ML Note

チューニングステップ
同時並行でやりすぎると学習に影響が出る可能性有
LibSVM
LIBSVMおよびLIBLINEARは広く使われるオープンソースの機械学習ライブラリ
C言語APIを用いたC++で記述されている
LIBSVMはカーネル法を用いたサポートベクターマシン の学習に使うSMOアルゴリズムを実装していて、分類と回帰に対応している
SVM(Support Vector Mniachine)
分類と回帰の両方の目的に使用できる教師あり機械学習アルゴリズムである。SVMは線形および非線形の問題を解くことができ、多くの実用的な問題に有効
SVMは、データをクラスに分ける線または超平面を作成
SVMはカテゴリ割り当て、スパム検出、感情分析などのテキスト分類タスクに使用される
画像認識の課題にもよく使われ、特にアスペクトに基づく認識や色に基づく分類で優れた性能を発揮する
CNN(Convolutional Neural Network)
畳み込みニューラル ネットワークには数十から数百の層があり、各層が画像のさまざまな特徴の検出を学習します
CNN は、入力層、出力層、その間にある多くの隠れ層で構成されている
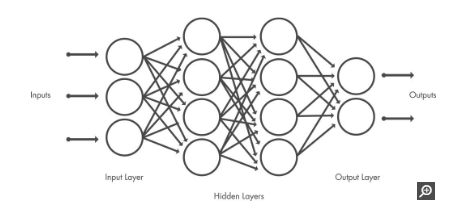
- 畳み込み層
- 正規化線形ユニット(ReLU)層
- プーリング層
画像や時系列データの重要な特徴を明らかにして学習できるよう、最適なアーキテクチャを提供する
医療画像処理: 画像中のがん細胞の有無を視覚的に検出可能
音声処理: 特定単語やフレーズの学習、検出
オブジェクト検出: 自動運転
合成データの生成: 新しい画像の生成
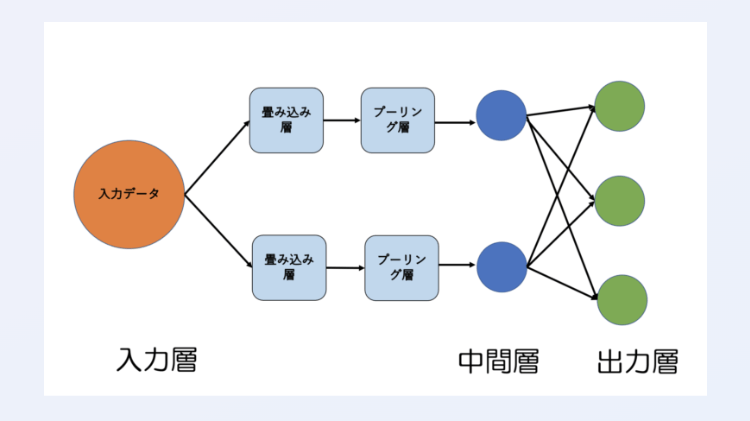
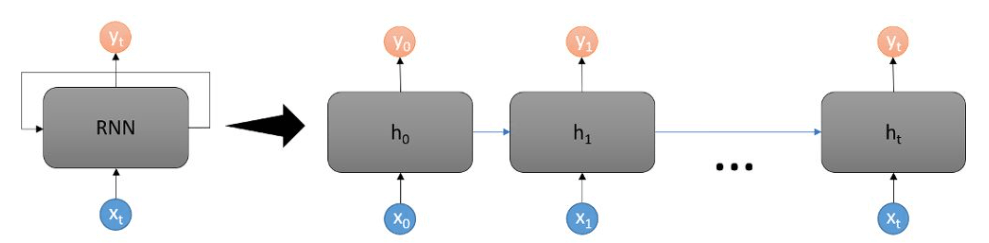
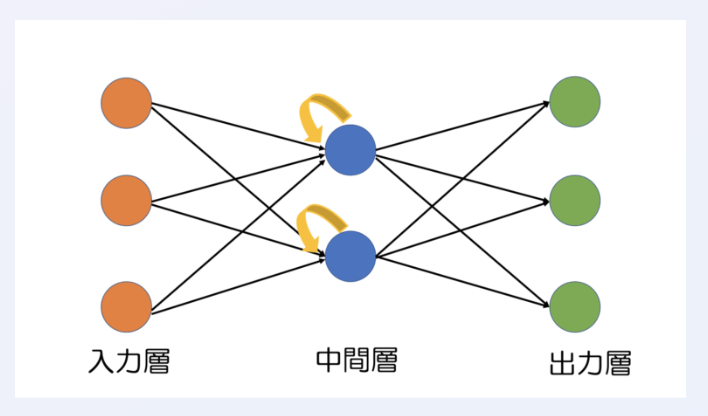
RNN(recurrent neural networks)
過去の情報を利用して現在および将来の入力に対するネットワークの性能を向上させる、ディープラーニングの構造
RNN の特徴は、ネットワークに隠れ状態とループが含まれている点
ネットワークにループ構造を用いると、過去の情報を隠れ状態で保存し、シーケンスで処理することができます。
信号処理: 信号は経時的にセンサーから収集される場合が多いため、自然にシーケンシャルデータになっています。大規模な信号データセットに対する自動分類および自動回帰により、リアルタイムでの予測が可能
テキスト解析: 言語は本来逐次的であり、テキストの長さはまちまちです。RNN は文章内の単語を文脈に当てはめて学習できるため、テキスト分類、テキスト生成、機械翻訳、感情分析 (単語やフレーズの意味の分類) などの自然言語処理タスクに適したツール
LSTM (長・短期記憶)
RNN は、通常、逆伝播により学習し、その際に勾配が "消失" または "爆発" する問題が生じることがある
この問題が発生すると、ネットワークの重みが非常に小さくなるか、または非常に大きくなり、長期の関係を学習する効果が薄れてしまいまう
この問題に対策が LSTM
MLP (多層パーセプトロン)
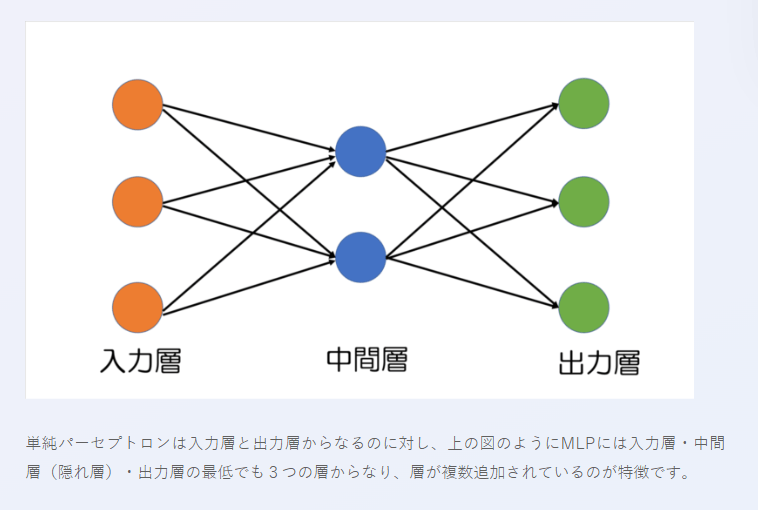
MLP(多層パーセプトロン)とは人間の脳をモデル化したパーセプトロンというものを多層化したもののことです。これは、機械学習のアルゴリズムの1つであるニューラルネットワークの基本となるもの
ResNet50
深さが 50 層の畳み込みニューラル ネットワークです。100 万個を超えるイメージで学習させた事前学習済みのニューラル ネットワーク
