LLMの日本語ロールプレイ能力を計測するベンチマーク「Japanese-RP-Bench」の概要と評価結果などのまとめ
はじめに
LLMのマルチターン対話における日本語ロールプレイ能力を計測するベンチマーク「Japanese-RP-Bench」を構築し、以下のリポジトリにて公開しました。
本記事では、構築に至った経緯やベンチマークの概要、評価結果などをまとめます。ベンチマークの実行方法についてはリポジトリをご確認ください。
また、結果だけを見たい方は結果のセクションをご覧ください。
概要
構築に至った背景
今回、以下のような背景・考えからこのベンチマークの構築に至りました。
- LLMのロールプレイ的な用途での需要は比較的高いが、このタスクでの性能を計測するようなベンチマークが現状日本語では存在しない
- Japanese MT-BenchにはRoleplayのカテゴリが存在するが、大したロールプレイにはなっていない
- ロールプレイタスクに限らず、「対話の楽しさ」のような抽象的なものを測ろうとするオープンなLLMベンチマークが存在しない
- 現在主に利用されている日本語のベンチマークはシングルターンのみ、あるいは2ターンまでであり、ロングターンの対話性能を測るメジャーなベンチマークが存在しない。その結果、ロングターンの対話になると出力が崩壊するオープンモデルが多い
こういった背景から、ロングターンの対話におけるLLMの日本語ロールプレイ能力を計測するベンチマークが欲しいと考え、構築に至りました。
システム概要
今回構築したベンチマークのシステム概要は下図のようなものになります。
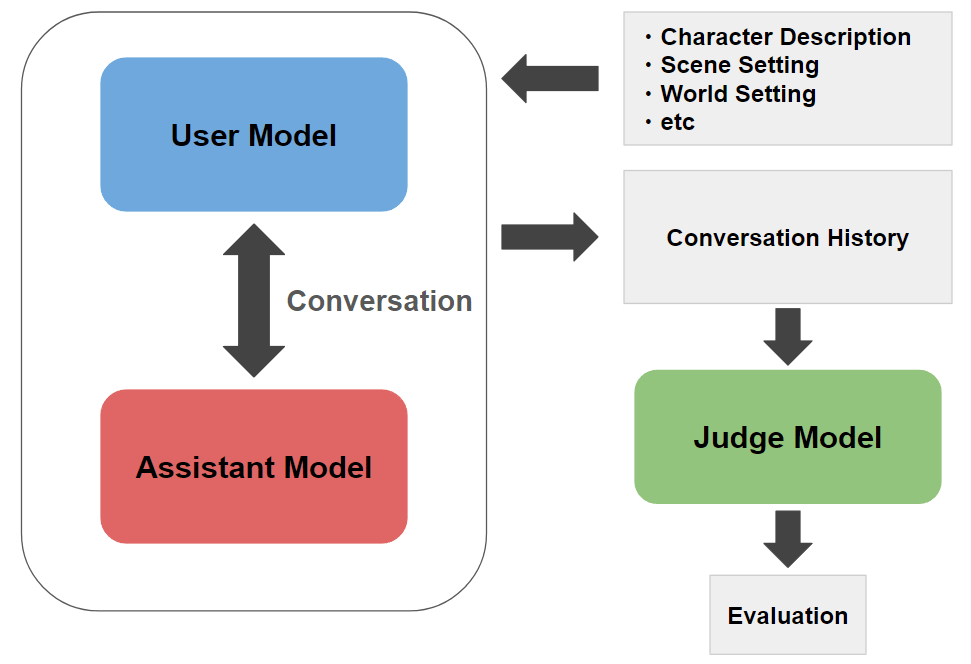
具体的には、以下のようなステップを踏むベンチマークです。
- ロールプレイの設定(キャラクター、世界観、シーンの設定など)が記載されたテスト用データセットをロードし、ユーザー側モデル用・アシスタント側モデル用のシステムプロンプトを構築
- ユーザー役を行うモデルとアシスタント役を行うモデルの2つのモデルを用意し、構築したシステムプロンプトを元にこの2つのモデル間でロールプレイ対話を複数ターン分実行
- ロールプレイの設定と出来上がった対話を元に、別の評価用モデルでアシスタントの応答の品質を評価
先行事例
同じようなタスク向けのベンチマークとして、PingPong benchmarkというベンチマークが英語圏に存在します。
今回こちらの先行事例の存在を知ったのは大部分の構築を終えた後でしたが、基本的なシステムは本ベンチマークと同じになっています。
今回の構築においては、主に評価部分を参考にさせていただきました。
評価用データ
今回のベンチマークでは以下のデータセットを評価用データとして利用しました。世界観やシーン、キャラクターなどの設定がまとまっている30件のデータセットです。この評価用データセットはClaude 3.5 Sonnetを用いて合成しました。
設定ファイルを書き換えることで、必要なキーを持っていれば別のデータセットを評価データとすることも出来ます。
評価観点
今回は以下のような評価観点を元に評価をしています。
- Roleplay Adherence: アシスタントがロールプレイ設定を厳守し、一貫して1人のキャラクターとして応答しているかどうか。また、ユーザー側の発言や行動を描写せず、ロールプレイ設定で指定された会話形式を守れているかどうか。
- Consistency: アシスタントがキャラクター設定に一貫して従い、対話全体に矛盾がないか。会話中に変化があっても、キャラクターの本質的部分を維持できているかどうか。
- Contextual Understanding: アシスタントが過去の発言や会話の文脈を正しく理解して応答をしているかどうか。設定にある情報を単に繰り返すのではなく新しい情報や提案を行い、それを巧みに取り入れて自然で深い応答を形成しているかどうか。
- Expressiveness: アシスタントがキャラクターの台詞、感情、トーンなどを豊かに表現しているかどうか。シーンに応じて適切に表現を変化させているか。また、単純な喜怒哀楽だけでなく、複雑で微妙な感情の変化も深く描写できているかどうか。
- Creativity: アシスタントの応答が独創的で機械的でないかどうか。単調な応答ではなく、興味深く魅力的な会話を展開できているか。また、ユーザーとのやり取りで意外な視点やアイデアを提供できているかどうか。
