DEA-C01 お勉強書き連ね
正式名
AWS Certified Data Engineer – Associate (DEA-C01)
公式ガイド
つまみんのまとめに感謝
Skill Builder
Exam Prep Official Practice Question Set: AWS Certified Data Engineer - Associate (DEA-C01 - Japanese)
弱かったところ
Redshiht へのデータ連携
→AppFlow
Lambda の EFS のマウント
SQS からのメッセージ削除
→DeleteMessage API/maxReceiveCountの到達/キューパージ(キュー内メッセージの全削除)
Redshift Serverlessのできることは?
→ライブデータの共有
KDS → Lambda の実行パフォーマンス
→シャードの数を増やす(デフォルト1シャード1関数)
IteratorAgeとは。。。?
→数値が高い場合リアルタイムでデータが処理されておらず最新のものからどんどんずれている可能性が高い
Redshift + S3 のクエリパフォーマンスの最適化
→Redshift マテリアライズドビュー + SQL REFRESH
Glue のジョブ実行モニタリング
→Glue コンソール上のジョブ実行モニタリングセクションから適切な DPU の判断が可能
各試験範囲の分野
※個人的に気になったところというか大事かなと思ったところ
分野1:データの取り込みと変換
データの ETL
→Glue 系 / Amazon EMR
パイプラインでのオーケストレーション、サービス連携
→Glue / AWS Glue DataBrew? / AppFlow / SQS /Step Functions / Glue Workflow
Glue
ETL サービス
念のため
E: Extract: 抽出
T: Transform: 変換
L: Load: 書き出し
・概要
Spark(Apache Spark)を使用したデータ分散処理が出来るため大規模データ ETL 処理が出来る →大容量データを高速分散処理するオープンソースフレームワーク、Hadoop の欠点を補う形で登場
・実行手順
クローラー実行: ソースデータから対象データを抽出しデータカタログを作成
ジョブ作成、実行: データカタログ(データソース)と宛先、変換処理を指定して実行
コスト関連
ジョブ実行時に割り当てる処理能力: DPU(Data Processing Unit)
→DPU の処理時間で決まる
処理数とかがタイミングでぶれる場合、Glue コンソール上のジョブ実行モニタリングセクションから適切な DPU の判断が可能
Glue Data Catalog
クローラーが実行され作成される。 ETL のソースデータのリファレンス
データの場所やスキーマ情報が保存されている
どこにどんなデータがあるのかの情報を整形して次の工程で使いやすくする感じ
Glue DataBrew
GUI でのデータの前処理が実施可能
Glue Workflow
Glue 内で処理が完結する場合に選択
Step Fundtions との使い分けは要検討
Amazon EMR
旧称 Amazon Elastic MapReduce
Hadoopクラスタを提供するサービス
関連用語
Hive: SQL ライクな HiveSQL でのクエリ
Pig: 分散処理ライブラリ
HDFS: データ保存レイヤー
YARN: コンピューティングリソースの管理レイヤー
Presto: 標準 SQL でのインタラクティブクエリ
EMR vs Glue
EMR を使用する場合って、Spark 以外のフレームワークを使用する場合やデータ出力先の都合で使用を検討
でもインスタンスの管理がいる、、
Glue の方が Serverless でインスタンスの管理が必要ない
AppFlow
ノーコードで SaaS アプリケーションや AWS サービス間のデータ転送が可能
送信元と宛先、トリガーを指定しフローを作成することでデータを転送する
Redshift や S3、Snowflake、Salesforce にデータを転送できる
※転送する際にフィールドのマッピングや検証、マスキングが出来る
Step Functions
各コンポーネントを疎結合にワークフロー管理できるマネージドサービス
Lambda や API の実行が出来、実行結果を踏まえた後続の処理の管理などけっこう柔軟にワークフローが実行できる
分野2: データストアの管理
データのカタログ化、設計
→Glue 系 / Lake Formation
データライフサイクル
→S3 のライフサイクルポリシーとかバージョニング、Redshift Spectrum
Lake Formation
データレイクを構築運用するサービス
