実行計画を元にした Spanner クエリ最適化の実践
私は「Spanner でも他の RDBMS で当たり前に行われているのと同程度には実行計画を理解する」ことをテーマに情報の公開や社内での啓蒙・トラブルシューティングなどの活動を行ってきました。
私見として、 2017年の Spanner のリリースから8年経った今も実行計画の最適化についての世の中の情報は多くありません。
実行方法が自明ではない SQL をどう現実的に実行可能な程度に最適化するかというような話はまだあまり増えていないと感じています。
この文書は私が株式会社メルペイを退職する前から社外に公開するという約束で書いていたものですが、一年半以上放置してこのまま墓場まで持っていくことになる可能性が出てきました。
時代遅れになっている記述や洗練されていないままの部分も残っていますが公開しておきます。もしもまた Spanner の仕事をすることがあったら更新するかもしれません。
この記事の意図ではないこと
- Spanner ユーザでない人に何らかの先入観を与えることは意図していませんので、 Spanner ユーザ以外は読む必要はありません。
- Spanner で複雑な分析クエリを実行することはもちろん推奨しません。何らかの分散処理基盤にオフロードすることを推奨します。
- 例えば必要に応じて Data Boost を有効にし、 BigQuery(
EXTERNAL_QUERYもしくは外部データセット), Cloud Dataflow などを使う選択肢があります。
- 例えば必要に応じて Data Boost を有効にし、 BigQuery(
- この記事に書かれたプラクティスが一般的に適用可能で常に問題が解決できるというような主張はしません。個別事象で問題を解決するために検討できる選択肢を増やすのが目的です。
- トレードオフが存在することを否定する意図はありません。
- この内容を全て理解するべきであるとは主張していません。Spanner にとって最も得意なワークロード以外も処理したい時に1つずつ解決できないかどうかを試行錯誤してみようという話です。
指針
SQLパフォーマンス詳解、もしくはその Web 版の Use The Index, Luke より
注意深い実行計画の調査結果は、 うわべだけのベンチマークよりも信用のおけるものです。
完全な負荷テストは意味のあることですが、そのための手間はかかります。
- 本質的に非効率な処理を含むクエリの多くは、注意深く実行計画を読むことで負荷試験よりも早いフェーズで発見可能です。
- これは本番相当のデータがない開発用データベースしかない状態であっても例外ではありません。
- クエリの実行計画をできるだけ開発中の早期にレビュー可能な状態で共有しましょう。
- 例えば、 GitHub に添付可能なテキスト形式で得られる
spanner-cli等のEXPLAINの結果を GitHub の Pull Request に貼るだけで良いでしょう。- 時期尚早な最適化をする必要はありませんが、クエリが期待と大きく違わない形で処理可能なことを他の人もレビューできる状態にすることが重要です。
- 最初は読めなくても、事後に振り返りをしているうちに読めるようになるでしょう。
- 時期尚早な最適化をする必要はありませんが、クエリが期待と大きく違わない形で処理可能なことを他の人もレビューできる状態にすることが重要です。
- 例えば、 GitHub に添付可能なテキスト形式で得られる
- データの有無によってコストベース最適化によって異なる実行計画が選ばれる場合はありますが、運良く良くなることに期待するのではなく、運悪く悪くなる可能性を想定しましょう。
- 定期的に非効率なクエリの存在をレビューしましょう。
- Query Stats https://cloud.google.com/spanner/docs/introspection/query-statistics
- Query Insights https://cloud.google.com/spanner/docs/using-query-insights
- これらに現れるクエリの種類が多すぎるのであればクエリパラメータが使われていないものがないかを確認しましょう。
- クエリパラメータを活用できていない動的クエリの弊害を受け、実行計画キャッシュにも影響するため、パフォーマンスにも影響があります。 これは公式ドキュメントの SQL ベストクラクティスの Use query parameters や Life of a Spanner Query などにも記述があります。
- 発行される可能性があるクエリが変わった結果不要になって無駄に Write コストだけ掛かっているインデックスがないかどうかは定期的にチェックしましょう。
トレードオフについて
多くの場合 Read(Query) と Write にはトレードオフが存在します。
クエリに必要なセカンダリインデックスは Mutation を使った Write には必要ないため、 Write に最も最適化した選択肢ではセカンダリインデックスは存在しないでしょう。
クエリを最適化するためにセカンダリインデックスを作ったり、そのセカンダリインデックスに更に STORING 列を追加することは Write のコストを上げることになります。
Read のパフォーマンスを高めるには Write を犠牲にすることを単純化すると下のグラフのようになります。
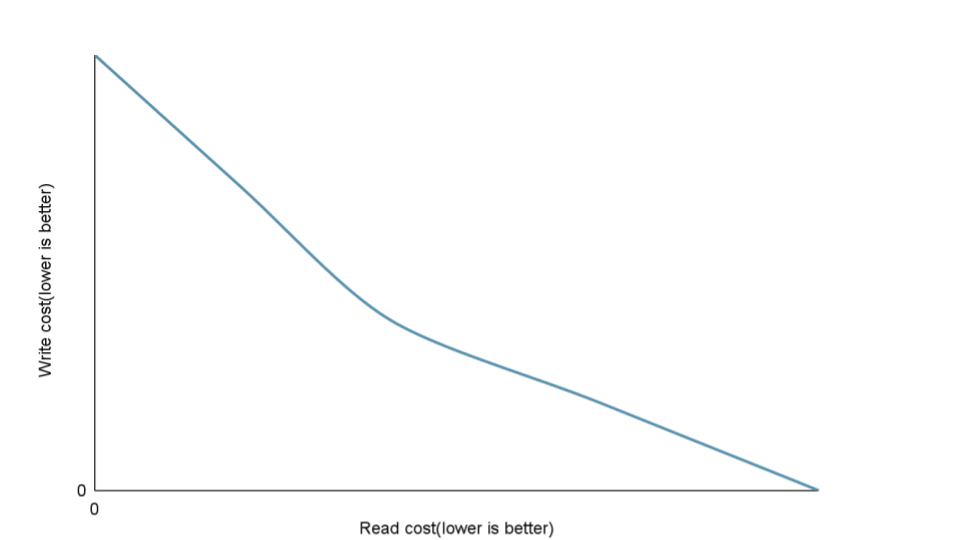
しかし、トレードオフ以前の問題になっている場面はよくあります。先ほどのグラフで言えば、線上の点がトレードオフした上でのそれぞれの最適解だとすれば、それよりも非効率的な選択肢は無数に存在します。
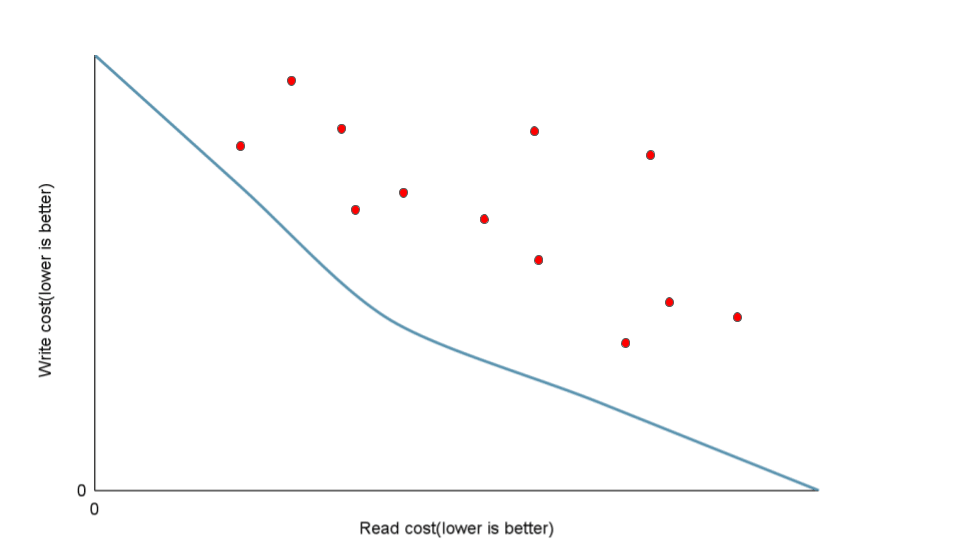
このような非効率な状態となる理由の一部として、クエリで十分に役立たないセカンダリインデックスに Write のコストを掛けているというものがあります。
この記事では、どのようにクエリに最適化することで Write のコストを無駄にせずに、 Read のパフォーマンスを上げられるかについてフォーカスします。
Introspection
How to get query plans and query profiles using spanner-cli
Google 公式の Spanner Studio の実行計画表示はあまり一覧性が高くなくフィルタ述語等のレビューが困難なため、実行計画全体をテキストで共有することを推奨します。
この用途に使うことができるツールとしては下記のようなものがあります。
EXPLAIN (PLAN)
EXPLAIN で実行計画を見ることができます。
spanner> EXPLAIN
-> SELECT LastName
-> FROM Singers
-> WHERE SingerId = 1;
+----+--------------------------------------------------------------+
| ID | Query_Execution_Plan |
+----+--------------------------------------------------------------+
| *0 | Distributed Union |
| 1 | +- Local Distributed Union |
| 2 | +- Serialize Result |
| *3 | +- Filter Scan (seekable_key_size: 1) |
| 4 | +- Table Scan (Table: Singers, scan_method: Scalar) |
+----+--------------------------------------------------------------+
Predicates(identified by ID):
0: Split Range: ($SingerId = 1)
3: Seek Condition: ($SingerId = 1)
クエリの実行やデータアクセスを伴わないため、実行計画の取得は本番環境で行っても安全です。
EXPLAIN ANALYZE (PROFILE)
EXPLAIN ANALYZE を使うことで実行プロファイルを取得できます。テストデータもしくは本番データを使って量的な性能特性を示したい場合はこちらを使いましょう。
spanner> EXPLAIN ANALYZE
-> SELECT LastName
-> FROM Singers
-> WHERE SingerId = 1;
+----+--------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+----+--------------------------------------------------------------+---------------+------------+---------------+
| *0 | Distributed Union | 1 | 1 | 2.24 msecs |
| 1 | +- Local Distributed Union | 1 | 1 | 2.23 msecs |
| 2 | +- Serialize Result | 1 | 1 | 2.23 msecs |
| *3 | +- Filter Scan (seekable_key_size: 1) | 1 | 1 | 2.22 msecs |
| 4 | +- Table Scan (Table: Singers, scan_method: Scalar) | 1 | 1 | 2.22 msecs |
+----+--------------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
0: Split Range: ($SingerId = 1)
3: Seek Condition: ($SingerId = 1)
1 rows in set (4.26 msecs)
timestamp: 2023-06-19T13:04:42.434401+09:00
