch.set_float32_matmul_precision("high")
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
pipe = None
sampler = FlowMatchEulerDiscreteScheduler(
shift = self.shift
)
if self.use_text_encoder_3:
if self.use_T5_quantization:
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
text_encoder = T5EncoderModel.from_pretrained(
self.model_path,
subfolder="text_encoder_3",
quantization_config=quantization_config,
)
pipe = StableDiffusion3Pipeline.from_pretrained(
self.model_path,
scheduler = sampler,
text_encoder_3=text_encoder,
device_map="balanced",
torch_dtype=torch.float16
)
else:
pipe = StableDiffusion3Pipeline.from_pretrained(self.model_path, scheduler = sampler, torch_dtype=torch.float16)
else:
pipe = StableDiffusion3Pipeline.from_pretrained(
self.model_path,
scheduler = sampler,
text_encoder_3=None,
tokenizer_3=None,
torch_dtype=torch.float16)
if self.use_T5_quantization:
pass
elif self.use_cpu_offload:
pipe.enable_model_cpu_offload()
else:
pipe = pipe.to("cuda")
print(pipe.scheduler.config)
pipe.set_progress_bar_config(disable=True)
pipe.transformer.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
pipe.transformer = torch.compile(pipe.transformer, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
return pipe
def generate_image(self, prompt, prompt_2 = None, prompt_3 = None, neg_prompt = "", neg_prompt_2 = None, neg_prompt_3 = None,seed = None):
def decode_tensors(pipe, step, timestep, callback_kwargs):
latents = callback_kwargs["latents"]
image = latents_to_rgb(latents,pipe)
gettime = time.time()
formatted_time_human_readable = time.strftime("%Y%m%d_%H%M%S", time.localtime(gettime))
image.save(f"./outputs/latent_{formatted_time_human_readable}_{step}_{timestep}.png")
return callback_kwargs
def latents_to_rgb(latents,pipe):
latents = (latents / pipe.vae.config.scaling_factor) + pipe.vae.config.shift_factor
img = pipe.vae.decode(latents, return_dict=False)[0]
img = pipe.image_processor.postprocess(img, output_type="pil")
return StableDiffusion3PipelineOutput(images=img).images[0]
if seed is not None:
self.generator = torch.Generator(device=self.device).manual_seed(seed)
if prompt_2 is None:
prompt_2 = prompt
if prompt_3 is None:
prompt_3 = prompt
if neg_prompt_2 is None:
neg_prompt_2 = neg_prompt
if neg_prompt_3 is None:
neg_prompt_3 = neg_prompt
image = None
if self.save_latent:
image = self.pipe(
prompt=prompt,
prompt_2=prompt_2,
prompt_3=prompt_3,
negative_prompt=neg_prompt,
negative_prompt_2 = neg_prompt_2,
negative_prompt_3 = neg_prompt_3,
height = self.height,
width = self.width,
num_inference_steps=self.n_steps,
guidance_scale=self.guided_scale,
generator=self.generator,
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
).images[0]
else:
image = self.pipe(
prompt=prompt,
prompt_2=prompt_2,
prompt_3=prompt_3,
negative_prompt=neg_prompt,
negative_prompt_2 = neg_prompt_2,
negative_prompt_3 = neg_prompt_3,
height = self.height,
