動的ペルソナ適応で進化する対話エージェントに関する論文を一緒に読みましょう!
SPDA: 会話中に“自分のペルソナ”を進化させる個人化対話エージェント
この記事は,「自分の理解を深めたい」という気持ちで書いています.読者のみなさんと同じ目線で,一緒に理解を育てていくスタイルです.僕の理解が及ばない部分があれば,優しく教えていただけると幸いです!
TL;DR
- SPDA(Self-evolving Personalized Dialogue Agents)は,対話の最中にエージェント自身のペルソナを動的に更新してユーザに徐々に合わせ込む枠組み.属性レベルとプロフィール(全体)レベルの二段で適応し,整合性チェックで矛盾を回避する.
- テストベッドは Emotional Support Conversations(ESConv).
静的評価(NLG/多様性/パーソナ指標) と対話型の人手評価(自然さ/親和/個人化) で,固定ペルソナ(Supporter/Pre-Match)や無ペルソナより広く優位. - アブレーションでは,属性レベル/プロフィールレベルの双方が有効で,階層型(両方) が最良.ペルソナ整合スコアはターン進行とともに上昇し,事前マッチを追い抜く.
背景
-
“固定ペルソナ”の限界
多くの対話エージェントは,最初に決めた(あるいは事前にマッチさせた)ペルソナで最後まで対話をする.しかし現実の会話では,ユーザの属性や好みは対話の進行につれて徐々に明らかにななる.固定のままだと不一致やぎこちなさが残る——ここが出発点です. -
対象ドメイン:感情支援(ESConv)
実験の土台は Emotional Support Conversations(ESConv).相談者と支援者のマルチターン会話で,共感・配慮・継続的な理解が求められるため,一貫した“人となり”の維持がとくに重要である. -
先行スタイルとの比較枠
ベースラインは大きく2系統:
①「Supporter」= 一般的な支援者プロファイル(個人化は弱い)
②「Pre-Match」= 事前に合いそうなペルソナを固定マッチ(途中でズレても直せない). -
動的更新の“安全策”が必要
会話の途中で設定を盛り替えると矛盾(例:「独身」→数ターン後「2年既婚」)が生じやすい.
一言でいうと:
「固定ペルソナだと現実の会話に追随できない」 という問題意識のもと,感情支援という“人となり”が効く場で,矛盾を避けつつ会話中にペルソナを進化させる——これが本研究の実験背景です.
提案
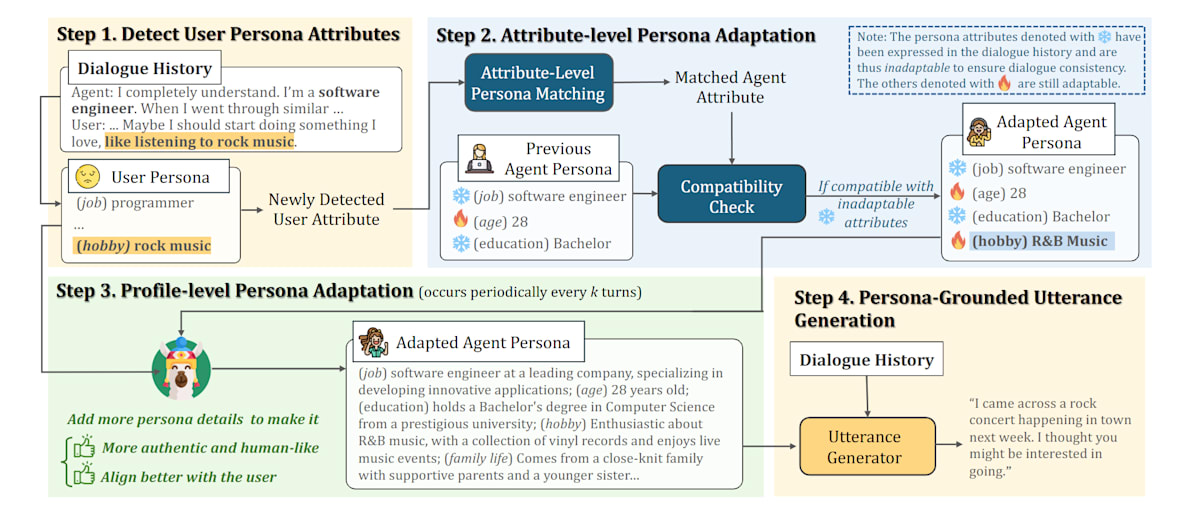
SPDAは,“動的に合わせ続ける” ことの意義を検証する設計.
また,属性レベルの互換性チェック(過去に発話済みの属性は“不変”として扱う)を入れて,破綻を未然に防ぐ設計にしている.
- 動的ペルソナ適応という新パラダイム(SPDA):ユーザ情報が会話で徐々に顕在化する前提で,都度“自分の設定”を更新して親和性を高める.
-
階層型の適応:細部と全体像の両方で“その人らしさ”を育てる
- 属性レベル:ユーザから検出した小さな事実(趣味・職業などの属性)に対し,同カテゴリのエージェント属性をマッチ→互換性チェックを通れば採用(矛盾回避).
- プロフィールレベル:kターンごとに人物像のプロフィール全体の記述を増補・精緻化して,より人間的で一貫性あるペルソナに.SFT→DPO で強化.
- データ構築:ESConv からユーザ/支援者のペルソナ対を注釈し,属性マッチ用とプロフィール拡張用の学習データを作成.
手法(SPDA 概観)
- ユーザ属性検出:最新発話から“未登録”のユーザ属性を抽出.
- 属性レベル適応:同カテゴリのエージェント属性を選び,発言済み(不変)属性との互換性を LLM で検証.OKなら採用.
- プロフィール適応:数ターンごとに全体記述を増補(SFT→DPO).より人間的で網羅的なペルソナに.
- 生成:適応後のペルソナを前置して各種ベースモデルでペルソナ条件付き生成.
データセット / 設定
- ESConv をベースにペア注釈(支援者/相談者)を作成:属性平均10個超,学習/検証/テストで属性マッチ用 3635/725/729,プロフィール適応用 1863/420/378 サンプル.
- ベースモデル:BlenderBot / Llama3-8B(SFT/ゼロショット)/ Gemini-1.0 / GPT-3.5.4ペルソナ条件(w/o / Supporter / Pre-Match / Ours)で比較.
- 評価指標:BLEU/ROUGE,Distinct-1/2/3,ペルソナ被覆(P/A-Cover),人手(自然さ/親和/個人化),整合スコア(Persona Alignment).
主な結果
静的評価

