Google CloudのVector StoreでRAG Agentsを構築する【Big Querty編】
はじめに
今回の記事は、これまでの記事の続編です。 (これまでの記事を参照して欲しいところは、適宜リンクを貼るようにします)
前回の記事では、ローカルのフォルダに格納されたドキュメントと、ローカルのChroma DBをVector Storeに採用してRAGのAgentsを構築しました。
今回は、Google CloudのBigQueryというサービスをVector Storeとして利用し、Google Cloud Strage(GCS)上のドキュメントを参照するRAGのシステムを構築することを考えていきます。
下記のチュートリアルを参考にしつつ、前回の記事でのドキュメントストレージとVector Storeを置き換える形で実装していきます。
例によって、自分の備忘録の側面が強いですが、参考になれば幸いです。
(公式のチュートリアルは多いんですが、わかりやすい解説記事は少ないんですよね)
RAGのVector Storeとして利用できるデータストア
ちなみに、今後の記事の流れにも関連しますが、現在Google CloudにてVector StoreをLangChainから利用するには、下記のデータストアが選択肢になります。
それらに対して、どのように利用するのかを今後解説したいと思います。
- BigQuery
langchain_google_community
- Vertex AI Vector Search
langchain_google_vertexai
- Cloud SQL for PostgreSQL
langchain-google-cloud-sql-pg-python
- Cloud SQL for MySQL
langchain-google-cloud-sql-mysql-python
- AlloyDB for PostgreSQL
langchain-google-alloydb-pg-python
- Firestore
langchain-google-firestore-python
- Spanner
langchain-google-spanner-python
- Memorystore for Redis
langchain-google-memorystore-redis-python
上がデータストア名で、下が利用するライブラリになります。(めちゃくちゃ多い・・・)
(調べきれていないだけで、他にもあるかもです)
今回は、BigQueryをVector Storeとして利用する場合の解説記事です。
次回以降に、そのほかのデータストアを利用する場合の記事を書きますが、基本的な流れは本記事と同じになります。
網羅的に、さまざまなデータストアを利用したときの実装方法などを解説する記事は少ないと感じましたので、参考になれば幸いです!
BigQueryは、使ってない時間はコストがかからないので、比較的リーズナブルに利用することが可能です。
とりあえず使ってみるという観点では、一番最初の選択肢になると思います。
参考書籍
(書籍のリンクはamazonアフィリエイトリンクになります)
記事
LangChain と Google Cloud データベースを使用して強化された生成 AI アプリケーションを構築する
LangChainのチュートリアル記事「Google BigQuery Vector Search」
Google APIのリスト
2024/9/1 langchain-google-vertexai は ChatVertexAI を使うべし
書籍
Generative AI on Google Cloud with LangChain: Design scalable generative AI solutions with Python, LangChain, and Vertex AI on Google Cloud
英語ではありますが、非常に分かりやすい書籍です。
というか、現在においてLangChain+Google Cloudを取り巻くライブラリの複雑さは異常だと思っています。
各DBごとに必要なライブラリが乱立しており、どのライブラリを利用するのが良いのかが分かりにくいです。(なぜなら技術記事では、一つのライブラリ、一つのDBにフォーカスしており、他にどんな選択肢があるのかが分かりにくい)
本書籍は、それらをすべて統括して分かりやすく記載されているため、全体像が掴みやすくおすすめの書籍になっています。
英語の本ではありますが、購入時にPDFも一緒に取得することができる(2025年2月現在)ため、「Google 翻訳」のPDF変換機能で翻訳することで、英語がわからなくても読むことができますので、ぜひお試しください。
(PDFが取得可能かどうかは、Amazonの商品概要欄に記載してありますので、購入前にお確かめください)
LangChainとLangGraphによるRAG・AIエージェント[実践]入門
ChatGPT/LangChainによるチャットシステム構築[実践]入門
LangChainを利用することで、あらゆるモデルを統一的なコードで実行できるようになります。
langchainに関しては、こちらの書籍を読めば大体のことはできるようになりますので、おすすめです。
また、現在推奨されているLangGraphでのRAG Agentを構築するcreate_react_agentに関しても説明されておりますし、さらに複雑なAgentsの構築方法やデザイン方法も網羅されており、とても勉強になります!
大規模言語モデル入門
大規模言語モデル入門Ⅱ〜生成型LLMの実装と評価
よく紹介させていただいておりますが、こちらの書籍は、LLMのファインチューニングから、RLHF、RAG、分散学習にかけて、本当に幅広く解説されており、いつも参考にさせていただいております。
今回の記事で紹介したRAGの内容だけでなく、さらにその先であるRAGを前提としてInstruction Tuningについても触れており、とても面白いです。
LLMを取り扱っている方は、とりあえず買っておいても損はないと思います。
さまざまな章、ページで読めば読むほど新しい発見が得られる、スルメのような本だなといつも思っております。
LLMのファインチューニングとRAG ―チャットボット開発による実践
上記2冊の本よりもRAGやファインチューニングに絞って記載されている書籍です。だいぶ平易に書いてあるのでとてもわかりやすいと思いました。
また、本記事の内容ではないですが、RAGを実装する上でキーワード検索を加えたハイブリッド検索を検討することは一般的だと思います。本書はそこにも踏み込んで解説をしています。
また、キーワード検索でよく利用するBM25Retrieverが日本語のドキュメントに利用する際に一工夫がいるところなども紹介されており、使いやすい本だなと思いました。
成果物
下記のGithubをご覧ください。
実行環境
著者の環境は下記です。
OS:MacOS 15.2
Python:3.11.9
Google Cloudの準備
私の記事で取り扱うのは初めてなので、Google Cloudの準備をしていきます。
まず、上記のページから、「無料で開始」をクリックします。
その後、「アカウント情報」「本人確認」を入力します。
本人確認の部分では、「お支払いプロファイル」を作成する欄がございます。

「新しいお支払いプロファイルを作成する」をクリックすると、下記のような入力欄が現れるので、入力しましょう。

個人で利用する場合には、「プロファイルの種類」の枠を「個人」に変更してください。
残りは、個々人に合わせて入力してください。
続いて、「お支払い方法を追加」にて、クレジットカードを設定します。
ここまで入力したら、「無料で利用開始」をクリックします。
これで無料アカウントが登録できるようになりました。

下記の記載があるため、無料トライアルが終了しても、フルアカウントを有効化しなければ課金はされないっぽいです。安心ですね。
トライアル期間が終了しても、料金が自動的に請求されることはありません。ただし、リソースは削除対象としてマークされるため、すぐに削除される可能性があります。リソースの削除を防ぐには、トライアル期間中にフルアカウントを有効化してください。フルアカウントを有効にした後は、ご利用分のみのお支払いになります。
実行までの準備
ローカルでの準備
gcloud CLIをインストールする
pythonスクリプトで、Google Cloudのリソースにログインするために、gcloud CLIをインストールします。
gcloud CLIをダウンロードすることで、コンソールからアカウントにログインしたり、コマンドラインからGoogle Cloudのリソースの作成や管理を行うことができるようになります。
gcloud CLIの概要は下記をご覧ください。
gcloud CLIのインストール方法は下記をご覧ください。
私の環境はMacOSかつApple siliconのため「google-cloud-cli-darwin-arm.tar.gz」をダウンロードして、解凍し、下記コマンドを実行することでインストールできました。
./google-cloud-sdk/install.sh
上記のコマンドでインストールする際に、PATHが更新されるので、一度ターミナルを開き直すか、下記のコマンドで、更新を反映させます。
source ~/.zshrc
また、最初の実行の前に初期化もしておきましょう。
gcloud init
LLM、EmbeddingモデルのAPIキーを設定する(任意)
もし、自分が利用したいLLMモデルや、Embeddingモデルが別にある場合は、API キーを取得して、環境変数に保存してください。
(この場合、コードの中身も適切に変更する必要があります)
また前回の記事では、Googleの無料モデルを利用するために、「Google AI Studio」から、APIKeyを取得して、利用できるようにしたはずです。
ただ、今回はGoogle CloudのVertex AIのモデルを利用します。
このモデルは、コンソールにてGoogle Cloudのプロジェクトにログインできていれば、APIキーの登録は不要です。
しかし。こちらのモデルは通常有料になるため、利用する際は気をつけてください
リポジトリをクローンする
下記のコードでリポジトリをクローンします。
git clone https://github.com/personabb/GC_RAG_Sample.git
今回の記事は、上記リポジトリのGC_RAG_Sample/bigqueryフォルダ内に格納されているコードを利用します。
必要なパッケージをインストールする
下記のコマンドで必要なパッケージをインストールします。
cd ./GC_RAG_Sample/bigquery
pip install -r requirements.txt
上記で動かない場合は、下記も試してみてください。
(現時点での著者のバージョン付きパッケージです)
pip install -r requirements.lock
Google Cloudのプロジェクトにログインする
下記のコマンドでログインします。
gcloud auth application-default login
こちらを実行すると、ブラウザが立ち上がり、Googleにログインする画面が表示されます。
もしくは、コンソール上に表示されるURLを踏んでも同じ画面に遷移します。
そこで、先ほど作成したGoogle CLoudで利用するアカウントでログインをしてください。
ログインが成功すれば、下記のような画面が表示されます。
初めての実行の場合は、コンソールにて、どのプロジェクトを設定するか選択する必要があります。

