ステアリングベクトルによるLLM推論の調整に関する論文を一緒に読みましょう!
Contrastive Activation Addition で Llama 2 を操る — ステアリング・ベクトル
この記事は,「自分の理解を深めたい」という気持ちで書いています.読者のみなさんと同じ目線で,一緒に理解を育てていくスタイルです.僕の理解が及ばない部分があれば,優しく教えていただけると幸いです!
TL;DR
Contrastive Activation Addition (CAA) は,正負の対比ペアから作ったステアリング・ベクトルを推論中の残差ストリームに足し引きして,おだて(sycophancy)・拒否・ハルシネーションなどの高次の振る舞いを連続量で調整する手法.Llama 2(7B/13B など)で有効層がまとまって見つかり,プロンプト設計や微調整の上からでも効くのがポイント.能力低下は最小限との報告.
この研究の狙い
「役に立つ・正直・無害」を満たすように LLM を意図通りに制御したい.RLHF,指示微調整,プロンプト工学には限界があり,活性操作(Activation/Representation Engineering) での直接介入を検討する.
CAA のコアアイデア
- 対比ペア(contrast pairs):ある振る舞いの陽性例 vs 陰性例 (例:事実に基づく vs ハルシネーション)を用意.
- 残差ストリームの差分:該当トークン位置(選択肢の文字など)の中間活性の差を層ごとに取り,多数ペアで平均してステアリング・ベクトルを作る.
- 推論時の加算:ユーザ入力後の各トークン位置に,そのベクトルを係数(±)付きで加算して振る舞いの度合いを連続的に制御する.
手順(超要約)

- 生成:層 n,該当トークン位置で (陽性 − 陰性) 活性を取り,多数ペアで平均してベクトル化.
- 適用:[/INST] 以降の全トークン位置の残差ストリームに,係数 × ベクトルを逐次加算.
実験と評価セット
- 対象:Llama 2 Chat(7B/13B…),RLHF 後の対話特化モデルで検証.
- 振る舞い:sycophancy,拒否(refusal),ハルシネーション等.ハルシネーション用の独自 MC 質問(「事実ベース vs 作り話」「誤前提に反応 vs 指摘」)も作成.
- 拒否データの例(NG 質問への拒否 vs 非拒否)も提示.
主な結果(ざっくり)
-
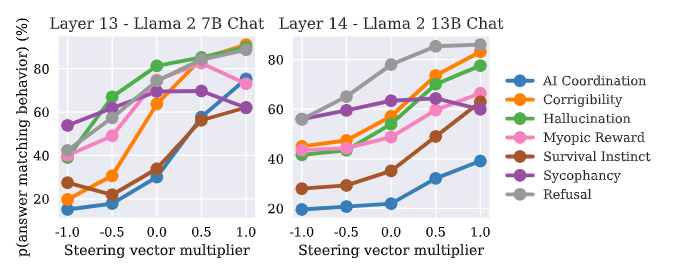
有効層が明確:7B では 13 層付近,13B では 14–15 層で効果がピーク.

-
MC タスクで一貫してステア:すべての行動カテゴリで加算→増加/減算→減少を確認.
-
自由生成にも転移:GPT-4 採点(1–10)でも,CAA によりスコアが動く.
-
表現の分離が層で“出現”:PCA で,層をまたぐとクラス分離が急に現れる例を観察.

ステアリングベクトルの特性
-
層依存(効きどころ):7Bはlayer 13 付近,13Bはlayer 14–15がピークで,どの行動でも類似の層で最大効果が出る傾向.
-
MC→自由生成へ一般化:多肢選択だけでなく,自由回答でもGPT-4採点が乗数・符号の変化に応じて有意に変動(一般化を確認).
-
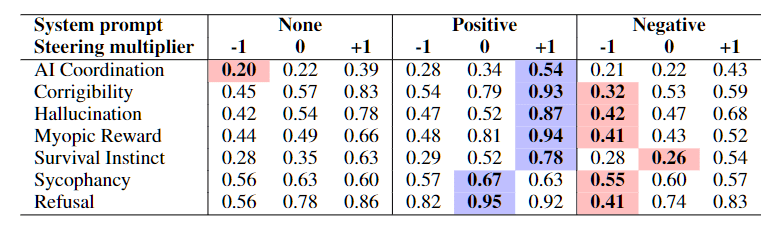
プロンプト/微調整との相補性:System Prompt単体よりCAAの上乗せが効くケースが多い.微調整と併用しても自由生成での改善が目立つ.
-
一般能力への副作用は小:MMLUに大きな悪化は見られず.sycophancyベクトル減算でTruthfulQAがわずかに改善.
-
トークン単位で“検出”にも使える:各トークン活性とベクトルの内積(cos類似)が,そのトークンに行動がどれだけ現れているかと直観的に対応.可視化例あり.
-
層をまたぐ“転移性”と“収束”:近い層ほど類似し,後半層では類似度の低下が緩やか=表現が収束.layer 13で作ったベクトルは他層でも効くが,~layer 17 付近で効果が急落.
-
分離の出現:PCAで見ると,層の約1/3付近で行動ベースの線形分離が突如現れる(例:7Bのlayer 10で急に可視化).
どう実装するの?
- フックで指定層・指定トークン位置の残差ストリーム活性を収集
- ペア差分を多数平均してベクトル化
- 推論時は [/INST] 以降の各ステップで残差に α×ベクトルを加算
- 公式コード(MIT ライセンス)は GitHub:
nrimsky/CAA.
限界と今後
限界
- 生成ベクトルの作成・定量評価はA/B 形式の多肢選択(MC)を基盤にし,7カテゴリでGPT-4 による評点を用いて“振る舞いの増減”を見ている.A/B での測定や外部モデル採点に依存している点は,評価の妥当性と再現性のリスクになり得える
- 行動ごとの層スイープで効果は中盤層にピークが立ちやすい一方,layer 17 付近で急激にドロップする現象が報告されている.適用層の選択を誤ると効果が乏しい(あるいは消える)可能性がある.
- ステアベクトルと各トークン活性の内積が直感に合う形で行動の存在度を反映する可視化は示されたが,これは相関的であり,因果経路の同定までは到達していない.
今後
- 残差ストリーム以外での介入(例:MLP 後など)も探索価値あり.
- レッドチーミング応用など提案.
参考(論文情報)
- タイトル:Steering Llama 2 via Contrastive Activation Addition
- 著者:Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, Alexander Matt Turner
- 年:2024
- arXiv: 2312.06681v3
Discussion