RubyでWebスクレイピング #3 Nokogiriを使いこなす
前 #2 初めてのNokogiri
次 #4 URLの取得とページ遷移
準備
一応続きものなので、前回と同様の準備(Nokogiriのインストール)をしておけばとりあえず大丈夫。このシリーズ用のリポジトリも、今回の記事に合わせて更新済みだ。
GitHub zenn_scraping
XPath vs CSSセレクタ
Nokogiriで要素を指定する際、大きく分けてXPathによる指定とCSSセレクタによる指定の2パターンが考えられる。もちろんこれは対象や目的によって使い分けてもいいのだが、Webスクレイピング目的であればCSSセレクタの使用を推奨する。理由は3つあり、「WebエンジニアにとってCSSセレクタの方が馴染みがある」、「今時のWebページはidやclassが適切に使われていることが多いため、それを素直に利用できた方が良い」、「私がCSSセレクタの方しか使ったことがない(それでもWebスクレイピングは問題なく行える)」だ。
ブラウザの開発ツール
スクレイピング対象のWebページのhtmlを確認したい場合、ページのソースを開いてもいいのだが、ブラウザに搭載されている開発ツール(デベロッパーツール)を使用した方がはるかに分かりやすいので、そちらを使うべきだ。Macの場合、FirefoxでもChromeでもCommand+Option+Iで開くことができる。今回はソースを確認したいので、Firefoxの場合はインスペクタータブ、Chromeの場合はElementsタブを選択する。

Firefoxの場合(開発ツール)
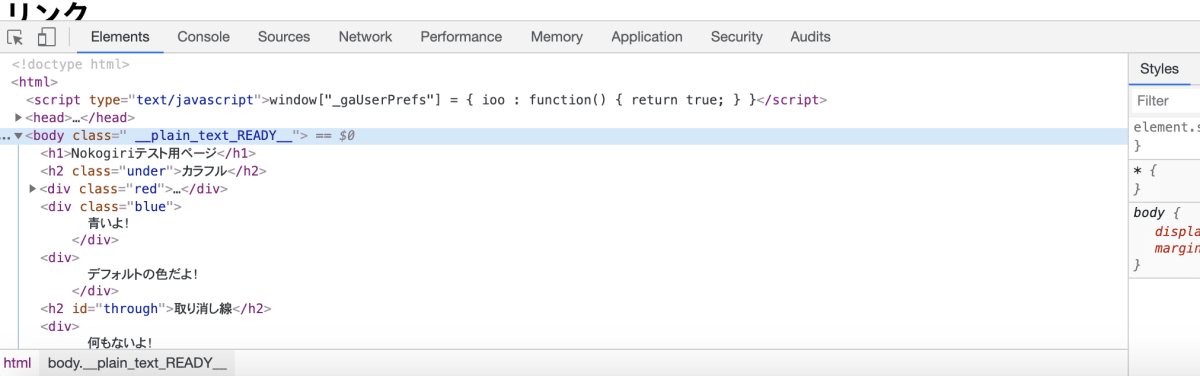
Chromeの場合(デベロッパーツール)
開発ツールを下部に表示している場合、その左上にあるアイコンをクリックすると、ページから要素を選択できる。ブラウザで表示されているこのテキスト、この画像は、htmlではどこに書かれているのか、といったものを簡単に探せるので、是非活用しよう。

Firefoxの場合

Chromeの場合
前回の記事でも少し触れたが、ブラウザの開発ツールについて、気を付けなければならないことがある。ブラウザの開発ツールで表示されるhtmlと、open-uriで取得できるhtmlには差分があることが多いのだ。ブラウザ側ではJavaScriptによって動的にコンテンツが生成されているのに対し、open-uriでは動的に生成されるコンテンツを取得できていない、というケースがほとんどだが、中にはhtmlがあまりお行儀よく書かれておらず、ブラウザ側で補完されているケースもある。ブラウザ側で補完されているケースについては本記事でも触れるが、JavaScriptによって動的に生成されるコンテンツから情報を切り出したいときのテクニックは、もうしばらく先の記事で解説する。
Nokogiriの各種メソッドと実際の使用例
Nokogiriに用意されているメソッドで何ができるか、どんなときに役立つかを、実際のWebページ、Rubyのコード、実行結果とセットで解説する。実際のWebページは解説のために用意したこちらを使う。
Nokogiriテスト用ページ
スクリプトを実行する度にアクセスしても良いが、常に同じhtmlを返すだけのシンプルなページなので、一度htmlをopen-uriで取得したらそれをローカルに保存し、それ以降は保存したhtmlを対象にスクレイピングを行ってみよう。また、リポジトリには最初からhtmlを保存してあるため、それをそのまま使えば良い。
require 'open-uri'
html = URI.open('https://arao99.github.io/zenn_scraping/nokogiri_practice.html').read
puts html
$ bundle exec ruby get_html_open-uri.rb > nokogiri_practice.html
取得したhtmlをローカルに保存する。
html = open('nokogiri_practice.html').read
それ以降は、このスクリプトをベースにNokogiriの練習をしよう。
title
前回の記事でも出てきたtitleメソッド。htmlのtitleを取得できる。
Nokogiri公式 title-instance_method
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
title = doc.title
puts title
$ bundle exec ruby title_nokogiri.rb
Nokogiriテスト用ページ
titleタグがある場合は、そのタグで囲まれた文字列をStringクラスで返し、titleがない場合はnilを返す。機能も使い方もごくシンプルだが、意外と使える場面は多いため、どのようなときに使えるか解説する。
