Alertmangerを用いてPrometheusからSlackにアラートを飛ばしてみる
はじめに
以前書いた記事が思ったより多くの方に読まれているようなので、続編としてAlert Managerについて解説します。Alert Managerを用いることで、サーバーになんらかのエラーが起きたことをリアルタイムで検知することができるようになります。自分も10数台のサーバーを管理していますが、Grafanaを一々見ることなくサーバーの状態を監視することができるので重宝しています。エラーの度合いによって細かく送信するSlackチャンネルを設定できるので、軽微なエラーは管理者のみに送信されるようにして致命的なエラーに発展する前に修正しつつ、致命的なエラーが発生した場合はユーザーにも周知し、使用を控えてもらうなどの対応を取ることができます。
本記事の目標
本記事では、Alert Managerを用いてSlackにサーバーがダウンした時やメモリの使用量が逼迫した時、Slackに通知を飛ばせるようになることを目標とします。公式ドキュメントを読むとわかりますが、Alert Managerは多彩な機能を有しており、連携できるサービスも多数あります。従って、本記事では全てを解説することはせずまずはAlert Managerを使えるようになることを目指します。
前提条件
- 自由に使えるSlack Workspaceを所持していること
- Docker Compose YAMLが読めること
- 読めなくても動きますが、読めた方が理解が深まるので推奨です
- 以前の記事で紹介したいずれかの方法でPrometheusサーバーを構築し、監視サーバーの状態を監視する方法を知っていること
Alert Managerとは
公式ドキュメント
-
Alertmanger
- Alert Managerについて大まかな説明がされています。本記事で解説します。
-
Alerting Rules
- Prometheusで設定する監視ルールについての説明されています。短いので本記事を終えた後にさっと読むことをお勧めします。
-
Configuration
- Alert Managerで設定可能なパラメータや使用可能な正規表現について詳細に説明されています。本記事を終えた後に読むことでより理解が深まると思います。
PrometheusとAlert Managerはそれぞれ異なる機能を分担しています。
- Prometheus : 監視サーバーの状態を常に監視し、監視ルールに該当する事象を確認した場合アラートを送信する
- Alert Manager : Alert Managerは、Prometheusから送信されたアラートを正しいreceiverに送信する。
Alert Managerがサポートするreceiverには、e-mailやSlackはもちろんインシデント管理ツールであるPagerDutyやOpsGenieも含まれています。大規模なプロジェクトにおいては、これらの利用も検討するといいでしょう。本記事では、Slackの利用方法のみについて解説します。
Grouping
Groupingとは、複数のアラートを1つにまとめる機能です。例えば大規模な障害が発生した場合、監視している全てのサーバーがダウンしたというアラートがPrometheusから送信されます。それらを1つのアラートにまとめてSlack等に送信する機能です。発生した事象や事象が発生したサーバーが存在するクラスタなど様々な属性でGroupingを設定することができます。
Inhibition
Inhibitionは、特定のアラートの通知をミュートする機能です。例えば、あるクラスタ全体に関する大規模な接続障害などが発生した場合、そのクラスタ内のサーバーから送信されるその他のアラートは接続障害を要因とするものなので無視されるべきです。
Silence
Silenceは、単純なミュート機能です。設定した時間任意のアラートをミュートします。Silenceは、Alert ManagerのWeb interfaceで設定できるそうですが、自分は利用したことがありません。UIは使いやすそうだったので、必要があれば確認してみてください。
Client behavior と High Availability について
これらは発展的な機能であり、必要がある場合に各々導入してください。
Client behaviorとは、Client側からアラートを送信する際の特別な仕様を定めたものです。
但し、Clientから直接アラートを送信することは推奨されておらず、本記事でもアラートはPrometheusから送信しています。
Alert Managerはクラスタを形成することでHigh Availabilityを実現することが可能です。自分もこれについては深掘りしていないため、Alert Managerにより高い信頼性が必要な場合に各々調べてください。--cluster-* flagsが参考になるかと思います。
Slackの設定
SlackにAlert Managerから通知を送信するには、Webhookというものを設定する必要があります。これは、チャンネルごとに設定されるURLでAlert ManagerがこのURLにメッセージを送信すると、Slackがhandleして自身のチャンネルに送信してくれます。
Slack Appを作成する
Webhookを設定するには、Slack Appを作成する必要があります。いかに大まかな流れを示しますが、よくわからなければ他の方の記事を参考にしてください。
- https://slack.com/workspace-signin でまず自分のワークスペースにブラウザでログインします
- https://api.slack.com/ にアクセスします
- 右上のYour Appsをクリックします
- 緑色のCreate New Appをクリックします
- 今回はデモなので適当に設定してください
- デモアプリのページに行って、Incoming Webhooksというタブを開き、Activateしてください
- 下の方のAdd New Webhook to Workplaceをクリックするとチャンネルが表示されるのでアラートを送りたいチャンネルを選択してください
- Webhook URLが発行されるので、これを以後の設定で用います。複数チャンネルを利用する場合は用途に応じて以上の操作を繰り返してください
Alert Managerを設定する
ディレクトリ構成
本記事では以下のような構成を想定しています。異なる構成で実装する場合は、docker-compose.yml内のパスを適切に変更してください。
.