上記のような表示が出てきたら、[1]に自分のプロジェクトIDが表示されていることを確認して、番号を入力しEnterを押してください。
プロジェクトIDに関しては、下記の画面の右側から確認してください。
(IDの部分です)
Google Cloudでの準備
Google Cloud Storageにドキュメントの格納
GCSのバケットの作成
コンソール上部から「GCS」と検索して、「Cloud Storage」サービスに入りましょう。

左タブから「バケット」をクリックすると下記のような画面になります。
「バケットを作成」をクリックすると、新しいクラウドストレージを作成できます。

下のような画面が表示されるため、一つ一つ設定していきましょう。
まず、名前を設定していきます。今回はテスト用に「gc_rag_sample_storage」としておきます。
「続行」をクリックします。

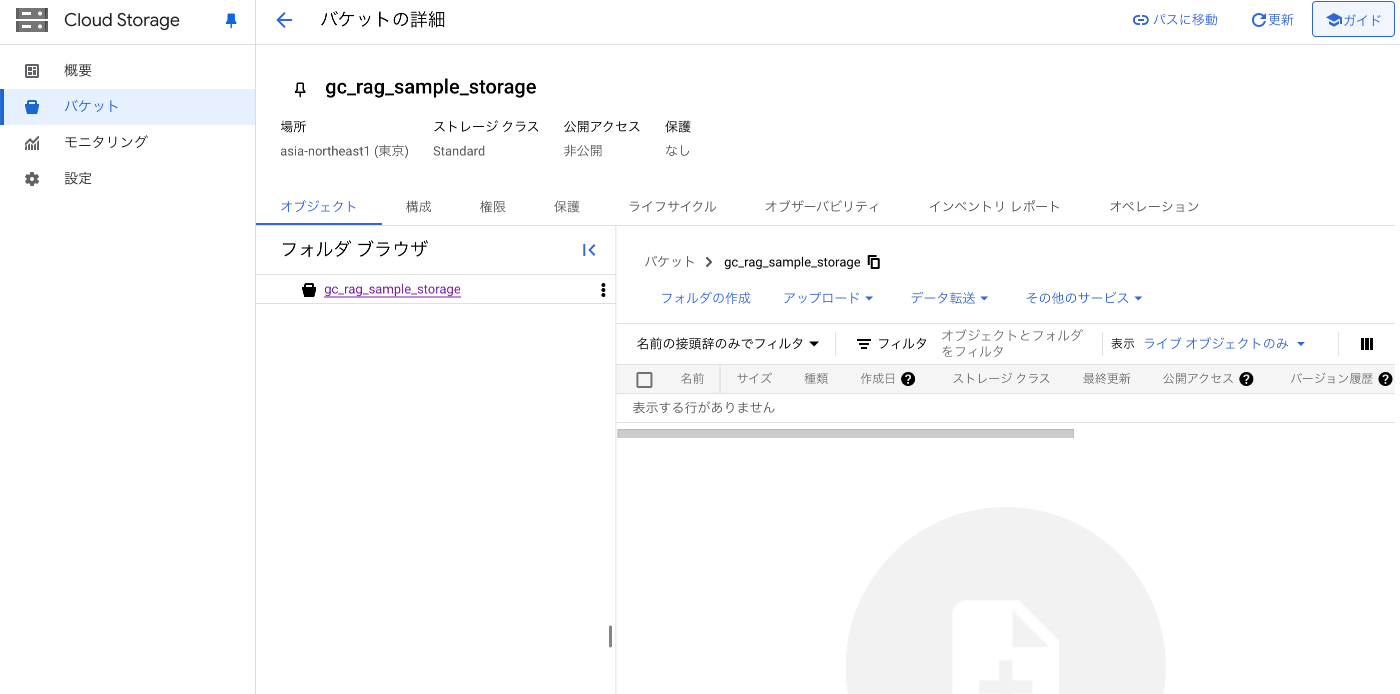
今回はテストなので、データの保存先は「Region」に設定しておきます。
商用利用の場合は、コスト感なども考慮した上で。「Multi-region」設定なども検討します。
Regionの場所は自由に設定してもらえれば良いですが、馴染み深いので「東京」を設定しておきます。
(コストを考慮するなら、他のRegionの方が多少安いです)

データのストレージクラスの設定はそのままで良いです。
オブジェクトへのアクセスを制御する方法もそのままで良いです。
オブジェクトデータを保護する方法もそのままで良いですが、今回はテストなので「削除ポリシー」の設定は外しておきます。
最後に「作成」をクリックすると、バケットが作成できます。
下記のような画面が表示されたら成功です。

GCSにドキュメントを格納する
最初にドキュメントを格納するフォルダを作りましょう。
下記の「フォルダの作成」をクリックします。
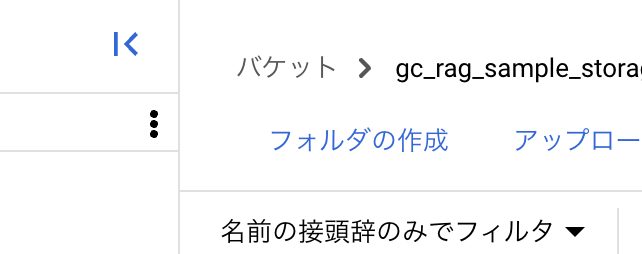
今回は「Inputs」という名前にしておきます。