width = self.width,
num_inference_steps=self.n_steps,
guidance_scale=self.guided_scale,
generator=self.generator
).images[0]
return image
では一つ一つ解説していきます。
SD3configクラス
class SD3config:
def __init__(self, config_ini_path = './configs/config.ini'):
# iniファイルの読み込み
self.config_ini = configparser.ConfigParser()
# 指定したiniファイルが存在しない場合、エラー発生
if not os.path.exists(config_ini_path):
raise FileNotFoundError(errno.ENOENT, os.strerror(errno.ENOENT), config_ini_path)
self.config_ini.read(config_ini_path, encoding='utf-8')
SD3_items = self.config_ini.items('SD3')
self.SD3_config_dict = dict(SD3_items)
ここではconfig_ini_path = './configs/config.ini'で指定されている設定ファイルをSD3_config_dictとして読み込んでいます。
辞書型で読み込んでいるため、設定ファイルの中身をpythonの辞書として読み込むことが可能になります。
SD3クラスのinitメソッド
class SD3:
def __init__(self,device = None, config_ini_path = './configs/config.ini'):
SD3_config = SD3config(config_ini_path = config_ini_path)
config_dict = SD3_config.SD3_config_dict
if device is not None:
self.device = device
else:
device = config_dict["device"]
self.device = "cuda" if torch.cuda.is_available() else "cpu"
if device != "auto":
self.device = device
self.n_steps = int(config_dict["n_steps"])
self.seed = int(config_dict["seed"])
self.generator = torch.Generator(device=self.device).manual_seed(self.seed)
self.width = int(config_dict["width"])
self.height = int(config_dict["height"])
self.guided_scale = float(config_dict["guided_scale"])
self.shift = float(config_dict["shift"])
self.use_cpu_offload = config_dict["use_cpu_offload"]
if self.use_cpu_offload == "True":
self.use_cpu_offload = True
else:
self.use_cpu_offload = False
self.use_text_encoder_3 = config_dict["use_text_encoder_3"]
if self.use_text_encoder_3 == "True":
self.use_text_encoder_3 = True
else:
self.use_text_encoder_3 = False
self.use_T5_quantization = config_dict["use_t5_quantization"]
if self.use_T5_quantization == "True":
self.use_T5_quantization = True
else:
self.use_T5_quantization = False
self.use_model_compile = config_dict["use_model_compile"]
if self.use_model_compile == "True":
self.use_model_compile = True
else:
self.use_model_compile = False
self.save_latent = config_dict["save_latent"]
if self.save_latent == "True":
self.save_latent = True
else:
self.save_latent = False
self.model_path = config_dict["model_path"]
if self.use_model_compile:
self.pipe = self.preprepare_compile_model()
else:
self.pipe = self.preprepare_model()
まず、設定ファイルの内容をconfig_dictに格納しています。これは辞書型のため、config_dict["device"]のような形で設定ファイルの内容を文字列として取得することができます。
あくまで、すべての文字を文字列として取得するため、int型やbool型にしたい場合は、適宜型変更をする必要があることに注意してください。
続いて下記の順番で処理を行います。
- モデルを動作させる
deviceを指定する - 設定ファイルの各種設定を取得する
- モデルを定義する。
- 設定ファイルに合わせて、適切なモデルを定義する
-
use_model_compileの設定に合わせて、self.preprepare_model()メソッド、もしくはself.preprepare_compile_model()メソッドで定義する
SD3クラスのpreprepare_modelメソッド
class SD3:
・・・
def preprepare_model(self):
pipe = None
sampler = FlowMatchEulerDiscreteScheduler(
