LLM向けデータ合成手法"Magpie"を応用して音声データセットを合成してみた
はじめに
この記事は、MagpieというLLM用のデータ合成手法をLLMベースのTTSモデルに応用し、合成音声データセットを作ってみたという記事です。
記事概要
最近、LlasaやOrpheus-TTSなど、LLMをベースとした自己回帰によるTTSモデルが増えてきています。これらのモデルはLLMベースであるため、LLMに適用可能な合成データ作成手法をある程度そのまま利用することができます。
今回、MagpieというLLM用のデータ合成手法をOrpheus-TTSに適用し、約12.5万件の合成音声データセットを作成・公開しました。データセットは以下で公開しています。
この記事では、このデータセットの作り方について概説します。
Magpieについて
MagpieはオープンなLLMを使ってゼロからInstruction Tuning用の指示・応答ペアの合成データセットを作成する手法です。
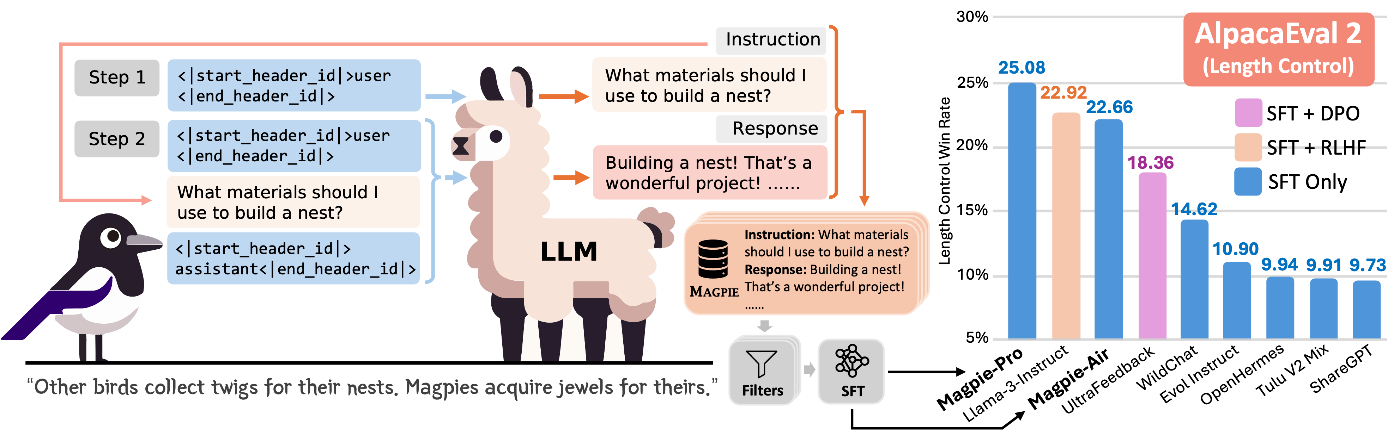
Magpieの概要図(公式GitHubより引用)
論文と公式実装は以下の通りです。
Magpieによるデータ合成は基本的に以下のような流れで行われます。
1. 指示プロンプトの合成
LLMを用いて指示プロンプトを合成します。一般的な合成データ作成手法では何らかのLLMにデータ作成を指示するようなプロンプトを与えることでInstruction Tuning用の指示プロンプトを作成しますが、Magpieはそういったことをせずに単体のLLMのみで完結した指示合成を実現します。
具体的には、Instruction TuningされたLLMのChat Templateにおいてユーザ入力(Instruction)が入る部分の直前までをプロンプトとして与えることで、モデルに自己回帰的にそこから続くInstruction部分を生成させます。
例えばLlama 3シリーズではプロンプトを投げるとき以下のようなChat Templateが用いられています。
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{user_prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{assistant_response}<|eot_id|>
この例では、本来user_promptの入る直前、すなわち、以下の部分をモデルに入力します(system_prompt部分は省略する場合もあり)。
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
すると、モデルはNext Token Predictionの予測の文脈でuser_promptに相当する部分を出力します。
基本的にInstruction Tuningはユーザ入力部分にloss maskをかけて行われるのですが、そのようなモデルに対してもこの手法がある程度有効であることが経験的に知られています。また、loss maskをかけずに学習されている一部のモデルに対してはこの手法は特に有効に働くようです。
2. 応答部分の合成
さきほど合成した指示をもとに、同じモデルで応答を合成します。これはシンプルに先ほどのInstructionを適切に加工してモデルに与えるだけです。
Llama 3の場合以下のような形式で与えます。ここのuser_promptは先ほど合成した指示プロンプトです。
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{user_prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
これにより、LLMは通常通り指示に対する応答を生成します。
