何度調べてもわからないDOMに決着をつける
はじめに
これまでやっぱりwebpackがわからない(エピソード1)、エピソード2、そもそもnpmからわからないを公開してきましたが、今回も分かりそうで分かっていない、DOMに関して説明したいと思います。
インターネット上には、既にDOMに関して詳しく説明しているコンテンツがあり、代表的なものが以下となります。
この2つは日本語訳もあり、DOMに関する多くの記事がこれをパクって参考に、またはオマージュして書かれています。言っている僕も、このコンテンツには大変お世話になりました。また、そもそも公式ドキュメントがありますので、本来ならば、これからの駄文を読む必要はないのですが、それでもわからないのがDOMです。そして、DOM(というよりJavaScript)の恐ろしいところは、理解していなくてもコピペなどで何となく結果が返ってくることです。
ですが、もちろんそのような事実はよくありません。この記事は、getElementById()の結果に値を入れて表示が変わらないと嘆かなくてもよくなるためのものです。
DOMとは
DOMとは何なのか?これを正確に答えられる人は少ないのではないでしょうか。では、公式ドキュメントを見てみましょう。
The Document Object Model (DOM) is a programming API for HTML and XML documents. It defines the logical structure of documents and the way a document is accessed and manipulated.
日本語訳:Document Object Model(DOM)は、HTMLまたはXML文書のためのプログラミングAPIです。ドキュメントの論理構造と、ドキュメントへのアクセスや操作の方法を定義しています。
つまり、DOM(Document Object Model) とはHTML(またはXML)ドキュメントに関するAPIで、ドキュメントをどのような構造にして、どのように操作するかを定義したものです。 例えるならMVCモデルのようなもので、MVCモデルはModel、View、Controllerに分けるよという定義があるだけで実態はいません。各々がその定義に従って構築し、その構築したものもMVCと呼ばれます。DOMも同じで実態はいません。定義された通りに実装すれば、それもDOMと呼ばれます。DOMをややこしくしているのが、その実装したものをDOMと呼ぶことです。せめて実装したものはモデルを外してDOと呼べば、この辺りの事情が分かりやすいのですが……。
このDOMが何を定義しているかというと、主にインタフェースです。HTML(またはXML)ドキュメントの各構成要素をオブジェクトにするのですが、この定義されたインタフェースを実装して、そのオブジェクトを操作できるようにしなさいよと。ただし、各々が勝手な名前で勝手な結果を出したら統一がとれないので、インタフェースの名前と結果だけは言う通りにしてね、それさえ守ればどのように実装してもいいよ、ということです。この定義に従ってDOMを実装するのですが、ではどこに実装するのでしょうか。そう、代表的なのがウェブブラウザーです。
ウェブブラウザーは、その定義をもとにインターフェースを実装しています。ウェブブラウザーはHTMLドキュメントを読み込むと、そのHTMLの各構成要素を、それらに該当するインターフェースを実装して、それぞれをオブジェクト化します。こうしてできたオブジェクト群がDOMです。そして、ドキュメントを画面に表示する際、HTMLドキュメントを直接解読して表示するのではなく、このDOMをもとに画面表示します。つまり、HTMLドキュメントはデータの取得にだけ使用され、画面表示やその後の表示変更などは、DOMを使用して行われます。
また、HTMLドキュメントは木構造モデルの構成をしていますので、それを元に作られるオブジェクトも木構造モデルの関連性にすることができます。したがって、このオブジェクトはHTMLを構成する各パーツ全てを操作することが可能となります。また、この木構造モデルを一般的にはDOMツリーと呼びます。
つまり、まとめるとDOMと呼ばれるものは、大きく分けて次の2種類となります。
- 公式ドキュメントで定義されているAPIの定義
- 定義されているAPIを具現化したオブジェクト
なぜDOMを使うのか
JavaScriptの歴史でも書きましたが、1997年頃の各ウェブブラウザーは、各々独自のスクリプトでHTMLを操作していました。これではウェブ開発者側は、それぞれのプログラムを作成しなければいけないので大変です。そこで1998年にW3CからDOMが勧告されます。これには、Aという機能はBという結果を返してねとだけ決められており、各ウェブブラウザーは、内容はどうでもいいのでそうなるように実装するだけです。そうすることにより、XブラウザーでもYブラウザーでも、Aという機能を使用すると同じBという結果を得ることができます。何度も言うようですが、機能名と結果が同じならいいだけで、その過程は自由です。
ここで疑問なのは、ウェブブラウザーが別でも同じJavaScriptを使用しているのなら、同じ処理があり、同じ結果なのではということです。これも、JavaScriptの歴史で書いていますが、各ウェブブラウザーは、これまたECMAScriptという仕様に則ってスクリプトを搭載しています。そして、そのECMAScriptには、ドキュメント操作の取り決めはされていません。したがって、DOMという別の仕様で取り決めをして、JavaScriptはそれを介してドキュメントを操作します。
何でそんな面倒なことをと思うかもしれませんが、逆にこのようなウェブブラウザー事情は親切です。例えば、WindowとMac、iOSとAndroid、ExcelとNumbersなど、同じような内容で開発できるものはあまりありません。
DOMの定義
以前はW3CがDOMの策定をしていましたが、現在はWHATWGがLiving Standardとして定義しています。これは、特定のウェブブラウザやプログラム言語への定義ではありません。つまり、JavaScript特有のものでないので、IDL(Interface description language)という特殊な言語で定義されています。
W3C DOM4
DOM Living Standard
DOM Living Standard 日本語訳
例えばDOMで定義されているgetElementById()というメソッドの、WHATWGが定義している箇所を確認してみましょう。
The getElementById(elementId) method steps are to return the first element, in tree order, within this’s descendants, whose ID is elementId; otherwise, if there is no such element, null.