shift = self.shift
)
if self.use_text_encoder_3:
if self.use_T5_quantization:
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
text_encoder = T5EncoderModel.from_pretrained(
self.model_path,
subfolder="text_encoder_3",
quantization_config=quantization_config,
)
pipe = StableDiffusion3Pipeline.from_pretrained(
self.model_path,
scheduler = sampler,
text_encoder_3=text_encoder,
device_map="balanced",
torch_dtype=torch.float16
)
else:
pipe = StableDiffusion3Pipeline.from_pretrained(self.model_path, scheduler = sampler, torch_dtype=torch.float16)
else:
pipe = StableDiffusion3Pipeline.from_pretrained(
self.model_path,
scheduler = sampler,
text_encoder_3=None,
tokenizer_3=None,
torch_dtype=torch.float16)
if self.use_T5_quantization:
pass
elif self.use_cpu_offload:
pipe.enable_model_cpu_offload()
else:
pipe = pipe.to("cuda")
print(pipe.scheduler.config)
return pipe
このメソッドはinitメソッドで呼ばれて、モデルを定義して読み込むメソッドになります。
use_model_compile = Falseの場合、つまりモデルのcompileを実施しない場合に利用するメソッドです。
設定ファイルに合わせて、SchedulerやText Encoder、StableDiffusion3Pipelineを設定し、必要なデバイスにモデルをロードしています。
記事の上の方(ipynbの4セル目の解説)でも提示しましたが、
print(pipe.scheduler.config)
でSchedulerの設定を確認できます。
基本的には下記の記事を参考に実装しています。
SD3クラスのpreprepare_compile_modelメソッド
class SD3:
・・・
def preprepare_compile_model(self):
torch.set_float32_matmul_precision("high")
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
pipe = None
sampler = FlowMatchEulerDiscreteScheduler(
shift = self.shift
)
if self.use_text_encoder_3:
if self.use_T5_quantization:
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
text_encoder = T5EncoderModel.from_pretrained(
self.model_path,
subfolder="text_encoder_3",
quantization_config=quantization_config,
)
pipe = StableDiffusion3Pipeline.from_pretrained(
self.model_path,
scheduler = sampler,
text_encoder_3=text_encoder,
device_map="balanced",
torch_dtype=torch.float16
)
else:
pipe = StableDiffusion3Pipeline.from_pretrained(self.model_path, scheduler = sampler, torch_dtype=torch.float16)
else:
pipe = StableDiffusion3Pipeline.from_pretrained(
self.model_path,
scheduler = sampler,
text_encoder_3=None,
tokenizer_3=None,
torch_dtype=torch.float16)
if self.use_T5_quantization:
pass
elif self.use_cpu_offload:
pipe.enable_model_cpu_offload()
else:
pipe = pipe.to("cuda")
print(pipe.scheduler.config)
pipe.set_progress_bar_config(disable=True)
pipe.transformer.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
pipe.transformer = torch.compile(pipe.transformer, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
return pipe
こちらはモデルのcompileを実施する際にinitメソッドから呼ばれるメソッドになります。
量子化やオフロードをする際はコンパイルできないので、本来は実装すべきではないのですが、後述する実験によりコンパイルができないことがわかったので、この時点では、まだcompileしていない方のメソッドと同様に実装しています。
(ご自身で実装する際は、オフロード時や量子化時はコンパイルできないように実装してください。エラーになります。)
例によって下記記事を参考に実装しています
SD3クラスのgenerate_imageメソッド
class SD3:
・・・
def generate_image(self, prompt, prompt_2 = None, prompt_3 = None, neg_prompt = "", neg_prompt_2 = None, neg_prompt_3 = None,seed = None):