まず、対象のWebページを正しく開けたか(正しくhtmlを取得できたか)の判定に使う。open-uriでHTTPステータスコード4xx系や5xx系を受け取った場合、open-uriは例外を投げてくれるので、そこで対応するようなコードを書けばいいのだが、HTTPステータスコードは正常なのにDBとの接続に失敗したなどの理由でエラーページを返してくるWebページも中にはある。そんなエラーページのtitleは大抵の場合エラーであることを示す文字列になっているため、いつものtitleと異なる、あるいは「エラー」などの文字列を含む場合、ページを正しく開けなかったと判断する、という使い方ができる。
次に、先ほどの例と似ているが、対象のWebページにレイアウト変更などがあった場合の検知に利用する。特定の情報サイトを毎日朝晩スクレイピングする、といったような定点観測を行う場合、その大敵はページのレイアウト変更だ。取得対象のテキストをidやclassなどで指定できている場合は、レイアウト変更があっても問題なく取得できていることが多いが、それでもレイアウト変更があった場合は変更後のhtmlを確認しておくに越したことはない。毎回のスクレイピングでtitleを取得して保存しておくようにして、前回とtitleが異なっていた場合に何らかのアラートを上げるようにしておけば、レイアウト変更に気付けることもある。もちろんtitleをそのままにレイアウト変更されるケースも多々あるため、確実ではないが。
最後に、URLが正しいかどうか確かめるのに使う。○○の公式サイトのURLは〜〜というような形のURLリストを渡された場合、そのURLリストが古いと、ドメインの有効期限切れで全く別のサイトになってたり、そもそもURLが間違っていたり、ということが頻繁にある。そういった場合に、open-uriで開けるかどうかのチェックの次に、titleにその○○の文字列が含まれているかどうかのチェックを行うと、URLが正しいかどうかの判断が機械的に行える。チェックで弾かれた場合でもその原因が表記揺れだったりすることがあるが、それでもいちいちブラウザで手動で開くよりかは遥かに効率よく検証を行えるはずだ。また当たり前だが、nilが返ってきた場合(titleタグがない場合)は、超高確率でURLが間違っている。
at_css, css
at_cssもcssも、CSSセレクタで要素を選択して取得するメソッドだ。機能がよく似ていて、Nokogiriでスクレイピングをしてみた、のようなブログには、cssの方しか紹介されていなかったりするが、両方を目的に合わせて正しく使い分けるのが、見通しの良いコードを書くポイントだと思う。
Nokogiri公式 at_css-instance_method
Nokogiri公式 css-instance_method
まずはat_cssメソッド。こちらは条件に合う要素を1つだけ取得する。条件に合う要素が複数ある場合は最初の要素を、条件に合う要素がない場合はnilを返す。要素があった場合、その戻り値はElementクラスになっている。実際のコードと実行結果を見てみよう。
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
pp doc.at_css('h1') # 条件に合う要素が1つだけの場合
pp doc.at_css('#through') # CSSセレクタらしくidで指定
pp doc.at_css('.under') # classで指定。条件に合う最初の要素を取得
pp doc.at_css('body > div:nth-child(3)') # nth-childも使える
pp doc.at_css('body > h2:nth-of-type(3)') # nth-of-typeも使える
pp doc.at_css('h1').class # 戻り値のクラスを確認
pp doc.at_css('.hogehoge') # 条件に合う要素が存在しない場合
$ bundle exec ruby at_css_nokogiri.rb
#(Element:0x320 { name = "h1", children = [ #(Text "Nokogiriテスト用ページ")] })
#(Element:0x334 {
name = "h2",
attributes = [ #(Attr:0x348 { name = "id", value = "through" })],
children = [ #(Text "取り消し線")]
})
#(Element:0x35c {
name = "h2",
attributes = [ #(Attr:0x370 { name = "class", value = "under" })],
children = [ #(Text "カラフル")]
})
#(Element:0x384 {
name = "div",
attributes = [ #(Attr:0x398 { name = "class", value = "red" })],
children = [
#(Text "\n" + " 赤いよ!"),
#(Element:0x3ac { name = "br" }),