簡単に訳すと「getElementById()は、子孫の中で該当するid属性を持つ最初の要素をツリー状で返す」という内容です。つまり、結果がこうなるように実装してくださいよと言っているだけで、どのように実装するかは実装する側にゆだねられています。
各環境におけるDOM
前述しましたが、DOMはWHATWGがDOM Standardという標準仕様を策定しており、W3Cで策定されたDOMに関する定義を包括し、更新しています。そして各ベンダーは、それに沿ってDOMを実装しています。このベンダーとは、ウェブブラウザの提供者だけではなく、PythonやPHPなどのプログラム言語の提供者も含まれます。したがって、前述した通りDOMは特定のウェブブラウザやJavaScriptだけで使用されるものではありません。
例えばPythonやRuby、PHPなどにもライブラリなどが存在し、DOMは使用できます。もちろん、これらはサーバ側で動作しますので、ウェブブラウザに実装されているJavaScriptのように、リアルタイムでクライアントサイドのHTMLを操作することはできません。主に取得したHTMLドキュメントを分析する、例えばスクレイピングなどに利用します。それでいうと、ウェブブラウザにおけるJavaScriptとはDOMを操作するためにあるといっても過言ではありません。したがって、JavaScriptを学ぶ際にDOMを理解することは、非常に重要なことになります。
なぜJavaScriptで操作するのか?
ウェブブラウザのDOMをJavaSctriptで操作するのは、ウェブブラウザがJavaScriptを実装しており、JavaScriptで操作ができるようにDOMを実装しているからです。例えば、ウェブブラウザがPythonを実装してPythonで操作ができるようにDOMを実装すれば、もちろんPythonで操作できます。ただし、そのような特殊なウェブブラウザを開発したとしても、余程のシェアがない限りウェブサービスなどの開発側は、それに合わせて開発を行うことはないでしょう。仮に業界での標準にしようとしても、ただでさえ大変な標準化作業を、別のプログラム言語で策定し直すのは現実的ではありません。このようなことから、ウェブブラウザでのDOMの操作は、長年JavaScriptで行うようになっています。
クロスブラウザ
ウェブサイトなどが、複数のウェブブラウザでも同じ対応をすることをクロスブラウザ(cross-browser) と言います。DOMの使用に強制力はないので、各ウェブブラウザはDOMを独自に定義して実装する、または実装しないということが可能(自由)です。これはHTMLやJavaScriptのある処理が、一方のウェブブラウザでは動作するがもう一方では動作しないということに繋がります。このように、クロスブラウザが損なわれる問題が発生しやすくなり、これを解決するためにjQueryなどが開発されました。
現在、各ウェブブラウザはDOMの定義に準拠した実装を進めており、このような非互換性問題も解消されつつあり、jQueryなどのライブラリの必要性も薄れてきました。一方、DOMの操作の複雑さや再構築にかかる時間などが問題視されるようになり、仮想DOMを実装するReactなどが主流になりつつあります。
DOMツリーの作成
DOMツリー作成までの手順は、次となります。
HTMLドキュメントの取得
ウェブブラウザーがウェブサーバにリクエストを行うと、3ウェイ・ハンドシェイクという手順でTCPコネクションという通信を確立させ、データをダウンロードします。その時に受け取るデータは、未加工のバイトデータです。これを、データのContent-Typeに指定されているUTF-8などのエンコードに基づいて、HTMLドキュメントに変換します。
3C 64 2F 72 70 3E 48……
↓ ↓ ↓
<!DOCTYPE html>
<html>
<head>
<title>テストサイト</title>
</head>
<body>
<h1>見出しです</h1>
<!-- コメント -->
<p>こんにちは!</p>
</body>
</html>
トークン化
HTMLドキュメントの文字列をW3CのHTML標準に基づいて、トークン化します。トークン(token) とは、プログラミングではデーターを最小の構成単位に分解した物のことをいい、ウェブブラウザーに限った処理ではありません。ソースコードをコンパイルするため、プログラムの構造を知るために行われます。つまりこの場合、HTMLドキュメントの各構成要素をオブジェクトにするためにトークン化します。
HTMLのトークンは簡単で、ドキュメントを1文字づつ読んでいき、<から>までを開始タグ、</から>までを終了タグとします。この調子でテキスト、コメント、タグ外のスペースと改行などの全てをトークン化できます。HTMLって単純なようでよくできていますね。
StartTag: html、StartTag: head、StartTag: title、Character:テストサイト、EndTag: title、……
もしHTML内に間違った要素(例えば閉じタグを忘れた)などがあった場合、よしなに修正して、トークン化します。HTMLに多少ミスがあっても、正常に表示されるのはこのためです。ただし、意図しない修正となる場合もあるので、正確な記述を心がけましょう。
また、2つ特別なルールがあります。
-
<head>の前のスペースは無視されます。 - HTMLは通常
</body>の後ろには何も設置しませんが、もし設置されていたら、自動で</body>の中に移動させます。
オブジェクト化
トークン化されたものを基にオブジェクト化します。したがって、コメントやホワイトスペース(空白文字)を含む、全ての構成要素がオブジェクトに変換されます。 以下の1つ1つがオブジェクトです。
DOCTYPE: html、HTML、HEAD、#text:、TITLE、#text: テストサイト、#text:、#text:、BODY、
#text:、H1、#text: 見出しです、#text:、#comment: コメント、#text:、p、#text: こんにちは!、#text:
この各オブジェクトは、インターフェースを実装して作成されます。これに関しては、後ほど詳しく説明します。
DOMツリー
作成されたオブジェクトは、元は木構造モデルのHTMLですので、その関連性を示してやることができます。そのために、各オブジェクトのプロパティで、子オブジェクトは~オブジェクト、親オブジェクトは~オブジェクトなどのように参照します。
すると、以下のような木構造として表現することができます。
├DOCTYPE: html
└HTML
├HEAD
│ ├#text:
│ ├TITLE
│ │ └#text: テストサイト
│ └#text:
├#text:
└BODY
├#text:
├H1
│ └#text: 見出しです
├#text:
├#comment: コメント
├#text:
├p
│ └#text: こんにちは!