if seed is not None:
self.generator = torch.Generator(device=self.device).manual_seed(seed)
if prompt_2 is None:
prompt_2 = prompt
if prompt_3 is None:
prompt_3 = prompt
if neg_prompt_2 is None:
neg_prompt_2 = neg_prompt
if neg_prompt_3 is None:
neg_prompt_3 = neg_prompt
image = None
image = self.pipe(
prompt=prompt,
prompt_2=prompt_2,
prompt_3=prompt_3,
negative_prompt=neg_prompt,
negative_prompt_2 = neg_prompt_2,
negative_prompt_3 = neg_prompt_3,
height = self.height,
width = self.width,
num_inference_steps=self.n_steps,
guidance_scale=self.guided_scale,
generator=self.generator
).images[0]
return image
このメソッドは、ここまでで読み込んだモデルと設定を利用して、実際に画像を生成するメソッドです。
本モデルにはText_Encoderが3つ存在します。promptを一つしか指定しない場合は、全てのEncoderに同じプロンプトが投入されますが、それぞれのEncoderごとに違うpromptも設定できるようになっています。
本メソッドの引数にてseedを指定すると、設定ファイルを上書きして、seedを指定できます。
したがって、ここで乱数を指定することで、ランダムな画像を生成できるようになります。
また、引数でseedを指定した場合は、
self.generator = torch.Generator(device=self.device).manual_seed(seed)
が呼ばれます。
一方で、引数で指定しない場合は、設定ファイルのseedが使用されて、同様のgeneratorがinitメソッドで作成されます。
したがって、生成のたびに一つ大きなseedに変更されて適用される(42→43→44)ため、生成のたびに画像を変化させることができます。
毎回ですが、下記記事を参考に実装しています
実験結果
ここからは、上記のコードによってGoogle Colabでパラメータを変更して、様々な実験を実施したため、その詳細を記載します。
実験1
まずは、こちらの記事に記載されている
Dropping the T5 Text Encoder during Inference
の章におけるdefaultの設定を採用して実験してみました。
(もっともVRAMを使わない軽い設定だと思います)
設定
[SD3]
device = auto
n_steps=28
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 7.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = False
結果
実行時間
generate image time: 35.947511196136475
generate image time: 34.840919733047485
generate image time: 33.75922894477844
Google Colabratoryでの実行のため、実行のたびに実行時間は荒ぶるため、参考程度に見てほしいが、大体30-40秒くらいで生成できるイメージだった。
生成された画像は下記に示します。正直SDXLの方が生成された画像の質は高いかなと思いました。



ただ、なぜか、CLIPエンコーダではDropされているはずの、プロンプトの後半部分も反映された画像になっているように見えます。
例えばプロンプトの下記の部分
The background features out-of-focus branches dotted with vibrant pink blossoms, set against a clear blue sky speckled with snow and bokeh, creating a dreamlike, serene atmosphere.
(日本語訳)
背景には、鮮やかなピンクの花が点在する枝がピンボケで描かれ、雪とボケが散りばめられた澄んだ青空を背景に、夢のような静謐な雰囲気を醸し出している。
この部分の情報も生成された画像には反映されているように見えます。なぜなのか・・・
知っている方いらっしゃれば教えてもらえると嬉しいです。
実験2
続いて、guided_scaleを記事で使われている7から、巷で推奨されている3.5-4.5の範囲に変更させてみたいと思います。
guided_scale = 4.0
shift = 3.0
にして実験を実施しました。
設定
[SD3]
device = auto
n_steps=28
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = False
結果
実行時間
generate image time: 36.00275254249573
generate image time: 34.94155263900757
generate image time: 33.83055567741394
生成された画像は下記に示します。



こちらの方が画質が良さそうなため、今後はguided_scale = 4.0で設定して実験します。
実験3
続いて、schedulerのshift値の変化による画像の変化を確認していきたいと思います。
巷では3.0付近を使うのを推奨されていますが、元々のFlowMatchEulerDiscreteSchedulerにてデフォルトで指定されている1.0を利用したらどうなるのか試してみたいと思います。
guided_scale = 4.0
shift = 1.0
にして実験を実施しました。
設定
[SD3]
device = auto
n_steps=28
seed=42
shift = 1.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = False
結果
実行時間