- Naturalness of Japanese: アシスタントの応答が自然な日本語で書かれているかどうか。不自然な言い回し、機械的な表現、他の言語の混入がないか。文法や語彙の選択が適切で、スムーズで読みやすい文章かどうか。また、同じフレーズや表現の繰り返しを避けているかどうか。
- Enjoyment of the Dialogue: 客観的に見て、アシスタントの応答が楽しい会話を生み出しているかどうか。ユーモアや機知に富んだ、魅力的な会話体験をユーザーに提供できているか。
また、評価プロンプトに以下のような工夫を取り入れ評価精度向上を狙っています。
- 各スコアの評価値のスケールにそれぞれ具体的な説明を付与
- 評価スコアを出力する前に評価理由を出力させる(CoT的な精度向上の狙い)
実際に使われている評価プロンプトはこちらをご確認ください。
ユーザー役モデルの選定
本ベンチマークでは評価対象となるモデルにアシスタント側の応答を生成させてその出力を評価しますが、それとは別に対話を展開するユーザー役モデルも必要となります。
ユーザー役モデルは単にロールプレイをするだけでなく、それと同時に場面転換や話題転換を駆使し、対話を上手く展開するというタスクも行わなければなりません。
このユーザー役モデルについて複数モデルで試行した結果、上手く対話を展開出来るものがClaude 3.5 Sonnetしか現状存在しないことが分かりました。具体的には、gpt-4o等のモデルに行わせても上手く展開できず、以下のような状況に陥ることが多いと分かりました。
- 場面転換が上手く出来ない。例えばどこかに出発するという対話の流れになった時に出発後の場面に話を転換できず、「さぁ、出発しましょう!」「はい、共に行きましょう!」「さぁ、出発しましょう!」「ええ、一緒に向かいましょう!」といった同じような対話の繰り返しに陥ってしまう。
- ロールプレイを早い段階で終了しようとする。5ターン程度対話が続いた後、「ロールプレイを終了します。お疲れさまでした」等の出力をし始め、対話を終了しようとしてしまう事が多い。
そのため、今回はユーザー役モデルとしてanthropic.claude-3-5-sonnet-20240620-v1:0を選定しました。設定ファイルから変更することも出来ますが、基本的に非推奨となっています。
評価モデルの選定
対話を評価するモデルについて、今回のベンチマークでは最終的に以下4モデルの平均を採用しました。
gpt-4o-2024-08-06o1-mini-2024-09-12anthropic.claude-3-5-sonnet-20240620-v1:0gemini-1.5-pro-002
先行事例のPingPong benchでは複数モデルの評価を統合したほうが人手評価との相関が強くなることが報告されており、これを参考に複数モデルの平均を採用しました。評価の妥当性の検証の項目で後述していますが、今回のベンチマークでも4つの評価モデルの平均が最も人手評価との相関が強いことを確認できています。
結果
評価結果
以下の条件で本ベンチマークを実行した結果です。
- ユーザー側のモデルには
anthropic.claude-3-5-sonnet-20240620-v1:0を利用 - 評価には
gpt-4o-2024-08-06、o1-mini-2024-09-12、anthropic.claude-3-5-sonnet-20240620-v1:0、gemini-1.5-pro-002の4モデルによる評価値の平均を採用 - 対話のターン数は10ターンまで
| target_model_name | Overall Average | Roleplay Adherence | Consistency | Contextual Understanding | Expressiveness | Creativity | Naturalness of Japanese | Enjoyment of the Dialogue | Appropriateness of Turn-Taking |
|---|---|---|---|---|---|---|---|---|---|
| claude-3-opus-20240229 | 4.403 | 4.6 | 4.792 | 4.625 | 4.092 | 3.833 | 4.8 | 4.083 | 4.4 |