└#text:
各オブジェクトは、先ほど説明をしたオブジェクトへの参照を持っていますので、例えば、○○要素の子要素などと指定することで、DOMツリーを漏れなく辿っていけます。このように、木構造モデルなどを漏れなく辿っていくことをトラバーサル(traversal) と言います。
木構造モデル(tree structure) はルート(root:根)を頂点とし、ノード(node:接点)とそれらを結ぶエッジ(edge:枝)から構成され、DOMではDOMツリー(DOM Tree) と呼ばれます。木をひっくり返して見ているイメージです。上の例でいうとDOCTYPE: htmlがルートで、ルートを含む全てのオブジェクトがノードです(edgeは概念的なものとなります)。特にDOMではこれらオブジェクトのことをノードと表現します。
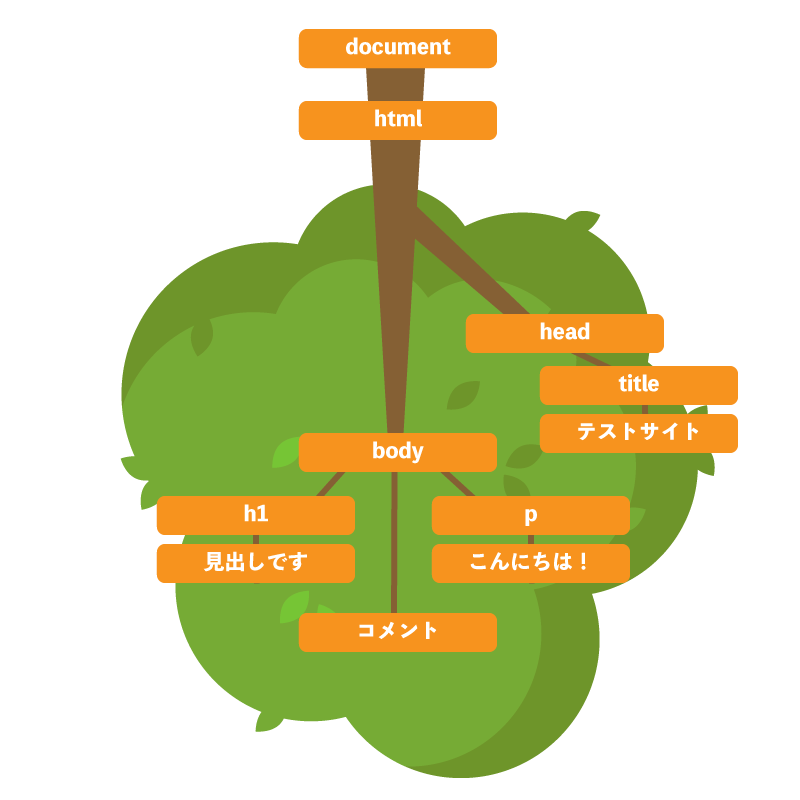
木構造モデルのノードにおいて、直接の配下にあるノードを子ノード(child node) といい、さらにネストされた先のノードを子孫ノード(descendant node) といいます。また、子ノードから見た上のノードは親ノード(parent node) であり、同じ親ノードを持つノードを兄弟ノード(sibling node)、親ノードを遡った全てのノードを先祖ノード(ancestor node) といいます。
なお、DOMツリーは管理者ツールで確認することができます。chrome DevToolsならElementsタブで確認できます。そして、ノードを選択することができます。コンソールでは、最後に選択したノードは$0、その前に選択したノードは$1となります。例えば、次は選択したノードをコンソールに表示します。
console.dir($0);
したがって、コンソール上でそのノードに対してAPIを実行できます。
※ ノードの内容はElementsタブのpropertiesからも確認できます。
CSSOM
DOMツリーを構築中にCSSの記述、またはCSSファイルへの参照があると、その時点でDOMと同じようにCSSOM(CSS Object Model: シー・エス・エス・オー・エム) を作成します。
CSSOMの構築中もDOMの構築は進行されます。ただし、CSSOMが構築されなければ、後述するレンダーツリーの構築ができず、レンダリングの処理が遅れてしまいます。このように、レンダリングの処理を遅らすことをレンダーブロッキング(Render blocking) といい、CSSのようにレンダーブロッキングを行うリソースをレンダーブロッキングリソース(Render blocking resource) といいます。CSSファイルが大きいほどレンダーツリーの構築が遅れてしまい、結果、表示が遅れます。対策としては、ファーストビューに関するCSSだけを通常読み込みさせ、それ以外のCSSはレンダーブロッキングが行われない遅延読み込みで対応するなどの方法があります。
なおメディア属性などで条件がある場合、その条件が発生するまでレンダーブロッキングは発生しません。例えば、以下はページを読み込んだ段階ではレンダーブロッキングは発生しません。
<link href="test.css" rel="stylesheet" media="orientation:portrait">
<link href="test.css" rel="stylesheet" media="print">
CSSOMの構造
CSSはCascading Style Sheetsの略ですが、CSSOMはこのカスケード(cascade) という概念で構成されます。カスケードとは「連続した小さな滝」という意味があり、CSSOMは上のノードの設定を下のノードが継承します。そして、下のノードで同じ設定があると、それが上書きされます。CSSは要素が入れ子になるほど優先度が高くなるのは、このためです。
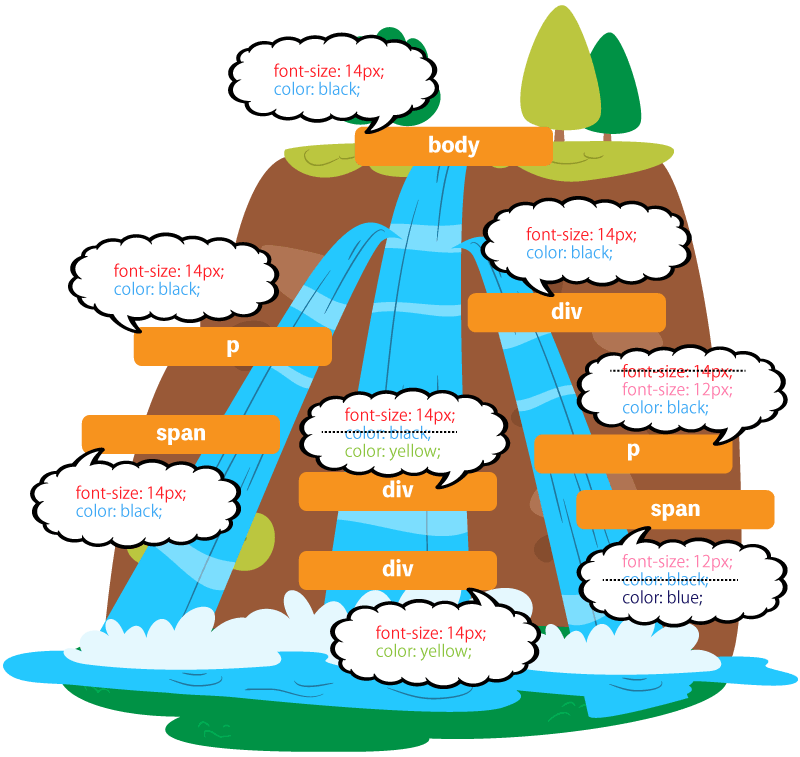
なお、各ウェブブラウザには、user agent stylesheetというデフォルトの設定があり、CSSの設定はそれをオーバーライド(再度定義)することになります。user agent stylesheetは、管理者ツールのElementsタブでStylesを確認すると、CSS file nameではなくuser agent stylesheetと記載されています。これを無効化するために設定するCSSが、いわゆるリセットCSSと呼ばれるものです。
JavaScript
JavaScriptは、その記述された場所で実行されます。つまりHTMLパーサー(ウェブブラウザが備えている、HTMLを解読する機能)がJavaScriptのソースコードに到達すると、DOMの構築を一時中断して、JavaScriptエンジンに制御を渡します。JavaScriptがその時点でのDOM、CSSOMの変更などの処理を完了させると、中断された位置に戻り、DOMの構築を再開します。このようにパーサーの処理を中断させるリソースを、パーサーブロッキングリソース(Parser blocking resource) といいます。JavaScriptの処理が大きくなるほど、中断される時間も大きくなり、外部のjsファイルを使用する場合、その読み込み時間も中断時間に含まれます。
また、JavaScriptは記述される(読み込む)場所が非常に需要となります。例えば、処理を行いたい要素の前に記述すると、その要素のノードはまだ作成されていませんので、処理を行うことができません。したがって全ての記述が終了した</body>の真上に設置したり、非同期処理を適用するなどで対応します。ただし、レンダリングは段階的に行われます(後ほど説明します)ので、それ以前のHTMLとCSSが解析されているとは限りません。その場合、例えばFirefoxの場合だと、解析途中のCSSがある場合、JavaScriptの解析を中断してそれらの解析を待ちます。Webkitでは、影響を受けそうなCSSプロパティがある場合に、JavaScriptの解析を中断してそれらの解析を待ちます。
レンダーツリー(Render Tree)
DOMとCSSOMが作成されると、この2つを合わせてレンダーツリーが作成されます。ウェブブラウザはこのレンダーツリーをもとに、画面に表示します。
DOMツリーのルートから順に以下の処理を行い、レンダーツリーを作成します。
- metaタグなど、表示に関係のないノードを省略します。
