MTG音声データから議事録を生成するCLIを作った
モチベーション
仕事でMTGの議事録を取る機会がよくあると思いますが、これをAIで非人力化できたら便利ですよね。
そんな時に、Amazon Transcribeという音声データを文字起こしするサービスがAWSにあることを知り、これとOpenAI APIを組み合わせて使えばいい感じに議事録を生成してくれそうだなと思ったため、簡易的なものではありますが作ってみました。
作ってみたもの
.mp3, .wavなどのMTG録音データを
- Amazon Transcribeで文字起こしし、
- 文字起こししたものをOpenAI APIで要約
するCLIです。
Deno/TypeScriptで書いています。
リンクのGitHubリポジトリやDeno Third Party Modulesページから、使用感やインストール方法を見ることができます。
処理の流れ
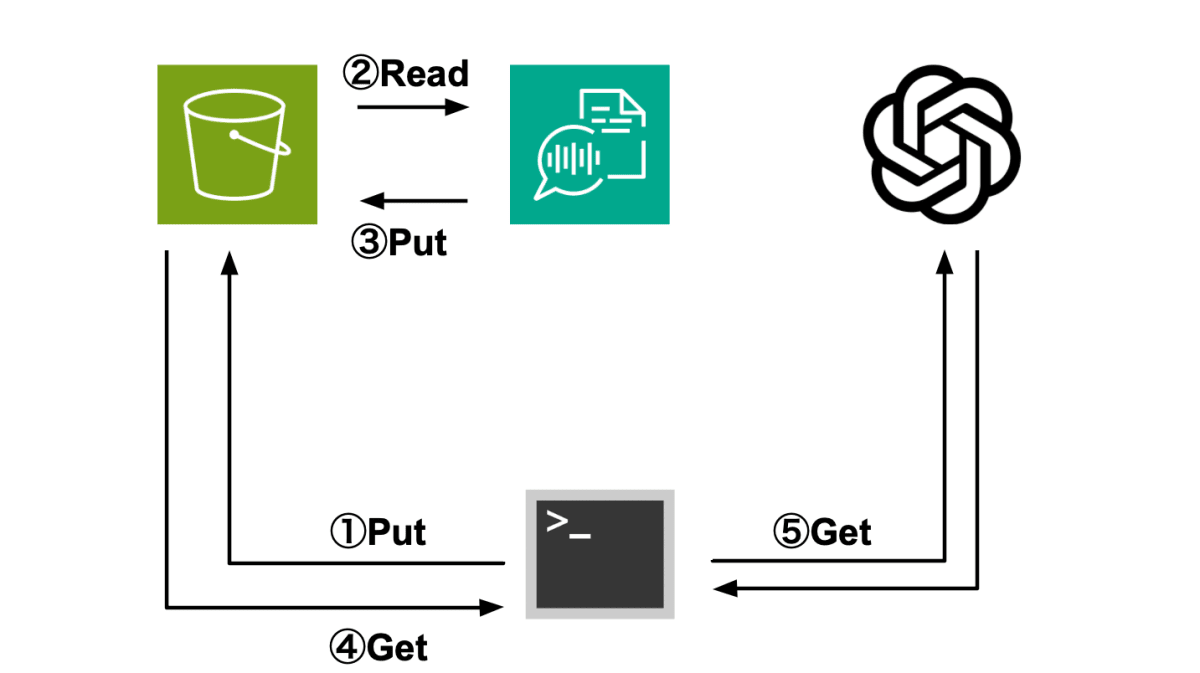
- 音声データをAmazon S3に置く
- Amazon TranscribeがS3から音声データを読み取り、文字起こしする
- 文字起こし結果を再度S3に格納
- S3に格納された文字起こし結果を取得
- OpenAI APIで要約
いいところ
サポート言語が多い
100種類近い言語をサポートしています(2024年4月現在)
といっても自分が使うのは日本語と精々英語くらいですが...
transcriptor --lang='ja-JP' --file='path/to/your/audio/data/to/summarize'
transcriptor --lang='en-US' --file='path/to/your/audio/data/to/summarize'
話者識別ができる
最大10人の話者を識別できます(2024年4月現在)
OpenAIの音声認識・文字起こし用モデルWhisperでは現状単体で話者識別はできないので、
この部分に関してはAmazon Transcribeの方が有利です。
transcriptor --speakerCount='4' --file='path/to/your/audio/data/to/summarize'
(余談)Denoの体験が良い
今回初めてDenoを使ってみたのですが、Node.jsに比べて手間がかからずお手軽に書けるのがよかったです。
一部確かdenoバージョン1.40系でopenaiモジュールが動かなかったのですが、
バージョン1.41に上げたところ問題なく動くようになりました。
それ以外は特に困ったことはなく、CLIを作る分にはdenoで全然問題ないと思いました。
課題
Amazon Transcribeの音声識別精度があまりよろしくない
ここまで書いておいて何なのですが、
Amazon Transcribeの音声認識精度についてはまだまだ改善の余地があるなと感じました。
アナウンサーのようなハキハキした声だと問題なく文字起こしされるのですが、
実際のMTGなどで録音されたボソボソ声や割の長めのセンテンスだと、精度は低くなります。
また、例えば"プルリクエスト"などの一般の会話には出てこない専門的なワードだと、
"プルリーグ"や"プロリーグ"など、他の近しい単語として認識されてしまうことが多く、
議事録としてはちょっと使えないなという結果になってしまうケースも多かったです。
AmazonTranscribeでは上記のような専門的な用語を認識させるために、
カスタム言語モデルをオプションで指定することができます。
トレーニングのために、数個ほどMTGを人力で文字起こししたデータを食べさせてみたのですが、認識できるほどの精度向上は感じられませんでした。
より多くのデータを食べさせると結果が変わってくるのかもしれませんが、それをやると本末転倒感があるので、未だ試せていません...
話者識別はできないですが、音声認識精度自体はOpenAIのWhisperの方が優れているという情報もあったため、今後Amazon Transcribeのみではなく、Whisperなどの他のモデルも使用できるようにしたいと思っています。
おわり
こういったAI系の便利ツールは皆さん各自で作って活用している/しようとしていると思いますが、なにか参考になれば幸いです。
Discussion