└── docker-compose.yml
├── prometheus
│ ├── prometheus.yml
│ └── alert.rules.yml
└── alertmanager
└── config.yml
Prometheusに監視ルールを設定する
監視ルールとは、Prometheusがアラートを飛ばす基準のことです。このYAMLファイルで設定した事象が発生した場合、Prmetheusはアラートを送信します。送信されたアラートは、Alert Manager側で処理されSlackなどに送られます。
以下には例として、
- Instance Down : サーバーの死活状況を監視するアラートです。より正確には、Node Exporterの死活状況を監視するため、ポート(default : 9100)を閉じてもアラートが飛びます。
- High Disk Usage : サーバーのHDDの容量を監視するアラートで、この例では90%以上でアラートが飛びます。Root File Systemしか監視していないので、外部ストレージを監視する場合は別途設定が必要かと思います。自分は調べたことがないので知りません。
各パラメータの意味はコメントを読めばわかると思います。コメントに日本語があるのは少し気持ち悪いですが、日本語の解説記事なので所々は日本語にしています。監視ルールを定義するexprは、PromQLというクエリ言語で書かれています。
prometheus/alert.rules.yml
groups: # Alert Group
- name: Instance Down # Alert Name (任意)
rules:
- alert: InstanceDown # Alert Name (任意)(.GroupLabels.alertnameという変数名でAlert Managerから参照できる)
expr: up == 0 # PromQL : サーバーの死活状況に関するクエリ
for: 60m # Duration : exprsがこの時間続いたらアラートを送信
labels: # Alert Managerのreceiverを決定するときに使用するラベル
severity: critical # アラートの重要度や
channel: general-channel # 送信するチャンネルなどを指定する
annotations: # Alert Txt : 事象発生時や回復時のテキスト
firing_text: "Instance {{ $labels.instance }} down" # .CommonAnnotations.firing_textでAlert Managerから参照できる
resolved_text: "Instance {{ $labels.instance }} up" # 同様に.CommonAnnotations.resolved_textでAlert Managerから参照できる
# 以下も同様
- name: High Disk Usage
rules:
- alert: HighDiskUsage # > 90%
expr: 100 - ((node_filesystem_avail_bytes{mountpoint="/"} * 100) / node_filesystem_size_bytes{mountpoint="/"}) > 90
for: 1h
labels:
severity: critical
channel: general-channel
annotations:
firing_text: "Instance {{ $labels.instance }} used more than 90% of Disk"
resolved_text: "Instance {{ $labels.instance }} up"
Alert Managerでアラートを処理する
以下はAlert Managerの設定ファイルです。Alert Managerは、Prometheusから送信されたアラートを処理し、Slackなどに送信します。Alert Managerの設定例は、こちらに記載されています。
alertmanager/config.yml
global: # Global変数
resolve_timeout: 5m # この時間Prometheusから何も送信されなければ回復アラートを送信する
route:
