初めてのSageMaker AIでSFTTrainerによるLLMのフルパラメータファインチューニングを試す
はじめに
業務でAWSを利用してAIの学習をする必要があり、勉強としてSageMaker AIを使ってみたので、その忘備録として置いておきます。
(わかりやすくて、最近のSageMaker AIの記事があまりなかったので、参考になれば幸いです)
最終的には、AWSのSageMaker環境を利用して、下記の記事の内容でLLMを学習してみようと思います。
SageMaker AIの設定をする
SageMaker AIの設定をする
AWSのコンソールから「Amazon SageMaker AI」サービスの入ります。

「シングルユーザ向けの設定」をクリックします。

下記のように「SageMaker Domain を準備しています。」と表示されるので、終わるまで気長に待ちます。数分から十数分かかることもあります。

準備が終わったら、場合に応じて「ストレージの設定」を変更してください。
ストレージのdefaultとMaxを変えておくと、AIの重みなどをたくさん保存できます。
変更する場合は、「編集」を押してください。

ここでは一旦、下記のようにdefaultを100GB、maxを500GBに設定しておきます。
そしたら、ページ下部の「送信」を押してください。

このページで、s3リソースの設定もできます。今回はスキップします。
設定が終わったら、左タブの「Studio」をクリックします

今作ったドメインになっていることを確認して、「Studioを開く」をクリックしてください。

StudioにてJupyterLabを利用する
下記のような画面になっていると思うので、左上の「JupyterLab」のアイコンをクリックしてください。
(左側のタブは、現在のカレントディレクトリが表示されています。デフォルトでEFSがマウントされています)

右上の「Create JupyterLab space」をクリックしてください。

名前を設定して、「Create space」をクリックしてください。
名前にはハイフン以外の記号は使えません。

下記のような画面が出ると思います。
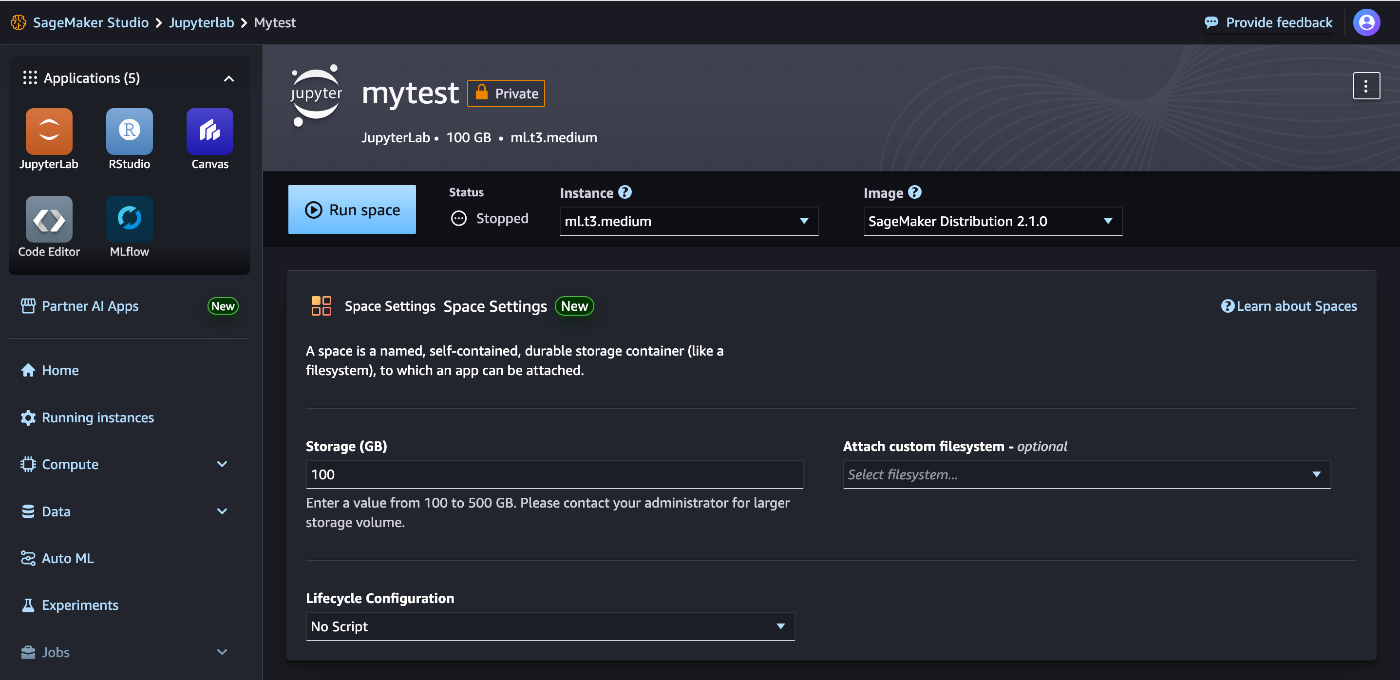
ここで設定するのは、「Instance」と「Strage(GB)」です。
Strageは一旦100GBで良いのでこのままにします。
Instanceは、今回LLMを学習するので、「ml.g4dn.xlarge」や「ml.p3.2xlarge」に設定しましょう。
今回は、早く立ち上げるために「ml.g4dn.xlarge」を選択しました。