その後、「Inputs」フォルダの中に入って、ドキュメントをドラッグアンドドロップすることで、アップロードできます。
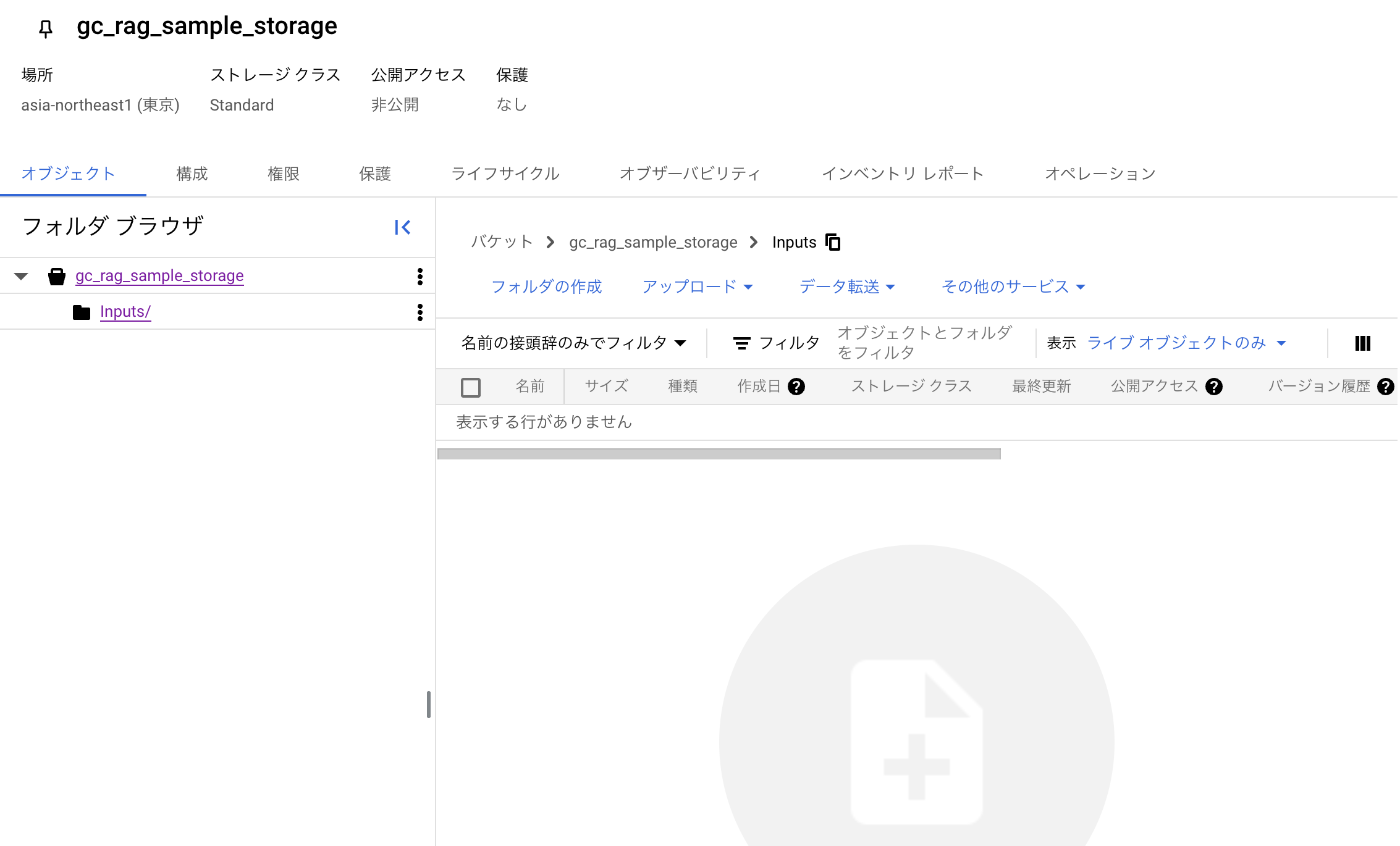
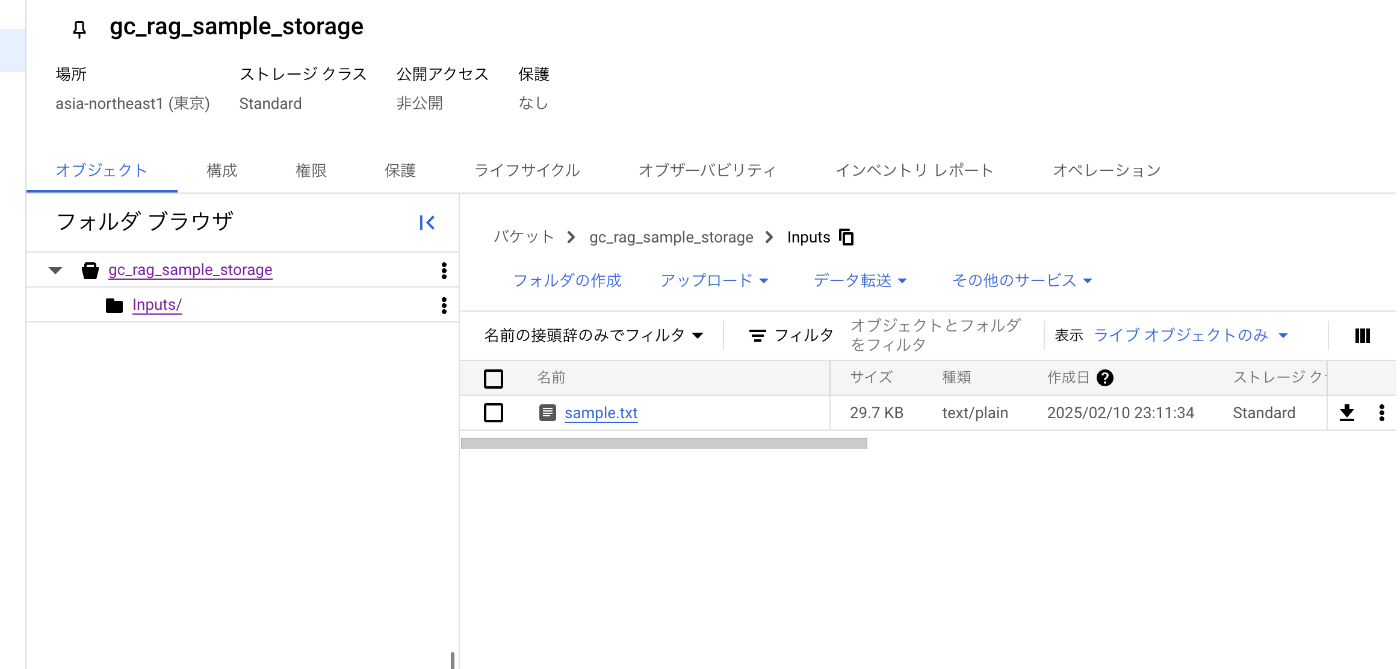
今回はリポジトリ内の「Inputs/sample.txt」をアップロードします。
下記のような画面になれば成功です。
Vertex AIのAPIを有効にする
今回の記事では、Vertex AIで提供されている、LLMとEmbeddingsモデルを利用します。
Google Cloudコンソールホームの左側のタブから、「APIとサービス」をクリックします。