#(Text "\n" + " 赤いよ!\n" + " ")]
})
#(Element:0x3c0 { name = "h2", children = [ #(Text "リンク")] })
Nokogiri::XML::Element
nil
こんな感じだ。ElementからAttrやText、あるいは他の子要素を取得する方法は後ほど。
次にcssメソッド。こちらは条件に合う要素を配列形式で全て取得する。戻り値のクラスはNodeSetになっている。こちらも実際のコードと実行結果を見てみよう。
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
pp doc.css('h2') # 複数取得
pp doc.css('#through') # 1つだけ取得
pp doc.css('.under') # 複数取得
pp doc.css('.hogehoge') # 条件に合う要素が存在しない場合
pp doc.css('table th') # もちろんこんなことも可能
pp doc.css('h2').class # 戻り値のクラスを確認(複数)
pp doc.css('#through').class # 戻り値のクラスを確認(1つだけ)
pp doc.css('.hogehoge').class # 戻り値のクラスを確認(存在しない)
$ bundle exec ruby css_nokogiri.rb
[#<Nokogiri::XML::Element:0x348 name="h2" attributes=[#<Nokogiri::XML::Attr:0x320 name="class" value="under">] children=[#<Nokogiri::XML::Text:0x334 "カラフル">]>, #<Nokogiri::XML::Element:0x384 name="h2" attributes=[#<Nokogiri::XML::Attr:0x35c name="id" value="through">] children=[#<Nokogiri::XML::Text:0x370 "取り消し線">]>, #<Nokogiri::XML::Element:0x3ac name="h2" children=[#<Nokogiri::XML::Text:0x398 "リンク">]>, #<Nokogiri::XML::Element:0x3e8 name="h2" attributes=[#<Nokogiri::XML::Attr:0x3c0 name="class" value="under">] children=[#<Nokogiri::XML::Text:0x3d4 "テーブル">]>]
[#<Nokogiri::XML::Element:0x384 name="h2" attributes=[#<Nokogiri::XML::Attr:0x35c name="id" value="through">] children=[#<Nokogiri::XML::Text:0x370 "取り消し線">]>]
[#<Nokogiri::XML::Element:0x348 name="h2" attributes=[#<Nokogiri::XML::Attr:0x320 name="class" value="under">] children=[#<Nokogiri::XML::Text:0x334 "カラフル">]>, #<Nokogiri::XML::Element:0x3e8 name="h2" attributes=[#<Nokogiri::XML::Attr:0x3c0 name="class" value="under">] children=[#<Nokogiri::XML::Text:0x3d4 "テーブル">]>]
[]
[#<Nokogiri::XML::Element:0x410 name="th" children=[#<Nokogiri::XML::Text:0x3fc "属性">]>, #<Nokogiri::XML::Element:0x438 name="th" children=[#<Nokogiri::XML::Text:0x424 "通常攻撃魔法">]>, #<Nokogiri::XML::Element:0x460 name="th" children=[#<Nokogiri::XML::Text:0x44c "大魔法">]>]
Nokogiri::XML::NodeSet
Nokogiri::XML::NodeSet
Nokogiri::XML::NodeSet
実行結果の方がちょっとゴチャゴチャしてしまったが、期待通りに取得できていることが何となく分かっただろうか。
さて、ここまでの例で、わざわざ戻り値のクラス名も確認していたのには訳がある。at_cssの戻り値Elementと、cssの戻り値NodeSetの関係を、きちんとイメージして覚えてほしいためだ。というわけで、公式ドキュメントを確認してみよう。
