はじめに
アルサーガパートナーズ株式会社でサーバーサイドエンジニアをしております、おーせと申します。
最近では、FastAPIを用いてバックエンドAPIの開発をメインに行なっております。
今回は、実務で発生したエラーとその解決策、セッション管理の重要性についてまとめますので、同じ境遇の方の参考になりましたら幸いです。
起こった事象
検証環境のSwaggerUIを使用して、テスト設計に基づきエンドポイントを叩いていたところ、時々500エラーが発生するという事象が発生しました。
毎回500エラーではなく、2回に1回は成功して1回は500エラーになると言った現象が発生して、検証環境での動作検証も一時滞るという事態になりました。
SwaggerUIとは(補足)
RESTful APIのドキュメントを視覚化、インタラクティブに操作できるユーザーインターフェースを提供するツールで、FastAPIでサポートされています。
(以下のようなUIのツールです。(FastAPI公式から引用))
発生したエラーについて
AWSで検証環境に関わるCloudWatchのログを確認したところ、エラー文言の中に以下の記載が複数発生していることを確認しました。
sqlalchemy.exc.PendingRollbackError: This Session's transaction has been rolled back due to a previous exception during flush.
To begin a new transaction with this Session, first issue Session.rollback().
Original exception was: (psycopg2.errors.NumericValueOutOfRange) integer out of range
原因と解決方法
このエラーを解釈すると、前回のSessionのトランザクションが終了していないことで、新たなトランザクションが開始できないことを意味します。
FastAPIでは、Sessionを自身で定義し、トランザクションを操作する必要があり、今回Session定義の部分が以下のように記載されていました。
※以下の実装は実際のものではなく、個人の実装に置き換えて記載しています。
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, declarative_base
DATABASE_URL = "postgresql://postgres:password@postgres-db:5432/postgres"
engine = create_engine(DATABASE_URL)
Session = sessionmaker(autocommit=False, autoflush=False, bind=engine)
# 上で定義したセッションをそのままreturnしていた。
def session_factory():
return Session()
上記のようにそのままSessionのインスタンスを返していたことで、処理の途中で500エラーが発生して失敗しても、トランザクションがロールバックやクローズされることなく、そのまま残ってしまい、新たな処理に影響していた可能性があります。
そのため、session_factory()の記載を以下のように修正し、最後には必ずクローズさせることで検証環境の500エラーは解消されました。
def session_factory():
session = Session()
try:
yield session
finally:
session.close()
修正した実装と解決した理由についての整理
yieldによりSessionのインスタンスsessionを渡します。
yieldは関数内の処理を一時停止して呼び出し元に提供し、呼び出し元での実行が終われば関数の処理が再開する処理を実現します。
def session_factory():
session = Session()
try:
yield session # 呼び出し元でsessionの処理が終了後、関数内の処理が再開する。
finally:
session.close() # 最終的には必ずcloseされる。
returnだと関数内の処理が終了してしまいその後の処理は無視されますが、yieldだとsessionを渡した後に再びsession_factory()の実行が再開します。
def session_factory():
session = Session()
try:
return session # 関数内の処理は終了、その後の処理は無視され、finallyブロックは実行されない。
finally:
session.close() # closeの処理は実行されない。
そして、finayllyはtryブロックが成功しても失敗しても呼び出されるので、ここでsession.close()を呼ぶことで必ずSessionを閉じることが可能です。
この実装では、yieldを使用して一時的にSessionを呼び出し元に提供し、呼び出し元がSessionを使用した後、finallyブロックで適切に閉じて、リソースリークを防止しています。
今回の事象から学ぶ点
今回実装箇所さえ特定できてしまえば解決は早かったのですが、解決に予期せぬ工数がかかってしまいました。
先述したとおりFastAPIではSessionを自ら定義し、トランザクションを操作する必要があるため、チーム内で記載の統一をしないとデータの不整合を招いてしまう可能性があります。
今回の事象を教訓にSessionに対する理解を深める必要があると感じたので、以下それぞれ整理してまとめたいと思います。
- Sessionについて
- トランザクションについて
- 適切なSession管理のために意識すること
Sessionについて
Sessionとは
今回の説明で使用しているFastAPIのセッションは、データベース接続やトランザクションを制御するために利用され、データベース操作の始まりから終わりまでを管理します。
セッション自体は、通常、SQLAlchemyなどのORM(Object-Relational Mapping)ライブラリなどのデータベース操作ライブラリで作成します。
設定方法
以下のように記載することでFastAPIのアプリとデータベース(例ではpostgreSQLを使用)を接続し、呼び出すことでDBに保存する実装などが可能になります。
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, declarative_base