cpu time: 2.06 msecs
rows scanned: 1 rows
deleted rows scanned: 0 rows
optimizer version: 5
optimizer statistics: auto_20230616_13_28_03UTC
EXPLAIN とは異なりこの機能は実際にクエリを実行します。意図せずに重いクエリを本番環境で実行することがないように気をつけましょう。
Query statistics
Query Statistics を使うことで本番環境で負荷が多いクエリを見つけることができます。
例: 過去7日間からクエリごとの負荷を合計の CPU 負荷順で取得するクエリ
SELECT TEXT_FINGERPRINT,
ANY_VALUE(text) AS text,
ANY_VALUE(request_tag) AS request_tag,
SUM(execution_count) AS execution_count,
SUM(execution_count * avg_cpu_seconds) AS total_cpu_seconds,
SUM(execution_count * avg_bytes) AS total_bytes,
SUM(execution_count * avg_latency_seconds) AS total_latency_seconds,
SUM(execution_count * avg_rows) AS total_rows,
SUM(execution_count * avg_rows_scanned) AS total_rows_scanned,
SUM(execution_count * avg_cpu_seconds) / SUM(execution_count) AS avg_cpu_seconds,
SUM(execution_count * avg_bytes) / SUM(execution_count) AS avg_bytes,
SUM(execution_count * avg_latency_seconds) / SUM(execution_count) AS avg_latency_seconds,
SUM(execution_count * avg_rows) / SUM(execution_count) AS avg_rows,
SUM(execution_count * avg_rows_scanned) / SUM(execution_count) AS avg_rows_scanned,
FROM spanner_sys.query_stats_top_hour
WHERE INTERVAL_END > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY)
GROUP BY TEXT_FINGERPRINT
ORDER BY total_cpu_seconds DESC
結果を共有するために CSV で出力して Google Sheets などのスプレッドシートにインポートするのも一つの方法です。
合計の負荷が大きい順に取得しているため、上位にあるものはどれもパフォーマンス改善上重要なクエリであると考えられます。観点としては下記のようなものがあります。
-
execution_countが非常に大きい。- 単体では負荷とレイテンシは小さくても、細かい改善が負荷に有意な差をもたらす可能性があります。
- クエリ結果の
avg_rowsに対してavg_rows_scannedが2倍以上大きい。- 結果を返すために必要な最低限の行をセカンダリインデックスとテーブルの両方を読んでいる場合よりも多い場合は、無駄にスキャンして処理したあとで捨てられている行がある可能性があります。
- 例外として集約関数を使っている場合は入力の
avg_rows_scannedに対して出力はavg_rowsは少なくなります。
-
avg_cpu_seconds,avg_latency_secondsが大きい。- 単体で負荷が高いクエリは実行時に負荷のスパイクを作る場合があります。
SQL の句ごとの最適化パターン
WHERE
- 原則として、一定以上の行数があるテーブルに対する OLTP 処理ではフルスキャンは許容できないので、実行計画上 Full Scan を見た場合は
WHERE句に対応したセカンダリインデックス等で解消すること。- タイムスタンプや連番など素直にセカンダリインデックスを作るとホットスポットになるカラムをグローバルに検索しなければならない場合にはアプリケーションレベルシャーディングを検討すること。
- 要件を満たすために必要ではないアプリケーションレベルシャーディングの濫用はアンチパターンです。無闇にキー空間上の分布を均等にすることはランダムスキャンに対するレンジスキャンの優位性などを損なう危険があります。
- Commit timestamp optimization が有効になる条件下では、バックジョインを伴うセカンダリインデックススキャンよりも効率的になる可能性があります。ただし、スキャン範囲や他の条件によってはこの限りではありません
- 可能な限り、 back join 後の Table Scan ではなく Index Scan 側でフィルタが処理されるようにセカンダリインデックスに含めること。
- 可能な限り、フィルタがスキャン時にインメモリでフィルタする Residual Condition ではなく Seek Condition で処理できていることを確認すること。
- Seek Condition は連続領域のスキャンとして意味があることを確認すること。
- 例: UserId, CreatedAt DESC に対する
UserId BETWEEN 0 AND 999999999 AND CreatedAt BETWEEN @from AND @toは Seek Condition となり full scan にはならないが、無数の UserId ごとに分割された領域をスキャンすることになるため意味がない。頻度が高い場合は ShardId の導入などで数少ない連続領域のスキャンとして扱えるようにする。
- 例: UserId, CreatedAt DESC に対する
ORDER BY & LIMIT
- 可能な限り ORDER BY の順序と一致する PK もしくはセカンダリインデックスを活用し、 Sort が実行計画上存在しないことを確認すること。
- Spanner のインデックスは逆順ソートができません。
-
LIMITに指定した数を減らした際にスキャンする量も減ることを確認すること。 - もしもインデックス順と一致させることが難しい場合は、インデックス単体で
SORT LIMITを行うことができるようにORDER BYに書かれた列をSTORINGすること。
集約関数 & GROUP BY
- 集約関数 に使われる列はキーの一部か
STORINGの形でセカンダリインデックスに含め、大量の分散 JOIN を回避すること。
可能な限り GROUP BY に指定した列と一致した順序でスキャンすることで、 Hash Aggregate ではなく Stream Aggregate で処理できることを確認する。
JOIN & Anti/Semi JOIN(EXISTS, NOT EXISTS, IN サブクエリ)
- 可能であれば、スキーマ設計の初期の時点で双方のテーブルを INTERLEAVE を活用することによって分散 JOIN 不要にすることを検討する。
- または JOIN 対象となるテーブルと INTERLEAVE されたセカンダリインデックスを使うことで分散 JOIN が回避できるかどうかも検討する。
- それ以外の場合でも Hash JOIN はキーを活用できず巨大なハッシュテーブルの構築を必要とする場合が多いので OLTP には向きません。
- 適切なキーを使った Distributed Cross Apply や Merge JOIN で最適化を試みること。
- 駆動表となる側の行が絞り込めることがわかっている場合は Distributed Cross Apply が良いケースが多いでしょう。Input 側、 Map 側双方をできるだけ最適化することが好ましいでしょう。
- 例えば、 JOIN 条件として使われる列を全てセカンダリインデックスに含めると、最終的な結果として必要がない行のベーステーブルを取得することを避けられます。
- 駆動表がある程度大きく同じ順序の同じ範囲を JOIN する場合であれば Merge JOIN が最適かもしれません。
- 駆動表となる側の行が絞り込めることがわかっている場合は Distributed Cross Apply が良いケースが多いでしょう。Input 側、 Map 側双方をできるだけ最適化することが好ましいでしょう。
- TODO: Push broadcast hash join が最適なケースについて
- 適切なキーを使った Distributed Cross Apply や Merge JOIN で最適化を試みること。
Examples
ここからは実際の実行計画とプロファイル情報を元に解説します。
慣れれば実行計画だけでも読み取れることは多いですが、数で説明した方がわかりやすいと思うので Spanner の公式ドキュメントに含まれるサンプルスキーマ上にランダムに入れたデータを使い解説します。
実行計画状のオペレータの処理については細かくは書きませんが、ある程度は公式にも解説があるので必要に応じて適当に読んでおいてください。
- https://cloud.google.com/spanner/docs/query-execution-plans
- https://cloud.google.com/spanner/docs/query-execution-operators
WHERE
フルスキャンを避け、 Seek Condition になるようにする
フルスキャンがあるクエリは通常データが増えるほど遅くなりますし、 LIMIT があったとしても read-write transaction の中で発行するとそのテーブルの全てをロックします。
そのようなクエリが生まれないように WHERE 句があるクエリはフルスキャンとして処理されていないかどうかを確認しましょう。