「Run space」をクリックします。Instanceによっては数分から十数分立ち上げに時間がかかりますので、気長にお待ちください。

立ち上がると、下記のような画面になります。
「Open JupyterLab」をクリックしてください。

JupyterLabでの操作
GPUの確認
立ち上げると下記のような画面になります。
GPUなどの確認のために、Terminalをクリックしてください。

コンソール画面が立ち上がるので、nvidia-smiコマンドを実行してみましょう
するとT4 GPUが利用できることがわかります。
Instanceに応じて、より強いGPUを利用することも可能です。

また、この環境はすでにかなりのpythonパッケージがインストールされています。
それらを確認したいときは、Terminalから下記コマンドで確認することもできます。
pip list
Notebookを使う
続いて、タブの右の「+」を押して「Launcher」を表示し、「notebook」の「Python3」をクリックしてください。

すると下記の画面が表示されます。まずは、Notebookの名前を変更しましょう。

左のタブの「Untitled.ipynb」を右クリックして、「Rename」をクリックしましょう

適当に名前をつけてください。記事では「sample.ipynb」に変更しました

これで準備は完全に完了です。
Notebookを編集・実行
今回は、下記の「npaka」様の記事の内容を踏襲して、AWSのSageMaker AIで学習することを目的にします。
基本的にはこのコードをそのまま利用で良いです。
ただし、モジュールをインストールする部分だけ、そのままだと既存のモジュールとの依存関係のせいでtrlのimportができません。
また、モデルの保存先もEFSの中を指定してみようと思います。他のリソースからも接続ができるようになりますので。
そこで下記のようにセルにコードを記載してください。
セルを記載したら、上から順番に「shift+Enter」で実行してください。
コードと実行結果の簡単な説明
詳細な説明は、元記事に記載されておりますので、忘備録のために簡単に記載していきます。
1セル目
# パッケージのインストール
!pip uninstall autogluon autogluon.timeseries autogluon.multimodal -y
!pip install --upgrade trl peft datasets transformers
パッケージをインストールしますが、すでに環境にインストールされているものはそのままにしておきます。
autogluon系は、そのままにしておくと、様々なパッケージとの依存関係に悩まされ、trlのimportがエラーになるため、もうアンインストールしました。
エラーの内容
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
File /opt/conda/lib/python3.11/site-packages/transformers/utils/import_utils.py:1390, in _LazyModule._get_module(self, module_name)
1389 try:
-> 1390 return importlib.import_module("." + module_name, self.__name__)
1391 except Exception as e:
File /opt/conda/lib/python3.11/importlib/__init__.py:126, in import_module(name, package)
125 level += 1
--> 126 return _bootstrap._gcd_import(name[level:], package, level)
File <frozen importlib._bootstrap>:1204, in _gcd_import(name, package, level)
File <frozen importlib._bootstrap>:1176, in _find_and_load(name, import_)
File <frozen importlib._bootstrap>:1147, in _find_and_load_unlocked(name, import_)
File <frozen importlib._bootstrap>:690, in _load_unlocked(spec)
File <frozen importlib._bootstrap_external>:940, in exec_module(self, module)
File <frozen importlib._bootstrap>:241, in _call_with_frames_removed(f, *args, **kwds)
File /opt/conda/lib/python3.11/site-packages/transformers/trainer.py:65
64 from .hyperparameter_search import ALL_HYPERPARAMETER_SEARCH_BACKENDS, default_hp_search_backend
---> 65 from .image_processing_utils import BaseImageProcessor
66 from .integrations.deepspeed import deepspeed_init, deepspeed_load_checkpoint, is_deepspeed_available
File /opt/conda/lib/python3.11/site-packages/transformers/image_processing_utils.py:20
18 import numpy as np
---> 20 from .image_processing_base import BatchFeature, ImageProcessingMixin