| claude-3-5-sonnet-20240620 | 4.397 | 4.592 | 4.708 | 4.617 | 4.025 | 3.967 | 4.742 | 4.117 | 4.408 |
| gpt-4o-mini-2024-07-18 | 4.324 | 4.692 | 4.708 | 4.575 | 3.883 | 3.642 | 4.717 | 3.85 | 4.525 |
| gemini-1.5-pro-002 | 4.268 | 4.633 | 4.683 | 4.467 | 3.858 | 3.658 | 4.658 | 3.817 | 4.367 |
| cyberagent/Mistral-Nemo-Japanese-Instruct-2408 | 4.266 | 4.508 | 4.642 | 4.533 | 3.85 | 3.658 | 4.675 | 3.892 | 4.367 |
| gpt-4o-2024-08-06 | 4.242 | 4.617 | 4.642 | 4.5 | 3.75 | 3.542 | 4.708 | 3.75 | 4.425 |
| command-r-plus-08-2024 | 4.216 | 4.617 | 4.633 | 4.425 | 3.708 | 3.55 | 4.65 | 3.733 | 4.408 |
| *Qwen/Qwen2.5-72B-Instruct | 4.206 | 4.658 | 4.65 | 4.458 | 3.725 | 3.533 | 4.608 | 3.692 | 4.325 |
| gemini-1.5-pro | 4.203 | 4.475 | 4.6 | 4.425 | 3.775 | 3.558 | 4.65 | 3.725 | 4.417 |
| o1-preview-2024-09-12 | 4.179 | 4.625 | 4.65 | 4.383 | 3.642 | 3.417 | 4.6 | 3.617 | 4.5 |
| gemini-1.5-flash-002 | 4.162 | 4.675 | 4.633 | 4.333 | 3.683 | 3.4 | 4.542 | 3.633 | 4.4 |
| claude-3-haiku-20240307 | 4.15 | 4.35 | 4.608 | 4.358 | 3.8 | 3.483 | 4.608 | 3.708 | 4.283 |
| Qwen/Qwen2.5-32B-Instruct | 4.132 | 4.525 | 4.617 | 4.408 | 3.65 | 3.45 | 4.508 | 3.533 | 4.367 |
| o1-mini-2024-09-12 | 4.117 | 4.675 | 4.6 | 4.367 | 3.475 | 3.392 | 4.583 | 3.525 | 4.317 |
| mistral-large-2407 | 4.114 | 4.642 | 4.617 | 4.367 | 3.525 | 3.325 | 4.55 | 3.558 | 4.325 |
| cyberagent/calm3-22b-chat | 4.085 | 4.4 | 4.583 | 4.35 | 3.583 | 3.475 | 4.55 | 3.6 | 4.142 |
| *google/gemma-2-27b-it | 4.06 | 4.442 | 4.575 | 4.275 | 3.567 | 3.392 | 4.542 | 3.542 | 4.142 |
| cyberagent/Llama-3.1-70B-Japanese-Instruct-2407 | 4.052 | 4.283 | 4.583 | 4.3 | 3.625 | 3.45 | 4.425 | 3.6 | 4.15 |
| Aratako/calm3-22b-RP-v2 | 4.045 | 4.358 | 4.55 | 4.225 | 3.6 | 3.342 | 4.517 | 3.592 | 4.175 |
| command-r-08-2024 | 4.038 | 4.4 | 4.567 | 4.258 | 3.55 | 3.308 | 4.508 | 3.567 | 4.15 |
| *meta-llama/Meta-Llama-3.1-405B-Instruct | 3.975 | 4.408 | 4.5 | 4.258 | 3.483 | 3.25 | 4.367 | 3.442 | 4.092 |
