[Kaggle]キャッサバコンペ振り返り

はじめに
2020年11月20日〜2021年2月19日に渡って開催されたKaggleのキャッサバコンペの概要や学んだことをまとめます。
このエントリーでわかること
- キャッサバコンペがどんなコンペだったか
- ディスカッションに投稿されたラベルノイズに関するアイデアや論文
コンペ概要
画像コンペにしてはデータセットが小さく(5GB程度)単純な画像分類タスクであったため初心者でも参加しやすいコンペでした(チーム数は3,000以上)。
概要を箇条書きで記します。
- キャッサバの葉や茎や芋の画像から病気の種類を分類する
- キャッサバの植物病害を迅速に特定することで、作物の収量を増やすのに役立つ(ちなみにキャッサバの芋は一時期ブームになったタピオカの原料)
- train set: 21,367枚, test set: 約15,000枚
- マルチクラス分類問題
- 5クラス(病気4種類、健康1種)
- 評価指標はAccuracy
- コードコンペ
- kaggle notebookで予測実行してsubmission.csvをサブミットする
- ラベル不均衡あり
- 間違ったラベルが付けられたデータが多い
- 2019年に同様のコンペ開催されており、2019年のデータ利用可能
データ
キャッサバの画像は素人目でも分類できそう?な特徴があります。
各クラスの特徴と具体例は以下です(詳しい解説)。
-
Cassava Bacterial Blight (CBB): 角ばった斑点、黄色の縁取りのある茶色の斑点、黄色の葉、葉がしおれてる
-
Cassava Brown Streak Disease (CBSD): 黄色斑点
-
Cassava Green Mottle (CGM): 黄色の模様、黄色と緑の不規則な斑点、葉縁の歪み、発育不良
-
Cassava Mosaic Disease (CMD): 重度の形状歪曲、モザイク模様
-
Healthy: その他
train set の分布は以下で、CMD が多い。
2019年のデータは今回のコンペと同じ画像があり、重複画像を除いてマージしたデータセットを公開した方もいました。
ラベルノイズ
本コンペは間違ったラベルが付けられたデータ(ラベルノイズ)が多く(詳しい解説)、ラベルノイズが本コンペを難しくした最大の要因でした。
ラベルノイズはtrain set だけでなくtest set にも残っているようで、このようなサンプルは間違ったラベルを間違った通りに当てる必要があります。
このため、本コンペは宝くじだと言うディスカッションも投稿されましたが、ホストからの回答はありませんでした。
とにかくわからない
test set にあるラベルノイズのためなのか、CV score が上がるとPublicLB 下がる問題に苦しみました。
シングルモデルだとCross Validation のAccuracy(CV score)> 0.895 になるとPublicLB と相関が取れなくなりました。
モデルアンサンブルでPublicLB=0.905 まで上げましたが、アンサンブルした各モデルのCV score は0.86-0.90 程度でCV score が高すぎないモデルをアンサンブルしないとPublicLB は上がりませんでした。
コンペ期間のleaderboard上位陣のスコアはほぼ0.90台で差がなく、1位だけが0.91台と突出していました。
PublicLB を上げるのを頑張ってもshake down(コンペの最終時に公開される最終的な順位のPrivateLB がPublicLB より下がること)すると考えてCV score が上がるモデルも作成し、最終サブミットはCV score が最も高いものとPublicLB が最も高いものを選択しました。
結果
我々のチームは34位でした。
1000位近くshake up/down したチームもある中で耐えた方でした。PrivateLB でも1位は変わらずでした。
解法概要はディスカッションに投稿しました。パイプラインは以下です。

