はじめに
エンジニア歴1年未満の新米がデータベースについて勉強したので、初心者なりにまとめてみました!技術記事を書くのは初めてなので、間違えているところがあれば教えていただけると助かります🙇♀️
前提知識
データベースについて
データベースとは、情報を効率的に保存・検索・管理するための構造化されたデータの集まりのことをいいます。
分かりやすく例えると、図書館のようなものです。図書館では、大量の本を論理的に整理し、カタログ化して保存していて、新しく本を追加したり古い本を削除したり、利用者が必要な本を探したりできるようになっています。データベースでも同様に、新しいデータを保存したり削除したり、ユーザーがデータを検索して必要な情報を探したりできるようになっています。
データベースには様々な種類がありますが、現在最も広く利用されているのがRDB(リレーショナルデータベース)です。
RDBについて
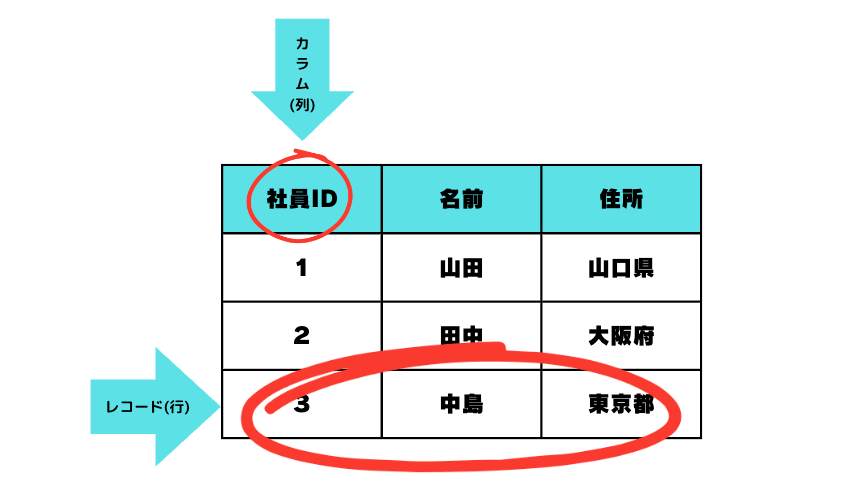
Excelシートのように、列と行からなる2次元表の形式でデータを管理するデータベースのことを、リレーショナルデータベース(通称RDB)といいます。
RDBにおいて、データはテーブルという構造で保存されます。テーブルがデータベースの中に複数存在し、1つ1つのデータがそれぞれのテーブル内で保管されているイメージです。
下の表のように、列(カラム)と行(レコード)で構成されていて、カラムはテーブルに保管するデータ項目を表し、レコードは1行でデータ1件を表します。
今回まとめていくのは、RDBにおいての設計となります!
論理設計について
データベース設計の手順を大きく分けると、以下の2つに分けられます。
- 論理設計
- 物理設計
論理設計とは、どのようにデータを整理し、関連付け、保存するかを計画するプロセスのことです。データの種類や関係性を定義し、データの整合性を保ちながら、効率的な検索や更新を可能にするためのルールや構造を設定します。
一方物理設計は、論理設計で定義されたデータベースの構造に基づいて、実際のデータベース管理システム(DBMS)が理解できる形式に変換し、パフォーマンスと効率を最適化するプロセスのことです。データベースシステムがスムーズに動作し、必要な情報を高速かつ安全に取得できるように設計していきます。
要するに、論理設計はデータベースの設計図を作成する段階で、物理設計は設計図を元にどうやって実現するかを決める段階となります。
論理設計の流れ
論理設計の手順としては、下記のように4つの工程に分けることができます。
- エンティティの抽出
- エンティティの定義
- 正規化
- ER図の作成
1. エンティティの抽出
エンティティは、実体・存在・本体などの意味を持ちますが、ここでは「ユーザー」や「商品」といったデータの集まりのことを指します。まず最初に、システムで必要となるエンティティを抽出します。
デリバリーシステムなどを例に考えてみる・・・
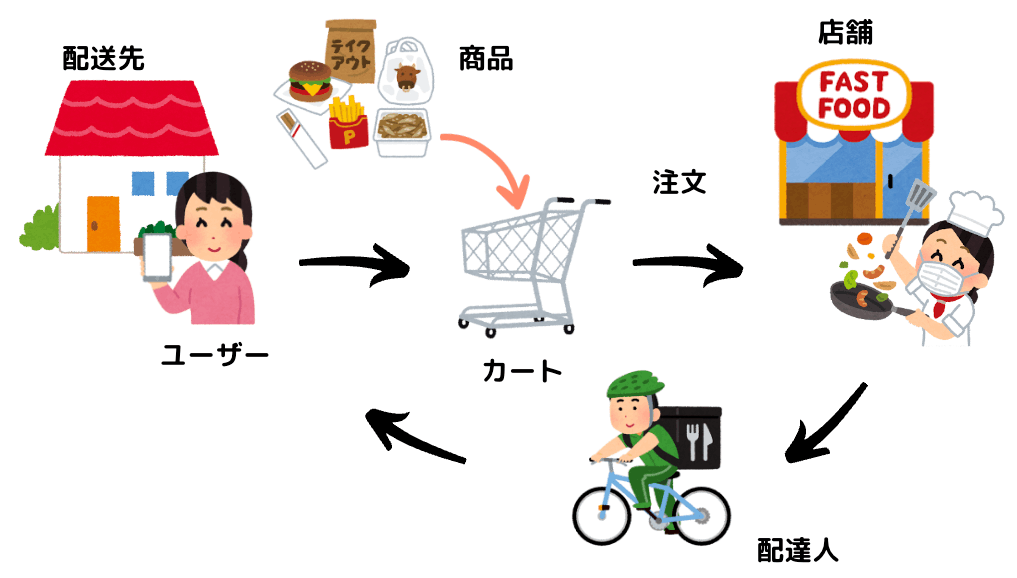
- 「ユーザー」や「配達人」といった登場人物
- 「商品」や「カート」などの物
- 「店舗」や「配送先」などの場所
- 「注文」などの行為
2. エンティティの定義
エンティティの抽出が完了したら、次はエンティティの定義です。それぞれのエンティティがどのようなデータを保持するかを決める必要があります。属性を洗い出すことで、どのエンティティにどのようなデータを持たせるかを定義し、テーブルを作成していきます。
先程抽出したエンティティに関係ありそうな属性を洗い出してみる・・・