ただし、セカンダリインデックスの単純な使用は多くの場合分散 JOIN を発生するため、下記のような場合ではセカンダリインデックスを使ってもパフォーマンスが上がらない可能性もあります。
- 小さく、今後データ量が増えないことが想定されるデータ(例えば100行程度)であれば、範囲スキャンで全て読んでも良いかもしれません。
- 例えばマスタデータなど
- ベーステーブルの多くの割合(例えば x > 20%)を取得するクエリは、セカンダリインデックスとベーステーブルの暗黙の分散 JOIN (バックジョイン) が発生することから、フルスキャンよりも重いかもしれません。
- このようなクエリはそもそも OLTP では処理不可能なので、 BigQuery + Data Boost などのオフロードを検討しましょう。
また、単にクエリがセカンダリインデックスを使っていることを確認するだけでなく、効率的に使えていることを必ず確認しましょう。
Worse
spanner> EXPLAIN
-> SELECT s.SingerId
-> FROM Singers AS s
-> WHERE s.LastName = 'Smith';
+----+-------------------------------------------------------------------------------+
| ID | Query_Execution_Plan |
+----+-------------------------------------------------------------------------------+
| 0 | Distributed Union |
| 1 | +- Local Distributed Union |
| 2 | +- Serialize Result |
| *3 | +- Filter Scan |
| 4 | +- Table Scan (Full scan: true, Table: Singers, scan_method: Scalar) |
+----+-------------------------------------------------------------------------------+
Predicates(identified by ID):
3: Residual Condition: ($LastName = 'Smith')
このクエリはフルスキャンが存在するため、テーブルが大きくなるにつれて遅くなることが想定されます。見るべき点は下記の2つです。
- ID 4 の Table Scan オペレータに
Full scan: trueがある。 - ID 3 の Filter Scan オペレータの Predicates は Residual Condition であり、シーク範囲を狭くするために役立っていない。
Better
下記のようないセカンダリインデックスがあると、実行計画からフルスキャンはなくなります。
CREATE INDEX SingersByLastName ON Singers(LastName);
spanner> EXPLAIN
-> SELECT s.SingerId
-> FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
-> WHERE s.LastName = 'Smith';
+----+------------------------------------------------------------------------+
| ID | Query_Execution_Plan |
+----+------------------------------------------------------------------------+
| *0 | Distributed Union |
| 1 | +- Local Distributed Union |
| 2 | +- Serialize Result |
| *3 | +- Filter Scan |
| 4 | +- Index Scan (Index: SingersByLastName, scan_method: Scalar) |
+----+------------------------------------------------------------------------+
Predicates(identified by ID):
0: Split Range: ($LastName = 'Smith')
3: Seek Condition: IS_NOT_DISTINCT_FROM($LastName, 'Smith')
セカンダリインデックスを使っているかどうかだけでなく、主要なフィルタが Filter Scan オペレータの Seek Condition として処理できているかどうかを確認しましょう。
See also: https://cloud.google.com/spanner/docs/query-execution-operators?hl=en#filter_scan
JOIN 後よりも JOIN 前にフィルタできるようにする
フィルタをセカンダリインデックス側の Seek Condition にはできないとしても、フィルタをセカンダリインデックス側で処理できるようにすることは大きくパフォーマンスを改善させることがあります。
Worse
spanner> EXPLAIN ANALYZE SELECT * FROM Songs@{FORCE_INDEX=SongsBySongName} WHERE SongName LIKE 'A%' AND Duration > 290;
+-----+----------------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+-----+----------------------------------------------------------------------------+---------------+------------+---------------+
| *0 | Distributed Union | 815 | 1 | 163.97 msecs |
| *1 | +- Distributed Cross Apply | 815 | 1 | 163.82 msecs |
| 2 | +- [Input] Create Batch | | | |
| 3 | | +- Local Distributed Union | 16949 | 1 | 15.77 msecs |
| 4 | | +- Compute Struct | 16949 | 1 | 14.38 msecs |
| *5 | | +- Filter Scan (seekable_key_size: 1) | 16949 | 1 | 9.9 msecs |
| 6 | | +- Index Scan (Index: SongsBySongName, scan_method: Scalar) | 16949 | 1 | 7.65 msecs |
| 20 | +- [Map] Serialize Result | 815 | 1 | 114 msecs |
| 21 | +- Cross Apply | 815 | 1 | 113.63 msecs |
| 22 | +- [Input] KeyRangeAccumulator | | | |
| 23 | | +- Batch Scan (Batch: $v2, scan_method: Scalar) | | | |
| 28 | +- [Map] Local Distributed Union | 815 | 16949 | 105.71 msecs |
| *29 | +- Filter Scan (seekable_key_size: 3) | 815 | 16949 | 99.63 msecs |
| 30 | +- Table Scan (Table: Songs, scan_method: Scalar) | 815 | 16949 | 92.02 msecs |
+-----+----------------------------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
0: Split Range: STARTS_WITH($SongName, 'A')
1: Split Range: ($SingerId' = $SingerId)
5: Seek Condition: STARTS_WITH($SongName, 'A')
29: Seek Condition: (($SingerId' = $batched_SingerId) AND ($AlbumId' = $batched_AlbumId)) AND ($TrackId' = $batched_TrackId)
Residual Condition: ($Duration > 290)
815 rows in set (173.22 msecs)
timestamp: 2023-06-21T15:23:13.695614+09:00
cpu time: 165.91 msecs
rows scanned: 33898 rows
deleted rows scanned: 0 rows
optimizer version: 5
optimizer statistics: auto_20230619_14_33_08UTC
Duration カラムはセカンダリインデックス SongsBySongName に含まれていないため、このクエリは 16949行をセカンダリインデックスから読み取った後で、全ての列を取得するために Songs テーブルと分散 JOIN してから Table Scan 側の Filter Scan で Duration のフィルタを行い、最終的な815行の結果を得ています。
つまり、わざわざ分散 JOIN した16000行以上を捨てています。