続いて、下記の画面から「+APIとサービスを有効にする」をクリックします。

検索窓において、「Vertex AI API」で検索し、「Vertex AI API」をクリックします。

下記画面において「有効にする」をクリックすれば完了です。

コードの修正
ここまでで、準備はほぼ完了です。
あとは、コード内のパラメータを変更します。
具体的には、どのGCSバケットを読み込むか、などの設定です。
ドキュメントをEmbeddingsモデルでベクトル化し、DBに格納するコード
upload_vactorstore_bigquery.pyを修正します。
必要に応じて、下記部分を変更してください。
・・・
def main():
# --- 定数定義 ---
REGION = "asia-northeast1"
BUCKET_NAME = "gc_rag_sample_storage"
GCS_FOLDER = "Inputs"
EM_MODEL_NAME = "text-multilingual-embedding-002"
DATASET = "gc_rag_sample_bigquery_dataset"
TABLE = "gc_rag_sample_bigquery_table"
RESET_TABLE_FLAG = True # テーブルをリセットするかどうか
・・・
-
REGION- GCSやBigQueryのリージョン
-
BUCKET_NAME- GCSのバケットの名称
-
GCS_FOLDER- GCSにおいて、読み込むドキュメントが格納されているフォルダ名
-
EM_MODEL_NAME- Vertex AIが提供しているEmbeddingsモデル
- ドキュメントの内容をベクトル化するモデルを指定する
- ここでは
text-multilingual-embedding-002を利用しているが、Vertex AIから提供されていればなんでも利用可能- 他社モデルを利用したい場合は、コードの該当部分を変更する必要がある
-
DATASET- BigQueryにおいて、作成するデータセットの名前を設定する
- データセットとは、テーブルの集合を所有するためのコンテナのこと
- ここで設定した名前で作成されるので、事前の準備は不要
- BigQueryにおいて、作成するデータセットの名前を設定する
-
TABLE- BigQueryにおいて、作成するテーブルの名前を設定する
- ここで設定した名前で作成されるので、事前の準備は不要
-
RESET_TABLE_FLAG- BigQueryへのベクトルデータの格納は、必ず追加になってしまうので、最初にテーブルを削除してデータをリセットするかどうかのフラグ
-
Falseにすると実行のたびに、行がどんどん追加される
DBに保存された内容から、LLMがRAGで質問に回答するコード
search_rag_documents_bigquery.pyとsearch_rag_documents_bigquery_tools.pyを修正します。
必要に応じて、下記部分を変更してください。
(両コード共に修正箇所と内容は同一です)
・・・
def main():
# --- 定数定義 ---
REGION = "asia-northeast1"
EM_MODEL_NAME = "text-multilingual-embedding-002"
LLM_MODEL_NAME = "gemini-2.0-flash-001"
DATASET = "gc_rag_sample_bigquery_dataset"
TABLE = "gc_rag_sample_bigquery_table"
# 質問文
query = "16歳未満のユーザーが海外から当社サービスを利用した場合、親権者が同意していないときはどう扱われますか? そのときデータは国外にも保存される可能性がありますか?"
・・・
-
REGION- GCSやBigQueryのリージョン
-
EM_MODEL_NAME- Vertex AIが提供しているEmbeddingsモデル
- ドキュメントの内容をベクトル化するモデルを指定する
- ここでは
text-multilingual-embedding-002を利用しているが、Vertex AIから提供されていればなんでも利用可能- 他社モデルを利用したい場合は、コードの該当部分を変更する必要がある
-
LLM_MODEL_NAME- Vertex AIが提供しているLLMモデル
- ユーザの質問に回答するLLMを指定する
- 他社のLLMを利用することも可能(LangChainで動かせれば)
- その場合は、コード中のモデル定義部分のコードだけを変更すればOK
-
DATASET- BigQueryにおいて、作成するデータセットの名前を設定する
- データセットとは、テーブルの集合を所有するためのコンテナのこと
- ここで設定した名前で作成されるので、事前の準備は不要
- BigQueryにおいて、作成するデータセットの名前を設定する
-
TABLE- BigQueryにおいて、作成するテーブルの名前を設定する
- ここで設定した名前で作成されるので、事前の準備は不要
-
query
-ユーザの質問文
実行方法
下記の手順でコードは実行できます。
DBへの登録
python upload_vactorstore_bigquery.py
LLMにRAGで回答させる
python search_rag_documents_bigquery.py
もしくは
python search_rag_documents_bigquery_tools.py
実施内容
これまでの記事と同様に、下記コードを実装しています。
ただし、今回はドキュメントローダにGCSを、ベクトルストアにBigQueryを利用します。
- ドキュメントをEmbeddingモデルでベクトル化し、DBに格納するコード
- DBに保存された内容から、LLMがRAGで質問に回答するコード(通常LLM)
- DBに保存された内容から、LLMがRAGで質問に回答するコード(Tool CallingによるAgent)
ドキュメントをEmbeddingsモデルでベクトル化し、DBに格納する
今回も前回と同様のプライバシーポリシー(ダミー)をドキュメントとして利用しています。
内容はこちらです。
コード解説
実際のコードは下記になります。
これまでの記事との差分に絞って解説いたします。
Google Cloudの認証情報を取得
# 認証情報とプロジェクトIDを取得します。
credentials, PROJECT_ID = google.auth.default()
上記のコードで、先ほどログインしたGoogle CloudのPROJECT_IDと認証情報(credentials)を取得できます。
本コードでは、データベースやストレージへの接続のために、PROJECT_IDを利用します。
定数定義
# --- 定数定義 ---
REGION = "asia-northeast1"
BUCKET_NAME = "gc_rag_sample_storage"
GCS_FOLDER = "Inputs"
EM_MODEL_NAME = "text-multilingual-embedding-002"
DATASET = "gc_rag_sample_bigquery_dataset"
TABLE = "gc_rag_sample_bigquery_table"
RESET_TABLE_FLAG = True # テーブルをリセットするかどうか
これらの内容は下記のとおりです。
-
REGION- GCSやBigQueryのリージョン
-
BUCKET_NAME- GCSのバケットの名称
-
GCS_FOLDER- GCSにおいて、読み込むドキュメントが格納されているフォルダ名
-
EM_MODEL_NAME- Vertex AIが提供しているEmbeddingsモデル
- ドキュメントの内容をベクトル化するモデルを指定する
- ここでは
text-multilingual-embedding-002を利用しているが、Vertex AIから提供されていればなんでも利用可能- 他社モデルを利用したい場合は、コードの該当部分を変更する必要がある
-
DATASET- BigQueryにおいて、作成するデータセットの名前を設定する
- データセットとは、テーブルの集合を所有するためのコンテナのこと
- ここで設定した名前で作成されるので、事前の準備は不要
- BigQueryにおいて、作成するデータセットの名前を設定する
-
TABLE- BigQueryにおいて、作成するテーブルの名前を設定する
- ここで設定した名前で作成されるので、事前の準備は不要
-
RESET_TABLE_FLAG- BigQueryへのベクトルデータの格納は、必ず追加になってしまうので、最初にテーブルを削除してデータをリセットするかどうかのフラグ
-
Falseにすると実行のたびに、行がどんどん追加される
Embedingモデルを定義する
# テキスト エンベディング モデルを定義する (dense embedding)
embedding_model = VertexAIEmbeddings(model_name=EM_MODEL_NAME)
ここで、ドキュメントを埋め込みベクトル化する、Embeddingsモデルを定義しています。
Vertex AIにて利用できるモデルを選定しています。
前回の記事で利用していたGoogleGenerativeAIEmbeddingsよりも選択肢が多いです。
(ただし有料になります)
BigQuery Vector Storeを定義する
# BigQuery Vector Store の初期化
# データセットの作成
client = bigquery.Client(project=PROJECT_ID, location=REGION)
client.create_dataset(dataset=DATASET, exists_ok=True)
# テーブルのリセット
if RESET_TABLE_FLAG:
table_id = f"{PROJECT_ID}.{DATASET}.{TABLE}"
client.delete_table(table_id, not_found_ok=True) # テーブル削除
print(f"Deleted table {table_id}")
else:
print(f"add data to existing table ({table_id})")
# ベクターストアの定義
vector_store = BigQueryVectorStore(
project_id=PROJECT_ID,
dataset_name=DATASET,
table_name=TABLE,
location=REGION,
embedding=embedding_model,
distance_strategy=DistanceStrategy.COSINE,
)
上記にて、BigQueryのデータセットを作成しています。
最初に作成(既存で同じ名前があれば接続)し、RESET_TABLE_FLAGのフラグに応じて、中身を初期化し、最後に、Vector Storeとして定義しています。
ドキュメントをGCSから読み込む
# GCS内の指定のフォルダ内のファイルを全てロード
loader = GCSDirectoryLoader(
project_name=PROJECT_ID,
bucket=BUCKET_NAME,
prefix=GCS_FOLDER
)
上記にて、GCSの指定したバケットの指定したフォルダ内の全てのファイルを読み込み、取得しています。
BigQuery Vector Store にデータを追加する
# ---- BigQuery Vector Store にデータを追加する ----
# https://github.com/langchain-ai/langchain-google/blob/a0027c820dafaddb1af4c0e536c8018c9940b794/libs/community/langchain_google_community/bq_storage_vectorstores/_base.py#L266
vector_store.add_texts_with_embeddings(
texts=texts,
embs=dense_embeddings,
metadatas=metadatas,
)
前回の記事とほぼ同じですが、上記によりBigQueryのDBに、ドキュメントとベクトルデータ、メタデータを格納しています。
add_texts_with_embeddingsにより、我々が事前に変換した埋め込みベクトルを利用して、DBに格納することができます。
コードのその他部分は、これまでの記事と同様の内容のため、そちらを合わせてご覧ください。
実行後、BigQueryを確認する
コードを実行した後、BigQueryにデータが格納されているかを確認します。
Google Cloudの上部検索窓にて「BigQuery」と検索し、BigQueryサービスを選びます。

画面真ん中寄りの「エクスプローラ」から「charged-magnet-450512-h1」のトグルを開きます。

コード内で設定した「gc_rag_sample_bigquery_dataset」の中の「gc_rag_sample_bigquery_table」をクリックすると、下のような画面になります。

