B200でNVFP4量子化モデルの推論を試す(llm-compressorによるLLMの量子化)
はじめに
この記事は、Blackwellから対応しているNVFP4量子化と推論をB200で実際に試し、速度や精度を測定してみたという記事です。
NVFP4とはなんぞやについてはこちらのNVIDIAの記事をご確認ください。
量子化
推論を試す前に、まずは量子化を試してみます。既にFP4に量子化されているモデルがHFにいくつかあるのでそれを使っても良いのですが、せっかくなので今回は自分で量子化するところから試してみます。
今回、量子化にはllm-compressorというライブラリを利用します。このライブラリはLLMの各種量子化を行うためのオープンソースフレームワークで、vLLMの関連ライブラリとして開発されています。
量子化の対象モデルとして、以前私が作ったMistral-Nemoベースの12Bモデルを利用します。
使い方はかなり簡単です。以下に量子化の手順を示します。(動作確認はRunPodのrunpod/pytorch:2.8.0-py3.11-cuda12.8.1-cudnn-devel-ubuntu22.04で行っていますが、CUDAやTorchのバージョンによっては上手く動作しないかもしれません)
- llm-compressorをインストール
シンプルにpipからインストールすることができます。
pip install llm-compressor
# 動かない場合は最新のmainで解決している可能性もあります
pip install git+https://github.com/vllm-project/llm-compressor.git@main
- 量子化の実行
以下のようなスクリプトを実行することで、NVFP4への量子化ができます。今回はWeightとActivationの両方をFP4に量子化しています。
RunPodのA100を使って量子化・保存まで1時間弱程度でした。量子化にはBlackwellは不要です。
量子化スクリプト
from datasets import load_dataset, concatenate_datasets
from transformers import AutoModelForCausalLM, AutoTokenizer
from llmcompressor import oneshot
from llmcompressor.modifiers.quantization import QuantizationModifier
from llmcompressor.utils import dispatch_for_generation
# 量子化対象のモデル
MODEL_ID = "Aratako/NemoAurora-RP-12B"
# モデルとトークナイザをロード
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
# Calibration用のデータ
# 今回は学習に利用していたデータを使います
DATASET_ID_1 = "Aratako/Synthetic-Japanese-Roleplay-SFW-DeepSeek-R1-0528-10k-formatted"
DATASET_SPLIT_1 = "train"
DATASET_ID_2 = "Aratako/Synthetic-Japanese-Roleplay-NSFW-DeepSeek-R1-0528-10k-formatted"
DATASET_SPLIT_2 = "train"
NUM_CALIBRATION_SAMPLES = 512
MAX_SEQUENCE_LENGTH = 4096
ds1 = load_dataset(DATASET_ID_1, split=f"{DATASET_SPLIT_1}[:{NUM_CALIBRATION_SAMPLES}]")
ds2 = load_dataset(DATASET_ID_2, split=f"{DATASET_SPLIT_2}[:{NUM_CALIBRATION_SAMPLES}]")