データの取り込みから権限管理モニタリングが可能
Blueprints: データ取り込み時に使用するテンプレート
列レベル、行レベルでのアクセス制限が出来るため組み合わせてセルレベルでアクセス制御が可能
S3
覚えてないところだけ(普段は暗記してなくても必要なときに調べればいいから。。。)
ライフサイクルポリシー
特定日数経過したオブジェクトを指定したストレージクラスへ移動したり削除したりする
ストレージクラス
- S3 Standard: 通常のもの
- S3 Standard – IA: S3 Standard のアクセス頻度低い版 *IA(Infrequent Access)
- S3 1 ゾーン - IA: S3 Standard – IA の 1AZ 版、可用性が低くてもいい場合に使う
- S3 Intelligent-Tiering: オブジェクトのアクセス頻度から費用対効果が高いストレージクラスに自動で移動することが出来る
- S3 Express One Zone: 2023 re:Invent での発表、S3 Standard の10倍のデータアクセス速度、リクエストコスト 50 %減、AZ を指定してデータ保存を行う
- S3 Glacier Instant Retrieval: 4半期に一度の読み取り、すぐ読み取りが出来る
- S3 Glacier Flexible Retrieval(旧 S3 Glacier): 年1~2回の読み取り、数分から数時間で読み取り
- S3 Glacier Deep Archive: 年1~2回の読み取り、12時間以内での読み取り
Redshift Spectrum が対応しているストレージクラス
*RedshiftクラスターとS3バケットは同一リージョン
Glacier ストレージクラスの3種類では未対応、S3 クラスに移動してから使用する必要がある
Athena が対応しているストレージクラス
基本的にすべてのストレージクラスを対応
*S3 Glacier Flexible Retrieval (以前の Glacier) および S3 Glacier Deep Archiveにクエリする場合は復元されたオブジェクトパラメータをテーブル単位で有効化する必要がある (有効化されていない場合はスキップされる)
分野3: データ運用とサポート
データ処理の自動化およびその運用監視
→KDS / KDF / Amazon MSK
データ分析
→Athena / KDA / OpenSearch Service / QuickSight / Redshift
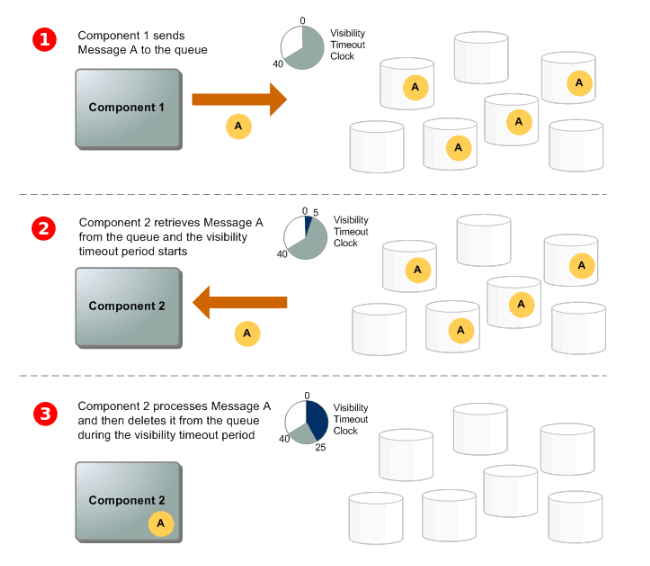
SQS
キューサービス、AWS や SaaS サービスの連携ができる
メッセージ(データ)をキューに入れ、それを適宜取り出すことが出来る
*入れる方をプロデューサ、取り出す方をコンシューマと呼ぶ
*テキストデータ 256KB 以下のデータが扱える
SQS からのメッセージ削除
→DeleteMessage API/maxReceiveCountの到達/キューパージ(キュー内メッセージの全削除)
FIFO キュー
重複せず正確な順序で受信/送信処理が出来る
*通常のキューは順番は可能な限り保持、配信回数は少なくとも1回
読み書きスループットは 300件/秒
可視性タイムアウト
コンシューマがメッセージをキューから取得してもキューに残り続けるメッセージを複数回取得しないようにする機能
デフォルト30秒再アクセスでの取得が出来なくなる(0秒~12時間)
厳密にする場合FIFOキューを使う
デッドレターキュー
正常に取得できなかったメッセージを専用のキュー(デッドレターキュー)に移動する
*ただのSQSだからエラーハンドリングなどをする場合、別途処理を作る必要はある
ロングポーリング/ショートポーリング
ショートポーリング: メッセージがなかったら空レスポンス、すべてのメッセージが取得できない可能性もある
ロングポーリング: メッセージがなくてもタイムアウトまではレスポンスを返さなくなる
Kinesis
4つのサービスの総称
- Amazon Kinesis Data Streams (KDS)
- Amazon Kinesis Data Firehose (KDF)
- Amazon Kinesis Data Analytics (KDA)
- Amazon Kinesis Video Streams (KVS?)
KDS
ストリームサービス
データをストリーム(シャード)に送信し、それを適宜読み取ることが出来る
*入れる方をプロデューサ、取り出す方をコンシューマと呼ぶ
Lambda の場合はストリームへの送信をトリガーに関数を実行し読み取り処理を行うイベント駆動型に出来る
KDS → Lambda の実行パフォーマンス
→シャードの数を増やす(デフォルト1シャード1関数)
IteratorAgeとは。。。?