画面右側の「プレビュー」タブをクリックし、下のような表示になれば成功です。

- doc_id
- 自動でつけられるユニークなID
- content
- ドキュメントのチャンクデータ
- embedding
- 埋め込みベクトルデータ
- Defaultで設定している埋め込みモデルを利用している場合は、768次元の埋め込みベクトルが格納されています
- my_metadata
- 自分で設定できるメタデータ
DBに保存された内容から、LLMがRAGで質問に回答するコード(通常LLM)
続いて、前回の記事と同様に、DBに格納された情報源を利用して、LLMが回答するコードの部分を実装します。
ドキュメントがダミーのプライバシーポリシーのため、今回のLLM君は、企業のQ&A botとして利用することを想定します。
ここでは、ユーザの質問文を、Embeddingsモデルによって、ベクトルに変換して、そのベクトルとDBに格納されているベクトルとで類似度を計算します。
そして、類似性が高いチャンクをLLMのプロンプトに提示し、その情報をもとにLLMに回答させることがゴールです。
LangChainを利用して実装するため、推奨されているLCEL記法を使って、Chainとして全部繋げて実行できることを目的にします。
その後、別の章にて、Tool CallingによるAgentの形で実装します。
コード解説
実際のコードは下記になります。
これまでの記事との差分に絞って解説いたします。
また、/upload_vactorstore_bigquery.pyにて解説した部分に関しても省略します。
定数定義
# --- 定数定義 ---
REGION = "asia-northeast1"
EM_MODEL_NAME = "text-multilingual-embedding-002"
LLM_MODEL_NAME = "gemini-2.0-flash-001"
DATASET = "gc_rag_sample_bigquery_dataset"
TABLE = "gc_rag_sample_bigquery_table"
# 質問文
query = "16歳未満のユーザーが海外から当社サービスを利用した場合、親権者が同意していないときはどう扱われますか? そのときデータは国外にも保存される可能性がありますか?"
#query = "おはよう"
#query = "今日は12歳の誕生日なんだ。これから初めて海外に行くんだよね"
これらの内容は下記のとおりです。
-
REGION- GCSやBigQueryのリージョン
-
LLM_MODEL_NAME- Vertex AIが提供しているLLMモデル
- ユーザの質問に回答するLLMを指定する
- 他社のLLMを利用することも可能(LangChainで動かせれば)
- その場合は、コード中のモデル定義部分のコードだけを変更すればOK
-
EM_MODEL_NAME- Vertex AIが提供しているEmbeddingsモデル
- ドキュメントの内容をベクトル化するモデルを指定する
- ここでは
text-multilingual-embedding-002を利用しているが、Vertex AIから提供されていればなんでも利用可能- 他社モデルを利用したい場合は、コードの該当部分を変更する必要がある
-
DATASET- BigQueryにおいて、作成するデータセットの名前を設定する
- データセットとは、テーブルの集合を所有するためのコンテナのこと
- ここで設定した名前で作成されるので、事前の準備は不要
- BigQueryにおいて、作成するデータセットの名前を設定する
-
TABLE- BigQueryにおいて、作成するテーブルの名前を設定する
- ここで設定した名前で作成されるので、事前の準備は不要
-
query- LLMへの質問文
LLMの定義
# Chatモデル (LLM)
llm = ChatVertexAI(
model_name=LLM_MODEL_NAME,
max_output_tokens=512,
temperature=0.2
)
ここではVertex AIのLLMモデルを利用します。
このとき、選択肢として、VertexAIクラスとChatVertexAIクラスが存在しますが、どうやらChatVertexAIクラスを利用するのが主流のようです。(参考)
カスタムRetriever
class VectorSearchRetriever(BaseRetriever):
"""
ベクトル検索を行うためのRetrieverクラス。
"""
vector_store: SkipValidation[Any]
embedding_model: SkipValidation[Any]
k: int = 5 # 返すDocumentのチャンク数
class Config:
arbitrary_types_allowed = True
def _get_relevant_documents(self, query: str) -> List[Document]:
# Dense embedding
embedding = self.embedding_model.embed_query(query)
search_results = self.vector_store.similarity_search_by_vector_with_score(
embedding=embedding,
k=self.k,
)
# Document のリストだけ取り出す
return [doc for doc, _ in search_results]
async def _aget_relevant_documents(self, query: str) -> List[Document]:
return self._get_relevant_documents(query)
基本的には、これまでの記事で解説したカスタムRetrieverクラスと同様ですが、similarity_search_by_vector_with_scoreメソッドは、BigQueryVectorStoreクラスで対応するメソッドに変更しています。
なお、無理にカスタムRetrieverクラスを利用しなくても、本記事の内容でしたら下記でも十分です。
ただ、カスタムRetrieverクラスを利用することで、より細かい部分の制御が可能になります。
dence_retriever = vector_store.as_retriever()
解説が必要な箇所はこれだけです。
LangChainを利用しているので、コアな部分のコードは同様に使いまわすことができるので便利ですね。
出力結果
本コードの出力結果は下記になります。
(ユーザクエリは「16歳未満のユーザーが海外から当社サービスを利用した場合、親権者が同意していないときはどう扱われますか? そのときデータは国外にも保存される可能性がありますか?」)
出力結果
===== DenseRetriever の実行結果 =====
DenseRetrieved Documents: [Document(metadata={'doc_id': '80429fc1927c49e1bc339e53244e73a2', 'my_metadata': 22, 'score': 0.6320097584244752}, page_content='2. \n\n未成年者の個人情報保護\n\n:\n\n16歳未満の利用者の個人情報に関しては、一般のユーザーと同等のセキュリティ対策を講じていますが、必要に応じてより厳格なアクセス制限を設定する場合があります。たとえば、投稿やコミュニケーション機能を制限したり、年齢に応じたコンテンツ表示のフィルタリングを行うことが検討されます。\n\n3. \n\n照会・削除請求\n\n:\n\n親権者が、当社が保有する未成年者の個人情報について照会・訂正・削除を希望する場合は、前条の「開示等」の手続きに従ってご連絡ください。当社は必要に応じて年齢確認や委任状の提出を求め、正当な請求であることを確認した上で対応します。\n\n4. \n\n利用規約との整合性\n\n:\n\n未成年者が当社サービスを利用する場合は、プライバシーポリシーに加えて、サービスの利用規約に定められた年齢制限や制約事項なども遵守する必要があります。もし利用規約に違反していると判明した場合は、アカウント停止などの措置が取られることがあります。\n\n第11条(プライバシーポリシーの変更)'), Document(metadata={'doc_id': '42455be21af94d9787e4345f5b658720', 'my_metadata': 21, 'score': 0.6455365836514703}, page_content='4. \n\n手数料\n\n:\n\n開示等の手数料については、当社が別途定める方法により請求させていただく場合がありますので、あらかじめご了承ください。\n\n上記のように、当社はユーザーの権利を尊重し、迅速かつ誠実な対応に努めます。ただし、請求内容によっては相当の期間や追加資料を要する場合があります。その際には手続きの進捗状況や必要な対応を速やかにユーザーへ連絡します。\n\n第10条(未成年者の個人情報)\n\n当社は、16歳未満のユーザーが当社サービスを利用する場合、法定代理人(親権者等)の同意を得ることが必要である場合があると認識しています。ユーザーが未成年者であるにもかかわらず同意を得ていない場合、もしくは未成年者である旨を偽って利用登録を行った場合には、当社は一切の責任を負いかねます。\n\n1. \n\n親権者の同意取得\n\n:\n\n未成年者がサービスを利用するにあたっては、親権者が本ポリシーの内容を確認したうえで利用に同意することが望ましいと考えています。特に決済手段の登録や外部サービスとの連携など、リスクの高い行為については慎重な対応を求めています。\n\n2. \n\n未成年者の個人情報保護'), Document(metadata={'doc_id': 'd68083d5aa234d149eb3aab2b68e9f36', 'my_metadata': 17, 'score': 0.651116118223945}, page_content='これらの技術を活用することで、当社はサービスの品質向上や適切なマーケティング活動を実現していますが、ユーザーのプライバシー保護にも十分配慮し、必要に応じて同意取得やオプトアウトの仕組みを提供するよう努めます。\n\n第8条(国際データ移転)\n\n当社は、日本国内だけではなく、ユーザーが所在する国または地域とは異なる管轄のサーバーやデータセンターを利用する場合があり、ユーザーの個人情報が国外へ移転されることがあります。たとえば、クラウドサービスプロバイダを通じて海外にあるデータセンターで個人情報を保管する場合などが挙げられます。\n\n1. \n\n保護水準の確認\n\n:\n\nこのような国際的なデータ移転に際しては、移転先の国や地域における個人情報保護法制が日本またはEUなどの基準と同等以上の水準にあるかどうかを確認し、必要に応じて適切な契約(EU標準契約条項など)を締結するなど、個人情報が適切に保護される体制を整備します。\n\n2. \n\nユーザーの明示的同意\n\n:'), Document(metadata={'doc_id': '0f69370cc7b5413b81def87d1d2bb08a', 'my_metadata': 18, 'score': 0.6792036970917404}, page_content='2. \n\nユーザーの明示的同意\n\n:\n\nユーザーの明示的同意を得ることなく国際データ移転を行う場合、当社は日本国法令や国際ルールで認められた要件を満たす範囲でのみ実施します。