ds = concatenate_datasets([ds1, ds2])
ds = ds.shuffle(seed=42)
def preprocess(example):
return {
"text": tokenizer.apply_chat_template(
example["messages"],
tokenize=False,
)
}
ds = ds.map(preprocess)
def tokenize(sample):
return tokenizer(
sample["text"],
padding=False,
max_length=MAX_SEQUENCE_LENGTH,
truncation=True,
add_special_tokens=False,
)
ds = ds.map(tokenize, remove_columns=ds.column_names)
# 量子化のRecipeを定義(NVFP4)
recipe = QuantizationModifier(targets="Linear", scheme="NVFP4", ignore=["lm_head"])
# 量子化を実行
oneshot(
model=model,
tokenizer=tokenizer,
dataset=ds,
recipe=recipe,
max_seq_length=MAX_SEQUENCE_LENGTH,
num_calibration_samples=NUM_CALIBRATION_SAMPLES,
)
print("\n\n")
print("========== SAMPLE GENERATION ==============")
dispatch_for_generation(model)
input_ids = tokenizer("こんにちは、私の名前は", return_tensors="pt").input_ids.to("cuda")
output = model.generate(input_ids, max_new_tokens=100)
print(tokenizer.decode(output[0]))
print("==========================================\n\n")
# compressed-tensors形式で保存
SAVE_DIR = MODEL_ID.rstrip("/").split("/")[-1] + "-NVFP4"
model.save_pretrained(SAVE_DIR, save_compressed=True)
tokenizer.save_pretrained(SAVE_DIR)
- モデルのアップロード
モデルをHFにアップロードしておきます。huggingface-cli upload-large-folder Aratako/NemoAurora-RP-12B-NVFP4 ./NemoAurora-RP-12B-NVFP4 --repo-type model
これで完了です。非常に簡単に量子化を行うことができました。こちらが実際に量子化されたモデルです。
出来上がったモデルはsafetensorsを拡張したcompressed-tensorsという形式で保存されています。
量子化モデルのconfig.jsonを見ると以下のようなquantization_configが追加されています。
"quantization_config": {
"config_groups": {
"group_0": {
"input_activations": {
"actorder": null,
"block_structure": null,
"dynamic": "local",
"group_size": 16,
"num_bits": 4,
"observer": "minmax",
"observer_kwargs": {},
"strategy": "tensor_group",