21 from .image_transforms import center_crop, normalize, rescale
File /opt/conda/lib/python3.11/site-packages/transformers/image_processing_base.py:29
28 from .feature_extraction_utils import BatchFeature as BaseBatchFeature
---> 29 from .utils import (
30 IMAGE_PROCESSOR_NAME,
31 PushToHubMixin,
32 add_model_info_to_auto_map,
33 add_model_info_to_custom_pipelines,
34 cached_file,
35 copy_func,
36 download_url,
37 is_offline_mode,
38 is_remote_url,
39 is_vision_available,
40 logging,
41 )
44 if is_vision_available():
ImportError: cannot import name 'add_model_info_to_custom_pipelines' from 'transformers.utils' (/opt/conda/lib/python3.11/site-packages/transformers/utils/__init__.py)
The above exception was the direct cause of the following exception:
RuntimeError Traceback (most recent call last)
File /opt/conda/lib/python3.11/site-packages/trl/import_utils.py:100, in _LazyModule._get_module(self, module_name)
99 try:
--> 100 return importlib.import_module("." + module_name, self.__name__)
101 except Exception as e:
File /opt/conda/lib/python3.11/importlib/__init__.py:126, in import_module(name, package)
125 level += 1
--> 126 return _bootstrap._gcd_import(name[level:], package, level)
File <frozen importlib._bootstrap>:1204, in _gcd_import(name, package, level)
File <frozen importlib._bootstrap>:1176, in _find_and_load(name, import_)
File <frozen importlib._bootstrap>:1147, in _find_and_load_unlocked(name, import_)
File <frozen importlib._bootstrap>:690, in _load_unlocked(spec)
File <frozen importlib._bootstrap_external>:940, in exec_module(self, module)
File <frozen importlib._bootstrap>:241, in _call_with_frames_removed(f, *args, **kwds)
File /opt/conda/lib/python3.11/site-packages/trl/trainer/sft_trainer.py:28
27 from huggingface_hub.utils._deprecation import _deprecate_arguments
---> 28 from transformers import (
29 AutoModelForCausalLM,
30 AutoTokenizer,
31 BaseImageProcessor,
32 DataCollator,
33 DataCollatorForLanguageModeling,
34 FeatureExtractionMixin,
35 PreTrainedModel,
36 PreTrainedTokenizerBase,
37 ProcessorMixin,
38 Trainer,
39 is_wandb_available,
40 )
41 from transformers.trainer_callback import TrainerCallback
File <frozen importlib._bootstrap>:1229, in _handle_fromlist(module, fromlist, import_, recursive)
File /opt/conda/lib/python3.11/site-packages/transformers/utils/import_utils.py:1380, in _LazyModule.__getattr__(self, name)
1379 elif name in self._class_to_module.keys():
-> 1380 module = self._get_module(self._class_to_module[name])
1381 value = getattr(module, name)
File /opt/conda/lib/python3.11/site-packages/transformers/utils/import_utils.py:1392, in _LazyModule._get_module(self, module_name)
1391 except Exception as e:
-> 1392 raise RuntimeError(