たとえば、データの暗号化や仮名化を徹底することで、リスクを最低限に抑えた状態でデータを取り扱う措置を講じます。\n\n3. \n\n越境データのセキュリティ確保\n\n:\n\n国際回線を経由してデータを送信する場合、盗聴や改ざんのリスクが考えられるため、VPNの利用やSSL/TLS通信などを組み合わせ、情報が不正に傍受される可能性を極力排除します。さらに、国外のデータセンターへのアクセス権限を厳格に制限し、監査ログを取得・分析することで、不正アクセスを検知・阻止できる仕組みを維持しています。\n\n4. \n\nユーザーへの周知\n\n:'), Document(metadata={'doc_id': 'f77685793d5c47d58a934652097547ff', 'my_metadata': 19, 'score': 0.6974352016440534}, page_content='4. \n\nユーザーへの周知\n\n:\n\n国際データ移転がサービス提供上不可避である場合、当社は利用規約や本ポリシーにてその旨を周知し、ユーザーがそのリスクや対策内容を理解できるよう配慮します。ユーザーが海外でサービスを利用する際には、各国の法規制やインターネットインフラ状況を踏まえて、データがどのように移転・保護されるのかを検討する必要があります。\n\n第9条(保有個人情報の開示・訂正・削除)\n\nユーザーは、当社が保有しているユーザー自身の個人情報について、開示、訂正、追加、削除、利用停止、または第三者提供の停止(以下「開示等」と総称)を請求する権利を有します。当社は、ユーザーからの開示等に関する請求があった場合、法令に基づき合理的な範囲で対応します。請求を希望される場合は、当社所定の手続き(本人確認等)を経たうえで、当社カスタマーサポートまでご連絡ください。\n\n1. \n\n開示の請求\n\n:')]
================= LLMの実行結果 =================
16歳未満のユーザーが当社のサービスを利用する場合、法定代理人(親権者等)の同意を得ることが必要です。ユーザーが未成年者であるにもかかわらず同意を得ていない場合、もしくは未成年者である旨を偽って利用登録を行った場合には、当社は一切の責任を負いかねます。
また、当社は、日本国内だけではなく、ユーザーが所在する国または地域とは異なる管轄のサーバーやデータセンターを利用する場合があります。そのため、ユーザーの個人情報が国外へ移転されることがあります。国際データ移転がサービス提供上不可避である場合、当社は利用規約やプライバシーポリシーにてその旨を周知し、ユーザーがそのリスクや対策内容を理解できるよう配慮します。
関連する情報源の文章は以下の通りです。
-
第10条(未成年者の個人情報)
当社は、16歳未満のユーザーが当社サービスを利用する場合、法定代理人(親権者等)の同意を得ることが必要である場合があると認識しています。ユーザーが未成年者であるにもかかわらず同意を得ていない場合、もしくは未成年者である旨を偽って利用登録を行った場合には、当社は一切の責任を負いかねます。
-
第8条(国際データ移転)
当社は、日本国内だけではなく、ユーザーが所在する国または地域とは異なる管轄のサーバーやデータセンターを利用する場合があり、ユーザーの個人情報が国外へ移転されることがあります。
-
4. ユーザーへの周知
国際データ移転がサービス提供上不可避である場合、当社は利用規約や本ポリシーにてその旨を周知し、ユーザーがそのリスクや対策内容を理解できるよう配慮します。
前回の記事と同じような結果になりました!
ドキュメントストレージやVector Storeを変更しても、結果は変わらないことが確認できました。
(Temperatureを0.2に設定しているため、出力の揺らぎが若干あります。)
前回の記事にも書きましたが、想定回答は下記になります。
想定回答
想定回答
16歳未満のユーザーがサービスを利用する場合には、第10条の規定により親権者の同意が必要となります。もし同意が得られていない場合は、当社は責任を負いかねるとしています。また、海外からの利用であるため、ユーザーのデータが国際データ移転の対象となる場合があります。これに関しては第8条で規定されており、必要に応じてEU標準契約条項などの締結や暗号化を行う形でデータの保護が図られます。つまり、親権者の同意がない場合はアカウント停止や責任の免除が行われる可能性がある一方で、データそのものが国外サーバーに保存される際にはプライバシー保護のための措置が適用される仕組みになっています。
根拠の箇所
第10条(未成年者の個人情報)
「16歳未満のユーザーが当社サービスを利用する場合、法定代理人(親権者等)の同意を得ることが必要... 同意を得ずに登録された場合...当社は一切の責任を負いかねます。」
第8条(国際データ移転)
「...移転先の国や地域における個人情報保護法制が日本またはEUなどの基準と同等以上の水準にあるかどうかを確認し、必要に応じて適切な契約を締結するなどの対応を取る...」
DBに保存された内容から、LLMがRAGで質問に回答するコード(Tool CallingによるAgent)
これまでの記事と同様に、Tool CallingによるAgentを実装します。
実装の意図はこれまでの記事をご覧ください。
コード解説
実際のコードは下記になります。
コードの構成要素に関しては、今回の記事と前回の記事で全て解説済みですので、上記のコードは読めるようになっているはずです。
繰り返しになるため、ここでは解説を省略します。
実行結果
本コードの出力結果は下記になります。
(ユーザクエリは「16歳未満のユーザーが海外から当社サービスを利用した場合、親権者が同意していないときはどう扱われますか? そのときデータは国外にも保存される可能性がありますか?」)
出力結果
================= エージェントの実行結果 =================
This model can reply with multiple function calls in one response. Please don't rely on additional_kwargs.function_call as only the last one will be saved.Use tool_calls instead.
=== Message 0 ===
Type: HumanMessage
Content:
16歳未満のユーザーが海外から当社サービスを利用した場合、親権者が同意していないときはどう扱われますか? そのときデータは国外にも保存される可能性がありますか?
=== Message 1 ===
Type: AIMessage
Content:
Tool calls:
[{'name': 'Document_Search_Tool', 'args': {'__arg1': '16歳未満のユーザーが海外から当社サービスを利用した場合、親権者が同意していないとき'}, 'id': '97701170-3578-4ef3-b8b5-718a9f3cf850', 'type': 'tool_call'}, {'name': 'Document_Search_Tool', 'args': {'__arg1': 'データは国外にも保存される可能性'}, 'id': '83335972-0c85-4a7c-9244-4f111ccb4b8a', 'type': 'tool_call'}]
Response Metadata:
{'is_blocked': False, 'safety_ratings': [], 'usage_metadata': {'prompt_token_count': 198, 'candidates_token_count': 44, 'total_token_count': 242, 'prompt_tokens_details': [{'modality': 1, 'token_count': 198}], 'candidates_tokens_details': [{'modality': 1, 'token_count': 44}], 'cached_content_token_count': 0, 'cache_tokens_details': []}, 'finish_reason': 'STOP', 'avg_logprobs': -0.018050289966843346}
=== Message 2 ===
Type: ToolMessage
Content:
[Document(metadata={'doc_id': '42455be21af94d9787e4345f5b658720', 'my_metadata': 21, 'score': 0.6328169720470406}, page_content='4. \n\n手数料\n\n:\n\n開示等の手数料については、当社が別途定める方法により請求させていただく場合がありますので、あらかじめご了承ください。\n\n上記のように、当社はユーザーの権利を尊重し、迅速かつ誠実な対応に努めます。ただし、請求内容によっては相当の期間や追加資料を要する場合があります。その際には手続きの進捗状況や必要な対応を速やかにユーザーへ連絡します。\n\n第10条(未成年者の個人情報)\n\n当社は、16歳未満のユーザーが当社サービスを利用する場合、法定代理人(親権者等)の同意を得ることが必要である場合があると認識しています。ユーザーが未成年者であるにもかかわらず同意を得ていない場合、もしくは未成年者である旨を偽って利用登録を行った場合には、当社は一切の責任を負いかねます。\n\n1. \n\n親権者の同意取得\n\n:\n\n未成年者がサービスを利用するにあたっては、親権者が本ポリシーの内容を確認したうえで利用に同意することが望ましいと考えています。特に決済手段の登録や外部サービスとの連携など、リスクの高い行為については慎重な対応を求めています。\n\n2. \n\n未成年者の個人情報保護'), Document(metadata={'doc_id': '80429fc1927c49e1bc339e53244e73a2', 'my_metadata': 22, 'score': 0.645221755068279}, page_content='2. \n\n未成年者の個人情報保護\n\n:\n\n16歳未満の利用者の個人情報に関しては、一般のユーザーと同等のセキュリティ対策を講じていますが、必要に応じてより厳格なアクセス制限を設定する場合があります。たとえば、投稿やコミュニケーション機能を制限したり、年齢に応じたコンテンツ表示のフィルタリングを行うことが検討されます。\n\n3. \n\n照会・削除請求\n\n:\n\n親権者が、当社が保有する未成年者の個人情報について照会・訂正・削除を希望する場合は、前条の「開示等」の手続きに従ってご連絡ください。当社は必要に応じて年齢確認や委任状の提出を求め、正当な請求であることを確認した上で対応します。\n\n4. \n\n利用規約との整合性\n\n:\n\n未成年者が当社サービスを利用する場合は、プライバシーポリシーに加えて、サービスの利用規約に定められた年齢制限や制約事項なども遵守する必要があります。もし利用規約に違反していると判明した場合は、アカウント停止などの措置が取られることがあります。\n\n第11条(プライバシーポリシーの変更)'), Document(metadata={'doc_id': 'd68083d5aa234d149eb3aab2b68e9f36', 'my_metadata': 17, 'score': 0.7226819044509505}, page_content='これらの技術を活用することで、当社はサービスの品質向上や適切なマーケティング活動を実現していますが、ユーザーのプライバシー保護にも十分配慮し、必要に応じて同意取得やオプトアウトの仕組みを提供するよう努めます。