この例では 170ms 程度で結果が返ってくるので許容可能な場合もあるかもしれませんが、大部分を占める処理が無駄になることはあまり良いこととは言えませんね。
Better
CREATE INDEX SongsBySongNameStoring ON Songs(SongName) STORING(Duration);
spanner> EXPLAIN ANALYZE SELECT * FROM Songs@{FORCE_INDEX=SongsBySongNameStoring} WHERE SongName LIKE 'A%' AND Duration > 290;
+-----+-----------------------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+-----+-----------------------------------------------------------------------------------+---------------+------------+---------------+
| *0 | Distributed Union | 815 | 1 | 16.47 msecs |
| *1 | +- Distributed Cross Apply | 815 | 1 | 16.34 msecs |
| 2 | +- [Input] Create Batch | | | |
| 3 | | +- Local Distributed Union | 815 | 1 | 5.43 msecs |
| 4 | | +- Compute Struct | 815 | 1 | 5.36 msecs |
| *5 | | +- Filter Scan (seekable_key_size: 1) | 815 | 1 | 5.06 msecs |
| 6 | | +- Index Scan (Index: SongsBySongNameStoring, scan_method: Scalar) | 815 | 1 | 4.94 msecs |
| 26 | +- [Map] Serialize Result | 815 | 1 | 9.53 msecs |
| 27 | +- Cross Apply | 815 | 1 | 9.27 msecs |
| 28 | +- [Input] KeyRangeAccumulator | | | |
| 29 | | +- Batch Scan (Batch: $v2, scan_method: Scalar) | | | |
| 35 | +- [Map] Local Distributed Union | 815 | 815 | 8.77 msecs |
| *36 | +- Filter Scan (seekable_key_size: 3) | 815 | 815 | 8.4 msecs |
| 37 | +- Table Scan (Table: Songs, scan_method: Scalar) | 815 | 815 | 7.88 msecs |
+-----+-----------------------------------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
0: Split Range: STARTS_WITH($SongName, 'A')
1: Split Range: ($SingerId' = $SingerId)
5: Seek Condition: STARTS_WITH($SongName, 'A')
Residual Condition: ($Duration > 290)
36: Seek Condition: (($SingerId' = $batched_SingerId) AND ($AlbumId' = $batched_AlbumId)) AND ($TrackId' = $batched_TrackId)
815 rows in set (28.69 msecs)
timestamp: 2023-06-21T15:23:43.307113+09:00
cpu time: 28.27 msecs
rows scanned: 17764 rows
deleted rows scanned: 0 rows
optimizer version: 5
optimizer statistics: auto_20230619_14_33_08UTC
セカンダリインデックスの STORING 列として Duration を追加することができれば、分散 JOIN の件数が削減でき、パフォーマンスを改善できます。
STORING した列はキーの一部ではなく Seek Condition としては処理することはできず、 Residual Condition として読み飛ばして処理する必要があるため rows scanned はこのケースでも17000行を超えており、無駄な処理は残っています。しかし Spanner は連続領域のスキャンは得意なため、リモートコールを伴うランダムアクセスが多い改善前と比較すればパフォーマンスは大幅によくなります。
それぞれのクエリを Seek Condition で効率的にアクセスできるようにしようとするとクエリごとに最適化したセカンダリインデックスの数が増えていき、結果として書き込みコストやメンテナンス性が悪化していく一方です。
それに対し既存のセカンダリインデックスに STORING するカラムを増やすことは ALTER INDEX ADD STORED COLUMN を使うことでセカンダリインデックスの数を増やす必要なく行うことができます。
セカンダリインデックスが増えて分散コミットに参加するスプリット(participants)が増えることに比べれば STORING 列が増えることは大きな書き込みコスト増加ではないため、比較的 Write のコストを上げづらい選択肢と考えることができます。
カバリングインデックスにするところまでは踏み切れないとしても、フィルタで使うカラムは STORING 列に追加することは積極的に選択肢に入れて良いでしょう。
タイムスタンプを使った非効率なスキャンを避ける
タイムスタンプ値は書き込みでのホットスポットを避けるため、グローバルなセカンダリインデックスを避けることがベストプラクティスです。しかし、タイムスタンプによるグローバルなフィルタをしたい場合が珍しくありません。
CREATE TABLE UserAccessLog (
LastAccess TIMESTAMP NOT NULL,
UserId INT64 NOT NULL,
) PRIMARY KEY (UserId, LastAccess);
このテーブルのプライマリキーは UserId ごとにタイムスタンプが設定されているため LastAccess が短調増加であってもホットスポットとならない良い設計となっています。
しかし、このキー設計は UserId ごとにタイムスタンプでフィルタするクエリのみに適しています。ユーザを跨いだタイムスタンプでのフィルタには適しません。
Worse
spanner> EXPLAIN SELECT * FROM UserAccessLog WHERE LastAccess BETWEEN @fromLastAccess AND @toLastAccess;
+----+-------------------------------------------------------------------------------------+
| ID | Query_Execution_Plan |
+----+-------------------------------------------------------------------------------------+
| *0 | Distributed Union |
| 1 | +- Local Distributed Union |
| 2 | +- Serialize Result |
| *3 | +- Filter Scan |
| 4 | +- Table Scan (Full scan: true, Table: UserAccessLog, scan_method: Scalar) |
+----+-------------------------------------------------------------------------------------+
Predicates(identified by ID):
0: Split Range: BETWEEN($LastAccess, @fromlastaccess, @tolastaccess)
3: Residual Condition: BETWEEN($LastAccess, @fromlastaccess, @tolastaccess)
LastAccess のみに対するフィルタではフルスキャンとなっており非効率なことがわかりやすいため、 UserId へのフィルタを追加しているクエリをよく見ます。(ここでは fromUserId と toUserId には UserId が取る値の下限と上限が入ります。)
spanner> EXPLAIN SELECT * FROM UserAccessLog WHERE UserId BETWEEN @fromUserId AND @toUserId AND LastAccess BETWEEN @fromLastAccess AND @toLastAccess;
+----+--------------------------------------------------------------------+
| ID | Query_Execution_Plan |
+----+--------------------------------------------------------------------+
| *0 | Distributed Union |
| 1 | +- Local Distributed Union |
| 2 | +- Serialize Result |