Magpieによって合成される指示はその原理上元の学習データセットに近いと考えられます。そのためこの指示プロンプトはモデルにとってOODではなく学習済みの内容に近いものであると考えられ、それに伴いステップ2で生成される応答も他の手法で作った指示プロンプトを使って合成するものよりもより高品質なものになることが期待されます。
Magpieを音声データセットの合成に応用する
これまでの説明は普通のInstruction Tuning用テキストデータの合成の話でしたが、この記事ではこのMagpieを音声データセットの合成に利用してみます。
前提として、LlasaやOrpheusなどのLLMベースのTTSモデルは基本的に以下のような流れで学習されています。
- Text-Speechペアのデータセットを用意
- TextデータはLLMのTokenizerで通常通りトークン化
- Speech部分の音声データを何らかの音声コーデックによって離散トークン化
- これらを
Text Token - Audio Tokenのような形式に加工して学習し、入力テキストに対応する音声トークンを出力するようにする
この学習の流れにおいて、TTSモデルにおける入力テキストと出力音声トークンの関係は、通常のLLMにおける指示と応答の関係と同等です。
すなわち、LLMでのMagpieにおける指示と応答の合成と全く同じ流れで、読み上げさせたいテキストとそれに対応する音声トークンのペアを簡単に合成することができます。
特にOrpheus-TTSの場合、以下の公式の学習用データ処理のNotebookを見るとわかるように入力テキスト部分にloss maskをかけずに学習しています。そのため、Magpieが特に有効に働くことが期待できます。
以下にOrpheus-TTSにMagpieを適用する具体的な流れを示します。
1. 入力テキストの合成
LLMの場合における指示プロンプトの合成と全く同じです。テキストが入る直前までをプロンプトとして与え、モデルに続きを生成させてText部分を取得します。
Orpheus-TTSがどのような形式で学習されているかについては上述したNotebookを確認していただければと思います。Text入力直前までは以下のような形式なので、以下の2トークンのみをプロンプトとして与えます。
<custom_token_3><|begin_of_text|>
ここで<custom_token_3>はStart of Human、<|begin_of_text|>はStart of Textトークンに相当します。
今回は以下のようなシンプルなPythonスクリプトでvLLMを使って入力テキストの合成を行いました。
テキスト合成用スクリプト
import re
from collections import Counter
import torch
from datasets import Dataset
from tqdm import tqdm
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
TARGET_SIZE = 500000
BATCH_SIZE = 2000
ITER = TARGET_SIZE // BATCH_SIZE
orpheus_model_id = "canopylabs/orpheus-3b-0.1-pretrained"
RE_CHAR_RUN = re.compile(r"(.)\1{3,}")
RE_WORD_RUN = re.compile(r"\b(\w+)(?:\W+\1){2,}\b")
RE_CTRL = re.compile(r"[\x00-\x08\x0B\x0C\x0E-\x1F]")
def ends_like_sentence(s: str) -> bool:
s = s.rstrip()
return len(s) >= 2 and s[-1] in ".?!…。!?"