1393 f"Failed to import {self.__name__}.{module_name} because of the following error (look up to see its"
1394 f" traceback):\n{e}"
1395 ) from e
RuntimeError: Failed to import transformers.trainer because of the following error (look up to see its traceback):
cannot import name 'add_model_info_to_custom_pipelines' from 'transformers.utils' (/opt/conda/lib/python3.11/site-packages/transformers/utils/__init__.py)
The above exception was the direct cause of the following exception:
RuntimeError Traceback (most recent call last)
Cell In[14], line 1
----> 1 from trl import SFTTrainer
3 # 学習の実行
4 trainer = SFTTrainer(
5 model=model,
6 tokenizer=tokenizer,
(...)
9 max_seq_length=512,
10 )
File <frozen importlib._bootstrap>:1229, in _handle_fromlist(module, fromlist, import_, recursive)
File /opt/conda/lib/python3.11/site-packages/trl/import_utils.py:91, in _LazyModule.__getattr__(self, name)
89 elif name in self._class_to_module.keys():
90 module = self._get_module(self._class_to_module[name])
---> 91 value = getattr(module, name)
92 else:
93 raise AttributeError(f"module {self.__name__} has no attribute {name}")
File /opt/conda/lib/python3.11/site-packages/trl/import_utils.py:90, in _LazyModule.__getattr__(self, name)
88 value = self._get_module(name)
89 elif name in self._class_to_module.keys():
---> 90 module = self._get_module(self._class_to_module[name])
91 value = getattr(module, name)
92 else:
File /opt/conda/lib/python3.11/site-packages/trl/import_utils.py:102, in _LazyModule._get_module(self, module_name)
100 return importlib.import_module("." + module_name, self.__name__)
101 except Exception as e:
--> 102 raise RuntimeError(
103 f"Failed to import {self.__name__}.{module_name} because of the following error (look up to see its"
104 f" traceback):\n{e}"
105 ) from e
RuntimeError: Failed to import trl.trainer.sft_trainer because of the following error (look up to see its traceback):
Failed to import transformers.trainer because of the following error (look up to see its traceback):
cannot import name 'add_model_info_to_custom_pipelines' from 'transformers.utils' (/opt/conda/lib/python3.11/site-packages/transformers/utils/__init__.py)
2セル目
from transformers import AutoModelForCausalLM, AutoTokenizer
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"cyberagent/open-calm-small"
)
model = AutoModelForCausalLM.from_pretrained(
"cyberagent/open-calm-small",
device_map="auto"
)
今回学習する小さなLLMの、モデルとトークナイザーをHuggingfaceからダウンロードしてきます。
3セル目
import torch
# プロンプトの準備
prompt = "この映画は"
# 推論の実行
for i in range(10):
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
tokens = model.generate(
**inputs,
max_new_tokens=64,
do_sample=True,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.05,