"""
postgresを例にとると、以下のような配置でURLをセットします。
DATABASE_URL = "postgresql://{User名}:{password}@{Host名}:{port番号}/{DB名}"
"""
DATABASE_URL = "postgresql://postgres:password@postgres-db:5432/postgres"
engine = create_engine(DATABASE_URL)
Session = sessionmaker(autocommit=False, autoflush=False, bind=engine)
# セッションを依存性として定義
def session_factory():
session = Session()
try:
yield session
finally:
session.close()
このファイルでやっていることを一つずつ解説します。
データベースURLの設定
DATABASE_URL = "postgresql://postgres:password@postgres-db:5432/postgres"
まず、接続するDB情報を記載します。 SQLAlchemyでサポートされているデータベースは以下を例に多岐に渡ります。
- PostgreSQL
- MySQL
- SQLite
- Oracle
- Microsoft SQL Serverなど
参照元:SQL (リレーショナル) データベース(FastAPI公式Docs)
ただし、データベースごとに接続するためのURL形式が異なりますので注意が必要です。
参考までにSQLiteとMySQLの場合はそれぞれ以下のような形式でURLを設定します。
"""
①SQLite
形式: sqlite:///の後にSQLiteデータベースファイルのパスが続く。
"""
SQLALCHEMY_DATABASE_URL = "sqlite:///./sql_app.db"
"""
②MySQL
形式:"mysql+pymysql://{username}:{password}@{hostname}:{port}/{database_name}"
"""
SQLALCHEMY_DATABASE_URL = ""mysql+pymysql://mysql_user:password@db:3306/mysql_db"
Engineの作成
SQLAlchemyのエンジン(Engine)は、SQLAlchemyでデータベースに接続するための核となる部分で、データベースへの接続を確立し、クエリの実行やトランザクションの管理を担当します。
エンジンを作成するためには、データベースの種類(PostgreSQL, MySQL, SQLiteなど)や接続情報を指定する必要があるため、先ほどで設定したURLをSQLAlchemyのメソッドであるcreate_engineの引数として渡して実行します。
engine = create_engine(DATABASE_URL)
Sessionクラスを作成
sessionmakerメソッドを使用してデータベース操作をするためのSessionクラスを作成します。
Session = sessionmaker(autocommit=False, autoflush=False, bind=engine)
bindにはSessionクラスがどのデータベースエンジンと接続するかを指定します。こちらには、先ほどcreate_engineで作成したengineを設定します。
その他にも、sessionmakerメソッドにはautocommitとautoflushという設定があります。
それぞれ以下のような特徴があり、今回はどちらもFalseとして無効化しています。
-
autocommit
セッションが自動的にコミットするかどうかを制御する設定でautocommitをTrueに設定すると、各文が即座にコミットされるようになります。 -
autoflush
セッションが自動的に変更をデータベースにflush(送信)するかどうかを制御します。
flushとは、commitの一歩手前の状態で、データベースに変更を送信し、一時保存する機能を持ちます。autoflushをTrueに設定することでセッションが変更を追跡し、必要に応じてflushされます。
依存性として定義する関数(session_factory)を作成
今回はsession_factoryメソッドという名称で定義します。以下実装例です。
def session_factory():
session = Session()
try:
yield session
finally:
session.close()
詳細な説明は重複するので割愛しますが、Sessionクラスのインスタンスを作成し、yieldを用いてsession_factoryの呼び出し元に渡します。
処理が終わればsession_factoryの処理が再開し、最後にsession.close()が実行され、セッションを適切に閉じられます。
また、以下のように処理の途中にエラーが発生した場合には、rollbackを実行する処理まで記載している例もあります。
def session_factory():
session = Session()
try:
yield session
except Exception:
session.rollback()
raise
finally:
session.close()
この場合、セッション操作中に例外が発生した場合rollbackの処理が走ってから、最後にsession.close()が実行される処理の流れになります。
database.pyで作成したsession_factory()は先ほども記載しましたが、パス関数内で依存性として定義し、使用することができます。
@router.post("/items", response_model=ItemOrm)
async def create_item(
item_data: ItemCreate,
# Dependsを使用してDI(依存性注入)
session: Session = Depends(session_factory)
):
"""
Itemを一件Insertするためのエンドポイント
"""
item = Item(**item_data.dict())
session.add(item)
session.commit()
session.refresh(item)
return item