"symmetric": true,
"type": "float"
},
"output_activations": null,
"targets": [
"Linear"
],
"weights": {
"actorder": null,
"block_structure": null,
"dynamic": false,
"group_size": 16,
"num_bits": 4,
"observer": "minmax",
"observer_kwargs": {},
"strategy": "tensor_group",
"symmetric": true,
"type": "float"
}
}
},
"format": "nvfp4-pack-quantized",
"global_compression_ratio": null,
"ignore": [
"lm_head"
],
"kv_cache_scheme": null,
"quant_method": "compressed-tensors",
"quantization_status": "compressed"
}
推論
NVFP4に量子化したモデルを実際に推論してみます。今回推論にはDeepInfraでB200をレンタルして環境をセットアップして使います。使った環境は以下の通りです。
- OS: Ubuntu 22.04
- CUDA: 12.8
- Torch: 2.7.0+cu128
- vLLM: 0.9.2
vLLMは以下のコマンドでインストールしています。
pip install vllm --extra-index-url https://download.pytorch.org/whl/cu128
では、実際に推論を試してみましょう。まずはvLLMで推論サーバを起動します。
vllm serve Aratako/NemoAurora-RP-12B-NVFP4 --max-model-len 8192
数分待つとサーバが立ち上がると思います。以下のようにcurlでリクエストを投げてみます。
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Aratako/NemoAurora-RP-12B-NVFP4",
"messages": [
{"role": "user", "content": "こんにちは"}
]
}'
無事レスポンスが返ってきました。
{"id":"chatcmpl-72b68a47e2fd40008a113eecb1d01bb0","object":"chat.completion","created":1752242949,"model":"Aratako/NemoAurora-RP-12B-NVFP4","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"こんばんは!\n今日はどんな相談ですか?","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":11,"total_tokens":24,"completion_tokens":13,"prompt_tokens_details":null},"prompt_logprobs":null,"kv_transfer_params":null}
FP8との比較
せっかくなので、FP8に量子化した同じモデルと速度や精度の比較をしてみます。比較対象として以下のFP8量子化モデルを用意しました。
FP8への量子化はNVFP4量子化に利用したスクリプトのscheme="NVFP4"部分をscheme="FP8"に変えることで簡単に行うことができます。対応しているscheme一覧はこちらにあります。
速度比較
FP8とNVFP4の各モデルで処理速度の比較をしてみます。今回、ベンチマークの実行にはvLLMが公式に提供しているベンチマークスクリプトを利用しました。あらかじめvLLMのリポジトリをクローンしておきます。