- ユーザー:氏名やメールアドレスの属性
- 商品:商品名や価格の属性
- 注文:請求金額やユーザー情報の属性
- 店舗:店名やジャンル、住所の属性
3. 正規化
正規化とは、効率の悪いテーブルを分割していくことです。データの登録や変更、削除などがスムーズに行えるよう、関連する情報を適切なテーブルに配置していきます。通常、第一正規形、第二正規形、第三正規形と、複数の段階で行われますが、原則第三正規形まで行えば十分とされています(第六正規形まである)。
1回の注文で複数の商品を注文する場合・・・

1つの属性に複数のデータを入れてみる

上記のテーブルだと、商品と個数の組み合わせが分かりづらい上に、一部だけ編集・削除したい時にシステム上面倒になるというデメリットがあります。これを解決するために、順番に正規化していきます。
第一正規形
- 1つのセルには1つの値しか入らない
- 関数従属性を満たすように整理していく
- 関数従属性とは、関数「y=f(x)」のように、ある属性のxの値が決まると他の属性yの値が一意に決まる関係のこと
下の表のように、1つのセルの中に2つ以上の値が入ることは、RDBでは規則違反になってしまう・・・


1つのセルに対して1つの値が入るように行を追加していく

これが第一正規形となります。この考え方と結びついているのが関数従属性といって、ある属性の値が決まると他の属性の値も決まるという関係にならなければいけません。1つのカラムの値が決まったら、他のカラムの値も決まるというテーブルでなくてはならないということです。
山田さんがハンバーガーを注文→注文する個数が決まる
第二正規形
- 主キーを1つに絞る
- 部分関数従属を排除し、完全関数従属にする
- 部分関数従属とは、ある属性(列)が他の属性の一部にだけ依存している状態のこと
- 完全関数従属とは、ある属性の値がわかると、他の属性の値が必ず一意に定まるという関係性のこと
4行目にある田中さんの名前を変更した際に、同じ人物である5行目の田中さんの名前が変わっていないという矛盾が生じてしまう・・・