generate image time: 35.75459671020508
generate image time: 34.87065076828003
generate image time: 33.78454518318176
生成された画像は下記に示します。



意外とshift=1.0の方が良い画質になることもありました。
この辺りは生成する画像に合わせて、試行錯誤して変更するのが良いかも
実験3.5
さらに、schedulerのshift値の変化による画像の変化を確認していきたいと思います。
人間の評価で高評価を得ていると言われている6.0に設定してみました。
guided_scale = 4.0
shift = 6.0
にして実験を実施しました。
設定
[SD3]
device = auto
n_steps=28
seed=42
shift = 6.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = False
結果
実行時間
generate image time: 33.36610460281372
generate image time: 32.84304141998291
generate image time: 32.25549674034119
生成された画像は下記に示します。



若干画質がくっきりしたように見えなくもないですが、あまり大きな変化はないかなと思いました。
とはいえ、生成される画像は若干変化するので、この辺りの設定も試行錯誤していきたいですね。
いろいろ試してみて、生成される画像の質に大きな変化はないので、以降の実験はdefaultの3.0を利用します。
実験4
続いてはモデルのcompileを試してみたいと思います。
上記の記事では推論のレイテンシを向上させることができると記載されているため、実行時間の削減が期待できます。
guided_scale = 4.0
shift = 3.0
use_model_compile = True
にして実験を実施しました。
設定
[SD3]
device = auto
n_steps=28
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = True
save_latent = False
結果
実行時間
generate image time: 654.5856740474701
generate image time: 31.83198046684265
generate image time: 29.641842126846313
1回目の生成の時にcompileをしているのか、1回目は非常に時間がかかっているが、3回目の実行は今までの実行の中で一番早く実行できていることがわかりました。
生成された画像は下記に示します。



画像を確認するとcompileされたからといって、生成される画像は変化していないことがわかります。
(もしかしたら、ピクセル単位では異なる可能性はありますが、見た目では変わらないかなと思います)
また、もっと多くの回数繰り返したときにどのくらい実行時間が変わるのかも試して見ました。
20回実行しています。
実行時間
generate image time: 126.06288695335388
generate image time: 31.938198804855347
generate image time: 30.529218196868896
generate image time: 29.582070112228394
generate image time: 30.36764097213745
generate image time: 30.32581877708435
generate image time: 30.02663564682007
generate image time: 30.31864595413208
generate image time: 30.280086517333984
generate image time: 30.2621488571167
generate image time: 30.286171436309814
generate image time: 30.32650923728943
generate image time: 30.289822578430176
generate image time: 30.310792207717896
generate image time: 30.356089115142822
generate image time: 30.34636688232422
generate image time: 30.17577314376831
generate image time: 30.156757831573486
generate image time: 30.116050958633423
generate image time: 30.14829444885254
この通り、大体30秒前後で生成できていることがわかります。
compileしないパターンと比較して、5秒前後高速に生成できているようです。
実験5
続いて、大規模なText EncoderであるT5を導入してみたいと思います。
guided_scale = 4.0
shift = 3.0
use_cpu_offload = True
use_text_encoder_3 = True
にして実験を実施しました。
use_text_encoder_3 = Trueだけの場合、Google Colaboratoryの無料版GPUでは、Out of Memoryになってしまうため、CPUオフロードも行います。
CPUオフロードとは、GPUに全てのモデルデータを置くのではなく、普段は通常のRAMにデータを置いておき、計算に必要なデータだけ、GPUのVRAMに置く手法になります。
計算のたびにVRAMにデータを送ったり、入れ替えたりするため、処理時間は増加します。
設定
[SD3]
device = auto
n_steps=28
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = True
use_text_encoder_3 = True
use_t5_quantization = False
use_model_compile = False
save_latent = False
結果
T5のモデルが大きすぎて、CPUオフロードした場合、Google ColaboratoryのシステムRAM12.7GBを使い切ってしまい、SD3クラスのgenerate_imageメソッド実行中にクラッシュしてしまったので実行不可でした。