git clone https://github.com/vllm-project/vllm.git
1. ShareGPTデータセットでのベンチマーク
まずはvLLMのexampleにあるShareGPTデータセットでのベンチマークを行ってみます。実行手順は以下の通りです。
- ベンチマーク用データのダウンロード
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json - 推論サーバの起動
vllm serve Aratako/NemoAurora-RP-12B-NVFP4 --max-model-len 8192 --disable-log-requests - ベンチマークスクリプトの実行
# 例:max-concurrency=4 の場合 python vllm/benchmarks/benchmark_serving.py --backend vllm --model Aratako/NemoAurora-RP-12B-NVFP4 --endpoint /v1/completions --dataset-name sharegpt --dataset-path ./ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 1000 --max-concurrency 4 --save-result
今回はmax-concurrencyを1から1024まで変化させながら、NVFP4とFP8でThroughputやTPOT、TTFTを計測してみました。各指標は以下のようなものです。
- Output Throughput: 1秒間で生成された出力トークン数。ある測定区間で生成されたトークン数を経過時間で割ることで求められる指標で、大きい方が良い。
- TPOT(Time Per Output Token): 下記のTTFTを除いた1トークン出力の間にかかる時間。Inter-Token Latency(ITL)とも呼ばれる。ストリーミングで出力が流れてくる際のそのストリーミング速度のような指標で、小さい方が良い。
- TTFT(Time To First Token): 最初のトークンの生成までにかかった時間。ユーザの入力に対するレイテンシのような指標で、小さい方が良い。
測定結果は以下の通りです。

ShareGPTデータセットでのThroughput
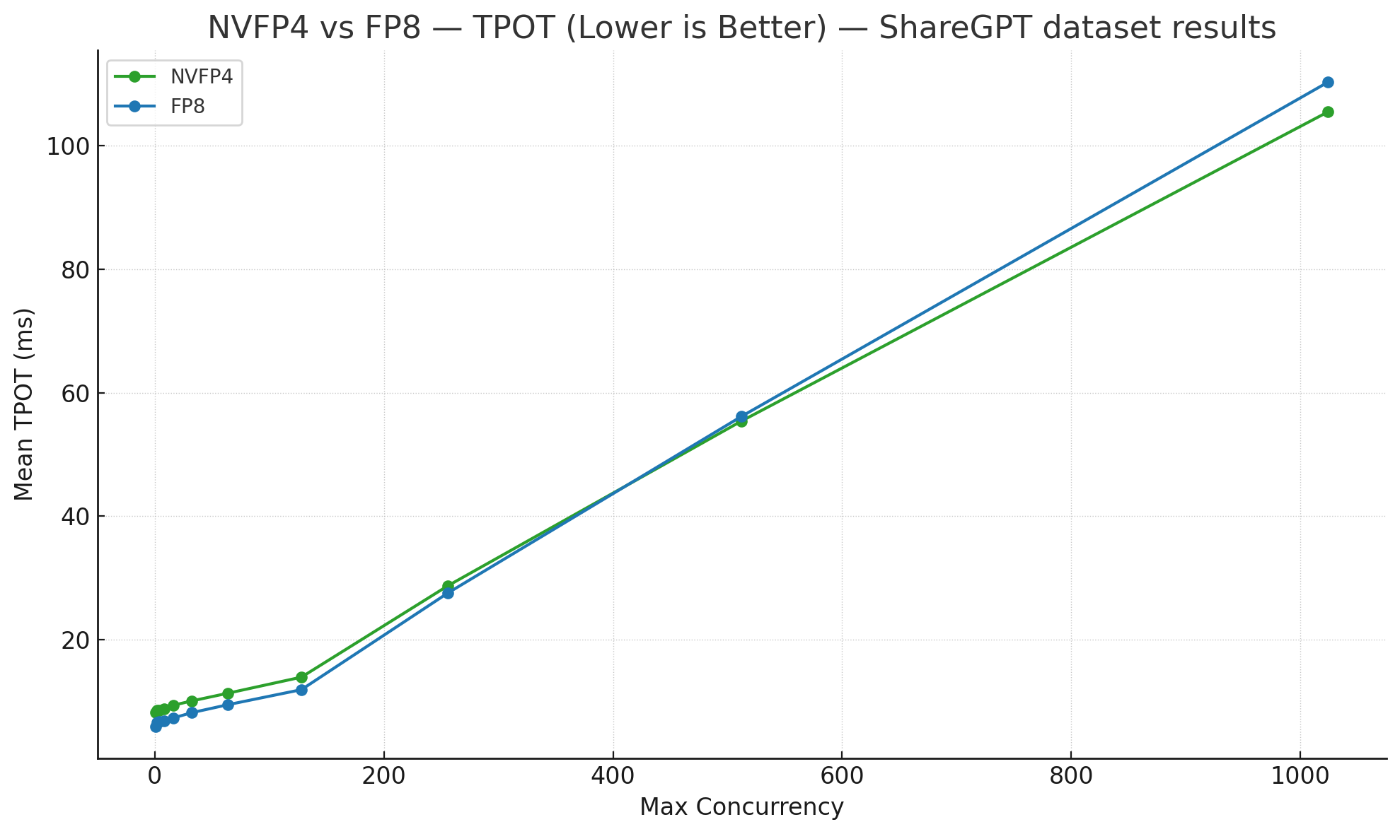
ShareGPTデータセットでのTPOT
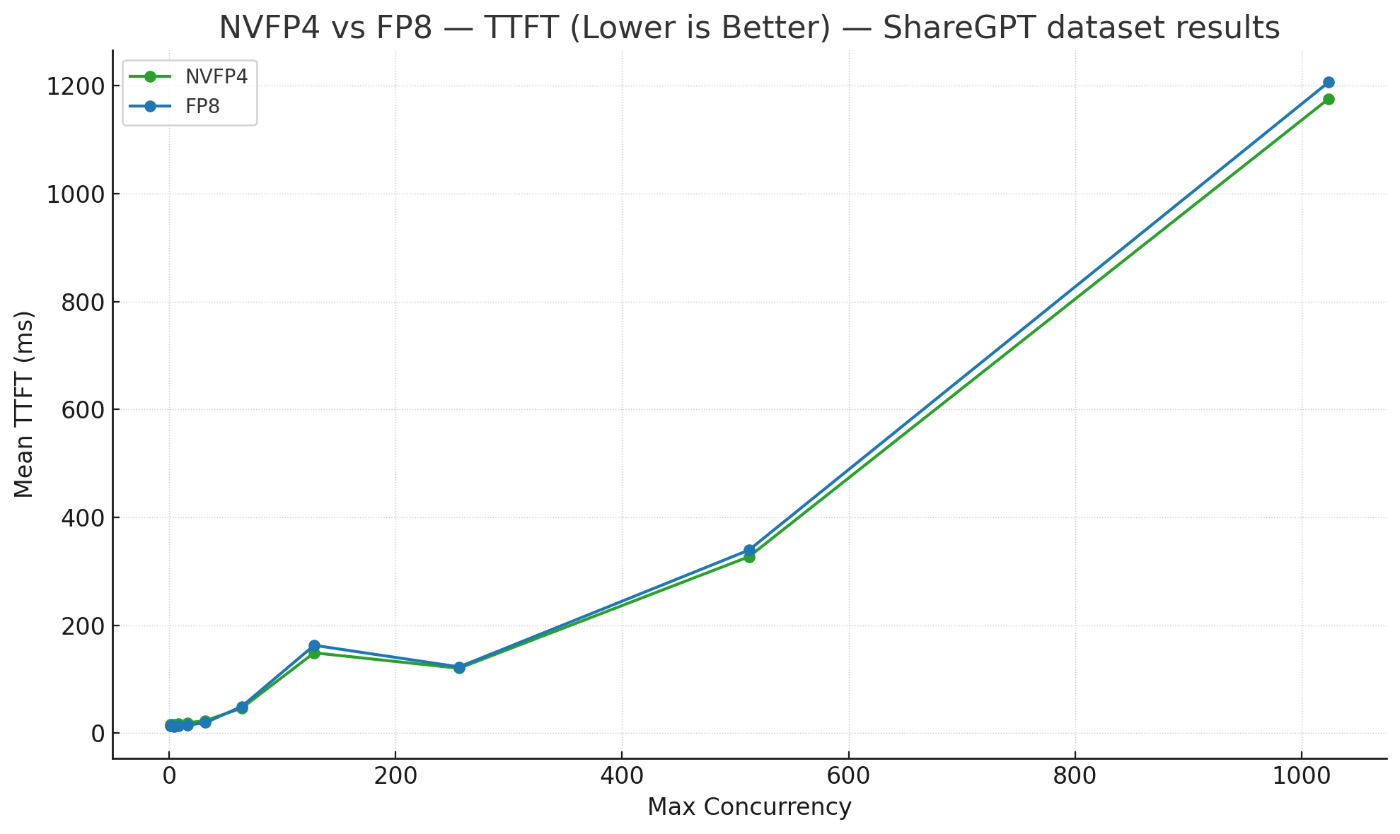
ShareGPTデータセットでのTTFT
2. LongAlign-10kデータセットでのベンチマーク
入力プロンプトが長いデータセットとして、THUDM/LongAlign-10kというデータセットでもベンチマークを行ってみました。ベンチマークスクリプトをやや改変し、messages列のuser roleのプロンプトだけ抽出して利用しています。先頭200件を利用し、入力トークン長の平均は約16000トークンでした。
ベンチマークの際には以下のようにmax_model_lenを長めにとり、prefix cachingを無効にしています。
vllm serve Aratako/NemoAurora-RP-12B-NVFP4 --max-model-len 65536 --disable-log-requests --no-enable-prefix-caching
結果は以下の通りです。

LongAlign-10kデータセットでのThroughput

LongAlign-10kデータセットでのTPOT

LongAlign-10kデータセットでのTTFT
3. Prefill Heavyな条件でのベンチマーク
よりPrefill Heavyな条件でのベンチマークも試してみます。今回はvLLMのベンチマークスクリプトにあるbenchmark_long_document_qa_throughput.pyを利用しました。これは長いプロンプトのバッチ処理時の推論速度を計測するスクリプトです。