Sessionクラスで使用できるメソッドはSession API(SQLAlchemy公式)にまとまっておりますので、ご参照ください。
トランザクションについて
トランザクションとは
自分の理解で恐縮ですが、トランザクションは、1つの目的に必要な複数の処理を1つにまとめたものを指すと考えています。
銀行口座での送金・入金を例に取ると、例えばAさんの口座からBさんの口座に5,000円送金するとします。その時に必要な処理は下の2点です。
- Aさんの口座から5,000円を差し引く。(-5,000円)
- Bさんの口座に5,000円を振り込む。(+5,000円)
これら2つの処理は「Aさんの口座からBさんへの口座へ送金する」という目的で同時に達成する必要があります。
一つでも欠けていると、Aさんの口座から5,000円が消えただけになったり、Bさんの口座で勝手に5,000円増えたようになってしまうため、2つの処理は密接に関係しています。
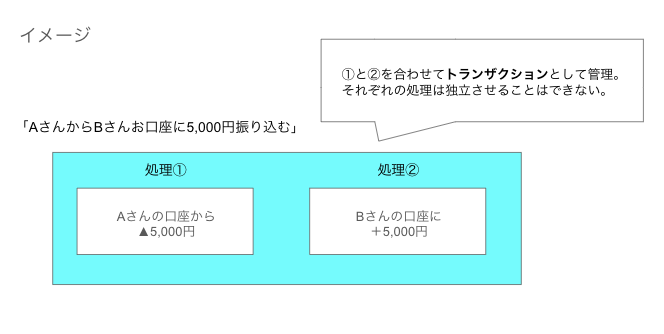
今回の目的だと1と2を合わせてトランザクションであり、処理を実行する際はデータの整合性を担保し、どちらか一つだけが失敗しないように管理する必要があります。
FastAPIに限らずアプリ開発を行う上で、トランザクションの特定とその管理は重大なエラーを発生させない意味でも大事になってきます。
FastAPIでは、Sessionの設定によっては1件ごとにcommit処理が走ってしまう可能性があります。
例えば、以下のように一つのトランザクションの関連する保存処理それぞれをcommitしてしまうとトランザクション単位ではなく、処理それぞれに保存処理が走ってしまいます。
@router.post("/item_list")
async def create_item_list(
item_data_list: List[ItemCreate],
session: Session = Depends(session_factory)
):
"""
複数のItemをInsertするためのエンドポイント
"""
for item_data in item_data_list:
item = Item(**item_data.dict())
session.add(item)
# ここで1件ずつcommitしている。
session.commit()
万が一ループ処理の途中で失敗してしまった場合、途中までの保存処理が実行されてしまい、データベースの整合性が損なわれる可能性があります。
このような状況を回避する実装として主に2つの方法があります。
flush()の活用
flush()とは、トランザクション内での変更をデータベースに反映させる前に、変更を一時的にデータベースに送信するメソッドで、今回の実装例だとsession.flush()という形で使用します。
以下実装の改善例です。
@router.post("/item_list")
async def create_item_list(
item_data_list: List[ItemCreate],
session: Session = Depends(session_factory)
):
"""
複数のItemをInsertするためのエンドポイント
"""
for item in item_data_list:
item = Item(**item.dict())
session.add(item)
# 一つ一つの処理はcommitせずにflushで送信
session.flush()
# トランザクション終了のタイミングでcommitしてデータ保存を確定
session.commit()
複数の処理が存在するトランザクションの場合、一つ一つの処理を一旦flush()で送信しておき、最後にcommit()することで処理を確定させます。
すべての処理が完了するまで保存処理が走らないため、途中で失敗してもデータの整合性が損なわれません。
context managerの活用
以下のように明示的にPythonのcontext manager(with文)を使用する方法もあります。
@router.post("/item_list")
async def create_item_list(
item_data_list: List[ItemCreate],
session: Session = Depends(session_factory)
):
"""
複数のItemをInsertするためのエンドポイント
"""
with session.begin():
for item in item_data_list:
item = Item(**item.dict())
session.add(item)
session.flush()
上記のように実装すると、with文の終了と共にSessionがコミットし、クローズされます。
トランザクション内の処理をすべてwith文に含めて、それぞれflushすることでwith文の終了に合わせて一括して保存(commit)され、データの整合性も損なわれません。
途中で処理が失敗してもflush()なので、保存されることなくロールバックします。
適切なSession管理のために意識すること
セッション管理を行うために以下2点が特に重要だと感じました。
それぞれ私の意見を記載させていただきます。
トランザクションとして管理する範囲の明確化
月並みなことですが、仕様を把握した上で一つのトランザクションとして管理すべき処理を明確化することが重要です。
記載によってはデータの不整合を招いてしまう可能性があるので、まずは仕様を理解し、トランザクションとしての範囲を特定して実装する必要があります。
Sessionの管理方法を開発チームで統一する
Sessionクラスを定義する記載もチームによってそれぞれです。
しっかりclose処理が書かれているか、処理ごとにrollbackは行うか、など整理した上で、トランザクション単位の処理をflushとcommitを使い分けて制御するのか、それともcontext managerを使用して明示的に管理するかを整理することが大事だと思います。
データベースの整合性はサービスとしての信頼性を担保する上でも特に重要な部分なので、チームでどのようにSessionを管理すべきか話し合うことが重要です。
最後に
同じエラーに遭遇した方やSession管理についてよくわからないという方の参考になれば幸いです。最後まで読んでいただいてありがとうございました!
明日は、@r0w2.0さんの記事になります!お楽しみに🎅
参考文献

Discussion