receiver: 'default' # default receiver : アラートがいずれにも分離されない場合、これがアラートを処理する
group_by: ['alertname', 'instance', 'severity', 'channel']
group_wait: 10m # この時間同じグループのアラートを待機し、まとめる
group_interval: 1h # 同じグループのアラートの送信間隔
repeat_interval: 1d # 同じアラートの送信感覚
routes:
- matchers: # チャンネル名で分岐処理
- channel = task-infrastructure
receiver: 'critical-alert' # receiverを選択
routes:
- matchers: # 特定のアラート名で分岐処理(group_waitなどを個別に設定するため)
- alertname = HighDiskUsage
receiver: 'critical-alert'
# High Disk Usageは1,2日で解決しない可能性があるのでインターバルを長めに設定する
group_wait: 10m
group_interval: 1h
repeat_interval: 2d
- matchers:
- channel = alert
receiver: 'warning-alert'
routes:
- matchers:
- alertname = HighDiskUsage
receiver: 'warning-alert'
group_wait: 10m
group_interval: 1h
repeat_interval: 2d
receivers: # Define Each Receiver
- name: 'default' # Nothing
- name: 'critical-alert' # general-channel(任意)というSlackチャンネルにアラートを送信する
slack_configs:
- api_url: 'https://hooks.slack.com/...' # 作成したURLを貼り付け
channel: '#general-channel' # Channel Name (なくてもいい, わかりやすくするために書いている
# 使用可能な変数等を用いてアラートメッセージを作成
title: '{{ if eq .Status "firing" }}[FIRING]{{else}}[RESOLVED]{{end}}
{{ .GroupLabels.alertname }}'
text: '{{ if eq .Status "firing" }}{{ .CommonAnnotations.firing_text }}{{else}}
{{ .CommonAnnotations.resolved_text }}{{end}}'
send_resolved: true # 回復したら回復アラートを送信(boolean)
# 以下も同様
- name: 'warning-alert'
slack_configs:
- api_url: 'https://hooks.slack.com/...'
channel: '#admin-channel'
title: '{{ if eq .Status "firing" }}[FIRING]{{else}}[RESOLVED]{{end}}
{{ .GroupLabels.alertname }}'
text: '{{ if eq .Status "firing" }}{{ .CommonAnnotations.firing_text }}{{else}}
{{ .CommonAnnotations.resolved_text }}{{end}}'
send_resolved: true
Alert Managerを立ち上げる
Docker Compose YAMLを用いた方法を紹介します。バイナリファイルやDockerを用いた方法は、Alert ManagerのGitHubで紹介されているので、どうしてもその方法を用いたい場合はそちらを参考にしてください。個人的には、今後の拡張性や利便性の観点からDocker Compose YAMLを用いることを推奨します。
以前の記事で解説したのでDocker Compose YAMLについての解説はほとんどありませんが、一応コメントは多少つけてあります。
