RubyでWebスクレイピング #5 javascript対応テクニック
準備
今回の記事に合わせてリポジトリを更新済み。
GitHub zenn_scraping
前回までと同様にNokogiriをインストールしておけば大丈夫、と言いたいところだが、今回紹介するテクニックの本質的な部分にNokogiriは関係ないので、なくても問題ない。
導入
予告通り、欲しい情報がブラウザでは取得できるがopen-uriで取得されるhtmlには含まれていない場合の主な対処方法を解説するのだが、いきなりその話をしても実感しにくいと思うので、まずは復習も兼ねてこちらに従って進めてみてほしい。今回使うサンプルページはこれだ。
jsサンプルページ1
ロマンシング サ・ガ3の8人の主人公の名前と性別が表になっている。開発ツールで構造を確認して、ひとまず一番上のユリアンを取得するようなスクリプトを書いてみよう。

開発ツールで確認
require 'open-uri'
require 'nokogiri'
html = URI.open('https://arao99.github.io/zenn_scraping/js_sample1.html').read
doc = Nokogiri::HTML.parse(html)
puts doc.at_css('td').text.strip
いつものようにopen-uriでhtmlを取得してNokogiriでパースして最初のtd要素のテキストを取得して先頭と末尾の空白文字を除去したものを出力するスクリプトだ。ところがこれを実行するとこんな感じのエラーが発生するはずだ。
$ bundle exec ruby normal_scraping1.rb
Traceback (most recent call last):
normal_scraping1.rb:6:in `<main>': undefined method `text' for nil:NilClass (NoMethodError)
NilClassにはtextメソッドが定義されていない、と言われている。つまりこれはat_cssメソッドの戻り値がnilになっていることを示していて、何故戻り値がnilになるかと言うと、条件に合う要素が1つも見つからなかったからだ。
開発ツール上ではちゃんとtd要素は存在しているのに、Nokogiriでパースするとないと言われる。このような場合、まずは取得されたhtmlが期待通りのものか(今回はtd要素を含んでいるか)確認してみよう。
require 'open-uri'
html = URI.open('https://arao99.github.io/zenn_scraping/js_sample1.html').read
puts html
$ bundle exec ruby normal_scraping2.rb > js_sample1.html
保存されたhtmlを確認すると、表の部分が丸々欠落していることが分かるはずだ。まさにこれが、欲しい情報がブラウザでは取得できるがopen-uriで取得されるhtmlには含まれていない場合、である。こんなときはどうすればいいか、今回の記事で解説する。
開発ツールのネットワークタブの確認
htmlに含まれていないものがブラウザで表示されるということは、javascriptによってhtmlが書き換えられていると考えられる。また、htmlに含まれないコンテンツは、何か別のリクエストによって取得されていると考えられるのが妥当だろう。どんなリクエストが走っているか、ブラウザの開発ツールのネットワークタブで確認してみよう。面倒なのでFirefoxの場合しか掲載しないが、他のブラウザ、少なくともChromeには同等の機能が備わっている。