実験6
CPUオフロードだけでは、計算リソースの不足で実験不可だったため、T5の量子化も試してみます。
guided_scale = 4.0
shift = 3.0
use_text_encoder_3 = True
use_t5_quantization = True
にして実験を実施しました。
use_text_encoder_3 = Trueだけの場合、Google Colaboratoryの無料版GPUでは、Out of Memoryになってしまうため、量子化も行います。
また、今回の量子化はbitsandbytesライブラリを使って量子化しているため、モデルはすでに適切なデバイスに格納されています。(つまり、すでにCPUオフロードがされている状態)
したがって、`use_cpu_offload`の設定は変更しても意味がないように実装しています。
設定
[SD3]
device = auto
n_steps=28
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = True
use_t5_quantization = True
use_model_compile = False
save_latent = False
結果
実行時間
generate image time: 74.37092518806458
generate image time: 60.2897834777832
generate image time: 60.057732582092285
大規模なText EncoderであるT5(量子化バージョン)を利用しているため、T5をDropしていたこれまでの実験結果と比較して、実行時間が長くなっております。
生成された画像は下記に示します。



確かにT5がある方がプロンプトの追従性が上がっているかもしれないです。
心なしか、画像の質も高いような。。。
もしかしたら、Text Encoderにも画像の質を左右するような重みが学習されているのか?とも思ったり。
詳しい方いましたら教えてください。
実験7
T5を導入すると、実行時間が長くなってしまうため、実行時間の削減を期待して、compileも試してみたいと思います。
guided_scale = 4.0
shift = 3.0
use_text_encoder_3 = True
use_t5_quantization = True
use_model_compile = True
にして実験を実施しました。
T5の量子化に加えて、compileも実行します。処理時間がどのくらい短くなるかが見ものです。
設定
[SD3]
device = auto
n_steps=28
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = True
use_t5_quantization = True
use_model_compile = True
save_latent = False
結果
残念ながら下記のエラーが発生しました。
--> 197 pipe.transformer.to(memory_format=torch.channels_last)
198 pipe.vae.to(memory_format=torch.channels_last)
199
/usr/local/lib/python3.10/dist-packages/accelerate/big_modeling.py in wrapper(*args, **kwargs)
453 for param in model.parameters():
454 if param.device == torch.device("meta"):
--> 455 raise RuntimeError("You can't move a model that has some modules offloaded to cpu or disk.")
456 return fn(*args, **kwargs)
457
RuntimeError: You can't move a model that has some modules offloaded to cpu or disk.
この通り、量子化した場合、データはオフロードもされているため、コンパイルを実施することはできないらしいです。
したがって、T5の量子化とコンパイルの両立はできないことがわかりました。
もちろん、量子化しない状態でT5を使った場合は、コンパイルも可能ですが、実行可能なGPUを持っていないため、実験できないことをご了承ください。
実験8
今度は趣向を変えて、1stepごとの生成途中の画像を見てみましょう。
とは言っても、SD3は画像自体に拡散プロセスを適応しているわけではなく、VAEの潜在表現に対して拡散プロセスを適用しているため、各ステップごとに得られるのは、生成途中の潜在表現のみになります。
SD3の潜在表現は(1,16,128,128)という型のため、そのまま取得しても画像として表示できません。
したがって、得られた潜在表現(ノイズ混じりの途中のも含めて)をSD3のVAE Decoderに入力して復元させたものを表示してみることにします。
そのためにmodule/module_sd3.pyのSD3クラスのgenerate_imageメソッドを下記のように変更します。
(Githubに保存されているコードはすでに変更済みのため、作業は不要です)
(興味のある方だけ解説をご覧ください)
変更の解説
下記のように変更しています。
(Githubに保存されているコードはすでに変更済みのため、作業は不要です)
class SD3:
・・・
def generate_image(self, prompt, prompt_2 = None, prompt_3 = None, neg_prompt = "", neg_prompt_2 = None, neg_prompt_3 = None,seed = None):
def decode_tensors(pipe, step, timestep, callback_kwargs):
latents = callback_kwargs["latents"]
image = latents_to_rgb(latents,pipe)
gettime = time.time()
formatted_time_human_readable = time.strftime("%Y%m%d_%H%M%S", time.localtime(gettime))