pad_token_id=tokenizer.pad_token_id,
)
output = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(output)
print("----")
このモデルは、Instructモデルではなくbaseモデルのため、文章の続きを書くモデルになります。
今回は「この映画は」に続く文章を、最大64token、10回分出力します。
出力結果は、「この映画は」に続く様々な文章が生成されると思います
出力
この映画は、ドラマ『ドクター・フー』のスピンオフとして制作され、脚本は『Death Note/デスノート』のジム・オルークが担当する。
あらすじ
西暦2049年。地球では、人類が戦争によって滅亡の危機に瀕している。しかし、かつて人類は地上から死滅し、その
----
この映画は、また、映画「The Other Side of the Story」も素晴らしい。
原作は、映画『The Other Side of the Story』の作者、J・A・バヨナの作品である。監督は、映画『The Other Side of the Story』で脚本を務めた
----
この映画は、この物語の主人公「ルビー」を、元・お嬢さまのジュリエッタが演じています。
また、この作品には、ルビー役にも出演した「リゼット」という声優も出演しています。
また、ルビー役には、「エンマ大王」の「エリザベス」ことエリザベス・オル
----
この映画は、映画ファンだけでなく、映画を観る人にとっても、新たな体験になるかもしれません。
さらに、本作には、3つの“HOLLYWOOD”と、5つの異なる“THE BEATLES”という、2つの世界が同時に描かれています。その3つの世界とは、「LOVE」と「STAY」、
----
この映画は、映画『スター・ウォーズ』シリーズのスピンオフ作品です。
宇宙海賊キャプテンハーロックに憧れる少年ルーク・スカイウォーカーは、ある日、謎の少女レイア・オーガナと出会い、彼女に惹かれていく。しかし、レイアはレイアと出会った直後に、突如として銀河帝国へと乗り移る。そして、レイア
----
この映画は、
「世界の映画祭」に、
2012年4月13日(土)~10月20日(日)
に、
「世界の映画祭」にて出品されます。
(会場:東京国際フォーラム)
また、
『映画村』では、
「映画村」で、
----
この映画は、とても面白かった。
僕はあまりよく知らないが、このアニメは「青春アドベンチャー」として、いろいろな人に勧められているようだ。
「青春アドベンチャー」も悪くはないのだが、内容としてはそれほど好きではない。
でも、この映画で特に印象に残っているのは、主人公のカミナリ(小栗旬)と、カ
----
この映画は、原作にはないキャラクター設定や設定画など、その世界観をより引き立てるよう、さまざまな工夫がされている。
しかし、原作と大きく異なる点は、原作とストーリー上の違いだ。原作では、神主として登場する「神木」という人物の設定が、映画では「神主」として描かれている。原作では、主人公
----
この映画は、映画『ダンケルク』や『ブラックパンサー』などに出演したクリス・エヴァンスが、自身の監督作品『ダンケルク』で監督を務めたことから、本作について語り合うシーンがある。
また、前作の監督であるトム・ハンクスから、「このアイデアには本当に驚かされました」と、本作についてコメントが
----
この映画は、映画と小説という2つのメディアで展開され、そのどちらもが1つの物語として綴られています。
映画『ロード・オブ・ザ・リング』は、世界を支配する「ガンダルフ」と、その父である「バロン・ナジーム」を描いた壮大な冒険物語です。
この物語は、「
----
4セル目
from datasets import load_dataset
# データセットの読み込み読み込み
dataset = load_dataset("tyqiangz/multilingual-sentiments", "japanese")
# 確認
print(dataset)
print(dataset["train"][0])
続いて、学習用のデータセットをHuggingfaceから取得します。 このデータセットは、肯定、中立、否定の3つのグループに分けた多言語感情データセットらしいです。
今回は日本語の学習をするので、日本語の文章のみを取得しています。
出力として、どんな形式か、そんなテキストが入っているのかが表示されるはずです。
5セル目
# データセットをpositiveのみ5000個でフィルタリング
train_dataset = dataset["train"].filter(lambda data: data["label"] == 0).select(range(5000))
# 確認
print(train_dataset)
print(train_dataset[0])
今夏は、出力結果がわかりやすいように、肯定的なデータのみを学習させます。
(学習結果が肯定的な文章のみを生成するようになれば成功です)
したがって、データのラベルが0のものだけを学習用データセットとして取得しています。
また、学習がすぐ終わるように、最初の5000データのみを取得しています。
出力結果では、肯定的な文章の例と、データの形式が出力されているはずです。
6セル目
from trl import SFTTrainer
# 学習の実行
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=train_dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()
# モデルの保存
trainer.save_model("./user-default-efs/output")
このセルでは学習を行っています。
SFTTrainerを使うことで簡単に学習できるのが良いですね。
最終的なモデルはEFSの中である./user-default-efs/outputに保存するようにしています。
学習時間は8分くらいかかりました。
下記のように、stepごとのTraining Lossも表示されます。