- ペルソナ設定(4種):
- w/o=ペルソナなし
- Supporter=全会話で同じ支援者ペルソナ
- Pre-Match=開始前にユーザへ“固定”でマッチ
- Ours=本手法SPDAが対話中に動的適応したペルソナ
- 全ベースで Ours が平均最良:多くの組合せで多様性(D-1/2/3)とP/A-Coverが改善.ゼロショット系で利得が大きい傾向.
対話型・人手評価
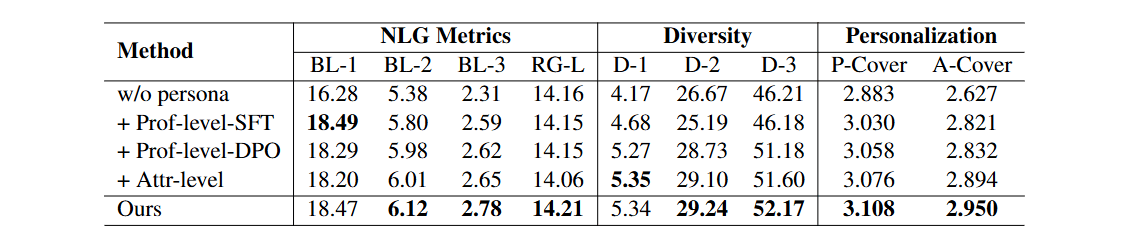
-
Prof-level-SFT
数ターンごとに,エージェントのプロフィール文(人物像の全体記述)をSFTだけで段階的に増補・書き換え. -
Prof-level-DPO
Prof-level と同じくプロフィール文を定期更新するが,更新器を DPO(嗜好最適化)までかけて人の好みに沿うよう強くチューニング. -
Attr-level
ユーザの新しい属性(嗜好・背景など)を検出するたびに,同カテゴリのエージェント属性を即時にマッチして更新.互換性チェックで矛盾を防ぐ. -
Full(Ours)
Attr-level(即時の属性更新) と Prof-level-DPO(定期の全体更新)を両方やる完全版.
プロフィールSFT→DPOが有効,属性レベルも自動指標で善戦.両輪(完全版) が総合最良.
アブレーション

- 自然さ/親和/個人化の3軸で,Ours ≫ w/o / Supporter / Pre-Match.特に親和は w/o に対し85.9%勝と顕著.
ペルソナ整合スコア

- 会話ターンが進むほど整合性が向上.序盤は事前マッチが優位だが,4ターン以降で動的適応群が逆転,完全版が最高.
限界と今後
限界(論文が自認)
- 評価スコープが狭い:実験は ESConv のみ・平均 23.4 ターンの対話長.より現実的で長期のシナリオでの分析は未実施.
- 長期運用での“膨張するペルソナ管理”が未解決:長期進化に伴うペルソナ情報の増大管理が課題として残る.
- 安全性・バイアス:エージェントは不適切/偏った内容を生成し得るため,使用時の注意を明記.
注意点(実装・運用の勘所)
- 矛盾リスクの常在:会話中に設定を更新する設計上,過去に発話済みの属性は“不変” として扱い,互換性チェックで破綻を防ぐ必要.
- 属性だけの寄せ集めは不自然になりがち:属性レベル更新のみだと人間らしさが不足しやすく,定期的なプロフィール更新(SFT→DPO)が必要.
- 制御と効率のトレードオフ:属性レベルは軽量で制御しやすいが粗く,プロフィールレベルは全体を滑らかに改善するが計算/遅延が増え得る.バランス設計が重要.
- ドメイン一般化:本検証は感情支援ドメインに限定.ほかの対話領域で同様の利得が出るかは追加検証が必要.
ひとことで:“会話中に進化”は効くが,長期現場での情報膨張・効率・安全性に設計コストが乗る——まずは互換性チェックの堅牢化とプロフィール更新頻度の最適化から始めるのが堅実です.
参考(論文情報)
- タイトル:Evolving to be Your Soulmate: Personalized Dialogue Agents with Dynamically Adapted Personas
-
著者:Yi Cheng, Wenge Liu, Kaishuai Xu, Wenjun Hou,
Yi Ouyang, Chak Tou Leong, Wenjie Li, Xian Wu, Yefeng Zheng - 年:2024
- arXiv: 2406.13960v1
Discussion