主キーが1つになるようにテーブルを分割する

「ユーザーテーブル」と「商品テーブル」、そして注文したユーザーの情報と商品の情報、個数の情報を組み合わせた「カートテーブル」の3つに分けることができました。この形が第二正規形です。第二正規形では、テーブルを分割して主キーを1つに絞っていきます。
第一正規形のままだと、部分関数従属の関係が存在するためデータを一意に特定できず、ミスが起こってしまいます。例えば「商品ID」が1の場合、「商品名」は「ハンバーガー」です。しかし、同じ商品ID(1)が別の行にも存在する場合、「商品名」が「ハンバーガー」であるか「ポテト」であるかは区別できません。このように、主キーの一部に対して従属する列がある状態を部分関数従属と言いますが、この部分関数従属を排除して完全関数従属にしていくことで、テーブルに矛盾が生じなくなります。
第三正規形
- 主キー以外の項目で関数従属している部分を分割する
- 他のデータと紐づかないデータも登録が可能
- 推移的関数従属を排除
- 推移的関数従属とは、テーブル内に段階的な従属関係があること
1人のユーザーは1つの配送先しか登録することができない・・・

テーブルを分割することで、配送先を増やすことが可能になる

特定のユーザーIDが与えられると、そのユーザーの複数の配送先IDがわかり、それぞれの配送先IDが特定の配送先住所に関連付けられています。この状態を推移的関数従属と言います。上のテーブルを分割して、推移的関数従属を排除した形が第三正規形となります。
4. ER図の作成
第三正規形まで正規化できたら、次はER図の作成です。ER図とは、データ同士の関係性を表す図のことです。データの関係、およびデータの構造を視覚的に示すのに役立ちます。ER図は主に以下の要素で構成されます。
- エンティティ:データの集まりのこと
- アトリビュート:エンティティの中の属性情報のこと
- リレーション:データ同士の関係を表現する線のこと
- カーディナリティ:リレーションの詳細を表現する記号のこと

テーブル同士の関係性
ER図を作成するには、テーブル同士の関係にはどのような種類があるのか知っておく必要があります。基本的なリレーションの種類は以下の3つです。
1対1
まずは1対1の関係ですが、このパターンは論理設計においてはほとんど使われません。なぜなら、1つのテーブルにまとめても問題ないことが多いからです。下の図のように、1人のユーザーは1つの電話番号を持ち、電話番号も1人のユーザーだけに関連がある場合、ユーザーテーブルの属性として電話番号を加えても問題ありません。
※システムの要件やセキュリティの観点から鑑みて、テーブルを分割して1対1の関係にした方が良い場合もあります。

1対多
最も多く使われるのがこのパターンで、データの整理・取得・表示など、さまざまな操作を行う際に非常に有用です。下の図は、1人のユーザーは複数の投稿をすることができ、投稿は特定の1人のユーザーに関連付けられることを表しています。厳密にいうと、「1対0以上の関係」「1対1以上の関係」のように考えることもできます。

多対多
システム上、問題が起こる可能性が高い関係性がこのパターンです。下の図は、ユーザーは複数の商品を注文することができ、商品は複数のユーザーによって注文されることができることを表しています。このような関係はデータモデルが複雑になり、データベースの管理が難しくなるなどのデメリットがあります。

中間テーブル
上記の多対多の回避方法として、中間テーブルを作成することがあげられます。中間テーブルを挟むことにより、多対多の関係から1対多の関係にすることができます。下の図のように、ユーザーと商品の間に「カート」というテーブルを用意することで、ユーザーとカート、商品とカートでそれぞれ1対多の関係にすることができます。

さいごに
ここまで、データベースの論理設計を4つの工程に分けてそれぞれ説明してきましたが、論理設計を行う上で(個人的に)最も大事だと感じるのは、要件の明確化です。システムの要件を十分理解した上で設計を行わないと、データベースのエンティティや関係性を把握できず、必要とするデータを適切な形で格納することができません。システムの品質を下げるだけでなく、後の運用にも大きな影響を及ぼす可能性があります。したがって、まずは要件を明確化し、エンティティの抽出を適切に行うことが重要だと考えられます。

Discussion