自分は下の3モデル(EfficientnetB4、SE-Resnext50_32x4d、ViT-B/16)の作成とstackingを主に行いました。
最終サブミットでこの組み合わせを選んだだけで、作成したモデルはこれの何倍もあります。チームメンバが凄まじい勢いでモデルを作ってくれました。
解法概要のディスカッションでも書いていますが、
CV score やPublicLB を上げるために行った混同行列に基づいたモデルブレンドやstackingはPrivateLB では逆効果でした。
ノイズの多いtest set では各モデルの予測値の単純平均が最も効果的でした。
これが本コンペで得た最大の学びでした。
ラベルノイズの対策
ラベルノイズの対策や論文はディスカッションで多く投稿されました。
今後の備考録を兼ねて試したものや有用そうなものを記します。
多様なモデルでアンサンブル
モデルアンサンブルがCV, LB 向上に最も効果的でした。
Hard Voting(各モデルの予測ラベルの多数決)よりも、Soft Voting(各モデルの確信度を足し合わせる)の方が精度上がりました。
複数モデルの予測結果がすべて同じ間違いをしているサンプルをラベルノイズと仮定して削除
どのモデルもclass=3と予測したけどlabel=1であるようなサンプルを除いて再学習する方法です。
この方法はCV score を上げるのに効果的でした(チームメンバが試した)。
おそらく、ラベルノイズを除いて学習することで予測が難しいハードサンプルを当てれるようになったんだと思います。
cleanlab でラベルノイズ見つけて削除やAugmentation
cleanlab はラベルノイズを見つけるためのPythonパッケージです。
モデルの混同行列から間違ったラベルの確率分布を推定してラベルノイズを見つけます。

cleanlab で見つけたラベルノイズを含むbatch はCutMix を行うように学習すると若干ですがCV score が上がりました。
予測値(確信度)が小さいサンプルを削除して再学習
モデルの確信度が小さいサンプルはラベルノイズと仮定して除く方法です。
test set にもラベルノイズがある本コンペではうまくいきませんでした。
- 成功例: PANDAコンペ1位の解法
ImageNet などのクリーンなデータセットでpre-trained したモデルをfine-tuning
pre-trained モデルが優れているほど、ラベルノイズが多いtrain タスクの汎化性能は高くなりやすいそうです。
2019年と今回のコンペのデータからBYOLでpre-trained モデルを作りましたがCV, LB ほぼ変わりませんでした。
- BYOL実装例 (PyTorch)
ラベルノイズにロバストな損失関数で学習
-
Bi-Tempered Logistic Loss
外れ値のロスの影響を減らす+softmaxの裾の幅広げることでラベルノイズの効果弱めるLogistic Loss- 論文: Robust Bi-Tempered Logistic Loss Based on Bregman Divergences
- 公式のgithub (Tensorflow)
- 非公式の実装 (PyTorch)
- デモサイト
-
Taylor Cross Entropy (TCE) Loss
テイラー級数展開で外れ値のロスの影響を緩めたCategorical Cross Entropy Loss- 論文: Can Cross Entropy Loss Be Robust to Label Noise?
- 非公式のgithub (PyTorch)
test set にもラベルノイズがあるためか、ノイズにロバストにして真のラベルを当てるこれらの手法は精度向上に寄与したかよくわかりませんでした。
ラベルを混ぜるData Augmentation で正則化
-
SnapMix
CAM(クラスアクティベーションマップ)で画像切り取る領域決めたCutMix -
ResizeMix
mixする画像全体を小さくresizeして別の画像に張り付けることで混ぜる -
Mixup Without Hesitation
ディスカッションで上がっていたが試していない。
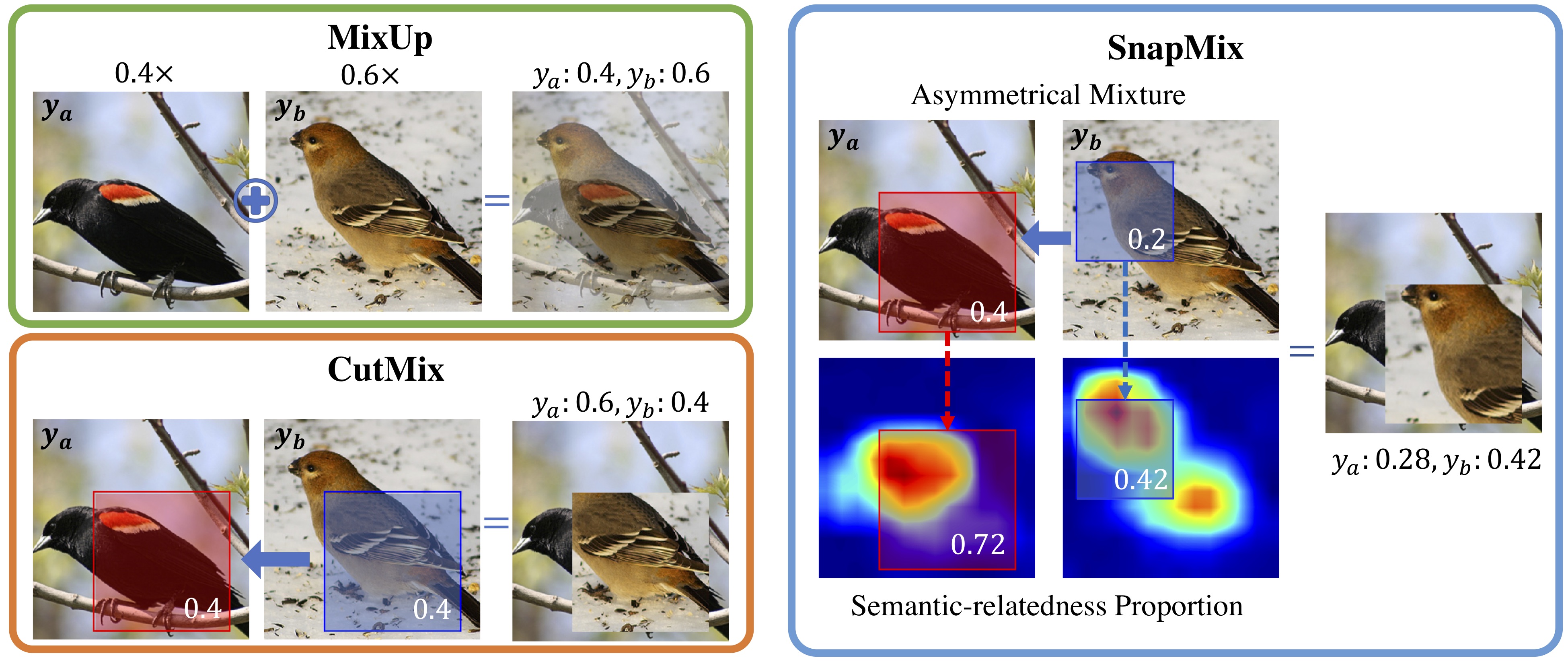