Nokogiri公式 Class: Nokogiri::XML::NodeSet
Nokogiri公式 Class: Nokogiri::XML::Element
Nokogiri公式 Class: Nokogiri::XML::Node
NodeSetクラスはNodeクラスのオブジェクトのリストを保持していて、ElementクラスはNodeクラスを継承している。またNodeSetクラスはEnumerableモジュールをインクルードしているため、配列と同じような感覚で扱うことができる。
module Enumerable
よく分からない!という方は、「at_cssはNodeを取得するメソッドで、cssはNodeSetを取得するメソッドで、NodeSetは各要素がNodeの配列」というイメージを持っておけば、ほぼ間違いはない。
では、それらを踏まえてサンプルコードとその実行結果を確認してみよう。
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
pp doc.at_css('h2')
pp doc.css('h2').first # この2つは同じものが取得される
pp doc.at_css('.hogehoge')
pp doc.css('.hogehoge').first # この2つも結果的に同じものが取得される
doc.css('th').each do |th| # eachの例
pp th
end
$ bundle exec ruby css_sample1_nokogiri.rb
#(Element:0x320 {
name = "h2",
attributes = [ #(Attr:0x334 { name = "class", value = "under" })],
children = [ #(Text "カラフル")]
})
#(Element:0x320 {
name = "h2",
attributes = [ #(Attr:0x334 { name = "class", value = "under" })],
children = [ #(Text "カラフル")]
})
nil
nil
#(Element:0x348 { name = "th", children = [ #(Text "属性")] })
#(Element:0x35c { name = "th", children = [ #(Text "通常攻撃魔法")] })
#(Element:0x370 { name = "th", children = [ #(Text "大魔法")] })
鋭い方はお気付きだと思うが、at_cssクラスもcssクラスもSearchableモジュールのメソッドで、SearchableモジュールはNodeクラスにもインクルードされている(NodeSetクラスにもインクルードされているが、話がややこしくなるためこちらは省略)。
Nokogiri公式 Module: Nokogiri::XML::Searchable
つまり、at_cssの戻り値にさらにat_cssやcssを使うことができる。
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
pp doc.at_css('table th')
pp doc.at_css('table').at_css('th') # この2つは同じものが取得される
$ bundle exec ruby css_sample2_nokogiri.rb
#(Element:0x320 { name = "th", children = [ #(Text "属性")] })
#(Element:0x320 { name = "th", children = [ #(Text "属性")] })
特定のdivタグやtableタグで囲まれた範囲に欲しい情報が集中している場合、いちいちそのdivやtableを指定して欲しい情報を取得するよりも、最初にそのdivやtableを取得して、それに対して欲しい情報を取得するためのat_cssやcssを書いた方が見通しが良くなりやすい。また、似たような構造の複数のtableそれぞれから同じ箇所を取得したい場合、引数にtable(Node)を取るメソッドを定義して、そのメソッドを複数のtableに対して実行してやる、という方法もある。
parent, children
これらメソッドを単体で使うことはまずないが、ちょっと凝ったことをしたいときによく使う。この後にも登場するのでこのタイミングで紹介。読んで字の如く、それぞれNodeの親要素と子要素を取得するメソッドだ。親の方は1つだけなのでNode(Element)クラスで、子の方は複数あったりなかったりするのでNodeSetクラスで、それぞれ取得される。
Nokogiri公式 parent-instance_method
Nokogiri公式 children-instance_method
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
