phi3とollamaを使ってローカルでデータ処理を行ってみる① 文章分類




LLMをまともに使ったことがなかったので、勉強がてら。
前提
- 想定用途: アンケートとか数百件程度のデータに対し、さくっと加工を済ませる。
- ChatGPTは使わず、ローカルで完結させることを目指す。
- 実務においてセキュリティでとやかく言われずに完結させたいため。
- また、費用的にもお得。
- ある程度の速度はほしい。
- GPUがなくても動く仕組みとしたい。
- ChatGPTは使わず、ローカルで完結させることを目指す。
環境構築
ollama
(あまり良くわかっていないが)LLMを裏で実行して専用のAPIをローカルに生やすソフトという理解。
まずはインストール。Linuxの場合。
curl -fsSL https://ollama.com/install.sh | sh
Windowsの場合は公式から落とせそう(試してない)
そして実行。
ollama serve
モデルをダウンロードしておく。
今回は出来立てほやほやのphi3を使うことにした。
ollama pull phi3
python
使うライブラリをインストールしておく。
pip install polars ollama
タスク1: 文章分類
サンプルとして、与えられた表題にいくつかのタグのうちどれか1つをつける、みたいなタスクを想定する。
データ準備
GitHub Copilotに適当にデータを生成してもらう。
日本語と英語交じりのデータにしてみた。
ISSUE_SAMPLE = [
{"title": "Add support for dark mode", "label": "enhancement"},
{"title": "Fix crash when clicking on 'Save' button", "label": "bug"},
{"title": "Update README with new installation instructions", "label": "documentation"},
{"title": "Improve performance of data processing module", "label": "enhancement"},
{"title": "Error message not clear when login fails", "label": "bug"},
{"title": "Add documentation for the new API endpoints", "label": "documentation"},
{"title": "Implement auto-save feature", "label": "enhancement"},
{"title": "Fix incorrect results in search functionality", "label": "bug"},
{"title": "Update user guide with new screenshots", "label": "documentation"},
{"title": "Add multi-language support", "label": "enhancement"},
{"title": "Application freezes when uploading large files", "label": "bug"},
{"title": "Improve documentation of error codes", "label": "documentation"},
{"title": "Add option to customize application theme", "label": "enhancement"},
{"title": "Fix memory leak in image processing module", "label": "bug"},
{"title": "Add FAQ section to the documentation", "label": "documentation"},
{"title": "Implement feature to export data in CSV format", "label": "enhancement"},
{"title": "Application crashes on startup", "label": "bug"},
{"title": "Update API documentation with new changes", "label": "documentation"},
{"title": "Add feature to import settings", "label": "enhancement"},
{"title": "Fix broken links in the help section", "label": "bug"},
{"title": "ダークモードのサポートを追加", "label": "enhancement"},
{"title": "'保存'ボタンをクリックするとクラッシュする", "label": "bug"},
{"title": "新しいインストール手順でREADMEを更新", "label": "documentation"},
{"title": "データ処理モジュールのパフォーマンスを改善", "label": "enhancement"},
{"title": "ログイン失敗時のエラーメッセージが不明確", "label": "bug"},
{"title": "新しいAPIエンドポイントのドキュメンテーションを追加", "label": "documentation"},
{"title": "自動保存機能を実装", "label": "enhancement"},
{"title": "検索機能の結果が不正確", "label": "bug"},
{"title": "新しいスクリーンショットでユーザーガイドを更新", "label": "documentation"},
{"title": "マルチ言語サポートを追加", "label": "enhancement"}
]
また、分類用のラベルも用意する。
今回は機能要望(enhancement),バグ(bug),文章改善(documentation),スパム(spam)の4つを用意した。
LABELS = ["enhancement", "bug", "documentation", "spam"]
上記データを元に、元データセットのサンプルを作成する。
import polars as pl
df = pl.DataFrame(
ISSUE_SAMPLE,
schema=["title", "label"]
)
df.sample(5).to_pandas()
titleと正解ラベルであるlabel列が存在するデータセットが用意できた。

システムプロンプトを用意する
こんな感じのプロンプトを用意した。カテゴリは動的に落とし込まれるように変数で代入。
# (訳)
# あなたは、与えられた文章に1つのタグをつける専門家です。
# 与えられた文章を以下のカテゴリのいずれかに分類してください。
# 以下のカテゴリのうち1つだけを選択しなければならない。
# 余計な出力をせずに、与えられたカテゴリの単語を1つだけ使って答えなければならない。
# ---
# カテゴリ: [機能要望,バグ,文章改善,スパム]
SYSTEM_PROMPT = f"""
You are an expert categorizer who tags one tag for a given sentence.
Please classify the given sentence into one of the following categories.
You MUST choose one of the following categories ONLY.
