ML つらつら

機械学習の概念
機械学習 (ML) は、履歴データを使用してより良いビジネス上の意思決定をするのに役立ちます。ML アルゴリズムはデータ内のパターンを発見し、これらの発見を使って数学的モデルを構築します。その後、そのモデルを使用して将来のデータを予測することができます。たとえば、機械学習モデルの 1 つの考えられる用途は、顧客が過去の行動に基づいて特定の製品を購入する可能性を予測することです。
- 予測するものを決定する (問題の策定
- ラベル付きデータを収集する = すでにターゲット(予測しようとしているもの)の回答がわかっているデータ (変数: ターゲットの回答を予測するパターンを識別するために使用するもの)
例: Eメール分類の場合、ターゲットはスパムかどうかを示すラベル、変数は送信者やテキスト、時刻など - データ分析を行い、各データの相関や値を見て期待通りのものかを確認しデータの質をよくする
- 機能の処理 = 変数を意味のあるものに変換する
例: 不足/欠落している値を中央値/平均値に置き換える - データをトレーニングデータと評価データに分割する(70~80:20~30)
→同一のデータをトレーニング/評価に使用するとモデルの一般化ではなく覚えるものに有利になる
データ変換(4. 機能の処理
機械学習モデルのトレーニングに使用されるデータについて
良いトレーニングデータは学習と一般化のために最適化されている
機能変換
機能=データフィールド
ランダム文字列などの学習プロセスに有用でないものを変換し学習プロセスの効果を上げる
データ変換
バイナリ属性(0 or 1)にする
例: Yes/No → 1/0
正規化(Normalization)
平均値がゼロで分散が 1 になるように数値変数を正規化する
→確認された残りの値に対する外れ値の影響を最小限に抑えることができる
なぜならその特徴がターゲットに対して有益であるかどうかにかかわらず、最大の変数が ML モデルで使われるから
→空白補完にランダム数列などを使うと予測能力の低下につながる場合などに使用
標準化(Standarization)
平均を0、標準偏差を1にする事。 データから平均を引いて、標準偏差で割る。
機械学習アルゴリズム
表形式
行。列で構成されたテーブルにまとめられたデータセットの分析を行う
因数分解マシン
分類タスク/回帰タスク両方に使用可能な汎用アルゴリズム
※教師有
線形モデルの拡張でクリック予測や項目推奨などに適している
K 最近傍 (k-NN)
分類タスク/回帰タスク両方に使用可能
※教師有
サンプルポイントに最も近いkポイントに対してクエリを行い予測を返す
トレーニングには、サンプリング、次元削減、インデックス構築の3ステップがある
XGBoost
分類タスク/回帰タスク、ランキングに使用可能
※教師有
勾配ブーストツリーアルゴリズムのよく知られた効率的なオープンソース
線形回帰
売上の予測、配達時間の予測、または数値の予測が可能
ロジスティック回帰
線形回帰に似ているがバイナリ出力が生成されるため数値予測はできない
テキスト
自然言語処理、文書の分類や要約、トピックのモデリング、分類、文字起こしや翻訳で使用される
BlazingText
大規模なデータセットに簡単に拡張できる Word2vec とテキスト分類アルゴリズムの高度に最適化された実装
Word2vec: 教師無
→センチメント分析、エンティティ認識、および翻訳に役立つ
テキスト分類: 教師有