image.save(f"./outputs/latent_{formatted_time_human_readable}_{step}_{timestep}.png")
return callback_kwargs
def latents_to_rgb(latents,pipe):
latents = (latents / pipe.vae.config.scaling_factor) + pipe.vae.config.shift_factor
img = pipe.vae.decode(latents, return_dict=False)[0]
img = pipe.image_processor.postprocess(img, output_type="pil")
return StableDiffusion3PipelineOutput(images=img).images[0]
if seed is not None:
self.generator = torch.Generator(device=self.device).manual_seed(seed)
if prompt_2 is None:
prompt_2 = prompt
if prompt_3 is None:
prompt_3 = prompt
if neg_prompt_2 is None:
neg_prompt_2 = neg_prompt
if neg_prompt_3 is None:
neg_prompt_3 = neg_prompt
image = None
if self.save_latent:
image = self.pipe(
prompt=prompt,
prompt_2=prompt_2,
prompt_3=prompt_3,
negative_prompt=neg_prompt,
negative_prompt_2 = neg_prompt_2,
negative_prompt_3 = neg_prompt_3,
height = self.height,
width = self.width,
num_inference_steps=self.n_steps,
guidance_scale=self.guided_scale,
generator=self.generator,
callback_on_step_end=decode_tensors,
callback_on_step_end_tensor_inputs=["latents"],
).images[0]
else:
image = self.pipe(
prompt=prompt,
prompt_2=prompt_2,
prompt_3=prompt_3,
negative_prompt=neg_prompt,
negative_prompt_2 = neg_prompt_2,
negative_prompt_3 = neg_prompt_3,
height = self.height,
width = self.width,
num_inference_steps=self.n_steps,
guidance_scale=self.guided_scale,
generator=self.generator
).images[0]
return image
pipeをcallするときに、新たにcallback_on_step_endとcallback_on_step_end_tensor_inputsを引数に追加しています。
callback_on_step_endは各ステップごとにその終わりに呼び出すコールバックを指定することができる引数です。この引数により指定されたコールバック関数が、callback_on_step_end_tensor_inputsにより指定された情報を引数にして呼び出されます。
このコールバック関数により、SD3モデルから引数に持って来れる情報は下記のコードをご覧ください。
上記のコードの__call__メソッドに記載されているcallback_outputsに格納しているlatentsとprompt_embedsとnegative_prompt_embedsとnegative_pooled_prompt_embedsが取得可能だと思われます。
ここで指定しているコールバック関数はdecode_tensorsです。その中で取得したlatents(つまり拡散プロセス適用中の潜在表現)を画像の変換して保存しています。
(保存先はべたがきしてしまっています)
潜在表現から画像に変換する関数としてlatents_to_rgbを定義しています。
ここでは、SD3のVAEのdecodeメソッドを取得して画像化しています。
(コードは上記のpipeline_stable_diffusion_3.pyを参考に記載しています)
この処理を各拡散プロセスの終了時にコールバック関数として呼び出され、実行されます。
save_latent = True
にして実験を実施しました。
(この設定をすることで、生成途中の潜在表現から画像を再構成して保存できます)
設定
[SD3]
device = auto
n_steps=28
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = True
結果
生成途中の潜在表現からVAEで画像に再構成した画像が下記のようになります。
枚数が多いので、生成順に並べてGIFにしたものを表示します。

この通り、ノイズが少しずつ除去されて、画像が生成されている様子がわかるかと思います。
実験9
続いては、step数の変化による画像の変化をみたいと思います。
SD3は直線的な微分方程式を解くため、step数が減っても問題なく画像を生成できるのではないかと思った次第です。(この辺りは自信がないので、理解が間違っていたら教えてください。)
n_steps=14
にして実験を実施しました。
推奨ステップ数の半分です
設定
[SD3]
device = auto
n_steps=14
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = False
結果
実行時間(14step)
generate image time: 17.692556381225586
generate image time: 17.215643167495728
generate image time: 16.85261869430542
step数が半分になってことで、生成にかかる時間もちょうど半分くらいになっています。
生成された画像は下記に示します。



意外と14stepでもかなり綺麗な画像になっているかなと思います。