- CSSで非表示(display: none)に設定されているノードを省略します。
- 各ノードに関連するCSSOMのルールを適用します。
レイアウト(Layout)
レンダーツリーが作成されると、それを基にレイアウトが作成されます。レイアウトでは画面に表示する位置情報を、各ノードに割り当てます。
ペインティング(Painting)
レイアウトを基にして、各設定を画面上の実際のピクセルに変換し、ペインティング(painting: 描画) します。レンダーツリーの容量が大きいほどペインティングに時間がかかるのは当然ですが、特定のスタイル、例えば複雑なグラデーションなども、単色に比べ時間がかかります。
また、一度ペインティングを行うと、その後は変更箇所のみをリペイント(repaint: 再描画)します。
レンダリングのフロー
レンダリングまでの処理をまとめると以下のフローになります。このシーケンス(一連の処理やデーター)をクリティカルレンダリングパス(Critical Rendering Path) といい、レンダリングエンジンが行います。
- DOMツリーを構築します。
- CSSOMツリーを構築します。
- DOMツリーとCSSOMツリーを組み合わせてレンダーツリーを構築します。
- レンダーツリーを基にレイアウトします。
- レイアウトを基にしてペインティングします。
段階的な処理
これらのシーケンスは1つ1つを完全に解析してから行うのではなく、JavaScript以外は段階的に処理されます。これはユーザーにいち早く情報を確認させるための処置となります。ネットワークからコンテンツの一部を取得するとクリティカルレンダリングパスを行い、表示されている間にネットワークからコンテンツを取得して、これを繰り返します。
JavaScriptに関しては、DOM(CSSOM)の操作を行う関係上、出現するとその箇所のソースコードを全て読み込み、処理を完了させます。
所要時間の確認
なお、これらの処理の所要時間は、DevToolsのperformance → event logで確認でき、クリティカルレンダリングパスの最適化の参考となります。
- Send Request: GETのリクエストを送信
- Parse HTML, Send Request: HTMLとDOM構造のパース。
- Parse Stylesheet: CSSOMのパース。
- Evaluate Script: main.jsを評価。
-
Layout: HTMLの
<meta name = "viewport">タグに基づいてレイアウトを生成。 - Paint: ドキュメント上のピクセルをペイント。
ノードとインターフェース
既に説明した通り、DOMとして作成された各オブジェクトのことをノード(node) といい、これらは種類により実装しているインターフェースが違います。ノードは実装するインターフェースによって、大きく12種類に分類できます。
例えば、主に次のようなインターフェースがあります。
- Document: HTMLツリーの頂点であるエントリーポイント。DOMの全体像。
- Element: HTMLエレメント
- Text: テキスト
- Comment: ソース内のコメント
それぞれが独自のプロパティやメソッドを持ちます。また、これら全てはNodeインターフェースを実装しており、そのNodeインターフェースはEventTargetインターフェースを実装しています。
[]で囲まれているのが、12のインターフェース
EventTarget
└ Node
├ [Document]
├ [Element]
│ ├ HTMLElement
│ └ SVGElement
├ [Attr]
├ [DocumentFragment]
├ [DocumentType]
└ [CharacterData]
├ [Text]
├ [Comment]
└ [CDATASection]
[Notation]
[Entity]
[EntityReference]
例えば、HTML要素から作成されるノードはElementインターフェースを実装したHTMLElementインターフェイスを実装するのですが、そこから更にHTMLElementインターフェイスを実装した<a>のHTMLAnchorElementインターフェースや<input>のHTMLInputElementインターフェースが存在し、それごとに使用できるプロパティやメソッドが違います。したがって、上記だけではなく、沢山のインターフェースが存在します。
そのノードがどのオブジェクト(インターフェース)から生成されているかを調べるには、constructor.nameで取得できます。
console.log(document.body.constructor.name); // HTMLBodyElement
console.dirでプロパティを確認できます。
console.dir(document.body);
/*
body
aLink: ""
accessKey: ""
……
instanceofで、継承の確認ができます。
console.log(document.body instanceof HTMLBodyElement); // true
console.log(document.body instanceof HTMLElement); // true
console.log(document.body instanceof Element); // true
console.log(document.body instanceof Node); // true
console.log(document.body instanceof EventTarget); // true
次は、12種類の各ノードがどのような子ノードを持っているかを表したものです。
| タイプ | 子ノード |
|---|---|
| Document | Element(最大1つ), ProcessingInstruction, Comment, DocumentType(最大1つ) |
| DocumentFragment | Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference |
| DocumentType | 子ノードなし |
| EntityReference | Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference |
| Element | Element, Text, Comment, ProcessingInstruction, CDATASection,EntityReference |
| Attr | Text, EntityReference |
| ProcessingInstruction | 子ノードなし |
| Comment | 子ノードなし |
| Text | 子ノードなし |
| CDATASection | 子ノードなし |
| Entity | Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference |
| Notation | 子ノードなし |
JavaScriptのインターフェース
ノードは様々なインターフェースを実装して構成されていると説明しました。例えばpノードの場合、以下の階層構造になっています。
EventTarget
└ Node
├ Document
└ Element
└ HTMLElement
└ HTMLParagraphElement
このためpノードは、上位のインターフェースのメソッドが使用できます。ただし、JavaScriptにはインターフェースの構文が用意されていません。したがってJavaScriptでいうインターフェースとはオブジェクトであり、下層のオブジェクトはprototypeチェーンなどでそれを継承しています。つまり、他プログラム言語のインターフェースのように、タイプだけを先に記述しているのではなく、メソッドが直接設定されている場合が殆どです。JavaScriptでいうインターフェースは言葉上だけのもので、継承と何ら変わりません。したがって、インターフェースをオブジェクトに置き換えて解釈しても、さほど問題ありません。
DOMが扱う値
例えば、idからノードを取得するgetElementById()というメソッドがあるのですが、次のようにオブジェクトを返します。
console.log(document.getElementById('foo'));
/*
foo: div#foo
accessKey: ""
align: ""
ariaAtomic: null
ariaAutoComplete: null
ariaBusy: null
……
DOMのAPIが扱う値はこのようなオブジェクトだけでなく、以下のインターフェースを実装したオブジェクトも存在します。
- DOMString
- DOMTokenList
- CSSStyleDeclaration
- HTMLCollection
- NodeList
※ これ以外にも存在します。
この値が、DOMの操作を混乱させる原因でもありますので、しっかりと理解しておきましょう。ただし、今の段階ではピンとこないと思いますので、この値を扱うオブジェクトを使用する際に、再度確認してください。
DOMString
DOMには文字列を扱うプロパティやメソッドがあるのですが、このDOMで扱う文字をDOMString型といい、符号なし16ビット整数の並びとなります。これはJavaScriptのStringに対応しており、JavaScript内ではStringとして使用できます。つまり、特に気にすることなくJavaScriptで文字列として扱うことができます。
例えば、Element.innerHTMLというプロパティは、そのノードのHTMLドキュメントをDOMStringで所持しています。
console.log(document.getElementById("foo").innerHTML);
/*
<!––TEST––>
<p>A</p>
<p>B</p>
*/
DOMTokenList
DOMTokenListインターフェースは、スペースで区切られた属性値などのオブジェクトのリストを扱います。Element.classList、HTMLAnchorElement.relList、HTMLLinkElement.relList、
HTMLAreaElement.relListなどのプロパティが、このインターフェースを実装したオブジェクトを値として持ちます。
詳しくはElement.classListプロパティを見てください。
CSSStyleDeclaration
CSSStyleDeclarationインターフェースは、CSSに関するオブジェクトのリストを扱います。HTMLElement.style、CSSStyleSheet、Window.getComputedStyle()などが、このインターフェースを実装したオブジェクトを扱います。
詳しくはHTMLElement.styleプロパティを見てください。
HTMLCollection
HTMLCollectionインターフェースはarray like(配列のような)なオブジェクトで、ノードをリストで扱います。
次のプロパティとメソッドを持ちます。
| プロパティ名 | 内容 |
|---|---|
| length | アイテム数を所持。 |
| メソッド名 | 機 能 | 内容 |
|---|---|---|
| item() | 取得 | 指定された位置にあるノードを返す。 |
| namedItem() | 取得 | 指定されたid、またはname属性が一致するノードを返す。 |
例えば別で説明するclass属性を持つ要素のHTMLCollectionを返す、getElementsByClassName ()を例にすると、以下のように使用します。
<div class="foo" id="aa"><p>AA</p></div>
<div class="foo" id="bb"><p>BB</p></div>
<div class="foo" id="cc"><p>CC</p></div>
console.log(document.getElementsByClassName('foo'));
/*
HTMLCollection(3) [div#aa.foo, div#bb.foo, div#cc.foo, aa: div#aa.foo, bb: div#bb.foo, cc: div#cc.foo]
0: div#aa.foo
1: div#bb.foo
2: div#cc.foo
aa: div#aa.foo
bb: div#bb.foo
cc: div#cc.foo
length: 3
[[Prototype]]: HTMLCollection
*/
// 1番目のfooクラスを持つノードを所得