def ngram_stats(words, n=3):
if len(words) < n:
return 1.0, 0 # unique_ratio, max_count
grams = [" ".join(words[i : i + n]) for i in range(len(words) - n + 1)]
c = Counter(grams)
unique_ratio = len(c) / len(grams)
max_count = max(c.values())
return unique_ratio, max_count
def passes_text_filters(
text: str,
finish_reason: str,
min_chars=8,
max_chars=300,
min_words=3,
max_words=80,
min_unique3_ratio=0.6,
max_3gram_count=3,
):
# 1) stop
if finish_reason != "stop":
return False, "finish_reason"
# 2) trivial cleaning
s = text.strip()
if not (min_chars <= len(s) <= max_chars):
return False, "length_chars"
words = re.findall(r"\w+", s.lower())
if not (min_words <= len(words) <= max_words):
return False, "length_words"
# 3) control/special tokens
if RE_CTRL.search(s):
return False, "ctrl_char"
if "<" in s and ">" in s: # 雑に防御(必要なら厳密に)
return False, "special_token_like"
# 4) repetition
if RE_CHAR_RUN.search(s):
return False, "char_run"
if RE_WORD_RUN.search(s):
return False, "word_run"
uniq3, max3 = ngram_stats(words, n=3)
if uniq3 < min_unique3_ratio or max3 > max_3gram_count:
return False, "ngram_repetition"
# 5) completeness
if not ends_like_sentence(s):
return False, "incomplete_sentence"
return True, "ok"
SOT_ID = 128000 # Start of Text
EOT_ID = 128009 # End of Text
SOS_ID = 128257 # Start of Speech
EOS_ID = 128258 # End of Speech
SOH_ID = 128259 # Start of Human
EOH_ID = 128260 # End of Human
SOA_ID = 128261 # Start of AI
EOA_ID = 128262 # End of AI
SOT_TOKEN = "<|begin_of_text|>" # Start of Text (128000)
EOT_TOKEN = "<|eot_id|>" # End of Text (128009)
SOS_TOKEN = "<custom_token_1>" # Start of Speech (128257)
EOS_TOKEN = "<custom_token_2>" # End of Speech (128258)
SOH_TOKEN = "<custom_token_3>" # Start of Human (128259)
EOH_TOKEN = "<custom_token_4>" # End of Human (128260)
SOA_TOKEN = "<custom_token_5>" # Start of AI (128261)
EOA_TOKEN = "<custom_token_6>" # End of AI (128262)
tokenizer = AutoTokenizer.from_pretrained(orpheus_model_id)
model = LLM(
model=orpheus_model_id,
gpu_memory_utilization=0.9,
max_model_len=256,
max_num_seqs=BATCH_SIZE,
seed=42,
)
sampling_params = SamplingParams(
temperature=1.0,
top_p=0.9,
repetition_penalty=1.1,
min_p=0.01,
stop_token_ids=[EOT_ID, SOS_ID],
max_tokens=100,
)
INPUT_TEXT = SOH_TOKEN + SOT_TOKEN
prompts = [INPUT_TEXT for i in range(BATCH_SIZE)]
results = []
for _ in tqdm(range(ITER)):
outputs = model.generate(prompts, sampling_params)
for output in outputs:
generated_text = output.outputs[0].text
finish_reason = output.outputs[0].finish_reason
ok, reason = passes_text_filters(generated_text, finish_reason)
if ok:
results.append({"text": generated_text.strip()})
ds = Dataset.from_list(results)
ds.to_json("output_text.jsonl", orient="records", lines=True)
これにより、以下のような読み上げ対象のテキストデータが得られます。
[
{
"text": "No, I mean this is the question for you."
},
{
"text": "Is it for a show? You just do that? Yeah, I always tell you this story about my friend, uh, he used to be in radio and he did the whole gig."
},
{
"text": "That the first thing that's, uh, not quite ready yet is going to be this main class, and then you're gonna put the rest of the classes in."