→数値が高い場合リアルタイムでデータが処理されておらず最新のものからどんどんずれている可能性が高い
*現在は廃止されていてGetRecords.IteratorAgeMillisecondsが正しい
現在時刻と、最後にストリームに対して GetRecords が行われた時刻の差分
保持期間はデフォルト24時間、最大365日
シャード
オンデマンドモードとプロビジョニングモードがある
送信: 最大1MB/秒 または 1,000record/秒
読み取り: 最大2MB/秒 または 2,000record/秒
シャードの設計を誤るとパフォーマンスの劣化が発生する
*シャード不足、パーティションキーの偏りによるシャードの偏りからのリクエスト再試行の頻発
容量不足: WriteProvisionedThroughputExceeded/ReadProvisionedThroughputExceeded
リシャーディング: データ転送速度が増加した際にシャード数を調整(分割/結合)してスループットを向上する
拡張ファンアウト: コンシューマーとシャード間に論理的な2MB/秒スループットパイプを提供する KDSコンシューマーのオプション機能。普通に複数のコンシューマーを設計すると、KDSの性能制限を超えてしまう場合や、200ms以下のデータ提供速度を求める場合に利用するらしい
プロデューサ
- AWS SDK (Kinesis API)
- KPL (Kinesis Producer Library)
- Kinesis Agent (Linux サーバ用Javaアプリケーション)
- AWS IoT
- CloudWatch Events/Logs
- その他アプリケーション
コンシューマ
- KDF
- KCL (Kinesis Client Library)
- KDA
- Lambda
- EMR
- Apache Storm
KDS vs SQS
データの保存期間や並列読み込み、複数の宛先への同時配信機能有無、最大データサイズ、メッセージ形式に差分あり
また、分散ストリーム処理に対応しているのが SQS の場合 Lambda のみ
*KDS は KDA/EMR/Lambda が対応
イメージ的には SQS よりは KDS の方がリッチで高機能、だけどその分パフォーマンス出すためのチューニングが必要
とってもわかりやすくまとめてくださって感謝
KDF
ニアリアルタイムでストリームデータをデータストア/分析ツールに配信するサービス
フルマネージドなのでチューニングが要らない
配信を行う前に、Lambda を使用したデータ変換が可能
→csv/json 形式への変換などの簡易 ETL が可能
プロデューサ
- AWS SDK (Kinesis API)
- KPL (Kinesis Producer Library)
- Kinesis Agent
- AWS IoT
- CloudWatch Events/Logs
- その他アプリケーション
*KDSと同じ
コンシューマ
- S3
- Redshift
- OpenSearch Service
KDS vs KDF
そもそもユースケースが違う≒コンシューマが異なる
KDSはストリームデータ処理の間に挟まるイメージ、KDFはストリームデータ保存を行うイメージ
あとはチューニングの有無とリアルタイム vs ニアリアルタイムくらい
KDA
ストリーミングデータに対してSQLやJavaでのリアルタイム分析が出来るサービス
データソースは KDS/KDF
出力先は LDS/LDF/Lambda など
Amazon MSK
MSK(Managed Streaming for Apache Kafka)
フルマネージドの Apache Kafka が使用できるサービス *Serverless あり
KDS と機能的には類似
Apache Kafka
OSS のスケーラビリティに優れた分散メッセージキュー(ストリーム)処理プラットフォーム
キーワードとしては以下2つ?