| *3 | +- Filter Scan (seekable_key_size: 2) |
| 4 | +- Table Scan (Table: UserAccessLog, scan_method: Scalar) |
+----+--------------------------------------------------------------------+
Predicates(identified by ID):
0: Split Range: (BETWEEN($UserId, @fromuserid, @touserid) AND BETWEEN($LastAccess, @fromlastaccess, @tolastaccess))
3: Seek Condition: (BETWEEN($UserId, @fromuserid, @touserid) AND BETWEEN($LastAccess, @fromlastaccess, @tolastaccess))
このクエリはフルスキャンではなく、 Seek Condition のみからなるため一見問題ないように見えます。
しかし、 LastAccess BETWEEN @fromLastAccess AND @toLastAccess にヒットする行が大量の UserId ごとに存在するため、パフォーマンスの改善効果は低いアンチパターンであると言えます。
このようなクエリが頻繁に実行されたり、ピーク負荷を構成している場合は最適化の候補です。
Better
例えば、 UserId のハッシュ値を元にした20の値を持つ ShardId を使ったセカンダリインデックスを作ることができます。次のような効果が期待できます。
-
UserIdよりは分散していませんが、最新のタイムスタンプへの書き込みを20に分散させることでホットスポットを回避することができます。- より大きな PU を持つインスタンスで均等に分散させたい場合は
ShardIdを大きくする必要があるかもしれません。
- より大きな PU を持つインスタンスで均等に分散させたい場合は
- 20個に分かれた領域それぞれへの範囲スキャンにすることで、テーブル全体に対するタイムスタンプのフィルタを行うクエリの効率も改善する場合があります。
See also: https://cloud.google.com/spanner/docs/generated-column/how-to?hl=en
ALTER TABLE UserAccessLog ADD COLUMN ShardId INT64 NOT NULL AS (MOD(ABS(FARM_FINGERPRINT(CAST(UserId AS STRING))), 20)) STORED;
CREATE INDEX UserAccessLogByShardIdLastAccess ON UserAccessLog(ShardId, LastAccess DESC);
spanner> EXPLAIN SELECT * FROM UserAccessLog WHERE ShardId BETWEEN @fromShardId AND @toShardId AND LastAccess BETWEEN @fromLastAccess AND @toLastAccess;
+----+---------------------------------------------------------------------------------------+
| ID | Query_Execution_Plan |
+----+---------------------------------------------------------------------------------------+
| *0 | Distributed Union |
| 1 | +- Local Distributed Union |
| 2 | +- Serialize Result |
| *3 | +- Filter Scan (seekable_key_size: 2) |
| 4 | +- Index Scan (Index: UserAccessLogByShardIdLastAccess, scan_method: Scalar) |
+----+---------------------------------------------------------------------------------------+
Predicates(identified by ID):
0: Split Range: (BETWEEN($ShardId, @fromshardid, @toshardid) AND BETWEEN($LastAccess, @fromlastaccess, @tolastaccess))
3: Seek Condition: (BETWEEN($ShardId, @fromshardid, @toshardid) AND BETWEEN($LastAccess, @fromlastaccess, @tolastaccess))
集約関数と GROUP BY
集約対象のカラムを STORING する
Worse
CREATE INDEX SongsBySongGenre ON Songs(SongGenre);
+-----+--------------------------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+-----+--------------------------------------------------------------------------------------+---------------+------------+---------------+
| 0 | Serialize Result | 1 | 1 | 1.5 secs |
| 1 | +- Global Stream Aggregate | 1 | 1 | 1.5 secs |
| *2 | +- Distributed Union | 1 | 1 | 1.5 secs |
| 3 | +- Local Stream Aggregate | 1 | 1 | 1.5 secs |
| *4 | +- Distributed Cross Apply | 13 | 1 | 1.5 secs |
| 5 | +- [Input] Create Batch | | | |
| 6 | | +- Local Distributed Union | 256844 | 1 | 145.19 msecs |
| 7 | | +- Compute Struct | 256844 | 1 | 129.11 msecs |
| *8 | | +- Filter Scan | | | |
| 9 | | +- Index Scan (Index: SongsBySongGenre, scan_method: Scalar) | 256844 | 1 | 79.61 msecs |
| 23 | +- [Map] Local Stream Aggregate | 13 | 13 | 1.1 secs |
| 24 | +- Cross Apply | 256844 | 13 | 1.07 secs |
| 25 | +- [Input] KeyRangeAccumulator | | | |
| 26 | | +- Batch Scan (Batch: $v6, scan_method: Scalar) | | | |
| 31 | +- [Map] Local Distributed Union | 256844 | 256844 | 959.29 msecs |
| *32 | +- Filter Scan (seekable_key_size: 3) | 256844 | 256844 | 867.3 msecs |
| 33 | +- Table Scan (Table: Songs, scan_method: Scalar) | 256844 | 256844 | 729.42 msecs |
+-----+--------------------------------------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
2: Split Range: ($SongGenre = 'ROCK')
4: Split Range: ($Songs_key_SingerId' = $Songs_key_SingerId)
8: Seek Condition: IS_NOT_DISTINCT_FROM($SongGenre, 'ROCK')
32: Seek Condition: (($Songs_key_SingerId' = $batched_Songs_key_SingerId) AND ($Songs_key_AlbumId' = $batched_Songs_key_AlbumId)) AND ($Songs_key_TrackId' = $batched_Songs_key_TrackId)
1 rows in set (1.51 secs)
timestamp: 2023-06-19T14:46:42.066088+09:00
cpu time: 1.5 secs
rows scanned: 513688 rows
deleted rows scanned: 0 rows
optimizer version: 5
optimizer statistics: auto_20230616_13_28_03UTC
Aggregate を Distributed Cross Apply による分散 JOIN 後にしか処理できなくなっているため、集計対象の行数に比例する大量の分散 JOIN が発生しています。
Better
Aggregate Function で使う列を STORING することで分散 JOIN を不要にすることができます。
必要な列をセカンダリインデックスのキーに含めることでも同様の効果を得ることができるかもしれませんが、 STORING は ALTER INDEX ADD STORED COLUMN で既存のセカンダリインデックスに追加することも可能です。使用する列が増えた際にも変更が少なくなりメンテナンス性に優れています。