}
]
2. 音声トークンの生成
ステップ1で合成したテキストをモデルに入力し、対応する音声トークンを生成します。
テキストをOrpheus-TTSの学習のフォーマットに従い、以下のように加工して入力することで、音声トークンを生成します。
<custom_token_3><|begin_of_text|>{input_text}<|eot_id|><custom_token_4><custom_token_5><custom_token_1>
ここで<custom_token_3>はStart of Human、<|begin_of_text|>はStart of Text、<|eot_id|>はEnd of Text、<custom_token_4>はEnd of Human、<custom_token_5>はStart of AI、<custom_token_1>はStart of Speechトークンに相当します。また、input_textはステップ1で合成したテキストです。
今回は以下のようなシンプルなPythonスクリプトでvLLMを使って音声トークンの生成を行いました。
音声トークン生成用スクリプト
import json
import os
from tqdm import tqdm
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
BATCH_SIZE = 200
orpheus_model_id = "canopylabs/orpheus-3b-0.1-pretrained"
SOT_ID = 128000 # Start of Text
EOT_ID = 128009 # End of Text
SOS_ID = 128257 # Start of Speech
EOS_ID = 128258 # End of Speech
SOH_ID = 128259 # Start of Human
EOH_ID = 128260 # End of Human
SOA_ID = 128261 # Start of AI
EOA_ID = 128262 # End of AI
SOT_TOKEN = "<|begin_of_text|>" # Start of Text (128000)
EOT_TOKEN = "<|eot_id|>" # End of Text (128009)
SOS_TOKEN = "<custom_token_1>" # Start of Speech (128257)
EOS_TOKEN = "<custom_token_2>" # End of Speech (128258)
SOH_TOKEN = "<custom_token_3>" # Start of Human (128259)
EOH_TOKEN = "<custom_token_4>" # End of Human (128260)
SOA_TOKEN = "<custom_token_5>" # Start of AI (128261)
EOA_TOKEN = "<custom_token_6>" # End of AI (128262)
tokenizer = AutoTokenizer.from_pretrained(orpheus_model_id)
model = LLM(
model=orpheus_model_id,
gpu_memory_utilization=0.95,
max_model_len=2816,
max_num_seqs=BATCH_SIZE,
max_num_batched_tokens=8192,
seed=42,
)
sampling_params = SamplingParams(
temperature=1.0,
top_p=0.9,
repetition_penalty=1.1,
min_p=0.01,
stop_token_ids=[EOS_ID, EOA_ID],
max_tokens=2560,
)
input_file = "./output_text.jsonl"
output_file = "./output_audio_tokens.jsonl"
processed_texts = set()
# 処理済みの行数をカウント
if os.path.exists(output_file):
print(f"既存の出力ファイル {output_file} をスキャンしています...")
try:
with open(output_file, "r", encoding="utf-8") as f:
# ファイルの行数をカウント
num_processed = sum(1 for _ in f)
except Exception as e:
print(f"エラー: 出力ファイルの読み込み中に問題が発生しました: {e}")
exit()
print(f"スキャン完了。{num_processed}件の処理済みデータを検出しました。")
else:
print(f"出力ファイル {output_file} が存在しません。新規作成します。")
num_processed = 0
# 入力ファイルを読み込む
print(f"入力ファイル {input_file} を読み込んでいます...")
