WEB好きエンジニアがデータサイエンス入門するのに統計コマンドを作った話
概要
タイトルまんまですが、csvファイルやtsvファイルの何列目かを指定するだけで
その列の統計情報を簡単に確認できるコマンドを作りました。
Colc (Column x Calculation)
動機
普段WEBの世界で生きているエンジニアですが、昨今のAIやらデータの時代だー!に感化され
データサイエンスを意識するようになったのでデータと仲良しになる方法を考えました。
まず統計やら機械学習やらを眺めてみたのですが、どうにも食指が動かない。。。
エクセルやPythonさんとは仲良しではなかったのですorz
そこで最近想いを寄せているWEBの急先鋒Deno様で統計コマンドを作っちゃえば仲良しさんになれるのでは??
そんな目論見からこのColcコマンドを作っちゃいました。
仕様
bash上のhead|tail|cut|sort|awkコマンド群のラッパーとして、動作します。
JavaScriptで大きい数値を扱うのは辛いので、そこはおまかせしました。
またDenoで各コマンドをパイプして実行するという処理が若干分かりにくかったので、
パイプ有無問わず実行したいコマンドをrunメソッドに渡せば、そのまま実行結果を取得できるようにしてます。
(実行に時間がかかる場合の、くるくる回る待機アニメーションがこだわりポイントですw)
使い方
インストール方法
Macユーザーなら、homebrewで簡単にインストールできちゃいます。
brew install solaoi/tap/colc
実行例
- あるテスト結果のcsvファイルがあるとします。
some.csv)
Student,Reading,Writing,Math,Science,Social Studies
A,90,74,33,73,59
B,83,67,84,41,61
C,73,72,80,12,93
D,43,87,67,55,63
E,33,89,97,76,66
- 2列目のReadingの統計情報が知りたいなら、下記コマンドを実行しましょう。
# colc 何列目か ファイル名
colc 2 some.csv
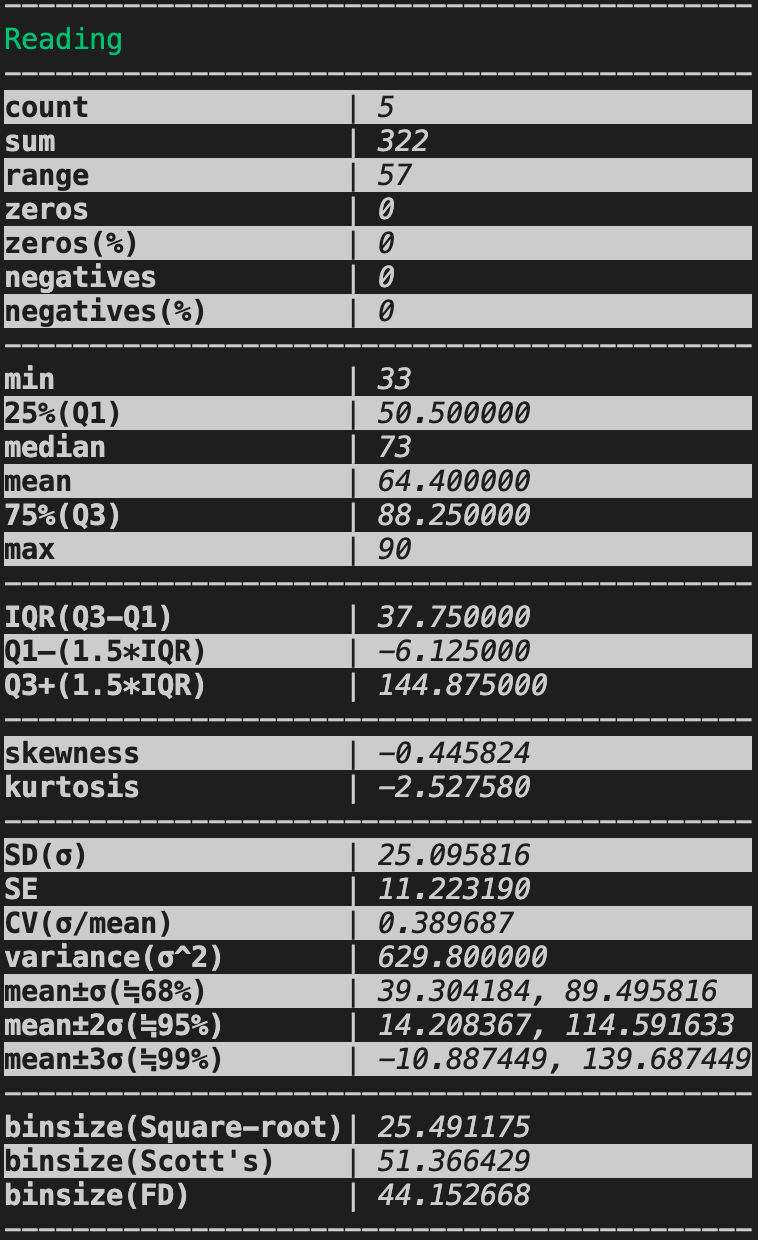
some.csvの2列目の統計情報
- 次に度数分布表やヒストグラムがほしい場合は、
上記統計情報のbinsizeを参考に、階級幅を-bまたは--binsizeオプションで指定して実行しましょう。
colc 2 some.csv -b 25
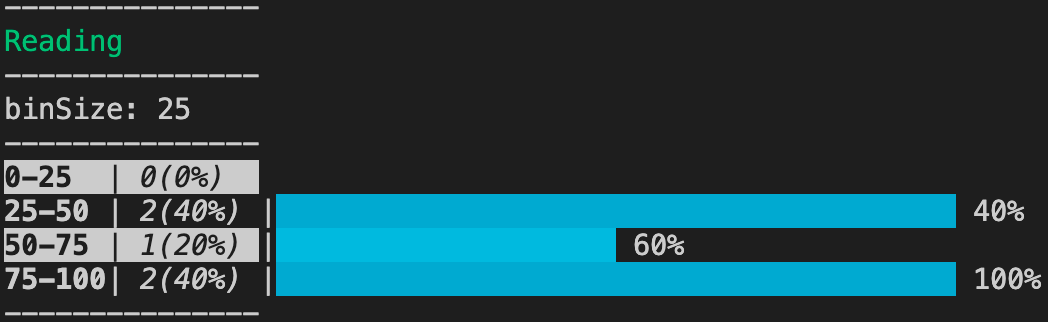
- 指定した列に数値以外のデータが混入していないか心配な場合は、
-cまたは--checkオプションを指定して実行することで確認もできます。