SnapMix, ResizeMix の他にCutMix, Fmix も試しましたがCV, LB ほぼ変わりませんでした。
その他
アノテーターの特性を学習
アノテータの特徴を学習(アノテータの間違えたラベルの付け方をモデル化)してノイジーなラベルから真の分布を見つける手法です。

試しましたがCV, LB 悪化しました。
Self-Adaptive Training
ラベルノイズ対策のSOTA(2021/01時点で)
チームメンバが試してくれましたが本コンペでは効果なかったみたいです。
ノイズ分類器
このディスカッションで書かれているようなラベルノイズかどうかの2クラス分類も試しましたがうまくいきませんでした。
モデル
新たに提案された高精度なモデルの論文やgithubもディスカッションによく投稿されました。
- Vision Transformer
- Data-efficient image Transformers(DeiT)
- RepVGG
これらのモデル入ってる画像モデルライブラリ pytorch-image-models(timm)
Vision Transformer はEfficientNet などのCNN のモデルとアンサンブルするとCV, LB 向上しました。Transformer とCNN のアンサンブルは有効そうでした。
まとめ
- キャッサバコンペはお手軽な画像コンペだけどラベル汚い
- ノイズの多いtest setでは各モデルの予測値の単純平均が最も効果的
- ラベルノイズの対策などいろいろ試したが、test set のラベルノイズにより何が効いたのかよくわからないコンペだった…
Discussion