all_data = []
try:
with open(input_file, "r", encoding="utf-8") as f:
for line in f:
all_data.append(json.loads(line))
except FileNotFoundError:
print(f"エラー: 入力ファイル {input_file} が見つかりません。")
exit()
print("読み込み完了。")
# インデックスを使って未処理のデータをスライスする
total_items = len(all_data)
if num_processed >= total_items:
print(f"すべてのデータ({total_items}件)は処理済みです。終了します。")
unprocessed_data = []
else:
print(f"合計{total_items}件中、{num_processed}件が処理済みです。")
# 処理済み件数番目から最後までをスライスして未処理データとする
unprocessed_data = all_data[num_processed:]
print(f"残り{len(unprocessed_data)}件の処理を開始します。")
# バッチ処理と逐次保存
if unprocessed_data:
# ファイルを追記モード('a')で開く
with open(output_file, "a", encoding="utf-8") as f_out:
for i in tqdm(range(0, len(unprocessed_data), BATCH_SIZE), desc="バッチ処理中"):
batch = unprocessed_data[i : min(i + BATCH_SIZE, len(unprocessed_data))]
prompts = []
for row in batch:
text = row["text"]
prompt = f"{SOH_TOKEN}{SOT_TOKEN}{text}{EOT_TOKEN}{EOH_TOKEN}{SOA_TOKEN}{SOS_TOKEN}"
prompts.append(prompt)
outputs = model.generate(prompts, sampling_params)
for item, output in zip(batch, outputs):
generated = output.outputs[0].text
finish_reason = output.outputs[0].finish_reason
result = {
"text": item["text"],
"audio_tokens": generated.strip(),
"finish_reason": finish_reason,
}
f_out.write(json.dumps(result, ensure_ascii=False) + "\n")
f_out.flush()
print("すべての処理が完了しました。")
これにより、以下のようなテキストと音声トークンのペアのデータセットが得られます。
[
{
"text": "No, I mean this is the question for you.",
"audio_tokens": "<custom_token_3987><custom_token_4137><custom_token_10650><custom_token_14034> ... <custom_token_21933><custom_token_27976>",
"finish_reason": "stop"
},
{
"text": "Is it for a show? You just do that? Yeah, I always tell you this story about my friend, uh, he used to be in radio and he did the whole gig.",
"audio_tokens": "<custom_token_2856><custom_token_7692><custom_token_9454><custom_token_13859> ... <custom_token_21094><custom_token_28110>",
"finish_reason": "stop"
},
{
"text": "That the first thing that's, uh, not quite ready yet is going to be this main class, and then you're gonna put the rest of the classes in.",
"audio_tokens": "<custom_token_1784><custom_token_5949><custom_token_10319><custom_token_16338> ... <custom_token_21392><custom_token_27976>",
"finish_reason": "stop"
}
]
3. 音声トークンから実際の音声データへの変換
ステップ2の生成結果はまだ単なる音声トークンなので、これを元に音声コーデックを使って実際の音声データへの変換を行います。Orpheus-TTSではhubertsiuzdak/snac_24khzを音声コーデックに採用しているので、これを使います。
以下のようなシンプルなスクリプトで前段の音声トークンから実音声を生成・保存します。
音声変換用スクリプト
import hashlib
import json
import math
import os
import re
import unicodedata
from typing import Iterator, List, Tuple
import soundfile as sf
import torch
from snac import SNAC
from tqdm import tqdm
from transformers import AutoTokenizer
JSONL_IN = "output_audio_tokens.jsonl"
AUDIO_DIR = "dataset/audio"
AUDIO_EXT = ".flac"
BIT_DEPTH = 16
META_OUT = "dataset/metadata.jsonl"
MODEL_ID = "canopylabs/orpheus-3b-0.1-pretrained"
SNAC_MODEL_ID = "hubertsiuzdak/snac_24khz"
SAMPLE_RATE = 24000
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
SUBTYPE = "PCM_24" if BIT_DEPTH == 24 else "PCM_16"
# OrpheusのSNACコードブック先頭ID(公式ノートブックの処理と同じ)
CODEBOOK_BASE = 128266
# 1フレームあたり7トークン(Orpheus既定)
TOKENS_PER_FRAME = 7
# 各サブコードブックの幅
CB_WIDTH = 4096
RE_CUSTOM = re.compile(r"<custom_token_\d+>")
snac_model = SNAC.from_pretrained(SNAC_MODEL_ID)
snac_model.to(DEVICE).eval()
def canonicalize_text(s: str) -> str:
# NFKC正規化 → 連続空白を1個に → 前後trim → 小文字化
s = unicodedata.normalize("NFKC", s)
s = re.sub(r"\s+", " ", s).strip()
return s.lower()
def text_hash_blake2s(s: str) -> str:
canon = canonicalize_text(s)
return hashlib.blake2s(canon.encode("utf-8"), digest_size=16).hexdigest() # 128-bit
def chars_per_second(s: str, duration_sec: float) -> Tuple[int, float]:
# 空白以外の可視文字数ベース
n_vis = len(re.findall(r"\S", s))
d = max(duration_sec, 1e-6)
return n_vis, n_vis / d
def iter_jsonl(path: str) -> Iterator[dict]:
with open(path, "r", encoding="utf-8") as f:
for line in f:
if not line.strip():
continue
yield json.loads(line)
def extract_custom_tokens(s: str) -> List[str]:
# 連結された <custom_token_xxx>... を1個ずつ抽出
return RE_CUSTOM.findall(s)
def tokens_to_ids(tok, toks: List[str]) -> List[int]:
ids = []
for t in toks:
i = tok.convert_tokens_to_ids(t)
if i is None or i == tok.unk_token_id:
raise ValueError(f"Unknown token in sequence: {t}")
ids.append(i)
return ids
def ids_to_layers(ids: List[int]) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Orpheus公式の変換に準拠:
- 7個で1フレーム
- (id - CODEBOOK_BASE) でコード域に変換
- 位置ごとに 4096 のオフセットを引いて [0,4095] に合わせる
- 出力は [1, T], [1, 2T], [1, 4T] の3テンソル
"""
if len(ids) < TOKENS_PER_FRAME:
raise ValueError("Too few tokens.")
# 余りは落として7の倍数の長さに
new_len = (len(ids) // TOKENS_PER_FRAME) * TOKENS_PER_FRAME
ids = ids[:new_len]
codes = [i - CODEBOOK_BASE for i in ids]
# 簡易チェック:負値があればマッピング違いの可能性
if any(c < 0 for c in codes):
bad = [c for c in codes if c < 0][:5]
raise ValueError(
f"Found negative codes after base subtraction (e.g., {bad}). "
f"Is CODEBOOK_BASE={CODEBOOK_BASE} correct for your model/tokenizer?"
)
L1, L2, L3 = [], [], []
T = len(codes) // TOKENS_PER_FRAME
for t in range(T):
x0 = codes[7 * t + 0]
x1 = codes[7 * t + 1] - 1 * CB_WIDTH
x2 = codes[7 * t + 2] - 2 * CB_WIDTH
x3 = codes[7 * t + 3] - 3 * CB_WIDTH
x4 = codes[7 * t + 4] - 4 * CB_WIDTH
x5 = codes[7 * t + 5] - 5 * CB_WIDTH
x6 = codes[7 * t + 6] - 6 * CB_WIDTH
# 各サブコードは [0, 4095] に入る想定
for val, name in [
(x0, "x0(L1)"),
(x1, "x1(L2)"),
(x2, "x2(L3)"),
(x3, "x3(L3)"),
(x4, "x4(L2)"),
(x5, "x5(L3)"),
(x6, "x6(L3)"),
]:
if not (0 <= val < CB_WIDTH):
raise ValueError(f"Subcode out of range: {name}={val} at frame {t}")
L1.append(x0)
L2.append(x1)
L3.append(x2)
L3.append(x3)
L2.append(x4)
L3.append(x5)
L3.append(x6)
t1 = torch.tensor(L1, dtype=torch.long, device=DEVICE).unsqueeze(0)
t2 = torch.tensor(L2, dtype=torch.long, device=DEVICE).unsqueeze(0)
t3 = torch.tensor(L3, dtype=torch.long, device=DEVICE).unsqueeze(0)
return t1, t2, t3
def decode_to_audio(
snac_model, layers: Tuple[torch.Tensor, torch.Tensor, torch.Tensor]
) -> torch.Tensor:
with torch.no_grad():
audio = snac_model.decode(list(layers))
if audio.dim() == 2 and audio.size(0) == 1:
return audio.squeeze(0)
return audio
def ensure_dir(path: str):
os.makedirs(path, exist_ok=True)
# ====== メイン処理 ======
def main():
tok = AutoTokenizer.from_pretrained(MODEL_ID)
ensure_dir(AUDIO_DIR)
ensure_dir(os.path.dirname(META_OUT))
meta_f = open(META_OUT, "w", encoding="utf-8")
n_ok = n_skip = 0
for idx, ex in enumerate(tqdm(iter_jsonl(JSONL_IN), desc="decoding")):
# finish_reason==stop のみ処理
fr = ex.get("finish_reason", "stop")
if fr != "stop":
n_skip += 1
continue
text = ex["text"]
audio_tok_str = ex["audio_tokens"]
try:
toks = extract_custom_tokens(audio_tok_str)
if len(toks) == 0:
raise ValueError("No <custom_token_*> found.")