特に2枚目とか好きです。手の表現は28stepと比較して若干甘いかなと思いました。
実験10
続いては7stepにしてみます。
n_steps=7
にして実験を実施しました。
設定
[SD3]
device = auto
n_steps=7
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = False
結果
実行時間(7step)
generate image time: 11.650048971176147
generate image time: 8.618378162384033
generate image time: 8.722979307174683
生成された画像は下記に示します。



若干、ぼやぼやっとしてきた感じはありますが、それでもまだ綺麗な画像が出ていると思います。
え、7stepでもこんなに綺麗な画像になるの?とちょっと驚いております。
実験11
続いては4stepです。
SDXL Turboで使っていたStep数になります。
n_steps=4
にして実験を実施しました。
設定
[SD3]
device = auto
n_steps=4
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = False
結果
実行時間(4step)
generate image time: 7.127336740493774
generate image time: 5.429738998413086
generate image time: 5.420844078063965
処理時間はかなり短くなりました。
生成された画像は下記に示します。



4stepになるとかなり崩れてしまっていますね。
2枚目とかは、ギリギリ顔を保っていますが、背景は完全にぼやけてしまっていますし、そのほかの画像は全体的にぼやけています。
実験12
うまくいかないことはわかっていますが、最後ですので。
n_steps=1
にして実験を実施しました。
設定
[SD3]
device = auto
n_steps=1
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = False
結果
実行時間(1step)
generate image time: 3.160846710205078
generate image time: 2.0624654293060303
generate image time: 2.028672933578491
生成された画像は下記に示します。



残念ながら1 stepではほとんどノイズのような画像になってしまいました。
しょうがないですね・・・
実験13
今度はStep数を標準の28から増やしてみようと思います。
最初は少しだけ増やしてみます。
n_steps=35
にして実験を実施しました。
設定
[SD3]
device = auto
n_steps=35
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = False
結果
実行時間(35step)
generate image time: 41.11394023895264
generate image time: 42.15063142776489
generate image time: 43.37374567985535
生成された画像は下記に示します。



微妙ではありますが、少しだけ解像感が上がったように見えます
(実験2と比較して)
この解像感のUPのために、10秒ほどの処理時間の増加を受け入れるかどうかですね。
実験14
続いては
n_steps=50
にして実験を実施しました。
SDXLでの標準のstep数です。
設定
[SD3]
device = auto
n_steps=50
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = False
結果
実行時間(50step)
generate image time: 61.70908522605896
generate image time: 60.577409982681274
generate image time: 60.86574172973633
生成された画像は下記に示します。



あれ?50 stepになると生成される画像の質が下がったような気がする・・・
いや、そうでもないのか?ちょっと判断できない。
実験15
最後に
n_steps=80
にして実験を実施しました。
数字は適当に設定しました
設定
[SD3]
device = auto
n_steps=80
seed=42
shift = 3.0
model_path = stabilityai/stable-diffusion-3-medium-diffusers
guided_scale = 4.0
width = 1024
height = 1024
use_cpu_offload = False
use_text_encoder_3 = False
use_t5_quantization = False
use_model_compile = False
save_latent = False
結果
実行時間(80step)
generate image time: 97.74183487892151
generate image time: 96.70283508300781
generate image time: 96.58707213401794
実行時間は大幅に増えました。
生成された画像は下記に示します。



結果、50stepとほとんど変わらない結果になりました。
少なくとも、目で見て判断できません。
まとめ
今回は、初心者向けにGoogle Colaboratoryで、簡単に生成AIを使えるようにする環境を作りました。
Part8の今回は、生成AIの一つ、画像生成AIのStable Diffusion 3 Mediumモデルを使えるようにしました。
今回は、初めて使うモデルだったこともあり、色々実験してみました。
色々実験してみてわかったことは
-
Shiftは3.0、guided_scaleは4.0を利用する - T5はなるべく利用した方が、生成される画像の質が高い
- 処理時間を優先したい場合は7-14 stepくらいまでなら、step数を減らしても、画像の画質は保てそう。
記述内容などで間違っている部分があればご教授ください。よろしくお願いします!
次回は、SD3でcontrolnetを試してみたいと思います!
Discussion