スクリプトを少し改変し、指定した条件で3回バッチ推論した平均処理速度を出力するようにして、Long ContextでLarge Batchな条件での処理速度を確認してみました。実行コマンドは以下の通りです。
python vllm/benchmarks/benchmark_long_document_qa_throughput.py --model Aratako/NemoAurora-RP-12B-NVFP4 --num-documents 200 --document-length 20000 --max-model-len 32768 --output-len 10 --repeat-count 5 --no-enable-prefix-caching
処理速度は以下の通りになりました。
Long Contextなバッチ推論速度の比較
| FP8 | NVFP4 |
|---|---|
| 128.0757秒 | 116.5086秒 |
速度比較の結果
速度比較の結果、低負荷時にはFP8の方が早い傾向があり、Prefill-HeavyでLarge Batchな高負荷条件においてはNVFP4の方が優位に立つ傾向が見られました。
TensorRT-LLMでも同様にDecodeにおいてFP4がFP8より遅いという事例が報告されています。
これに関しては、NVFP4のカーネル最適化がFP8と比べて進んでいないことが大きな原因かなと思います。そもそもvLLMのBlackwell最適化もまだまだ途中なので、さらに最適化が進むとより多くの条件でNVFP4が優位に立つようになるかと思います。
また、そもそものモデルサイズをNVFP4の方がより小さくできるので、限られたVRAM容量の中でより大きなモデルをGPUに載せて推論できるというメリットも存在します。
精度比較
速度だけでなく精度も比較してみます。
今回は以下のようなスクリプトを用いて、学習に利用したデータセットのPPLをvLLMで測定してみました。
PPL測定スクリプト
import math
from datasets import load_dataset
from tqdm import tqdm
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# ---- vLLM 初期化 ------------------------------------------
llm = LLM(
model="Aratako/NemoAurora-RP-12B-NVFP4",
max_model_len=8192,
max_num_seqs=1000,
)
tokenizer = AutoTokenizer.from_pretrained("Aratako/NemoAurora-RP-12B-NVFP4")
sp = SamplingParams(
max_tokens=1,
temperature=0.0,
prompt_logprobs=0,
)
ds = load_dataset(
"Aratako/Synthetic-Japanese-Roleplay-NSFW-DeepSeek-V3-0324-20k-formatted",
split="train",
)
def format_messages(example):
return {
"text": tokenizer.apply_chat_template(
example["messages"],
tokenize=False,
)
}
ds = ds.map(format_messages, remove_columns=ds.column_names)
def coerce_logprob_to_num(logprob):
return getattr(logprob, "logprob", logprob)
total_nll = 0
total_num_tokens = 0
def process_batch(text_batch):
batch_nll = 0