- Broker: メッセージキュー (KDS のシャード)
- Zookeeper: Broker 間の連携に使用
Athena
S3(Glacier含む) 内のデータに対して標準 SQL を使用して分析できるフルマネージドサービス
*GZIPなどに圧縮されていてもクエリ可能
Glue Data Catalog を参照してクエリを実行することも可能
読み取りデータに応じてコストがかかるため圧縮や列指向フォーマットにデータを変換すると良い
*列指向: Excel の縦、IDで範囲を取ったり、日付をパーティションにして検索すると効率よくなる 2023/01 - 2023/12 みたいな
Redshift
マネージドデータウェアハウスサービス
→大量のデータを溜めて SQL などでクエリを行ってデータ分析を行うためのサービス
Not Data Lake
自動/手動のスナップショットでバックアップが可能
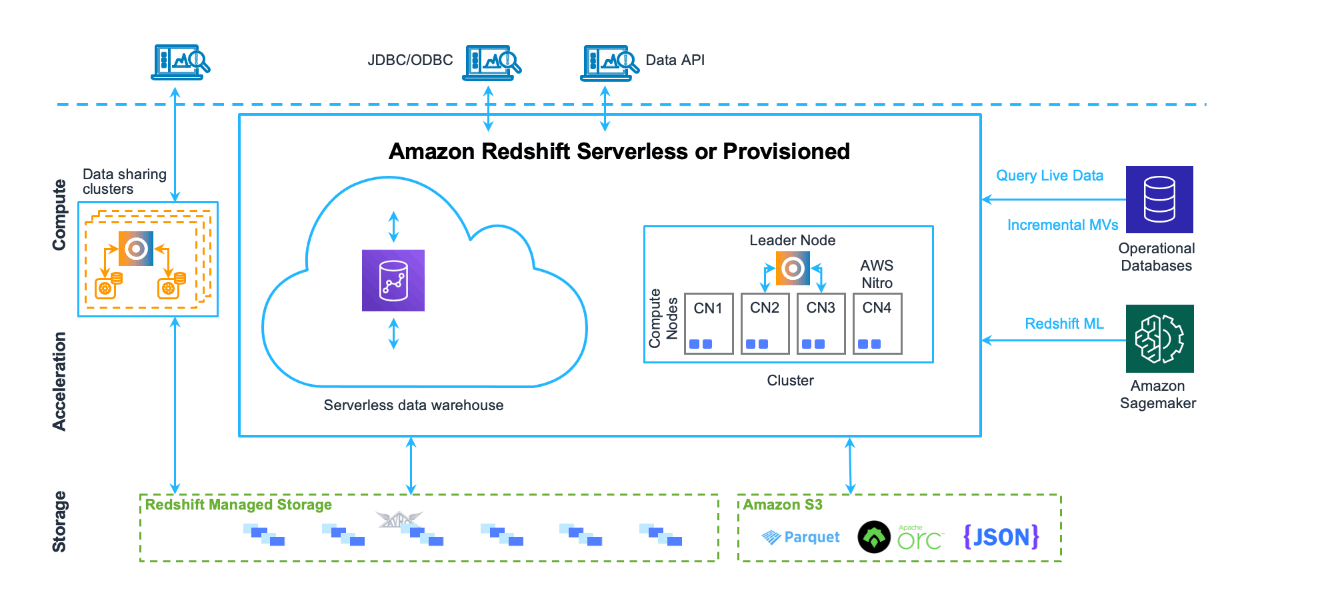
クラスタ、Serverless 間でのデータ共有が可能
マテリアライズドビュー
ビューで保持している SQL の実行結果を増分データで更新できるためパフォーマンスが改善しクエリレスポンスが早くなる
Redshift Spectrum
S3 のデータを Redshift にロードせずにクエリを行うことが出来る機能
*RedshiftクラスターとS3バケットは同一リージョン
S3 のデータを外部スキーマ/外部テーブルとしてクエリする
コストのかかり方は Athena と同様のためデータ圧縮や列指向フォーマットデータ化などを考える
Redshift Serverless
クラスターのデータを共有して一時的に別の処理を行うとかでも使用可能
Redshift vs Athena
Athena は小規模データやアドホック(特定目的)クエリに便利
Redshift Spectrum で S3 だけをクエリしたい場合でも Redshift クラスターが必要
→ある程度の大規模データセット以上で高パフォーマンスとなる
OpenSearch Service
OpenSearch クラスターのデプロイ、オペレーション、スケーリングを容易にするマネージドサービスです
OpenSearch はログ分析、リアルタイムのアプリケーションモニタリング、クリックストリーム分析などのユースケース向けの、完全なオープンソースの検索および分析エンジン
*Serverless あり
ログなどのデータをため込み、クエリをしてグラフィカルなビューを表示できるサービス
QuickSight
データをクエリしてグラフィカルなビューを表示できる(BI)サービス
Athena のクエリ結果や各種DBなどをデータソースにすることが可能
MLと連携した分析実施可能
SPICE(インメモリエンジン)に事前に読み込ませておくことでより速いレスポンスを提供
分野4: データのセキュリティとガバナンス
各サービス連携時の認証認可(IAM)
→IAM / Secrets Manager
データ保存時の暗号化とマスキング
→Macie / KMS(SSE)
気になったところだけ
Aurora / RDS への認証
MariaDB/MySQL/PostgreSQL の場合は IAM データベース認証が可能
それ以外の場合は Secrets Manager を選択
S3 の PII データの処理
*保存する前のは Lambda とかで良しなに、、、
AWS Macie を使用する
すべてのバケットから自動検出可能
*すでに保存されているデータも対象
Security Hub や EventBridge と連携可能で検出時の通知およびイベント駆動での処理が可能
Discussion