100 万個を超えるイメージで学習させた事前学習済みのニューラル ネットワークを、ImageNet データベース[1]から読み込むことができる
CBOW

Factorization Machines
数値データではなく Float32 で渡す
アンダーフィッティング対策でレイヤー追加したら精度が収束しなくなった
→「勾配の消失」は、シグモイド活性化関数の小さな導関数を多層で多数掛け合わせた結果生じる。ReLUは小さな導関数を持たないので、この問題を回避できる。
バッチサイズが大きいと学習が速くなるが、バッチサイズが大きいと、真の極小値を見つけられずに局所的な極小値にはまり込む危険性がある。
ハイパーパラメータのチューニングのベストプラクティス
・可能な限り小さい範囲でハイパーパラメータを選択する
・一回で一つのトレーニングジョブを実行する
Incremental Training
時間が経つにつれて、モデルが生成する推論が以前ほど良くないことに気づくかもしれない。
インクリメンタル・トレーニングでは、既存のモデルの成果物を使用し、新しいモデルをトレーニングするために拡張されたデータセットを使用することができる
※インクリメンタル・トレーニングは、時間とリソースの両方を節約します。
用途
・拡張データセットを使用して新しいモデルをトレーニングします。そのデータセットには、以前のトレーニングでは考慮されなかった基本的なパターンが含まれており、その結果モデルのパフォーマンスが低下しています。
・一般に公開されているモデルのモデル成果物またはモデル成果物の一部をトレーニングジョブに使用する。ゼロから新しいモデルをトレーニングする必要はありません。
・停止していたトレーニングジョブを再開する。
異なるハイパーパラメータを設定したり、異なるデータセットを使用したりして、モデルの複数のバリエーションをトレーニングします。
Inference Pipelines
機械学習で推論するためには、生のデータをそのまま使うのではなく「前処理」が必要になることがとても多いです。
また、推論した結果を、後続のシステムが使いやすい形に「後処理」することも多いです。
そこで、「前処理」、「推論」、「後処理」等の処理を一連の流れとして実行できるようにしておく必要があるのですが、このように「複数の処理を指定した順番で一連の流れで処理させる」機能をSageMakerでは「推論パイプライン」として実装できます
2-15 のコンテナをサポート
ハイパーパラメータチューニング
モデルの性能不足の万能薬ではないので、データエンジニアリングやモデルの代替アルゴリズムなど、他のオプションを検討する必要がある
回帰モデルの過大評価
評価データのオブザベーションの残差は、真のターゲットと予測されたターゲットの差です。残差は、モデルが予測できないターゲットの部分を表します。正の残差は、モデルがターゲットを過小評価している(実際のターゲットが予測ターゲットより大きい)ことを示します。負の残差は、過大評価(実際のターゲットが予測ターゲットより小さい)を示します。
残差プロットは,過小評価または過大評価の傾向を示す
平均絶対誤差(Mean Absolute Error)とRoot mean square error (RMSE)はどちらも誤差の大きさ
早期停止
ハイパーパラメータチューニングジョブの早期停止を有効にすると、SageMaker は以下の基準を使用します:
現在のトレーニングジョブの目的メトリックの値が、同じエポックまでの過去のトレーニングジョブの目的メトリックの実行平均の中央値よりも悪い(目的メトリックを最小化する場合は高く、最大化する場合は低く)場合、Amazon SageMakerは現在のトレーニングジョブを停止します。
cnn再トレーニング(転移学習)
分布
ポワソン分布
二項分布
その他分布については要確認
Discussion