CREATE INDEX SongsBySongGenreStoring ON Songs(SongGenre) STORING (Duration);
spanner> EXPLAIN ANALYZE
-> SELECT s.SongGenre, AVG(s.duration) AS average, COUNT(*) AS count
-> FROM Songs@{FORCE_INDEX=SongsBySongGenreStoring} AS s
-> WHERE SongGenre = 'ROCK'
-> GROUP BY SongGenre;
+----+------------------------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+----+------------------------------------------------------------------------------------+---------------+------------+---------------+
| 0 | Serialize Result | 1 | 1 | 98.23 msecs |
| 1 | +- Global Stream Aggregate | 1 | 1 | 98.22 msecs |
| *2 | +- Distributed Union | 1 | 1 | 98.22 msecs |
| 3 | +- Local Stream Aggregate | 1 | 1 | 98.2 msecs |
| 4 | +- Local Distributed Union | 256844 | 1 | 81.02 msecs |
| *5 | +- Filter Scan | | | |
| 6 | +- Index Scan (Index: SongsBySongGenreStoring, scan_method: Scalar) | 256844 | 1 | 69.71 msecs |
+----+------------------------------------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
2: Split Range: ($SongGenre = 'ROCK')
5: Seek Condition: IS_NOT_DISTINCT_FROM($SongGenre, 'ROCK')
1 rows in set (101.46 msecs)
timestamp: 2023-06-19T14:47:25.085188+09:00
cpu time: 101.05 msecs
rows scanned: 256844 rows
deleted rows scanned: 0 rows
optimizer version: 5
optimizer statistics: auto_20230616_13_28_03UTC
このように分散 JOIN は不要となり、ハッシュテーブルを作る必要がある Hash Aggregate よりも単純な Stream Aggregate となるため、 STORING する前よりも高速かつメモリ等のリソースの使用量も少なくなります。
ORDER BY & LIMIT
降順ソートには降順インデックスを使う
Worse
他のデータベースではインデックスを逆順に辿ることができるため降順インデックスの概念すら無かったものもあります。しかし、 Spanner はテーブルやインデックスを逆順にスキャンすることはできないため、 ORDER BY 句とは逆順のインデックスしかない場合、必ず明示的なソートが発生します。
CREATE INDEX SongsBySongName ON Songs(SongName);
spanner> EXPLAIN ANALYZE
-> SELECT *
-> FROM Songs@{FORCE_INDEX=SongsBySongName}
-> ORDER BY SongName DESC
-> LIMIT 1;
+-----+---------------------------------------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+-----+---------------------------------------------------------------------------------------------------+---------------+------------+---------------+
| 0 | Global Limit | 1 | 1 | 457.31 msecs |
| *1 | +- Distributed Cross Apply (order_preserving: true) | 1 | 1 | 457.31 msecs |
| 2 | +- [Input] Create Batch | | | |
| 3 | | +- Compute Struct | 1 | 1 | 455.86 msecs |
| 4 | | +- Local Limit | 1 | 1 | 455.85 msecs |
| 5 | | +- Distributed Union (preserve_subquery_order: true) | 1 | 1 | 455.85 msecs |
| 6 | | +- Local Sort Limit | 1 | 1 | 455.84 msecs |
| 7 | | +- Local Distributed Union | 1024000 | 1 | 375.54 msecs |
| 8 | | +- Index Scan (Full scan: true, Index: SongsBySongName, scan_method: Scalar) | 1024000 | 1 | 326.32 msecs |
| 28 | +- [Map] Serialize Result | 1 | 1 | 1.41 msecs |
| 29 | +- MiniBatchKeyOrder | | | |
| 30 | +- Minor Sort Limit | 1 | 1 | 1.4 msecs |
| 31 | +- RowCount | | | |
| 32 | +- Cross Apply | 1 | 1 | 1.39 msecs |
| 33 | +- [Input] RowCount | | | |
| 34 | | +- KeyRangeAccumulator | | | |
| 35 | | +- Local Minor Sort | | | |
| 36 | | +- MiniBatchAssign | | | |
| 37 | | +- Batch Scan (Batch: $v2, scan_method: Scalar) | 1 | 1 | 0 msecs |
| 52 | +- [Map] Local Distributed Union | 1 | 1 | 1.37 msecs |
| *53 | +- Filter Scan (seekable_key_size: 3) | 1 | 1 | 1.37 msecs |
| 54 | +- Table Scan (Table: Songs, scan_method: Scalar) | 1 | 1 | 1.36 msecs |
+-----+---------------------------------------------------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
1: Split Range: ($SingerId' = $sort_SingerId)
53: Seek Condition: (($SingerId' = $sort_batched_SingerId) AND ($AlbumId' = $sort_batched_AlbumId)) AND ($TrackId' = $sort_batched_TrackId)
1 rows in set (500.07 msecs)
timestamp: 2023-06-19T14:13:16.792848+09:00
cpu time: 470.41 msecs
rows scanned: 1024001 rows
deleted rows scanned: 0 rows
optimizer version: 5
optimizer statistics: auto_20230616_13_28_03UTC
この場合 Sort なしに Limit できないため、 LIMIT 1 であっても 1024000行(テストデータ全て)をスキャンしてから Local Sort Limit でソートして捨てていることが分かります。
このようなクエリはデータベースが大きくなるほど重くなるためスケールせず、最適化の候補です。
Better
DESC で ORDER BY するクエリを最適化したい場合は明示的に DESC 順にしたインデックスを定義します。
CREATE INDEX SongsBySongNameDesc ON Songs(SongName DESC);
spanner> EXPLAIN ANALYZE
-> SELECT *
-> FROM Songs@{FORCE_INDEX=SongsBySongNameDesc}
-> ORDER BY SongName DESC
-> LIMIT 1;
+-----+-------------------------------------------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+-----+-------------------------------------------------------------------------------------------------------+---------------+------------+---------------+