pp doc.at_css('th')
pp doc.at_css('th').parent
pp doc.at_css('tr')
pp doc.at_css('tr').children
$ bundle exec ruby parent_children_nokogiri.rb
#(Element:0x320 { name = "th", children = [ #(Text "属性")] })
#(Element:0x334 {
name = "tr",
children = [
#(Text "\n" + " "),
#(Element:0x320 { name = "th", children = [ #(Text "属性")] }),
#(Text "\n" + " "),
#(Element:0x348 { name = "th", children = [ #(Text "通常攻撃魔法")] }),
#(Text "\n" + " "),
#(Element:0x35c { name = "th", children = [ #(Text "大魔法")] }),
#(Text "\n" + " ")]
})
#(Element:0x334 {
name = "tr",
children = [
#(Text "\n" + " "),
#(Element:0x320 { name = "th", children = [ #(Text "属性")] }),
#(Text "\n" + " "),
#(Element:0x348 { name = "th", children = [ #(Text "通常攻撃魔法")] }),
#(Text "\n" + " "),
#(Element:0x35c { name = "th", children = [ #(Text "大魔法")] }),
#(Text "\n" + " ")]
})
[#<Nokogiri::XML::Text:0x370 "\n ">, #<Nokogiri::XML::Element:0x320 name="th" children=[#<Nokogiri::XML::Text:0x384 "属性">]>, #<Nokogiri::XML::Text:0x398 "\n ">, #<Nokogiri::XML::Element:0x348 name="th" children=[#<Nokogiri::XML::Text:0x3ac "通常攻撃魔法">]>, #<Nokogiri::XML::Text:0x3c0 "\n ">, #<Nokogiri::XML::Element:0x35c name="th" children=[#<Nokogiri::XML::Text:0x3d4 "大魔法">]>, #<Nokogiri::XML::Text:0x3e8 "\n ">]
だいたいイメージ通りだと思うが、htmlソースを読みやすくするための改行やインデントも、テキストノードとして扱われてしまっていることに注意が必要だ。
text(content)
先ほど後回しにした、Element(Node)からTextを取得するためのメソッド。戻り値はStringクラス。使い方は簡単だがちょっとコツが要る。
Nokogiri公式 content-instance_method
公式にはcontentで掲載されていて、Also known as: text, inner_textとされているが、個人的にtextの方が直感的に分かりやすいため、以降もtextで統一する。前回記事で見出しを取得したときもtextを使っていた。
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
puts doc.at_css('h1').text
puts doc.at_css('.red').text
puts doc.at_css('.blue').text
$ bundle exec ruby text1_nokogiri.rb
Nokogiriテスト用ページ
赤いよ!
赤いよ!
青いよ!
どうも様子がおかしい。これはhtmlソースを読みやすくするための改行やインデントもそのまま扱われてしまっているのが原因だ。このような問題を解決する便利メソッドがRubyには用意されている。
instance method String#strip
文字列の先頭と末尾の空白文字を全て取り除いた文字列を生成して返してくれる、stripというメソッドだ。こちらもしれっと前回の記事で使っている。
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
puts doc.at_css('h1').text.strip
puts doc.at_css('.red').text.strip
puts doc.at_css('.blue').text.strip
$ bundle exec ruby text2_nokogiri.rb
Nokogiriテスト用ページ
赤いよ!