You MUST answer with only one of the words in a given category without any extra output.
---
Categories: {LABELS}
""".strip()
CHAT_BASE = [
{"role": "system", "content": SYSTEM_PROMPT},
# 具体例を渡してあげる(few-shot)ときは、ここでサンプルを提供する
{"role": "user", "content": "Add support for dark mode."},
{"role": "assistant", "content": "enhancement"},
]
pythonからollamaを叩く用の関数を用意する
使い方は正直コードを見ればすぐわかると思う。
LLMの性質上、出力結果が安定しないので後処理は必須。
今回は入れていないが、たまにとんでもないのを返してくるのでラベル候補以外の出力は無視したほうが良い。
# ollamaに分類タスクを解いてもらう
import ollama
def ollama_chat(input: str):
USE_MODEL = "phi3"
rst = ollama.chat(
model=USE_MODEL,
messages=[
*CHAT_BASE,
{"role": "user", "content": input},
],
options={
# reference: https://github.com/ollama/ollama/blob/main/docs/api.md
"top_k": 1,
"temperature": 0.01,
"top_p": 0.9,
"num_predict": 5,
"penalize_newline": True,
},
)
return postprocess(rst["message"]["content"])
# 出力結果の後処理
# 改行や空白以降の文字を無視する
import re
def postprocess(output: str):
return re.split("\s", output)[0]
試してみる
まずは上記で用意したollama_chat関数を単一データで試してみる。
ollama_chat("バージョンアップ後、うまく動作しなくなった。")
# >> 'bug'
しれっとやっているが日本語をしっかり認識できているのがすごい。
ollama_chat("今ならひき肉が30円引き! やすい! お得!")
# >> 'spam'
訓練なしでちゃんとスパムを認識できていそうなのがすごい。
当てはめてみる
polarsのmap_element関数を使って1つずつ当てはめてみる。
df_with_class = (
df.with_columns([
pl.col("title").map_elements(ollama_chat, return_dtype=pl.String).alias("llm_label"),
])
.with_columns([
(pl.col("label") == pl.col("llm_label")).alias("correct")
])
)
自分のデスクトップPCで実行したところ、30件のデータで7.8秒ほどかかった。
結果を見てみると
df_with_class.to_pandas()
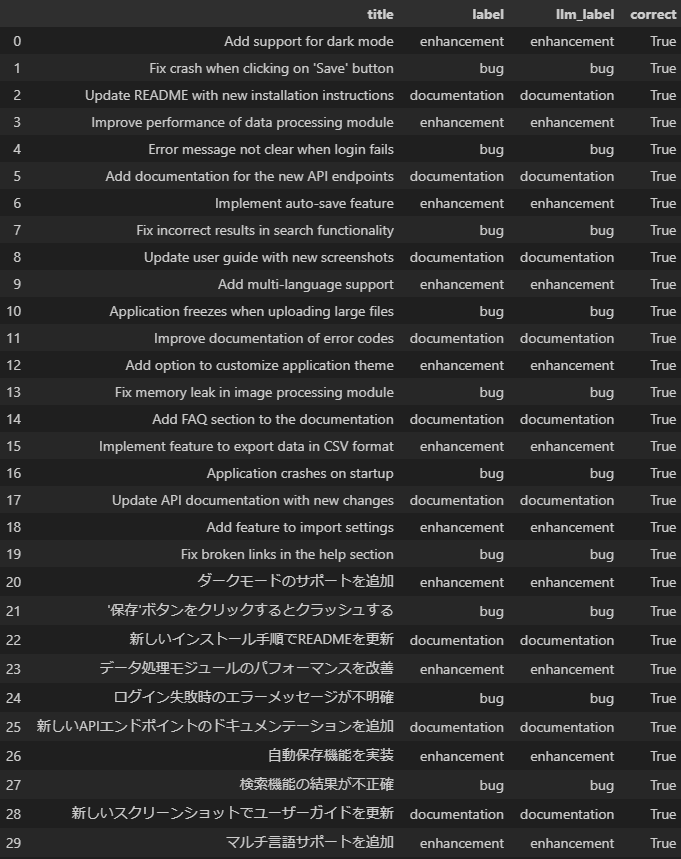
全問正解!
単純な例なので複雑になったときどうなるかはわからないが、初手としてはかなり良さそう。
所感
- 思ってたよりパワーを感じたのでこっち方面の勉強もしないとなあと思った次第。
- 出力がもう少し早くなればさらに色々使えそう。
- そこそこの性能のPCに、部署のメンバーが専用で使えるollama serverを立ててもいいかも。
- それならchatgptとかazureでいい気もするけど、それまでの繋ぎとしては良さそう。
- そこそこの性能のPCに、部署のメンバーが専用で使えるollama serverを立ててもいいかも。
Discussion