| 0 | Global Limit | 1 | 1 | 0.33 msecs |
| *1 | +- Distributed Cross Apply (order_preserving: true) | 1 | 1 | 0.33 msecs |
| 2 | +- [Input] Create Batch | | | |
| 3 | | +- Compute Struct | 1 | 1 | 0.19 msecs |
| 4 | | +- Local Limit | 1 | 1 | 0.19 msecs |
| 5 | | +- Distributed Union | 1 | 1 | 0.19 msecs |
| 6 | | +- Local Limit | 1 | 1 | 0.16 msecs |
| 7 | | +- Local Distributed Union | 1 | 1 | 0.16 msecs |
| 8 | | +- Index Scan (Full scan: true, Index: SongsBySongNameDesc, scan_method: Scalar) | 1 | 1 | 0.16 msecs |
| 23 | +- [Map] Serialize Result | 1 | 1 | 0.1 msecs |
| 24 | +- MiniBatchKeyOrder | | | |
| 25 | +- Minor Sort Limit | 1 | 1 | 0.1 msecs |
| 26 | +- RowCount | | | |
| 27 | +- Cross Apply | 1 | 1 | 0.09 msecs |
| 28 | +- [Input] RowCount | | | |
| 29 | | +- KeyRangeAccumulator | | | |
| 30 | | +- Local Minor Sort | | | |
| 31 | | +- MiniBatchAssign | | | |
| 32 | | +- Batch Scan (Batch: $v2, scan_method: Scalar) | 1 | 1 | 0 msecs |
| 47 | +- [Map] Local Distributed Union | 1 | 1 | 0.08 msecs |
| *48 | +- Filter Scan (seekable_key_size: 3) | 1 | 1 | 0.08 msecs |
| 49 | +- Table Scan (Table: Songs, scan_method: Scalar) | 1 | 1 | 0.08 msecs |
+-----+-------------------------------------------------------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
1: Split Range: ($SingerId' = $SingerId)
48: Seek Condition: (($SingerId' = $sort_batched_SingerId) AND ($AlbumId' = $sort_batched_AlbumId)) AND ($TrackId' = $sort_batched_TrackId)
1 rows in set (9.23 msecs)
timestamp: 2023-06-19T14:18:57.213425+09:00
cpu time: 9.19 msecs
rows scanned: 2 rows
deleted rows scanned: 0 rows
optimizer version: 5
optimizer statistics: auto_20230616_13_28_03UTC
Sort オペレーションは必要なくなり、インデックス順に 1 行だけスキャンすることで ORDER BY と LIMIT 両方の仕事をできるようになりました。
JOIN (TODO)
See also
SELECT
必要に応じてバックジョインを避ける
Spanner のドキュメント上ではセカンダリインデックスからテーブルの行を取得する暗黙の JOIN は back join(邦訳だとバック結合) と呼ばれます。
他のデータベースだとインデックスからテーブルのルックアップに相当するこの back join は分散データベースである Spanner では多くの場合分散 JOIN を意味するため、リモートコールを要し本質的に安価ではありません。
下記も参照してください。
- https://cloud.google.com/spanner/docs/query-execution-plans?hl=en#index_and_back_join_queries
- https://cloud.google.com/blog/products/databases/how-to-use-a-storing-clause-in-cloud-spanner/
Worse
下記の例では SongsBySongName インデックスに含まれていない Duration 列を使おうとすると、 Distributed Cross Apply を使った分散 JOIN (ID: 1) が発生することが実行計画上から確認できます。
CREATE INDEX SongsBySongName ON Songs(SongName);
spanner> EXPLAIN ANALYZE
-> SELECT s.SongName, s.Duration
-> FROM Songs@{force_index=SongsBySongName} AS s
-> WHERE STARTS_WITH(s.SongName, "B");
+-----+----------------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+-----+----------------------------------------------------------------------------+---------------+------------+---------------+
| *0 | Distributed Union | 78940 | 1 | 1.41 secs |
| *1 | +- Distributed Cross Apply | 78940 | 1 | 1.39 secs |
| 2 | +- [Input] Create Batch | | | |
| 3 | | +- Local Distributed Union | 78940 | 1 | 85.15 msecs |
| 4 | | +- Compute Struct | 78940 | 1 | 79.96 msecs |
| *5 | | +- Filter Scan (seekable_key_size: 1) | 78940 | 1 | 53.06 msecs |
| 6 | | +- Index Scan (Index: SongsBySongName, scan_method: Scalar) | 78940 | 1 | 41.13 msecs |
| 20 | +- [Map] Serialize Result | 78940 | 4 | 1.12 secs |
| 21 | +- Cross Apply | 78940 | 4 | 1.09 secs |
| 22 | +- [Input] KeyRangeAccumulator | | | |
| 23 | | +- Batch Scan (Batch: $v2, scan_method: Scalar) | | | |
| 28 | +- [Map] Local Distributed Union | 78940 | 78940 | 1.05 secs |
| *29 | +- Filter Scan (seekable_key_size: 3) | 78940 | 78940 | 1.01 secs |
| 30 | +- Table Scan (Table: Songs, scan_method: Scalar) | 78940 | 78940 | 955.6 msecs |
+-----+----------------------------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
0: Split Range: STARTS_WITH($SongName, 'B')
1: Split Range: ($Songs_key_SingerId' = $Songs_key_SingerId)
5: Seek Condition: STARTS_WITH($SongName, 'B')
29: Seek Condition: (($Songs_key_SingerId' = $batched_Songs_key_SingerId) AND ($Songs_key_AlbumId' = $batched_Songs_key_AlbumId)) AND ($Songs_key_TrackId' = $batched_Songs_key_TrackId)
Better
このようなインデックスからテーブルデータを取得するための分散 JOIN を回避するために、 Spanner でも一般的な RDBMS でもよくあるテクニックを使うことができます。
テーブルから行を取得せずにインデックスから必要な列を全て取得する index-only scan です。
index-only scan にするためにはクエリを変えるか、インデックスを変えるか、その両方の組み合わせを考えることになります。
A: クエリを変え、 SELECT する列を減らす
SELECT する列を減らせば、今あるセカンダリインデックスのままでも back join を不要にできるかもしれません。
DTO や構造体に詰めるために全カラムを SELECT するクエリは多いですが、本当にそのロジックで全ての列が必要でしょうか?