\n\n第8条(国際データ移転)\n\n当社は、日本国内だけではなく、ユーザーが所在する国または地域とは異なる管轄のサーバーやデータセンターを利用する場合があり、ユーザーの個人情報が国外へ移転されることがあります。たとえば、クラウドサービスプロバイダを通じて海外にあるデータセンターで個人情報を保管する場合などが挙げられます。\n\n1. \n\n保護水準の確認\n\n:\n\nこのような国際的なデータ移転に際しては、移転先の国や地域における個人情報保護法制が日本またはEUなどの基準と同等以上の水準にあるかどうかを確認し、必要に応じて適切な契約(EU標準契約条項など)を締結するなど、個人情報が適切に保護される体制を整備します。\n\n2. \n\nユーザーの明示的同意\n\n:'), Document(metadata={'doc_id': '0f69370cc7b5413b81def87d1d2bb08a', 'my_metadata': 18, 'score': 0.7233778051655454}, page_content='2. \n\nユーザーの明示的同意\n\n:\n\nユーザーの明示的同意を得ることなく国際データ移転を行う場合、当社は日本国法令や国際ルールで認められた要件を満たす範囲でのみ実施します。たとえば、データの暗号化や仮名化を徹底することで、リスクを最低限に抑えた状態でデータを取り扱う措置を講じます。\n\n3. \n\n越境データのセキュリティ確保\n\n:\n\n国際回線を経由してデータを送信する場合、盗聴や改ざんのリスクが考えられるため、VPNの利用やSSL/TLS通信などを組み合わせ、情報が不正に傍受される可能性を極力排除します。さらに、国外のデータセンターへのアクセス権限を厳格に制限し、監査ログを取得・分析することで、不正アクセスを検知・阻止できる仕組みを維持しています。\n\n4. \n\nユーザーへの周知\n\n:'), Document(metadata={'doc_id': 'f77685793d5c47d58a934652097547ff', 'my_metadata': 19, 'score': 0.7498571325964949}, page_content='4. \n\nユーザーへの周知\n\n:\n\n国際データ移転がサービス提供上不可避である場合、当社は利用規約や本ポリシーにてその旨を周知し、ユーザーがそのリスクや対策内容を理解できるよう配慮します。ユーザーが海外でサービスを利用する際には、各国の法規制やインターネットインフラ状況を踏まえて、データがどのように移転・保護されるのかを検討する必要があります。\n\n第9条(保有個人情報の開示・訂正・削除)\n\nユーザーは、当社が保有しているユーザー自身の個人情報について、開示、訂正、追加、削除、利用停止、または第三者提供の停止(以下「開示等」と総称)を請求する権利を有します。当社は、ユーザーからの開示等に関する請求があった場合、法令に基づき合理的な範囲で対応します。請求を希望される場合は、当社所定の手続き(本人確認等)を経たうえで、当社カスタマーサポートまでご連絡ください。\n\n1. \n\n開示の請求\n\n:')]
Tool name: Document_Search_Tool
=== Message 3 ===
Type: ToolMessage
Content:
[Document(metadata={'doc_id': 'd68083d5aa234d149eb3aab2b68e9f36', 'my_metadata': 17, 'score': 0.6827826933082144}, page_content='これらの技術を活用することで、当社はサービスの品質向上や適切なマーケティング活動を実現していますが、ユーザーのプライバシー保護にも十分配慮し、必要に応じて同意取得やオプトアウトの仕組みを提供するよう努めます。\n\n第8条(国際データ移転)\n\n当社は、日本国内だけではなく、ユーザーが所在する国または地域とは異なる管轄のサーバーやデータセンターを利用する場合があり、ユーザーの個人情報が国外へ移転されることがあります。たとえば、クラウドサービスプロバイダを通じて海外にあるデータセンターで個人情報を保管する場合などが挙げられます。\n\n1. \n\n保護水準の確認\n\n:\n\nこのような国際的なデータ移転に際しては、移転先の国や地域における個人情報保護法制が日本またはEUなどの基準と同等以上の水準にあるかどうかを確認し、必要に応じて適切な契約(EU標準契約条項など)を締結するなど、個人情報が適切に保護される体制を整備します。\n\n2. \n\nユーザーの明示的同意\n\n:'), Document(metadata={'doc_id': '0f69370cc7b5413b81def87d1d2bb08a', 'my_metadata': 18, 'score': 0.68700110099915}, page_content='2. \n\nユーザーの明示的同意\n\n:\n\nユーザーの明示的同意を得ることなく国際データ移転を行う場合、当社は日本国法令や国際ルールで認められた要件を満たす範囲でのみ実施します。たとえば、データの暗号化や仮名化を徹底することで、リスクを最低限に抑えた状態でデータを取り扱う措置を講じます。\n\n3. \n\n越境データのセキュリティ確保\n\n:\n\n国際回線を経由してデータを送信する場合、盗聴や改ざんのリスクが考えられるため、VPNの利用やSSL/TLS通信などを組み合わせ、情報が不正に傍受される可能性を極力排除します。さらに、国外のデータセンターへのアクセス権限を厳格に制限し、監査ログを取得・分析することで、不正アクセスを検知・阻止できる仕組みを維持しています。\n\n4. \n\nユーザーへの周知\n\n:'), Document(metadata={'doc_id': 'f77685793d5c47d58a934652097547ff', 'my_metadata': 19, 'score': 0.7470679114140902}, page_content='4. \n\nユーザーへの周知\n\n:\n\n国際データ移転がサービス提供上不可避である場合、当社は利用規約や本ポリシーにてその旨を周知し、ユーザーがそのリスクや対策内容を理解できるよう配慮します。ユーザーが海外でサービスを利用する際には、各国の法規制やインターネットインフラ状況を踏まえて、データがどのように移転・保護されるのかを検討する必要があります。\n\n第9条(保有個人情報の開示・訂正・削除)\n\nユーザーは、当社が保有しているユーザー自身の個人情報について、開示、訂正、追加、削除、利用停止、または第三者提供の停止(以下「開示等」と総称)を請求する権利を有します。当社は、ユーザーからの開示等に関する請求があった場合、法令に基づき合理的な範囲で対応します。請求を希望される場合は、当社所定の手続き(本人確認等)を経たうえで、当社カスタマーサポートまでご連絡ください。\n\n1. \n\n開示の請求\n\n:'), Document(metadata={'doc_id': '28ea9df84a644a26b0bfff1c2dfc5b4e', 'my_metadata': 14, 'score': 0.761599898198027}, page_content='1. \n\n業務委託\n\n:\n\n当社が外部企業に対して業務を委託する場合に、業務遂行上必要となる個人情報の一部を提供することがあります。たとえば、メール配信サービスやデータ解析サービスを委託するケースなどが該当します。この場合、当社は委託先との契約により守秘義務を課し、委託先の安全管理体制を確認・監督します。\n\n2. \n\n事業承継\n\n:\n\n合併、会社分割、営業譲渡、その他の事由により事業が継承される場合、個人情報が承継される可能性があります。ただし、その際には利用目的の範囲内でのみ継承され、ユーザーに対して事前に通知または公表されます。事業承継時にプライバシー保護の水準が下がらないよう、厳格な審査を行います。\n\n3. \n\n統計データの開示\n\n:\n\n匿名化処理された統計データについては、ユーザー個人を特定できない形で第三者に提供することがあります。マーケティング分析や市場調査レポートなどに活用される場合がありますが、再識別が発生しないよう厳重に管理します。'), Document(metadata={'doc_id': '8934eae112a4482c89e57ee6b1377e3f', 'my_metadata': 11, 'score': 0.7799267268644657}, page_content='これらの目的以外で個人情報を利用する場合には、事前にユーザーの同意を得るか、もしくは当該利用が法令で許容される場合に限り行います。利用目的の大幅な変更が生じる場合には、当社ウェブサイト上やメール等で通知を行い、必要に応じて改めてユーザーの同意を取得します。こうした手続きを通じて、ユーザーの意に反してデータが用いられないよう配慮しています。\n\n第5条(個人情報の管理と安全対策)\n\n当社は、ユーザーの個人情報を正確かつ最新の状態に保つよう努めるとともに、不正アクセス、漏洩、改ざん、滅失等のリスクを軽減するため、適切な技術的および組織的安全管理措置を講じます。具体的には以下のようなセキュリティ対策を実施しています。\n\n1. \n\nアクセス権限管理\n\n:\n\nデータへのアクセスは業務上必要な範囲の従業員に限定し、ID・パスワードの管理やアクセスログの記録を徹底することで、権限のない従業員が利用できないようにしています。これには、役職や職務内容に応じた権限設計や、部署をまたいだアクセス制御などが含まれます。\n\n2. \n\n暗号化技術の使用\n\n:')]
Tool name: Document_Search_Tool
=== Message 4 ===
Type: AIMessage
Content:
16歳未満のユーザーが当社のサービスを利用する場合、法定代理人(親権者等)の同意を得ることが必要となる場合があります。ユーザーが未成年者であるにもかかわらず同意を得ていない場合、もしくは未成年者である旨を偽って利用登録を行った場合には、当社は一切の責任を負いかねます。
また、当社は、日本国内だけではなく、ユーザーが所在する国または地域とは異なる管轄のサーバーやデータセンターを利用する場合があります。そのため、ユーザーの個人情報が国外へ移転されることがあります。
以下に、toolから取得した情報を記載します。
-
未成年者の個人情報について
- 未成年者がサービスを利用するにあたっては、親権者が本ポリシーの内容を確認したうえで利用に同意することが望ましいと考えています。特に決済手段の登録や外部サービスとの連携など、リスクの高い行為については慎重な対応を求めています。
- 16歳未満の利用者の個人情報に関しては、一般のユーザーと同等のセキュリティ対策を講じていますが、必要に応じてより厳格なアクセス制限を設定する場合があります。たとえば、投稿やコミュニケーション機能を制限したり、年齢に応じたコンテンツ表示のフィルタリングを行うことが検討されます。
-
国際データ移転について
- 当社は、日本国内だけではなく、ユーザーが所在する国または地域とは異なる管轄のサーバーやデータセンターを利用する場合があります。そのため、ユーザーの個人情報が国外へ移転されることがあります。
- 国際的なデータ移転に際しては、移転先の国や地域における個人情報保護法制が日本またはEUなどの基準と同等以上の水準にあるかどうかを確認し、必要に応じて適切な契約(EU標準契約条項など)を締結するなど、個人情報が適切に保護される体制を整備します。