開発ツール ネットワークタブ
一般的なページを開くともっとたくさんのリクエストが裏で走っているのだが、今回のサンプルページはシンプルなものだ。一番上のjs_sample1.htmlはhtmlの本体で、その下のonload_html.jsは、このhtml内にscriptタグで埋め込まれているjavascriptファイルだ。アイコン画像を用意していないため404が返ってきているfavicon.icoはスルーして、その下のheroes.htmlがいかにも怪しい。このリクエストのレスポンスを確認してみると、こんな感じになっている。
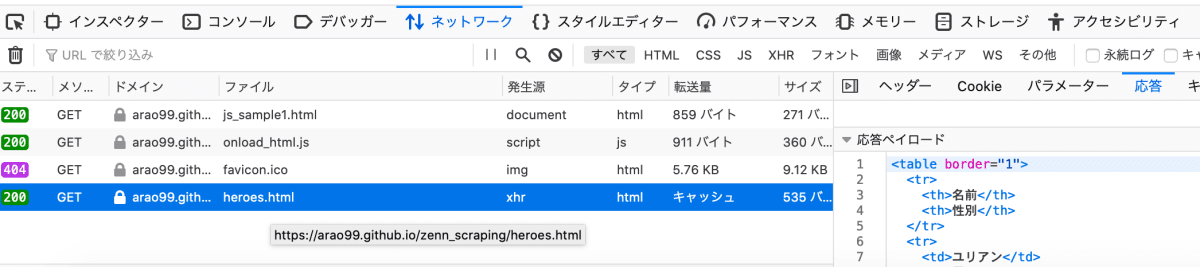
heroes.htmlの中身
もうお分かりだろう。javascriptによってjs_sample1.htmlとは別のhtmlを取得するリクエストが投げられていて、そのレスポンスが元のjs_sample1.htmlに描画されているのである。今回取得したい情報がこのレスポンスに含まれていることが分かったので、js_sample1.htmlを取得するのではなく、heroes.htmlを取得してやればいいわけだ。
require 'open-uri'
require 'nokogiri'
html = URI.open('https://arao99.github.io/zenn_scraping/heroes.html').read
doc = Nokogiri::HTML.parse(html)
puts doc.at_css('td').text.strip
$ bundle exec ruby js_scraping1.rb
ユリアン
さっきのスクリプトと異なるのはURLだけだ。このように、欲しい情報が含まれるリクエストを探るのがうまくいかないときの基本方針となる。
JSONの取得
次のサンプルページはこちら。ブラウザで表示してみよう。
jsサンプルページ2
ブラウザ上での表示はさっきと同じだが、ネットワークタブを確認してみると、こちらはhtmlではなくJSONを取得している。
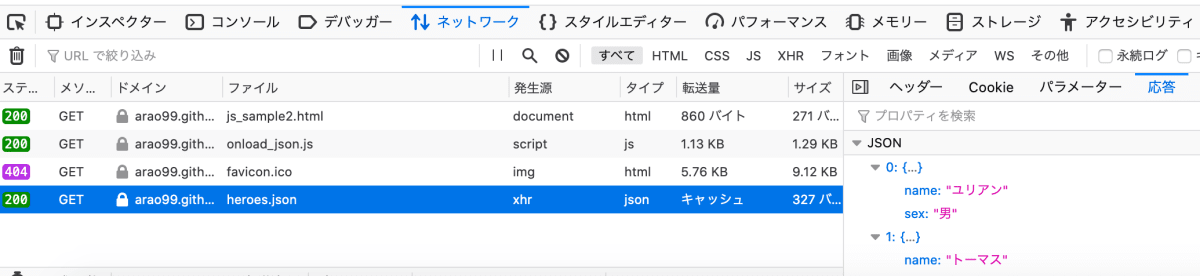
heroes.jsonの中身
したがって、今回はNokogiriを使うのではなくRuby標準のJSONモジュールを使ってパースしてやる必要がある。
module JSON
require 'open-uri'
require 'json'
heroes_json = URI.open('https://arao99.github.io/zenn_scraping/heroes.json').read
heroes_array = JSON.parse(heroes_json)
pp heroes_array
puts heroes_array.first['name']
$ bundle exec ruby js_scraping2.rb
[{"name"=>"ユリアン", "sex"=>"男"},
{"name"=>"トーマス", "sex"=>"男"},
{"name"=>"ミカエル", "sex"=>"男"},
{"name"=>"ハリード", "sex"=>"男"},
{"name"=>"サラ", "sex"=>"女"},
{"name"=>"エレン", "sex"=>"女"},
{"name"=>"モニカ", "sex"=>"女"},
{"name"=>"カタリナ", "sex"=>"女"}]
ユリアン
こんな感じになる。JSONをパースしたものも出力してみた。経験上、javascriptによってコンテンツが取得される場合、そのコンテンツは高確率でJSONだ。時々最初の例のようにhtmlがそのまま落ちてくる場合もあるにはあるが、それほど多くない。Web APIのレスポンスもJSONで返ってくるのが一般的なので、JSONの扱いには慣れておこう。
ブラウザ上の操作によって取得されるコンテンツ
これまでの例では特にこちらが何か操作をすることなくコンテンツが読み込まれたが、ブラウザ上での操作に応じてコンテンツが書き換わるようなページも多い。そのサンプルを用意したので、まずはそれを確認してほしい。
jsサンプルページ3
上のセレクトボックスでゲームのタイトルを選択すると、そのタイトルに登場するボスのリストが下のセレクトボックスに反映される。ロマサガ1は四天王の方を選ぶべきだったかもしれないが、ロマサガ2、ロマサガ3との対応を考えて三柱神を選んだ。このタイトルごとのボスの一覧を取得することを考えてみよう。
例によって開発ツールのネットワークタブを確認してみると、タイトルを選ぶとリクエストが走り、JSONが取得されていることが分かる。