console.log(document.getElementsByClassName('foo').item(0)); // <div class="foo" id="aa"><p>AA</p></div>
// 配列のように使用できる
console.log(document.getElementsByClassName('foo')[1]); // <div class="foo" id="bb"><p>BB</p></div>
// id ccに一致するノードを所得
console.log(document.getElementsByClassName('foo').namedItem("cc")); // <div class="foo" id="cc"><p>CC</p></div>
// lengthメソッド
console.log(document.getElementsByClassName('foo').length); // 3
また、for...ofを使うことができます。
for (const node of document.getElementsByClassName('foo')) {
console.log(node);
}
// <div class="foo" id="aa">……</div>
// <div class="foo" id="bb">……</div>
// <div class="foo" id="cc">……</div>
ただし、array likeであって配列ではないので、配列特有のメソッドは使用できません。その場合は、Array.fromやスプレット構文などで、配列に変換することが可能です。
console.log( Array.from(document.getElementsByClassName('foo')) );
/*
(3) [div#aa.foo, div#bb.foo, div#cc.foo]
0: div#aa.foo
1: div#bb.foo
2: div#cc.foo
length: 3
[[Prototype]]: Array(0)
*/
なお、ノードを取得する際、for...ofの代わりにfor...inを使用すると、列挙可能な全てのプロパティを反復してしまうので、余程の理由がない限りは使用するべきではありません。
for (const node in document.getElementsByClassName('foo')) {
console.log(node);
}
/*
0
1
2
length
item
namedItem
*/
NodeList
NodeListオブジェクトもHTMLCollectionと同じくarray likeなオブジェクトとなり、ノードをリストとして所持しているのですが、HTMLCollectionよりも扱えるメソッドが多くなります。
| プロパティ名 | 内容 |
|---|---|
| length | アイテム数を所持。 |
| メソッド名 | 機 能 | 内容 |
|---|---|---|
| item() | 取得 | 指定された位置にあるノードを返す。 |
| forEach() | 反復 | 各要素に対して指定された関数を実行。 |
| entries() | 反復 | キーと値のセットを順次処理。 |
| keys() | 反復 | キーを順次処理。 |
| values() | 反復 | 値を順次処理。 |
例えば、後述するname属性を持つ要素のNodeListを返すgetElementsByName()を例にすると、以下のように使用します。
<div name="foo"><p>AA</p></div>
<div name="foo"><p>BB</p></div>
<div name="foo"><p>CC</p></div>
console.log(document.getElementsByName('foo'));
/*
NodeList(3) [div, div, div]
0: div
1: div
2: div
length: 3
[[Prototype]]: NodeList
*/
// 1番目のname fooを持つ要素を所得
console.log(document.getElementsByName('foo').item(0)); // <div name="foo">……</div>
// 配列のように使用できる
console.log(document.getElementsByName('foo')[1]); // <div name="foo">……</div>
// lengthメソッド
console.log(document.getElementsByName('foo').length); // 3
for...ofを使用したり、Array.fromやスプレット構文などで、配列に変換することが可能です。
for (const node of document.getElementsByName('foo')) {
console.log(node);
}
// <div class="foo">……</div>
// <div class="foo">……</div>
// <div class="foo">……</div>
console.log( Array.from(document.getElementsByName('foo')) );
/*
(3) [div.foo, div.foo, div.foo]
0: div.foo
1: div.foo
2: div.foo
length: 3
[[Prototype]]: Array(0)
*/
ここまでは、HTMLCollectionと変わりませんが、例えばNodeListはforEachが使用できます。例えば次は、forEachでdivエレメンだけを表示させています。
const nodeList = Array.from(document.getElementsByName('bar'))
nodeList.forEach(node => {
if (node.nodeName === "DIV") {
console.log(node);
}
});
HTMLCollectionとNodeListの違い
HTMLCollectionとNodeListはよく似ていますが、最大の違いはDOMの変更に対して動的(dynamic)か静的(static)かという点です。
例えば、次のようなHTMLがあるとします。
<ul>