colc 2 some.csv -c
各統計情報について
| Colc上での表記 | 説明 |
|---|---|
| count | 行数 |
| sum | 合計 |
| range | 最大値 - 最小値 |
| zeros | 0の件数 |
| zeros(%) | 全行に占める0の割合 |
| negatives | 負の数の件数 |
| negatives(%) | 全行に占める負の数の割合 |
| min | 最小値 |
| 25%(Q1) | 第1四分位数 |
| median | 中央値 |
| mean | 平均値 |
| 75%(Q3) | 第3四分位数 |
| max | 最大値 |
| IQR(Q3-Q1) | 四分位範囲 |
| Q1–(1.5*IQR) | 外れ値検出ありの箱ひげ図のひげ下限 |
| Q3+(1.5*IQR) | 外れ値検出ありの箱ひげ図のひげ上限 |
| skewness | 歪度 |
| kurtosis | 尖度 |
| SD(σ) | 標準偏差 |
| SE | 標準誤差 |
| CV(σ/mean) | 変動係数 |
| variance(σ^2) | 分散 |
| mean±σ(≒68%) | 正規分布の場合に全体の68%が含まれる範囲 |
| mean±2σ(≒95%) | 正規分布の場合に全体の95%が含まれる範囲 |
| mean±3σ(≒99%) | 正規分布の場合に全体の99%が含まれる範囲 |
| binsize(Square-root) | 階級幅の参考値(平方根選択) |
| binsize(Sturges') | 階級幅の参考値(スタージェスの公式) |
| binsize(Scott's) | 階級幅の参考値(スコットの公式) |
| insize(FD) | 階級幅の参考値(フリードマン=ダイアコニスの公式) |
あとがき
DenoでCLIがこんなに簡単に作れるのに素直に感動しました。
deno compile コマンドだけでバイナリ吐かれるなんて便利すぎますね。
リポジトリ上では、GitHubActionsのWorkflowを使って自動でReleaseのAssetsへの登録と、
Homebrewのtapへの登録もしてるので、良かったら見てみてください。
また、現時点ですでに観念してPythonのJupyterLab内でEDAするために、
pandas-profilingやpivottablejsなど触ってみてますが、ほぼコード書かずに統計情報を表やグラフで見れて改めて感動しました。(matlibplotを最初にみて、コード書くの面倒くさいマンになってました。。。反省)
他にも開発時に必要なスタブAPIを簡単に作れるツールも作っているので、
良かったら、こちらの記事も御覧ください。
参考
Discussion