- ユーザーの明示的同意を得ることなく国際データ移転を行う場合、当社は日本国法令や国際ルールで認められた要件を満たす範囲でのみ実施します。たとえば、データの暗号化や仮名化を徹底することで、リスクを最低限に抑えた状態でデータを取り扱措置を講じます。
- 国際データ移転がサービス提供上不可避である場合、当社は利用規約や本ポリシーにてその旨を周知し、ユーザーがそのリスクや対策内容を理解できるよう配慮します。
Tool calls:
[]
Response Metadata:
{'is_blocked': False, 'safety_ratings': [], 'usage_metadata': {'prompt_token_count': 4197, 'candidates_token_count': 506, 'total_token_count': 4703, 'prompt_tokens_details': [{'modality': 1, 'token_count': 4197}], 'candidates_tokens_details': [{'modality': 1, 'token_count': 506}], 'cached_content_token_count': 0, 'cache_tokens_details': []}, 'finish_reason': 'STOP', 'avg_logprobs': -0.011727100304464106}
================= 最終的な出力結果 =================
16歳未満のユーザーが当社のサービスを利用する場合、法定代理人(親権者等)の同意を得ることが必要となる場合があります。ユーザーが未成年者であるにもかかわらず同意を得ていない場合、もしくは未成年者である旨を偽って利用登録を行った場合には、当社は一切の責任を負いかねます。
また、当社は、日本国内だけではなく、ユーザーが所在する国または地域とは異なる管轄のサーバーやデータセンターを利用する場合があります。そのため、ユーザーの個人情報が国外へ移転されることがあります。
以下に、toolから取得した情報を記載します。
-
未成年者の個人情報について
- 未成年者がサービスを利用するにあたっては、親権者が本ポリシーの内容を確認したうえで利用に同意することが望ましいと考えています。特に決済手段の登録や外部サービスとの連携など、リスクの高い行為については慎重な対応を求めています。
- 16歳未満の利用者の個人情報に関しては、一般のユーザーと同等のセキュリティ対策を講じていますが、必要に応じてより厳格なアクセス制限を設定する場合があります。たとえば、投稿やコミュニケーション機能を制限したり、年齢に応じたコンテンツ表示のフィルタリングを行うことが検討されます。
-
国際データ移転について
- 当社は、日本国内だけではなく、ユーザーが所在する国または地域とは異なる管轄のサーバーやデータセンターを利用する場合があります。そのため、ユーザーの個人情報が国外へ移転されることがあります。
- 国際的なデータ移転に際しては、移転先の国や地域における個人情報保護法制が日本またはEUなどの基準と同等以上の水準にあるかどうかを確認し、必要に応じて適切な契約(EU標準契約条項など)を締結するなど、個人情報が適切に保護される体制を整備します。
- ユーザーの明示的同意を得ることなく国際データ移転を行う場合、当社は日本国法令や国際ルールで認められた要件を満たす範囲でのみ実施します。たとえば、データの暗号化や仮名化を徹底することで、リスクを最低限に抑えた状態でデータを取り扱措置を講じます。
- 国際データ移転がサービス提供上不可避である場合、当社は利用規約や本ポリシーにてその旨を周知し、ユーザーがそのリスクや対策内容を理解できるよう配慮します。
続いてのユーザクエリは「おはよう」
出力結果
================= エージェントの実行結果 =================
=== Message 0 ===
Type: HumanMessage
Content:
おはよう
=== Message 1 ===
Type: AIMessage
Content:
おはようございます!何かお手伝いできることはありますか?
Tool calls:
[]
Response Metadata:
{'is_blocked': False, 'safety_ratings': [], 'usage_metadata': {'prompt_token_count': 161, 'candidates_token_count': 11, 'total_token_count': 172, 'prompt_tokens_details': [{'modality': 1, 'token_count': 161}], 'candidates_tokens_details': [{'modality': 1, 'token_count': 11}], 'cached_content_token_count': 0, 'cache_tokens_details': []}, 'finish_reason': 'STOP', 'avg_logprobs': -0.11558755961331454}
================= 最終的な出力結果 =================
おはようございます!何かお手伝いできることはありますか?
続いてのユーザクエリは「今日は12歳の誕生日なんだ。これから初めて海外に行くんだよね」
出力結果
================= エージェントの実行結果 =================
=== Message 0 ===
Type: HumanMessage
Content:
今日は12歳の誕生日なんだ。これから初めて海外に行くんだよね
=== Message 1 ===
Type: AIMessage
Content:
12歳のお誕生日おめでとうございます!初めての海外旅行、わくわくしますね!どちらに行かれるんですか?素敵な思い出がたくさんできますように。何かお手伝いできることがあれば、お気軽にお声かけください。
Tool calls:
[]
Response Metadata:
{'is_blocked': False, 'safety_ratings': [], 'usage_metadata': {'prompt_token_count': 170, 'candidates_token_count': 42, 'total_token_count': 212, 'prompt_tokens_details': [{'modality': 1, 'token_count': 170}], 'candidates_tokens_details': [{'modality': 1, 'token_count': 42}], 'cached_content_token_count': 0, 'cache_tokens_details': []}, 'finish_reason': 'STOP', 'avg_logprobs': -0.13439939135596865}
================= 最終的な出力結果 =================
12歳のお誕生日おめでとうございます!初めての海外旅行、わくわくしますね!どちらに行かれるんですか?素敵な思い出がたくさんできますように。何かお手伝いできることがあれば、お気軽にお声かけください。
こちらも前回と同様に、ユーザからの質問であればRAGをToolとして呼び出し、雑談には、Toolを実行せずに雑談として返すことができています。
まとめ
今回は、Google CloudのGCSをドキュメントローダとして、BigQueryをVector Storeとして利用したRAGのエージェントをLangGraphで実装しました。
次は、また別のVector Storeでの実装方法を記事にしたいと思います。
ここまで読んでくださり、ありがとうございました!
学習書籍
(書籍のリンクはamazonアフィリエイトリンクになります)
記事
LangChain と Google Cloud データベースを使用して強化された生成 AI アプリケーションを構築する
LangChainのチュートリアル記事「Google BigQuery Vector Search」
Google APIのリスト
2024/9/1 langchain-google-vertexai は ChatVertexAI を使うべし
書籍
Generative AI on Google Cloud with LangChain: Design scalable generative AI solutions with Python, LangChain, and Vertex AI on Google Cloud
英語ではありますが、非常に分かりやすい書籍です。
というか、現在においてLangChain+Google Cloudを取り巻くライブラリの複雑さは異常だと思っています。
各DBごとに必要なライブラリが乱立しており、どのライブラリを利用するのが良いのかが分かりにくいです。(なぜなら技術記事では、一つのライブラリ、一つのDBにフォーカスしており、他にどんな選択肢があるのかが分かりにくい)
本書籍は、それらをすべて統括して分かりやすく記載されているため、全体像が掴みやすくおすすめの書籍になっています。
英語の本ではありますが、購入時にPDFも一緒に取得することができる(2025年2月現在)ため、「Google 翻訳」のPDF変換機能で翻訳することで、英語がわからなくても読むことができますので、ぜひお試しください。
(PDFが取得可能かどうかは、Amazonの商品概要欄に記載してありますので、購入前にお確かめください)
LangChainとLangGraphによるRAG・AIエージェント[実践]入門
ChatGPT/LangChainによるチャットシステム構築[実践]入門
LangChainを利用することで、あらゆるモデルを統一的なコードで実行できるようになります。
langchainに関しては、こちらの書籍を読めば大体のことはできるようになりますので、おすすめです。
また、現在推奨されているLangGraphでのRAG Agentを構築するcreate_react_agentに関しても説明されておりますし、さらに複雑なAgentsの構築方法やデザイン方法も網羅されており、とても勉強になります!
大規模言語モデル入門
大規模言語モデル入門Ⅱ〜生成型LLMの実装と評価
よく紹介させていただいておりますが、こちらの書籍は、LLMのファインチューニングから、RLHF、RAG、分散学習にかけて、本当に幅広く解説されており、いつも参考にさせていただいております。
今回の記事で紹介したRAGの内容だけでなく、さらにその先であるRAGを前提としてInstruction Tuningについても触れており、とても面白いです。
LLMを取り扱っている方は、とりあえず買っておいても損はないと思います。
さまざまな章、ページで読めば読むほど新しい発見が得られる、スルメのような本だなといつも思っております。
LLMのファインチューニングとRAG ―チャットボット開発による実践
上記2冊の本よりもRAGやファインチューニングに絞って記載されている書籍です。だいぶ平易に書いてあるのでとてもわかりやすいと思いました。
また、本記事の内容ではないですが、RAGを実装する上でキーワード検索を加えたハイブリッド検索を検討することは一般的だと思います。本書はそこにも踏み込んで解説をしています。
また、キーワード検索でよく利用するBM25Retrieverが日本語のドキュメントに利用する際に一工夫がいるところなども紹介されており、使いやすい本だなと思いました。
Discussion