はじめに
この記事は any Product Team Advent Calendar 18日目の記事です。
こんにちは。anyの荒川です。弊社のこましりchatという機能(RAG)に対する実験管理を、LangSmithとStreamlitを組み合わせて社内アプリとして構築したのでその紹介をしたいと思います!🙏
もともと抱えていた課題
こましりchatは、Qastに溜まった社内のドキュメントを、いわゆるRAGの仕組みを介して、自然言語での質問に対して回答を得ることができます。
RAGの精度向上が生命線となるほどプロダクトにとっても重要なわけですが、 RAGの改善に対して精度検証(いわゆるオフライン評価)を自動化する仕組みがありませんでした。
テストケースを用意し、ケースごとに回答を得て、それらを評価するという一連のサイクルを手動で行うのは非常に手間がかかります。
こういった実験管理を楽にしたいという想いと、定量的スコアリングを導入するという二つの目的を叶えるため、LangSmithとStreamlitを組み合わせて、PoCの社内アプリを構築しました。
 エンジニア発信のProblemからTry!
エンジニア発信のProblemからTry!
LangSmith / Streamlit について
LangSmithはLangChain社のLLMOpsのためのプラットフォームです。実行のトレース、プロンプトの試行錯誤などの機能がありますが、弊社では特にLangSmithを「実験管理」の観点で導入をしてみたので、この記事ではそちらについて紹介します。
また、StreamlitはPythonのWeb UIフレームワークの一種で、非常に直感的なコードでUIを作成することができます。
どういったフレームワークかは実例を見てもらう方が早いので、下記のようなテキストボックスとボタンというシンプルなWebアプリケーションを作成したい場合...

下記のようにコードを書けば良いだけです!🎉
def run(self):
st.title("Qast AI Scoring Platform")
col1, col2 = st.columns(2)
with col1:
num_repetitions = st.number_input("実験回数", min_value=1, max_value=3, value=1, help="同一のデータセットに対してスコアリングする回数")
with col2:
dataset_name = st.text_input("データセット名", help="LangSmith上のデータセット名を入力します")
if not st.button("Evaluate!"):
return
if not dataset_name:
st.error("データセットを入力してください")
return
with st.spinner('実行中...'):
evaluator = LangSmithEvaluator(team, workspace_id, login_identifier, login_password)
experiment_results = evaluator.run(num_repetitions, dataset_name)
テキストボックスに対して「数値しか入力させない」や「未入力を許さない」の時のバリデーションなども直感的に作成できます。
StreamlitはあくまでもLangSmithのフロントエンドとしての利用になりますが、PoCレベルのWebアプリケーションとして最速で実装ができる点を気に入っています。
アプリケーション / インフラ構成
さて次に使い方を紹介します。まずはLangSmith上に「質問」「想定回答(Ground Truth)」のデータセットを事前に準備しておきます。

そしてStreamlit上のWebアプリケーションから「Evaluate」を実行すると用意したデータセットに対してQastのアプリケーション上から回答を得ることができます。Streamlit上では Pandas の dataframeを st.dataframe メソッドで直接描画できるため、下記のように表としてそのまま出力ができるので、LLMのエコシステムと相性が良いです。

そして結果はすべてLangSmith上にも保存されます。そして蓄積されたデータセットに対する結果同士を比較することも可能です!データセットに対して一括で回答を得られるだけではなく、想定回答とのコサイン類似度などもはかることができるのですが、今回は都合上割愛しております🙏

アプリケーションはAWS Fargate上に社内限定公開アプリとして公開されています。Streamlit上のWebアプリケーションでLangSmithの evaluate メソッドを呼ぶと、そのなかで弊社のRAGであるこましりchatにアクセスされ、その実験結果をLangSmithに登録します。非常にシンプルなのですが、データセットに対して一気に処理を実行できるようになりました🥳