ids = tokens_to_ids(tok, toks)
t1, t2, t3 = ids_to_layers(ids)
with torch.no_grad():
audio = snac_model.decode([t1, t2, t3]).squeeze(0).to("cpu")
# 音声ファイルの保存
fname = f"{idx:09d}{AUDIO_EXT}"
audio_path = os.path.join(AUDIO_DIR, fname)
sf.write(
audio_path, audio.numpy().T, SAMPLE_RATE, format="FLAC", subtype=SUBTYPE
)
# メタデータの保存
duration = audio.numpy().shape[-1] / SAMPLE_RATE
num_chars, cps = chars_per_second(text, duration)
item = {
"id": f"{idx:09d}",
"text": text,
"text_hash": text_hash_blake2s(text),
"audio_path": audio_path,
"n_audio_tokens": len(ids),
"frames": len(ids) // TOKENS_PER_FRAME,
"sr": SAMPLE_RATE,
"duration_sec": round(duration, 3),
"num_chars": num_chars,
"cps": round(cps, 3),
}
meta_f.write(json.dumps(item, ensure_ascii=False) + "\n")
n_ok += 1
except Exception as e:
print(f"[skip #{idx}] {e}")
n_skip += 1
continue
meta_f.close()
print(f"done. ok={n_ok}, skip={n_skip}")
if __name__ == "__main__":
main()
4. 各種フィルタリングなど
必要に応じて出来上がった音声データに各種フィルタリングを行います。今回のデータにおいては以下の6つのフィルタリングを行っております。
- テキストハッシュをもとに完全一致で重複除去
- CPS(Characters Per Second、1秒あたりの文字数)の上位10%と下位10%のデータを除外
-
openai/whisper-large-v3を使って生成音声を文字起こしし、元テキストとのWER(Word Error Rate: 単語誤り率)、CER(Character Error Rate: 文字誤り率)を計算して
WER <= 0.15 & CER <= 0.05を満たすデータのみを抽出 - クリッピング率によるフィルタリング(
abs(x) >= 0.999の割合が0.05%を超えるデータを除外) - DCオフセット(音声波形の中心のズレ)によるフィルタリング(
abs(mean(x)) > 3e-4のデータを除外) - DNSMOSによって音声をスコアリング、下位15%を除去
これは一例なので、その他必要なフィルタリングがあれば適宜行ってください。
最終的なデータセットとして以下のものが完成しました。
まとめ
この記事ではMagpieというLLM用のデータ合成手法をLLMベースのTTSモデルに応用し、合成音声データセットを作ってみました。
このデータセットが実用的かどうかは未検証なので不明ですが、LLMのアプローチで音声データセットを作れるということは面白いと思います。他のLLMベースのアプローチを適用することで、より多様なデータセットを作ることができると思います。
Discussion