| gemini-1.5-flash | 3.88 | 4.467 | 4.467 | 4.075 | 3.4 | 3.192 | 4.183 | 3.325 | 3.933 |
| deepseek-chat | 3.794 | 4.308 | 4.383 | 4.008 | 3.308 | 2.992 | 4.333 | 3.15 | 3.867 |
| mistralai/Mistral-Small-Instruct-2409 | 3.749 | 4.225 | 4.35 | 3.967 | 3.258 | 2.942 | 4.083 | 3.192 | 3.975 |
| weblab-GENIAC/Tanuki-8B-dpo-v1.0 | 3.695 | 3.817 | 4.1 | 3.983 | 3.317 | 3.233 | 4.183 | 3.308 | 3.617 |
| nitky/Oumuamua-7b-instruct-v2 | 3.686 | 3.742 | 4.242 | 3.958 | 3.325 | 3.067 | 4.15 | 3.275 | 3.733 |
| elyza/Llama-3-ELYZA-JP-8B | 3.673 | 4.2 | 4.408 | 3.817 | 3.067 | 2.858 | 4.217 | 3.108 | 3.708 |
| Qwen/Qwen2.5-7B-Instruct | 3.661 | 3.867 | 4.175 | 3.975 | 3.275 | 3.008 | 3.983 | 3.2 | 3.808 |
| *mistralai/Mistral-Nemo-Instruct-2407 | 3.535 | 3.808 | 4.058 | 3.842 | 3.175 | 3.042 | 3.433 | 3.133 | 3.792 |
| *meta-llama/Meta-Llama-3.1-70B-Instruct | 3.517 | 4.117 | 4.208 | 3.675 | 2.975 | 2.708 | 3.958 | 2.892 | 3.6 |
| tokyotech-llm/Llama-3-Swallow-8B-Instruct-v0.1 | 3.271 | 3.8 | 4.008 | 3.4 | 2.717 | 2.483 | 3.708 | 2.642 | 3.408 |
| *meta-llama/Meta-Llama-3.1-8B-Instruct | 2.986 | 3.475 | 3.775 | 3.042 | 2.533 | 2.25 | 3.4 | 2.442 | 2.967 |
*DeepInfraのAPIを利用しているため、内部で量子化されている可能性あり
評価の妥当性の検証
本ベンチマークではLLMによる自動評価をスコアとして利用していますが、この評価がそもそも妥当なものなのかを検証する必要があります。
今回はランダムにピックアップした50件の対話データを元に私が人手評価*をし、その評価結果とLLMによる評価結果の相関を検証しました。
*本来は信頼できる第三者を用意して検証するべきですが、個人開発なのでお許しください。
人手評価とLLM評価間のスピアマン順位相関係数を算出し一覧にしたものが以下になります。表中の列名であるOverallは4モデルの評価値の平均、それ以外は列名のモデルの評価値の平均を示しています。
| Overall | gpt-4o-2024-08-06 | o1-mini-2024-09-12 | anthropic.claude-3-5-sonnet-20240620-v1:0 | gemini-1.5-pro-002 | gpt-4o-2024-08-06_o1-mini-2024-09-12 | gpt-4o-2024-08-06_anthropic.claude-3-5-sonnet-20240620-v1:0 | gpt-4o-2024-08-06_gemini-1.5-pro-002 | o1-mini-2024-09-12_anthropic.claude-3-5-sonnet-20240620-v1:0 | o1-mini-2024-09-12_gemini-1.5-pro-002 | anthropic.claude-3-5-sonnet-20240620-v1:0_gemini-1.5-pro-002 | gpt-4o-2024-08-06_o1-mini-2024-09-12_anthropic.claude-3-5-sonnet-20240620-v1:0 | gpt-4o-2024-08-06_o1-mini-2024-09-12_gemini-1.5-pro-002 | gpt-4o-2024-08-06_anthropic.claude-3-5-sonnet-20240620-v1:0_gemini-1.5-pro-002 | o1-mini-2024-09-12_anthropic.claude-3-5-sonnet-20240620-v1:0_gemini-1.5-pro-002 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Roleplay Adherence | 0.632 | 0.473 | 0.46 | 0.29 | 0.54 | 0.604 | 0.392 | 0.619 | 0.479 | 0.63 | 0.464 | 0.579 | 0.684 | 0.522 | 0.578 |
| Consistency | 0.52 | 0.576 | 0.501 | 0.195 | 0.446 | 0.641 | 0.412 | 0.566 | 0.406 | 0.491 | 0.287 | 0.554 | 0.613 | 0.435 | 0.39 |
| Contextual Understanding | 0.526 | 0.416 | 0.525 | 0.309 | 0.484 | 0.556 | 0.393 | 0.498 | 0.459 | 0.563 | 0.403 | 0.507 | 0.586 | 0.45 | 0.496 |
| Expressiveness | 0.56 | 0.391 | 0.477 | 0.42 | 0.47 | 0.519 | 0.494 | 0.503 | 0.5 | 0.517 | 0.474 | 0.55 | 0.555 | 0.521 | 0.521 |
| Creativity | 0.43 | 0.347 | 0.294 | 0.396 | 0.462 | 0.374 | 0.42 | 0.427 | 0.386 | 0.384 | 0.422 | 0.406 | 0.408 | 0.442 | 0.401 |
| Naturalness of Japanese | 0.555 | 0.484 | 0.566 | 0.386 | 0.548 | 0.56 | 0.494 | 0.545 | 0.51 | 0.564 | 0.515 | 0.541 | 0.566 | 0.545 | 0.544 |
| Enjoyment of the Dialogue | 0.504 | 0.2 | 0.438 | 0.481 | 0.443 | 0.399 | 0.437 | 0.376 | 0.525 | 0.475 | 0.498 | 0.507 | 0.442 | 0.463 | 0.524 |
| Appropriateness of Turn-Taking | 0.617 | 0.531 | 0.288 | 0.488 | 0.361 | 0.485 | 0.604 | 0.573 | 0.45 | 0.384 | 0.491 | 0.577 | 0.564 | 0.635 | 0.482 |
| Average Score | 0.601 | 0.426 | 0.463 | 0.427 | 0.554 | 0.547 | 0.507 | 0.564 | 0.503 | 0.56 | 0.517 | 0.567 | 0.599 | 0.554 | 0.549 |
独創性や対話の面白さなど非常に抽象的な観点が評価に含まれており難易度の高い評価タスクではありますが、それでも人手評価との一定の相関を確認できています。
また、先行事例のPingPong benchmarkの例と同様に、複数モデルの評価の平均を取った方が人手評価との相関が強くなるという結果になりました。
考察・今後の改善点
評価観点の項目数について
現在のベンチマークでは、評価観点で説明した通り8つの項目を評価していますが、項目数が多すぎる可能性があります。