docker-compose.yml
services:
prometheus: # OSS for server/system monitoring
image: prom/prometheus
container_name: prometheus
hostname: prometheus
volumes:
- ./prometheus:/etc/prometheus # Configuration file
- metrics_data:/prometheus # External Storage
ports:
- 9090:9090
restart: always
networks:
- prom
alertmanager: # Alerting for Prometheus
image: prom/alertmanager
container_name: alertmanager
hostname: alertmanager
volumes:
- ./alertmanager:/etc/alertmanager # Configuration file
command:
- --config.file=/etc/alertmanager/config.yml # See GitHub : https://github.com/prometheus/alertmanager
ports:
- 9093:9093
restart: always
networks:
- prom
volumes:
metrics_data:
external: true
networks:
prom:
docker-compose.ymlが存在しているディレクトリで以下のコマンドを実行してください。全てのファイルが正しく配置されていれば起動するはずです。
$ sudo docker volume create metrics_data
$ sudo docker compose up -d
Slackで通知を確認
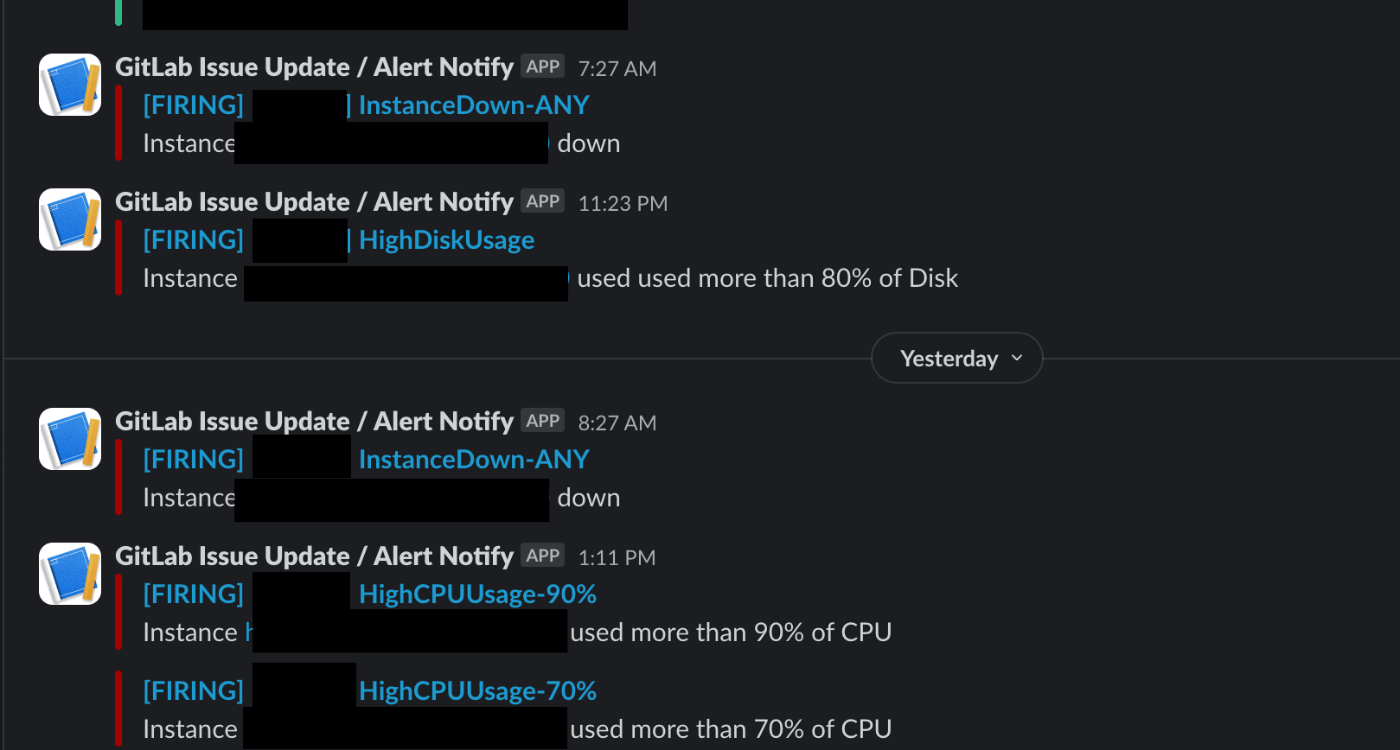
画像は、自分が普段監視しているSlackチャンネルの様子です。ご自身の環境でテストを行いたい場合はテストしたい内容ごとに、それぞれ以下のような方法が挙げられます。
- Instance Down
- サーバーを意図的に落とす
- ネットワークを切断する
- ポートを閉じる(デフォルトは9100)
- High CPU/Memory Usage
- アラートを飛ばす基準を0%以上にする
おわりに
本記事を終えた皆さんはサーバーをいつでもGrafanaで監視できるだけでなく、予期せぬインシデントをSlackでいつでも確認できるようになりました。おめでとうございます!
実際に使ってみるとわかりますが、意外とサーバーというものはインシデントに直面します。特に自分場合は研究室の機械学習用の計算資源としてサーバーを提供しているのですが、1週間に1回はなんらかのアラートが飛んできます。そんな時にAlert Managerがあるとリアルタイムで問題を確認できるので、原因を特定しやすくて助かっています。
今回の記事を執筆するにあたってPrometheusの公式ドキュメントを改めて読み直したのですが、実装当初は全く理解していなかった概念やツールなどが存在することを知り、新たな学びになりました。特にインシデント管理ツールなどというインシデントの管理に特化したツールの存在などは初めて知りました。今まではSlackでインシデントを検知するだけで満足していましたが、今後はより効率的にインシデントを管理する方法を学び記事にしていきたいと思います。
参考
-
Prometheus Alertmanager Best Practices
- Alert Managerのベストプラクティスが説明されています。本記事はAlert Managerを使えるようになることだけを目標にしているので、より実際的な実装はこちらが参考になると思います。
-
Routing tree editor - Prometheus
- Alert Managerの
config.ymlをペーストすると、レシーバーのルーティングツリーを描いてくれます。ファイルを書き終えた後にきちんと想定通りのツリーになっているか確認することができます。
- Alert Managerの
Discussion