LDA
一連のドキュメントのトピックを決定するのに適しているアルゴリズム、分類カテゴリ
教師無
NTM
トピックモデリングを行ってドキュメントの分類/要約やコンテンツレコメンデーションを行う
教師無
seq2seq
一般的にニューラル機械翻訳に使用される
テキスト/オーディオを入力し、テキスト/オーディオを出力する機械翻訳
テキスト翻訳や要約などにも応用可能
教師有
TensorFlow
テキスト分類用の事前学習済みモデルによる転移学習をサポートする
教師有
転移学習
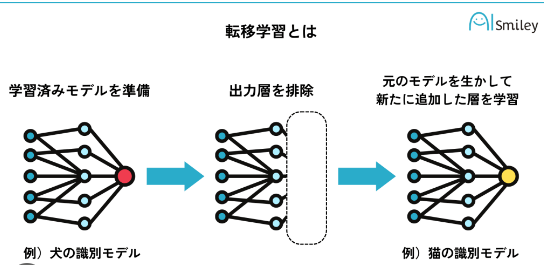
監視なし
K-means クラスタリング
1 つのグループのメンバーができるだけ互いに類似し、他のグループのメンバーとできるだけ異なる離散グループをデータ内に見つける
教師無
RCF
その他の高度に構造化またはパターン化されたデータとは異なるデータセット内の異常なデータポイントを検出
教師無
時系列データにおける突然のスパイク、周期性の中断、分類できないデータポイントなどを検出
モデル評価
正しい予測
(正しい検出)True Positive
→怪しい動作をちゃんと検出した
(正しい日検出)True Negative
→怪しい動作だけど検出対象ではなかった
誤った予測
(誤検出)False Positive
→正しい動作を検出した
(検出漏れ)False Negative
→怪しい動作を検出しなかった
正解率(Accuracy): 正しい予測の割合
TP + TN / TP + TN + FP + FN (正しい予測 / 全体)
→全体の中で正しい予測だった割合
範囲は 0 ~ 1 で値が大きいほど予測精度が高い
適合率(Precision、精度): 正と予測される例の中の実際の正の割合
TP / TP + FP (正しい検出 / 検出数)
→ Positive 予測だったものの中で正しかったものの割合
範囲は 0 ~ 1 で値が大きいほど予測精度が高い
リコール(再現率): 実際の正の割合のうち正と予測されたものの数 = 真陽性率(True positive rate)
TP / TP + FN (正しい検出 / 検出対象)
→正で検出されるべきものの中で実際に検出されたものの割合
範囲は 0 ~ 1 で値が大きいほど予測精度が高い
誤検出率(FPR): 正と予測された実際の負の割合 = 偽陽性率(False positive rate)
FP / FP + TN (誤検出 / 非検出対象)
→検出されるべきでないものの中で検出されたものの割合
範囲は 0 ~ 1 で値が小さいほど予測精度が高い
F1測定値: 正確さとリコールの組み合わせ
範囲は 0 ~ 1 で値が小さいほど予測精度が高い
(2 x Precision x Recall) / (Precision + Recall)
AUC / ROC
ROC: リコールと FPR のグラフ
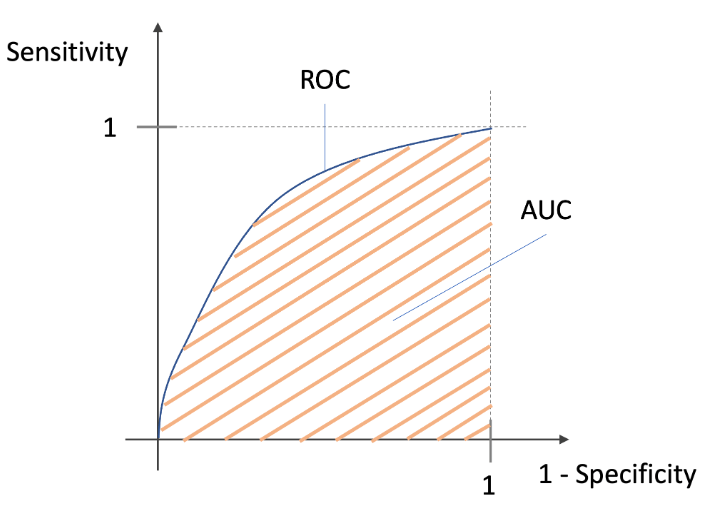
AUC(面積) が大きいほど精度が高いモデル
モデル制度の向上
複数回のMLプロセスを繰り返し実行しモデルを改善しながらより良い予測を得るようにする
- データ収集: トレーニング例の数を増やす
- 機能処理: 変数とより良い処理機能を追加する
- モデルパラメータのチューニング: 学習アルゴリズムで使用するトレーニングパラメータの値を変えてみる
モデルの適合性
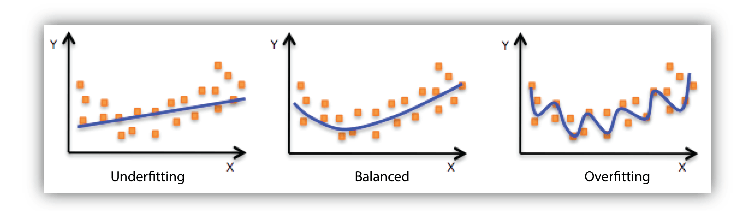