<li class="foo" name="bar">AAA</li>
<li class="foo" name="bar">BBB</li>
<li class="foo" name="bar">CCC</li>
<li class="foo" name="bar">DDD</li>
</ul>
HTMLCollectionはDOMの変更に対して動的です。例えばgetElementsByClassName()で取得した後にノードを追加し、再度getElementsByClassName()で取得すると、それが反映しています。
const htmlCollection = document.getElementsByClassName('foo');
console.log(htmlCollection.length); // 4
const li = document.createElement('li');
li.innerText = 'EEE';
li.classList = 'foo'
document.querySelector('ul').appendChild(li)
console.log(htmlCollection.length); // 5
一方、NodeListは静的です。例えばgetElementsByName()で取得した後にノードを追加し、再度getElementsByName()で取得しても、結果は変わりません。
const nodeList = document.getElementsByName('bar');
console.log(nodeList.length); // 4
const li = document.createElement('li');
li.innerText = 'EEE';
li.classList = 'foo'
document.querySelector('ul').appendChild(li)
console.log(nodeList.length); // 4
ノードを確認してみる
ノードとはどのような内容なのかを、Documentインターフェースを継承するdocumentオブジェクトで見てみましょう。
documentオブジェクトはDOMツリーの頂点となるオブジェクトで、DOMの操作はここから始まります。そして、そのdocumentオブジェクトが実装しているのがDocumentインターフェースです。
DocumentインターフェースはDOMの全体像を管理するインターフェースであり、DOM内に存在する各ノードのエントリーポイントとなります。各ノードのエントリーポイントとなりますので、ノードを取得する様々なメソッドを所持しています。例えば頻繁に使用するgetElementById()などがあります。このDocumentインターフェースを実装したdocumentオブジェクトを取得して、そこから各ノードを取得していきます。
そうは言っても、documentオブジェクトが何なのかが今一つピンとこないのではないでしょうか。そういう時には、実際に見てみるのが一番です。管理者ツールで確認してみましょう。
まずは、そのHTMLのdocumentを取得します。
const foo = document;
もちろんこれは、Documentインターフェースを取得しているのではなく、そのHTMLのdocumentのノード(オブジェクト)を取得しています。このdocumentオブジェクトがDocumentインターフェースを継承しているわけです。
ウェブブラウザーで開き、管理者ツールのSources > Whachにfooを設定して下さい。
foo: document
location: Location {ancestorOrigins: DOMStringList, href: 'file:///****/index.html', origin: 'file://', protocol: 'file:', host: '', …}
URL: "file:///****/index.html"
activeElement: body
adoptedStyleSheets: []
alinkColor: ""
all: HTMLAllCollection(13) [html, head, meta, title, link, body, div, p, div, p, div, p, script]
anchors: HTMLCollection []
applets: HTMLCollection []
baseURI: "file:///****/index.html"
bgColor: ""
body: body
characterSet: "UTF-8"
……
凄まじい数のプロパティが確認できます。もちろん、これら全て使用可能です。では、試しにこの中にあるcharacterSetプロパティを表示してみましょう。
console.log(document.characterSet); // UTF-8
ここで理解しておきたいのが、例えばこのcharacterSetプロパティはHTMLで<meta charset="UTF-8">を設定したのでプロパティとして存在しているのではなく、もともとデフォルトで持っているcharacterSetに値を追加しています。HTMLから<meta charset="UTF-8">を撤去して、同じようにdocumentオブジェクトを確認して見てください。characterSet: "windows-1252"などになっています。これから様々なノードを取得していきますが、それらはデフォルトでプロパティを持っており、その値を設定していくのだという事を覚えておいてください。
では、このオブジェクトの中の最下部を見てください。
[[Prototype]]: HTMLDocument
何故か、DocumentインターフェースではなくHTMLDocumentインターフェースを実装しています。Prototypeが分からない方は、Prototypeをご確認ください。
では、HTMLDocumentインターフェースを見てみましょう。
[[Prototype]]: HTMLDocument
constructor: ƒ HTMLDocument()
Symbol(Symbol.toStringTag): "HTMLDocument"
URL: (...)
activeElement: (...)
adoptedStyleSheets: (...)
alinkColor: (...)
all: (...)