赤いよ!
青いよ!
惜しいところまでは来たが、赤いよ!の方がまだ変だ。文字列の先頭と末尾以外の空白文字は取り除いてくれないので当たり前と言えば当たり前ではある。ブラウザでの表示をそのまま取得したい場合、brタグは改行として扱い、各テキストノードの先頭と末尾の空白文字は除去する、という作業が必要になる。その作業に使えるのが、先ほど説明したchildrenメソッドだ。ここから先は赤いよ!の部分に対象を絞って、ブラウザでの表示をそのまま取得する方法を解説する。
まずは対象のノードのchildrenを確認してみる。
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
pp doc.at_css('.red').children
$ bundle exec ruby text3_nokogiri.rb
[#<Nokogiri::XML::Text:0x320 "\n 赤いよ!">, #<Nokogiri::XML::Element:0x334 name="br">, #<Nokogiri::XML::Text:0x348 "\n 赤いよ!\n ">]
childrenで取得できたのは、3つの要素(Node)からなるNodeSetだ。それぞれに注目すると、Textはstripしてして取得、nameがbrのElementは改行文字として取得すれば良さそう、ということが分かる。つまりNodeがTextかどうか判定するメソッドと、Nodeのnameを取得するメソッドが必要になり、もちろんそれらはちゃんと用意されている。
Nokogiri公式 text?-instance_method
Nokogiri公式 node_name-instance_method
公式のドキュメントでは、Method Listの方にはnode_nameと記載されているのに本文ではnameと記載されていて、なおかつAlso known as: nameとなっていてややこしいが、ここではnameで統一して進める。
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
red_string = ''
doc.at_css('.red').children.each do |red_child|
if red_child.text? then # 子ノードがTextの場合
red_string += red_child.text.strip # 先頭と末尾の空白文字を除去した文字列
elsif red_child.name == 'br' then # 子ノードがbrタグの場合
red_string += "\n" # 改行文字に置換
end
end
puts red_string
$ bundle exec ruby text4_nokogiri.rb
赤いよ!
赤いよ!
最初の期待通りの出力が得られたはずだ。
思い通りのテキストを取得するためにより複雑な処理が必要になることもあるが、今回扱ったメソッドや、あるいはこんなメソッドがあればいいな、というようなメソッドを調べてみたりして、今回と同様に考えていけば、よほどのことがない限り対応できるはずだ。苗字と名前の区切りに全角スペースを使った上で、レイアウト目的でさらに全角スペースを使う、などといった大変お行儀の悪いWebページもあるため、確実に対応できるとは言い切れないのだが。
attribute
attributeはその名の通り、対象ノードの属性(属性値)を取得するメソッドだ。引数には属性名を指定する必要がある。
Nokogiri公式 attribute-instance_method
属性値が欲しい機会なんてそんなにないのでは?と思う人もいるかもしれないが、それは大間違いだ。aタグのhref属性やimgタグのsrc属性を取得して、リンクを次々に辿ったり画像ファイルを取得する、なんてことができる。その具体的な方法は次回記事に回すとして、attributeメソッドの使い方はこんな感じになる。
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
puts doc.at_css('#through').attribute('id') # これは全く意味がない
link_element = doc.at_css('a') # aタグ
puts link_element.text
puts link_element.attribute('href') # aタグのhref属性を取得して出力
$ bundle exec ruby attribute_nokogiri.rb
through
ただのリンク
nokogiri_practice2.html