実際、先行事例のPingPong benchmarkでは評価項目をStay in character score、Language fluency score、Entertain scoreの3つにしています。
評価項目の妥当性について確認するため、全データの各指標のスコア間の相関係数を出してみたものが以下の表になります。
| Roleplay Adherence | Consistency | Contextual Understanding | Expressiveness | Creativity | Naturalness of Japanese | Enjoyment of the Dialogue | Appropriateness of Turn-Taking | |
|---|---|---|---|---|---|---|---|---|
| Roleplay Adherence | 1 | 0.836 | 0.725 | 0.637 | 0.617 | 0.736 | 0.652 | 0.767 |
| Consistency | 0.836 | 1 | 0.818 | 0.723 | 0.707 | 0.797 | 0.749 | 0.798 |
| Contextual Understanding | 0.725 | 0.818 | 1 | 0.821 | 0.867 | 0.827 | 0.869 | 0.871 |
| Expressiveness | 0.637 | 0.723 | 0.821 | 1 | 0.841 | 0.759 | 0.904 | 0.758 |
| Creativity | 0.617 | 0.707 | 0.867 | 0.841 | 1 | 0.74 | 0.908 | 0.782 |
| Naturalness of Japanese | 0.736 | 0.797 | 0.827 | 0.759 | 0.74 | 1 | 0.795 | 0.786 |
| Enjoyment of the Dialogue | 0.652 | 0.749 | 0.869 | 0.904 | 0.908 | 0.795 | 1 | 0.817 |
| Appropriateness of Turn-Taking | 0.767 | 0.798 | 0.871 | 0.758 | 0.782 | 0.786 | 0.817 | 1 |
これを見ると、以下のようなことが分かります。
-
Expressiveness、Creativity、Enjoyment of the Dialogueという「対話の面白さ」を測るための指標3つが強く相関している。 -
Roleplay Adherence、Consistency、Contextual Understandingという「ロールプレイ力」を測るための指標3つが強く相関している。
この結果を見ると、PingPong benchで使われているような3つ程度の指標にまとめた方が良いかもしれないということが分かります。
データセットの多様性
今回の評価データはClaude 3.5 Sonnetに合成させた30件のデータセットですが、多様性にやや欠けていることを確認できています。具体的には、アシスタントがAIのキャラクターであることが多かったり、異世界系のジャンルで「エーテル」に関連する設定が多発することが確認できています。
人手作成を含め、より多様なデータセットを準備することで高い精度での評価が可能になると考えられます。
gpt-4oとgpt-4o-miniの性能逆転について
評価結果を見ると、gpt-4o-miniのスコアがかなり高くgpt-4oを上回っていることが確認できます。
最初は評価の誤差によるものかと思いましたが、先行事例であるPingPong benchの結果においても同様にgpt-4o-miniがgpt-4oを上回っており、誤差ではなくgpt-4o-miniの方がロールプレイ能力が高い可能性があります。
この原因として、有害な出力をしないようにアライメントされた非常に性能が高いモデルは表現力や創造性を逆に失ってしまっている可能性があると考えています。良くも悪くもgpt-4o-miniの方が少し「お馬鹿」であり、その結果として多様な表現を生み出せているのではないかと考えられます。
まとめ
この記事では、今回構築したJapanese-RP-Benchに関して概要や評価結果等をまとめました。まだまだ改善点等も多いですが、LLMの性能検証にどこかで役に立つことを祈ります。
Discussion