🐈
文中の一部について文脈化単語埋め込みを獲得するために
文中の一部について文脈化単語埋め込みを獲得したい時、tokenizeによって思うように埋め込みが獲得できないことがあります。
例えば
「'猫', 'は', 'こたつ', 'で', '丸く', 'なる', '。'」
の「丸く」について埋め込みが獲得したいとき、単純にtokenizerに通すと
「'[CLS]', '猫', 'は', 'こ', '##た', '##つ', 'で', '丸', '##く', 'なる', '。', '[SEP]'」のようにtokenizeされ、該当の埋め込みを取得するためのindexがズレてしまいます。
また、分かち書きされていない文章に対しても同様に「n文字目~m文字目」等で与えられた対象部分について埋め込みを獲得したい場合があると思います。
このような場合、対象部分を[MASK]トークンに変更してしまうことで簡単に対応できるのでオススメです。
[MASK]トークンを利用してtokenize前後の対応を取る
方針は以下の通りです。tokenize後の対象部分のindexとトークンid列を獲得することを目標にしています。(それ以降は好きにやってくれという気持ちの乱雑な5.)
- 埋め込みを獲得したい対象部分を[MASK]トークンに置換したマスク文と対象部分のみのテキストを用意する。
- マスク文、対象部分のみのテキストをそれぞれtokenizeする。
- マスクid列の[MASK]トークンid部分を探す(tokenize後の対象部分)
- マスクid列の[MASK]トークンid部分を対象id列に置換する。
- (トークンid列を用いて埋め込みを獲得し、対象部分のindexを用いて対象部分の埋め込みを獲得する)
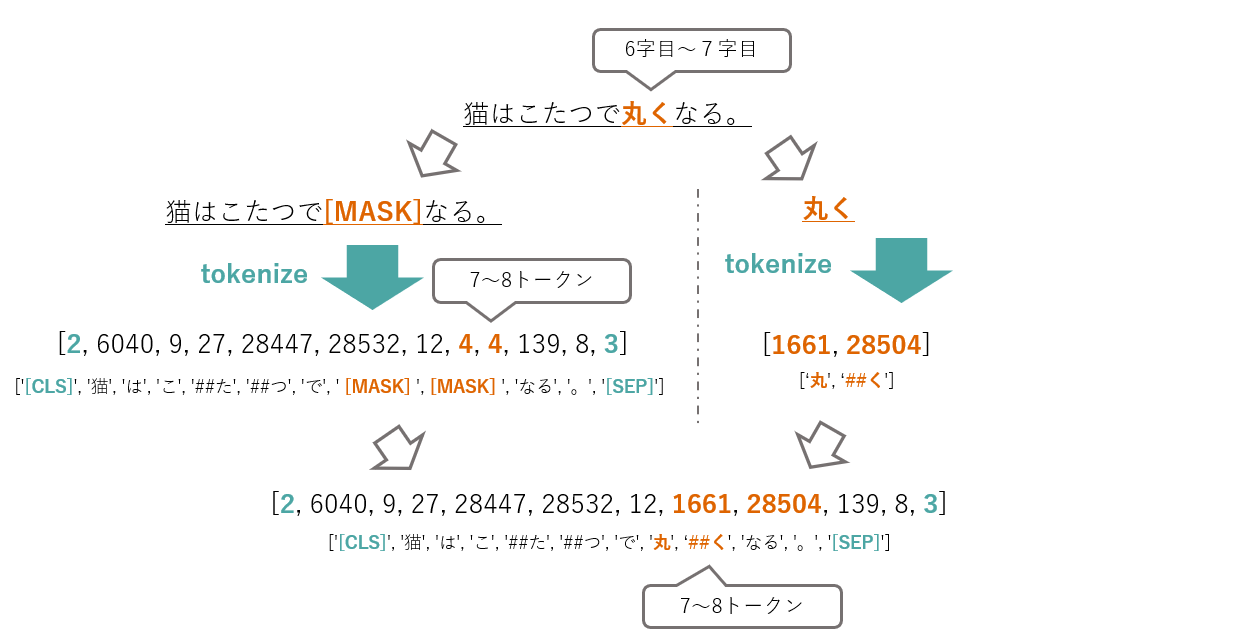
こんな感じのイメージです。[MASK]トークンのidはtokenizer.mask_token_idで取得することができます。
実装例も載せておきます。原文sentenceに対しtarget_spanで対象部分を表しています。target_id_span_startとtarget_id_span_endがtokenize後の対象部分を表し、input_idsにトークンid列が入っています。
span_maskは対象部分のみ1の行列になっていて、埋め込みとの積を取ることで対象部分のみの埋め込みを獲得できます。ここについては方針で示した範囲を超えますが参考になればということで。
tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking")
sentence = "猫はこたつで丸くなる。"
# target = "丸く"
target_span = [6, 7]
target = sentence[target_span[0] : target_span[1] + 1]
masked_sentence = (sentence[:target_span[0]] + tokenizer.mask_token + sentence[target_span[1] + 1 :])
target_ids = tokenizer(target, add_special_tokens=False).input_ids
masked_ids = tokenizer(masked_sentence).input_ids
# tokenize後のindex
target_ids_span_start = masked_ids.index(tokenizer.mask_token_id)
target_ids_span_end = target_ids_span_start + len(target_ids) - 1
input_ids = (masked_ids[:target_ids_span_start] + target_ids + masked_ids[target_ids_span_start + 1 :])
span_mask = [0] * len(input_ids)
span_mask[target_ids_span_start : target_ids_span_end + 1] = [1] * len(target_ids)
それなりによく使いそうなのにいい感じの方法が見当たらなかったので参考になればと思い書きました。
わからないことや間違っていることがあれば教えてください。
Discussion