最初の、id属性がthroughの要素を探して、その要素のid属性を取得する操作には全く意味がないことが分かるだろうか。本題はその下の、aタグのhref属性を取得している部分だ。href属性は絶対パスで書かれていたり相対パスで書かれていたり、はたまたルートパスが使われていたり、Webページによってマチマチだが、そこは各々工夫して頑張ってほしい。
next_element, previous_element
ここまではタグをズバリ指定して、そのタグに囲まれたテキストを取得したりそのタグの属性値を取得したりしてきたが、条件に合うタグの次のタグ、前のタグの情報を取得したい、という機会もあるはずだ。今回のサンプルページを例に取ると、一番下のテーブルにおいて、氷属性の通常攻撃魔法を取得したい、大魔法セラフィックローサイトに派生する通常攻撃魔法を取得したい、といったケースだ。それぞれ、「氷」というテキストを囲んだtdタグの次のタグが囲んでいるテキスト、「セラフィックローサイト」というテキストを囲んだtdタグの前のタグが囲んでいるテキストを取得すれば、目的は達成できることになる。こんなときに使えるのがnext_elementメソッド、previous_elementメソッドだ。
Nokogiri公式 next_element-instance_method
Nokogiri公式 previous_element-instance_method

ちなみにこれらはヴァルキリープロファイルというゲームに登場する魔法
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
doc.css('td').each do |td|
if td.text.strip == '氷' then
puts td.next_element.text
end
end
doc.css('td').each do |td|
if td.text.strip == 'セラフィックローサイト' then
puts td.previous_element.text
end
end
$ bundle exec ruby next_previous1_nokogiri.rb
アイシクル・エッジ
クール・ダンセル
イグニート・ジャベリン
こんな感じで目的の情報を切り出すことができた。実際のWebページでは属性が記載されているセルが縦方向に結合していてかなり工夫が必要になることもあるが、本質的ではないところでサンプルスクリプトが複雑になってしまうため、ここでは紹介しない。先ほど紹介したattributeメソッドを使ってrowspan属性の値を取得してゴニョゴニョやってやればできるので、興味がある方は適当なサンプルhtmlを用意した上で挑戦してみてほしい。
さて、next_elementメソッドとprevious_elementメソッドに似た、next_siblingメソッドとprevious_siblingメソッドというものが存在する。標準的なWebスクレイピングではあまり使う機会がないため紹介するかどうか迷ったが、ついウッカリこちらのメソッドを使ってしまって思い通りにいかずハマるというケースも考えられるので、簡単に紹介だけしておく。
Nokogiri公式 next_sibling-instance_method
Nokogiri公式 previous_sibling-instance_method
ついウッカリこちらのメソッドを使ってしまう原因は、Also known as: nextに集約される。next_elementを使おうとしてnextと書いてしまうと、next_elementではなくnext_siblingになってしまうためだ。もちろんこれはpreviousの方も同様である。
next_elementとnext_siblingの説明を読み比べてみると、next_elementの方は、次のElementクラスの兄弟ノードを返すとあり、next_siblingの方は、次の兄弟ノードを返すとある。これがどういうことかは、実際の動作を見てみるのが一番分かりやすいだろう。
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
tr = doc.at_css('tr')
pp tr.children # テーブルのヘッダー行の子要素を確認
center_th = tr.at_css('th:nth-of-type(2)')
pp center_th # テーブルのヘッダー行の真ん中のセル(通常攻撃魔法)
pp center_th.next_element # 次のセル(大魔法)
pp center_th.next_sibling # ???
pp center_th.previous_element # 前のセル(属性)
pp center_th.previous_sibling # ???