spanner> EXPLAIN ANALYZE
-> SELECT s.SongName
-> FROM Songs@{force_index=SongsBySongName} AS s
-> WHERE STARTS_WITH(s.SongName, "B");
+----+----------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+----+----------------------------------------------------------------------+---------------+------------+---------------+
| *0 | Distributed Union | 78940 | 1 | 51.1 msecs |
| 1 | +- Local Distributed Union | 78940 | 1 | 44.26 msecs |
| 2 | +- Serialize Result | 78940 | 1 | 40.99 msecs |
| *3 | +- Filter Scan (seekable_key_size: 1) | 78940 | 1 | 29.82 msecs |
| 4 | +- Index Scan (Index: SongsBySongName, scan_method: Scalar) | 78940 | 1 | 20.08 msecs |
+----+----------------------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
0: Split Range: STARTS_WITH($SongName, 'B')
3: Seek Condition: STARTS_WITH($SongName, 'B')
B: カバリングインデックスのために STORING を使う
SELECT を含めクエリで使う必要があるカラムが限られているのであれば、クエリが使う全てのカラムを含めた「カバリングインデックス」を作ることを検討すると良いでしょう。
STORING は ALTER INDEX ADD STORED COLUMN によって追加することもできるので、セカンダリインデックスのキー列を増やすよりは容易にメンテナンスできます。
-- Create a new secondary index
CREATE INDEX SongsBySongNameStoring ON Songs(SongName) STORING(Duration);
-- or, you can simply add STORING columns into the existing index
ALTER INDEX SongBySongName ADD STORED COLUMN Duration
spanner> EXPLAIN ANALYZE
-> SELECT s.SongName, s.Duration
-> FROM Songs@{force_index=SongsBySongNameStoring} AS s
-> WHERE STARTS_WITH(s.SongName, "B");
+----+-----------------------------------------------------------------------------+---------------+------------+---------------+
| ID | Query_Execution_Plan | Rows_Returned | Executions | Total_Latency |
+----+-----------------------------------------------------------------------------+---------------+------------+---------------+
| *0 | Distributed Union | 78940 | 1 | 97.91 msecs |
| 1 | +- Local Distributed Union | 78940 | 1 | 88.31 msecs |
| 2 | +- Serialize Result | 78940 | 1 | 83.48 msecs |
| *3 | +- Filter Scan (seekable_key_size: 1) | 78940 | 1 | 68.54 msecs |
| 4 | +- Index Scan (Index: SongsBySongNameStoring, scan_method: Scalar) | 78940 | 1 | 57.19 msecs |
+----+-----------------------------------------------------------------------------+---------------+------------+---------------+
Predicates(identified by ID):
0: Split Range: STARTS_WITH($SongName, 'B')
3: Seek Condition: STARTS_WITH($SongName, 'B')
不要なインデックスの削除
クエリごとに個別に最適化をしていると、同じプリフィックスを持つセカンダリインデックスが増えていくことがあります。
CREATE INDEX SingersByFirstName ON Singers(FirstName);
CREATE INDEX SingersByFirstNameLastNameStoring ON Singers(FirstName, LastName) STORING(BirthDate);
双方のセカンダリインデックスとも FirstName カラムをプリフィックスに持つため、単に FirstName でフィルタするクエリはどちらのセカンダリインデックスを使っても全く同じ実行計画となります。
SingersByFirstName の場合、実行計画は下記のようになります。
spanner> EXPLAIN
-> SELECT *
-> FROM Singers@{FORCE_INDEX=SingersByFirstName}
-> WHERE FirstName = 'Catalina';
+-----+-------------------------------------------------------------------------------+
| ID | Query_Execution_Plan |
+-----+-------------------------------------------------------------------------------+
| *0 | Distributed Cross Apply |
| 1 | +- [Input] Create Batch |
| 2 | | +- Compute Struct |
| *3 | | +- Distributed Union |
| 4 | | +- Local Distributed Union |
| *5 | | +- Filter Scan |
| 6 | | +- Index Scan (Index: SingersByFirstName, scan_method: Scalar) |
| 18 | +- [Map] Serialize Result |
| 19 | +- Cross Apply |
| 20 | +- [Input] KeyRangeAccumulator |
| 21 | | +- Batch Scan (Batch: $v2, scan_method: Scalar) |
| 23 | +- [Map] Local Distributed Union |
| *24 | +- Filter Scan (seekable_key_size: 1) |
| 25 | +- Table Scan (Table: Singers, scan_method: Scalar) |
+-----+-------------------------------------------------------------------------------+
Predicates(identified by ID):
0: Split Range: ($SingerId' = $SingerId)
3: Split Range: ($FirstName = 'Catalina')
5: Seek Condition: IS_NOT_DISTINCT_FROM($FirstName, 'Catalina')
24: Seek Condition: ($SingerId' = $batched_SingerId)
SingersByFirstNameLastNameStoring の場合、実行計画は下記のようになります。
spanner> EXPLAIN
-> SELECT *
-> FROM Singers@{FORCE_INDEX=SingersByFirstNameLastNameStoring}
-> WHERE FirstName = 'Catalina';
+-----+----------------------------------------------------------------------------------------------+
| ID | Query_Execution_Plan |
+-----+----------------------------------------------------------------------------------------------+
| *0 | Distributed Union |
| *1 | +- Distributed Cross Apply |
| 2 | +- [Input] Create Batch |
| 3 | | +- Local Distributed Union |
| 4 | | +- Compute Struct |
| *5 | | +- Filter Scan |
| 6 | | +- Index Scan (Index: SingersByFirstNameLastNameStoring, scan_method: Scalar) |
| 19 | +- [Map] Serialize Result |
| 20 | +- Cross Apply |
| 21 | +- [Input] KeyRangeAccumulator |
| 22 | | +- Batch Scan (Batch: $v2, scan_method: Scalar) |
| 26 | +- [Map] Local Distributed Union |
| *27 | +- Filter Scan (seekable_key_size: 1) |
| 28 | +- Table Scan (Table: Singers, scan_method: Scalar) |
+-----+----------------------------------------------------------------------------------------------+
Predicates(identified by ID):
0: Split Range: ($FirstName = 'Catalina')
1: Split Range: ($SingerId' = $SingerId)
5: Seek Condition: IS_NOT_DISTINCT_FROM($FirstName, 'Catalina')
27: Seek Condition: ($SingerId' = $batched_SingerId)
一般的に、あるクエリをより高速化するためにキーのサフィックスや STORING を増やしたセカンダリインデックスは他のより条件の緩いクエリでも活用可能な傾向があります。
今回の例における SingersByFirstName のような不要なセカンダリインデックスを削除して数少ないインデックスで多くのクエリを処理できるようにすることで、スキーマを単純に保つことが好ましいでしょう。
Cloud Spanner では特に、テーブルに INTERLEAVE されていないセカンダリインデックスを増やすことは two-phased commit による分散コミットの必要性を増やします。
Read のメリットすらないもののために Write のパフォーマンスを悪化させ続けることは避けましょう。
See also: https://cloud.google.com/spanner/docs/whitepapers/life-of-reads-and-writes
Discussion