batch_num_tokens = 0
results = llm.generate(text_batch, sampling_params=sp)
for result in results:
original_logprobs = result.prompt_logprobs
logprobs_dicts = [
(
{
token: coerce_logprob_to_num(logprob)
for token, logprob in logprobs_dict.items()
}
if logprobs_dict is not None
else None
)
for logprobs_dict in original_logprobs
]
tokens = getattr(result, "prompt_tokens", None)
if tokens is None:
tokens = result.prompt_token_ids
token_logprobs = []
for tok, lp_dict in zip(tokens[1:], logprobs_dicts[1:]):
if lp_dict is None:
continue
lp = lp_dict.get(tok, float("-inf"))
token_logprobs.append(lp)
if token_logprobs:
batch_nll -= sum(token_logprobs)
batch_num_tokens += len(token_logprobs)
return batch_nll, batch_num_tokens
batch = []
for idx, ex in enumerate(tqdm(ds, desc="Calculating loss")):
batch.append(ex["text"])
if len(batch) == 1000:
batch_nll, batch_num_tokens = process_batch(batch)
total_nll += batch_nll
total_num_tokens += batch_num_tokens
batch = []
if batch:
batch_nll, batch_num_tokens = process_batch(batch)
total_nll += batch_nll
total_num_tokens += batch_num_tokens
if total_num_tokens > 0:
avg_nll = total_nll / total_num_tokens
perplexity = math.exp(avg_nll)
print(f"\nDataset Average NLL: {avg_nll:.4f}")
print(f"Dataset Perplexity (PPL): {perplexity:.4f}")
else:
print("Could not calculate PPL, no tokens were processed.")
結果は以下の通りになりました。
PPL測定結果
| FP8 | NVFP4 |
|---|---|
| 6.8161 | 6.8946 |
なお、このPPL計算の処理はLarge Batchでの出力1トークンのgenerateなのでかなりのPrefill Heavyな計算になりますが、この処理はNVFP4の方が約20%~30%程高速でした。
精度比較の結果
精度比較においては、NVFP4はFP8に対してPPLが約1.15%ほど悪化していました。これの影響が実タスクで大きいか小さいかの判断のためには、下流タスクでより具体的なベンチマークを取るなどをする必要がありそうです。
まとめ
この記事では、LLMのNVFP4量子化と推論をB200で実際に試し、速度や精度を測定してみました。速度に関してはあまり大きなメリットは現状ないようでしたが、今後カーネルの最適化が進むとより速度的にも優位に立つことが多くなるかと思います。
Discussion