$ bundle exec ruby next_previous2_nokogiri.rb
[#<Nokogiri::XML::Text:0x320 "\n ">, #<Nokogiri::XML::Element:0x348 name="th" children=[#<Nokogiri::XML::Text:0x334 "属性">]>, #<Nokogiri::XML::Text:0x35c "\n ">, #<Nokogiri::XML::Element:0x384 name="th" children=[#<Nokogiri::XML::Text:0x370 "通常攻撃魔法">]>, #<Nokogiri::XML::Text:0x398 "\n ">, #<Nokogiri::XML::Element:0x3c0 name="th" children=[#<Nokogiri::XML::Text:0x3ac "大魔法">]>, #<Nokogiri::XML::Text:0x3d4 "\n ">]
#(Element:0x384 { name = "th", children = [ #(Text "通常攻撃魔法")] })
#(Element:0x3c0 { name = "th", children = [ #(Text "大魔法")] })
#(Text "\n" + " ")
#(Element:0x348 { name = "th", children = [ #(Text "属性")] })
#(Text "\n" + " ")
この例だと、次のElementクラスの兄弟ノードは大魔法になるが、次の兄弟ノードはTextクラスのhtmlの見栄えのためだけの空白文字群になってしまうのだ。人間にとっての読みやすさを一切無視したhtmlが対象であれば今回のような例で使い分けを気にする必要はないが、そんなWebページはまずない。
ブラウザ側でタグが補完されている例
最初の方で、htmlがあまりお行儀よく書かれておらずブラウザ側で補完されているケースの存在について少し触れたが、実は今回サンプルとして使っているhtmlにもそうなっている箇所があるのだ。それはtableタグの部分で、ブラウザの開発ツールではtbodyタグが補完されている。参考画像も掲載するが、是非自分でも確かめてみてほしい。FirefoxとChromeでは補完されていることを確認したが、もしかしたらブラウザによっては補完されていないかもしれない。

開発ツールではtbodyタグが補完されているが

オリジナルのソースにはtbodyタグは存在しない
open-uriにはタグを補完する機能はないため、open-uriで取得したhtmlはオリジナルのソースである。したがって、ブラウザの開発ツールだけを見てCSSセレクタを書いていると、思うように要素を選択できない事象が時々発生する。中でもこのtbodyの補完が原因であるケースが非常に多いため、今回紹介した。具体的にどうなるのかは次のスクリプトで確認してみよう。
require 'nokogiri'
html = open('nokogiri_practice.html').read
doc = Nokogiri::HTML.parse(html)
puts doc.at_css('table > tr > th').text # オリジナルのhtmlに従った場合
puts doc.at_css('table > tbody > tr > th').text # 開発ツールに従った場合
$ bundle exec ruby complement.rb
属性
Traceback (most recent call last):
complement.rb:7:in `<main>': undefined method `text' for nil:NilClass (NoMethodError)
親子関係をカッチリ指定したCSSセレクタを書いた場合だ。オリジナルのhtmlに従った方はちゃんと要素を取得できているので、テキストも取得できている。しかし、開発ツールに従った場合は存在しないtbodyが含まれてしまっているため、要素を取得できない。at_cssメソッドは要素を取得できなかった場合にnilを返す仕様になっているため、NilClassにtextなんてメソッドはないよというエラーが出てしまった。
まとめ
Nokogiriを使いこなすと題して、Webスクレイピングでよく使うNokogiriの各種メソッドを解説した。今回解説したメソッドを使えば、普通のWebスクレイピングで困ることはあまりなくなるはずだ。本当はもう少しコンパクトにまとめるつもりだったのだが、どうせならこれも紹介しておくか、これの解説をするならこっちの解説も必要だ、といった具合に、内容がどんどん肥大化してしまった。
ちなみにNokogiriにはhtmlをパースする(DOM構造を解析する)機能だけでなく、解析したDOM構造を書き換えたり、さらに書き換えたDOM構造をhtmlに戻す機能なんかも備えている。これらの機能は今のところ解説の予定はないが、高度なWebスクレイピングや特殊な目的では使いたくなることもあるので、今後のために存在だけでも覚えておいてほしい。
次回以降の予定
attributeメソッドで画像ファイルやリンク先のURLを取得する例を紹介したので、次回はページ遷移や画像ファイルの取得を伴うWebスクレイピングの手法と、そのときの注意点について解説しようと思う。html以外のものを取得する方法は後回し。
Discussion