ネットワークタブ
そしてそのファイル名(URLの一部)は、インスペクタータブを確認してみると、上のセレクトボックス内のoption要素のvalue属性値によって定まっていることが分かる。

インスペクタータブ
したがって、option要素からタイトルを取得し、value属性値からURLを生成し、ボスのリストを取得する、というのを繰り返せば良さそうだ。具体的にはこんな感じになる。リクエストの前にsleepを挟むのを忘れないように。
require 'open-uri'
require 'nokogiri'
require 'json'
html = URI.open('https://arao99.github.io/zenn_scraping/js_sample3.html').read
doc = Nokogiri::HTML.parse(html)
doc.css('select[name="game"] > option').each do |title|
value = title.attribute('value').value
next if value.empty?
puts title.text.strip
url = "https://arao99.github.io/zenn_scraping/#{value}.json"
sleep 1
boss_json = URI.open(url).read
boss_hash = JSON.parse(boss_json)
boss_hash['boss'].each do |boss|
puts boss['name']
end
end
$ bundle exec ruby js_scraping3.rb
ロマサガ1
デス
シェラハ
サルーイン
ロマサガ2
ワグナス
ノエル
スービエ
ロックブーケ
ダンターグ
ボクオーン
クジンシー
ロマサガ3
アラケス
ビューネイ
アウナス
フォルネウス
サンプルページにGitHub Pagesを使っている関係上、選択することによって落ちてくるJSONは静的なJSONだが、実際のWebページではvalueの値やテキストがクエリパラメータに設定されることが多い。例としてNURO光対応マンション一覧のページを挙げておく。こちらのページを対象に練習をしてみるのも良いと思うが、くれぐれも連続アクセスなどによって迷惑をかけないように。
NURO光

NURO光の場合
まとめ
javascriptによって描画されるコンテンツを取得したい場合のテクニックを解説した。より厳密にロジックを組み立てる場合は、実際のjsファイルの中身も確認した方が良いのだが、難読化されていたり、そうでなくても分量が多くて当該箇所を探すのが大変だったりと、現実的ではない。先ほどの例でもvalueの値が使われているというのは推測でしかないわけだが、それでも経験上この推測はほとんど正しいので、この部分は慣れていくしかない。ブラウザの開発ツールから欲しいコンテンツを受け取っているリクエストを探すのも最初のうちは大変だが、フィルタなどを活用して頑張ってみてほしい。すぐ慣れるはずだ。あまりにも複雑な場合は諦めてSelenium + Headless Chromeに頼った方が良い。
次回以降の予定
そろそろMechanizeの解説を、といきたいところだが、せっかくWebスクレイピングによって取得した情報を標準出力に吐き出すだけではその後扱いにくいため、RubyとMySQLを接続するActiveRecordの使い方を先に解説する。Nokogiriを導入してから新しいgemは登場していなかったが、次回はいくつか登場する見込み。こちらも自分で復習しながら書き進めるので、時間がかかりそうだ。
Discussion