モデルが一般化されていない時に発生する
アンダーフィット
モデルがデータに対してあまりフィット(マッチ)していない = シンプルすぎる
モデルがターゲットを説明するには入力機能が十分に説明あれておらず単純すぎることが原因の可能性が高いため柔軟さを高めることで改善が可能
・固有機能の追加や機能処理タイプの変更(nグラムサイズの増加)
・使用する正則化の量を減らす
オーバーフィット
モデルがデータに対してフィット(マッチ)しすぎている = 細かすぎる
モデルが既存のデータを記憶していて、新しいデータに対して一般化できないため、柔軟性を低下させる措置をとることで改善可能
・機能の組み合わせを少なくする(nグラムサイズの減少)
・使用する正則化の量を増やす
学習アルゴリズムに学習するデータが十分にない場合、トレーニングデータとテストデータの精度が悪くなる可能性があるため、トレーニングデータの例の量を増やしたり、既存トレーニングデータのパスの数を増やすことでパフォーマンス向上をすることが出来る
nグラム変換
テキスト変数を入力として受け取り、nワードのウィンドウをスライドさせることに対応する文字列を生成し出力する
nグラム変数のサイズが大きいほど組み合わせが多くなる
- ウィンドウサイズ = 1 で nグラム変換を指定すると、その文字列内の個々の単語がすべて得られる
{"I", "really", "enjoyed", "reading", "this", "book"}
- ウィンドウサイズ = 2 でnグラム変換を指定すると、すべての 2 語の組み合わせと 1 語の組み合わせが得られる
{"I really", "really enjoyed", "enjoyed reading", "reading this", "this
book", "I", "really", "enjoyed", "reading", "this", "book"}
- ウィンドウサイズ = 3 で nグラム変換を指定すると、このリストに 3 語の組み合わせが追加され、次の結果が得られる
{"I really enjoyed", "really enjoyed reading", "enjoyed reading this",
"reading this book", "I really", "really enjoyed", "enjoyed reading",
"reading this", "this book", "I", "really", "enjoyed", "reading",
"this", "book"}
正則化
過学習を防ぐための手法
学習時に重み付けを行う
ポアソン分布
統計学および確率論で用いられるポアソン分布とは、ある事象が一定の時間内に発生する回数を表す離散確率分布
二項分布の考え方
オーバーサンプリング
多数派のクラスに合わせて少数派のクラスのデータをランダムに複製する
アンダーサンプリング
少数派のクラスに合わせて、多数派のクラスのデータをランダムに削除する
SMOTE
SMOTEとは元のデータから類似するデータを生成する手法で、以下の手順を繰り返すことでデータを生成する
- 元データからランダムにデータを選択
- 選択したデータの近傍に存在するデータからランダムに1つを選択
- 選択したデータと近傍データの間に新たなデータを生成
エポック数
「一つの訓練データを何回繰り返して学習させるか」の数のこと
Discussion