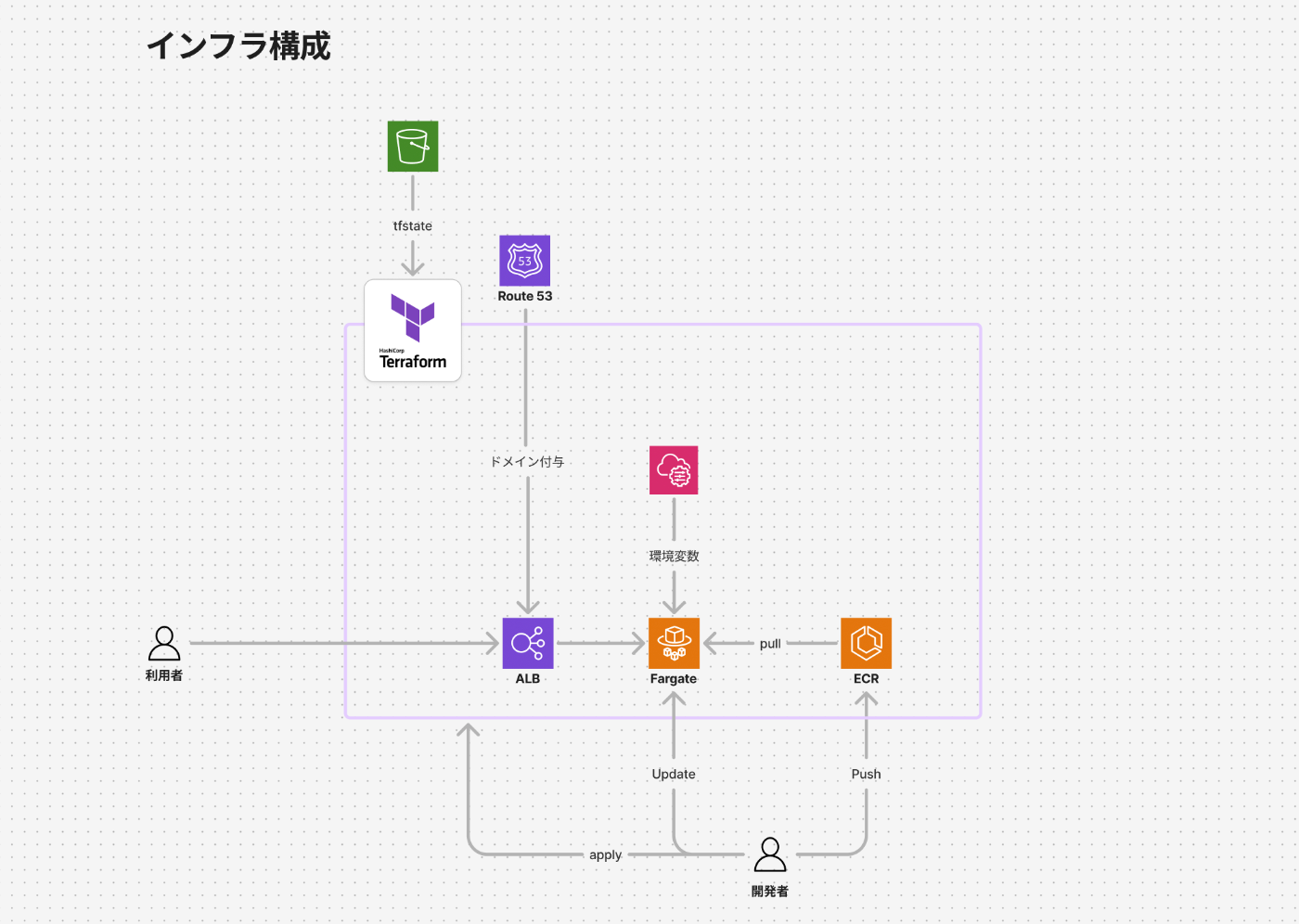
インフラ構成もAWS環境におけるアプリケーションは下記の構成でデプロイをしています。取り立てて特別な構成ではないですが、Terraformで構築されています。
導入してみて
LangSmithとStreamlitのおかげで、ざっくり2,3日程度で仕組みの構築ができました。
テストケースをLangSmith上で作成すれば、それで一括でRAGの回答を得ることもでき、また定量的な指標を計算できる体制が整いました。
一方で課題もあります。例えば、
- Jupyter notebook上などでハイパラやプロンプトを変更して実行できる仕組みを作りたい。いまはQastのAIサーバのデプロイが必要になってしまう
- こましりchatは社内ドキュメントを取り扱うため、オフライン評価の定量化指標をどのように構築していくかに試行錯誤中
- QastではLangChainを利用しているものの、クセも強いためどの程度依存するかをいまだに迷っている
- 実験管理の知見がなかったため、LangSmithからトライを進めたが、Langfuseなども試してみたいところ
という課題もあります。改善ポイントはたくさんありますし、実験管理に対する知見も溜まったため、LangSmithではない選択肢も入れてアップデートしていく必要がありそうです🤲
さいごに
弊社はLLMアプリケーションの運用や精度検証なども非常に盛んな開発現場で、また最先端のRAGを追求していくことができるエンジニアリング的なチャレンジできます。
先日、シリーズBで資金調達もしました!これで一気にエンジニアリングを加速させていきたいので、ぜひカジュアル面談などからよろしくお願いします!

Discussion