7セル目
# モデルの準備
model = AutoModelForCausalLM.from_pretrained(
"./user-default-efs/output",
device_map="auto"
)
モデルの重みファイルを今回学習したものでロードし直しています。
これで、学習した重みを利用できます。
8セル目
import torch
# プロンプトの準備
prompt = "この映画は"
# 推論の実行
for i in range(10):
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
tokens = model.generate(
**inputs,
max_new_tokens=64,
do_sample=True,
temperature=0.7,
top_p=0.9,
repetition_penalty=1.05,
pad_token_id=tokenizer.pad_token_id,
)
output = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(output)
print("----")
最後に、3セル目と同様に「この映画は」から始まる文章が生成されています。
生成結果を見るとわかるように、肯定的な意見の文章だけが出力されています。
意味があるかは置いておいて、学習は成功です。
出力
この映画は、とてもいい映画でした。 見ていて癒されます。 買ってよかったです。 ありがとうございました。 また、よろしくお願いします。 友達にもお勧めしたいです。 ありがとうございました。 良い作品でした。 評価が良かったです。 本当に良かったです。 有難うございました。 とても満足です。 購入ありがとうございました。 購入ありがとうございました。 とても良い
----
この映画は、とても良かったです。 今まで映画を見ていないので、とても新鮮です。 特に、銃が怖いです。 もう少し、手触りが柔らかい方が良かったと思います。 銃は、非常に危険で危険なものなので、慎重に扱わないと怖いですね。 あと、主人公が銃を撃つシーンは、とても感動的です。
----
この映画は、とても良かった。 本当に良い買い物ができた。ありがとうございました。 また買いたい。 次も購入します。 本当に良かったです。 ありがとうございました。 また是非購入したいです。 ありがとうございました。 とても満足しています。 ありがとうございます。 これからも頑張ってください。 ありがとうございました。 ありがとうございました。 良い買い物ができた。 次
----
この映画は、映画館で観ました。 本当にいい映画でした。 見終わった後、私の心を鷲掴みにしたと思います。 とてもよかったですね! これからも楽しみにしています。 ありがとうございました。 また、機会があれば是非観てみてください。 追記:DVDで2本同時発売されましたが、こちらの方が良いかと思います。
----
この映画は、とても良かったです。 ストーリーもすごく面白いです! 良い映画でした! 映画館が、とても綺麗で、とてもよかったです。 素晴らしい映画でした。 良い映画でした! とても良い映画です。 とてもいい映画です。 素晴らしいです。 良い映画でした。 良い映画でした! 良い映画
----
この映画は、とても良かったです。 主人公の女の子は、母親から虐待されて、そして家族を殺され、そのせいで、娘を失いました。 彼女は、本当に悲しくて、愛しくて、孤独で、そして、絶望的で、そして、非常に悲惨です。 私はそれを忘れることができない、私はそれが何かを知っていると思います。 私達は
----
この映画は、 とても良かったです。 私も欲しいです。 値段もお手頃で、買ってよかったです。 良い買い物をしました。ありがとうございました。 また機会があれば購入したいです。 これからも頑張って下さい。 今後もよろしくお願いします。 ありがとうございました。 これからも頑張ってください。 次回も注文します。 ありがとうございました。 また何かありましたら、よろしくお願いします。
----
この映画は、テレビで見るより、はるかに良い! 映画館にいるような気分になるし、映画館の映画館のような雰囲気を味わうことができる。 私達は映画が好きなので、このビデオが私を驚かせることを期待している。 素晴らしい作品をありがとう。 素晴らしい作品、素晴らしい映画をありがとう! あなたはまた、あなたの人生を幸せにするために、あなたが望む
----
この映画は、 見たら絶対に買いたいと思います。 ストーリーも面白いし、音楽も最高です。 見終わった後、子供達にプレゼントしたいです。 ありがとうございました。
とてもいい本です。また、注文した翌日に届き、迅速な対応に安心しました。とても満足しています。ありがとうございます。
----
この映画は、私の人生の中で最高の1本です。 私が持っている一番のお気に入りです。 音楽は、音楽を聴くために完璧な音を出します。 最高のオーディオ体験を得ることができます! 私はこれを本当に期待している! 素晴らしい映画を見て、私はそれについてもっと良いものを見つけるでしょう! もう一度買うつもりです。 ありがとう。
----
学習結果の保存
全ての処理が完了した後、学習済み重みは./user-default-efs/outputにあります。
左側のタブを辿って、./user-default-efs/outputの中身を表示してください。

このファイルを一つ一つ右クリックから「Download」をクリックするとダウンロードができます。ローカルに保存したい場合は、この方法で一つ一つ保存してください。

また、./tmp_trainerフォルダの中には、500stepごとに、学習途中のcheckpointが出力されます。
途中の内容も保存したい方は、このフォルダの中も同様に保存してください。
まとめ
ここまでで、初めて「SageMaker AI」を利用して、簡単にLLMをSFTTrainerによるフルパラメータファインチューニングをしてみるところまで試してみました。
皆様の手助けになれば幸いです。
最後にLLM系の記事を書く、勉強するにあたって参考にさせていただいた記事、書籍を記載しておきます。
Webサイト
Google Colab で SFTTrainer によるLLMのフルパラメータのファインチューニングを試す
SFT Trainer
書籍
(下記、Amazonアフィリエイトリンクになります)
LLMのファインチューニングとRAG ―チャットボット開発による実践
大規模言語モデル入門Ⅱ〜生成型LLMの実装と評価
上記2冊とも、LLMの学習に関して詳細に解説している数少ない書籍です。
(Fine Tuning, Instruction Tuning, LoRA, QLoRAなど取扱範囲も多いです)
ここまで読んでくださりありがとうございました!
Discussion