……
documentオブジェクトの実装元ですので、同じプロパティが並んでいます。とりあえず、最下部を見てみましょう。
[[Prototype]]: Document
ようやく、Documentインターフェースが出てきました。中身を確認すると、先ほどまでの物にプラスアルファしたような内容です。見慣れたgetElementByIdなども出てきました。これは一体どういうことでしょうか。
実は先ほどのHTMLDocumentインターフェースは非推奨となっています。これまでHTMLDocumentインターフェースは、Documentインターフェイスを拡張する意味合いでdocumentノードから実装されていたのですが、今後はそれらのメンバをDocumentインターフェイス直属のメンバとしたいのです。ですが、いきなりHTMLDocumentインターフェースを撤去するのは難しいので、未だ残っているという訳です。つまり、今後HTMLDocumentインターフェースの存在は気にしないでいいでしょう。このようにDOMは、非推奨になったり逆に機能が追加されたりと、常に進化を続けています。
では、Documentインターフェイスの最下部を見てみましょう。
[[Prototype]]: Node
次は、Nodeインターフェイスを実装しており、同じく沢山のプロパティが確認できます。Nodeインターフェイスの最下部を見てみましょう。
[[Prototype]]: EventTarget
EventTargetインターフェイスを実装しています。更に最下部を見てみましょう。
[[Prototype]]: Object
Objectインターフェイスを実装しており、実装はここで終わっています。
つまり、以下のような関係となります。
※ HTMLDocument インターフェイスは除外しています。
ノード(node)とインターフェースで説明した通り、Ddocumentオブジェクトに限らず各オブジェクトは沢山のインターフェースを実装しています。これで、とりあえずdocumentオブジェクトがこのようなオブジェクトだというのが分かったのではないでしょうか。
また、Objectインターフェイスを継承しているという事は、やはりノードはJavaScriptのオブジェクトのようです。つまり、次のようにプロパティを追加できます。
const foo = document;
foo.bar = "Hello";
console.log(foo.hasOwnProperty("bar")); // true
メソッドも追加可能です。
foo.bar = function() {
return "Hello";
};
console.log(foo.bar()); // Hello
では、インターフェースはどうでしょうか。次はNodeインターフェースにプロトタイプを設定して、それを実装するオブジェクト全てで使用可能にしています。
Node.prototype.Hello = function() {
return "Hello";
};
const foo = document.getElementById("foo");
console.log(foo.Hello());
どうやら、インターフェースもやはりJavaScriptのオブジェクトのようです。
オブジェクトの参照
DOMでよく混乱するJavaScriptのオブジェクトの参照に関して復習しておきましょう。
例えば、Documentのプロパティで紹介するDocument.bodyプロパティでbodyのノード、Element.firstElementChildプロパティで最初の子ノードを取得できるのですが、これらのノードはそのプロパティに直接格納されているわけではありません。
『業務ができる中級者になるためのJavaScript入門(文法編)』で無料公開しているオブジェクト(object)で詳しく説明していますが、オブジェクトはメモリ内の番地が参照されます。
つまり、document.bodyを仮に自分で作るとすると、次のようになります。
const bodyNode = {
msg: "This is the BODY element.",
}
const document = {
body: bodyNode,
}
console.log(document.body.msg); // This is the BODY element.
DOMツリーの作成で説明した通り、HTMLの各構成要素がオブジェクトとなり、それらが参照しあっています。そして、そこからできる関連性が木構造モデルとなるDOMツリーです。
同じように、ノードの操作も混乱するポイントとなります。例えば次は、id属性がfooの要素のテキストをHelloに変更しています。
const foo = document.getElementById('foo');
foo.innerHTML = "Hello";
変数fooに代入したノード(オブジェクト)のプロパティを変更して、何故画面表示に影響するのかと混乱する人がいますが、これも参照が代入されています。つまり、これを操作すると、本体のノードが更新されることになります。
最後に
DOMは、皆が使用している割には、結局よくわかっていない技術の代表格だと思います。更にjqueryやReactなどの登場によって、余計訳が分からないまま何となく構築を進めている人も多いのではないでしょうか。本記事が、少しでもDOMの理解の手助けになれれば幸いです。
また、各ノードの使い方に関しては、業務ができる中級者になるためのJavaScript入門(DOM編)を参考にして下さい。
Discussion
ふわっとした理解のままとりあえず動く物としてDOMを扱っていたので、とても参考になりました。
一箇所「DebTools」になっている部分があったので報告します。
参考になってよかったです。また、ミスのご指摘をありがとうございます。修正しました。
すごい"熱量"で圧倒されました!
ちょうど今、フロントエンドアプリ開発(Typescript + React)の修練中だったので、とても参考になりそうです。ありがたく勉強させて頂きます。