CorrelationをObjectiveにしたXGboostのExample
この記事はNumerai Advent Calendar 2021 の8日目の記事です。
概要
Correlation(相関係数)をObjective function(目的関数)に設定したXGboostのモデルの例を紹介します。Numerai公式のフォーラムに投稿されている関連のコードを切り貼りや改変して作成したものです。手っ取り早く動かすことを目的としており、理論的な部分やパラメータ設定の追求は行っていません。学習データはNumeraiのデータセットを用います。
元になる投稿
特に以下のteddykokerさんのNumerai公式フォーラムへの投稿がベースになります。
上記投稿によると、
- NumeraiのCorrはスピアマンの順位相関係数で、計算に順位のソートがあるので微分ができず、従来はGBMの目的関数にしにくかった。
- しかし、最近の論文で微分可能な順位のソートの方法が新しく紹介されていたので、それを用いた目的関数を作成した。
とのことです(超意訳)。こういうのをさらっとできてしまう輩が集まっているのがNumeraiという戦場です。恐ろしいです。
下準備
fast_soft_sortのインストール
こちらのgithubのfast-soft-sortというものを事前にインストールしておく必要があります。
setup.pyを使うか、もしくはfast_soft_sort/のフォルダをプロジェクトのフォルダに置いてインストールしなさいとあります。
この記事では後者の方法でインストールします。
fast_soft_sortのダウンロード
下図①の「Code」から②の「Download ZIP」を選択してソースコードをダウンロードします。
解凍したフォルダの中の「fast_soft_sort」というフォルダをこれからモデルを作成するフォルダにコピーしておきます。
fast_soft_sortに必要なライブラリ
- NumPy
- SciPy
- Numba
- PyTorch
の4つが入っていなければインストールします。
Windowsの場合、上の3つはコマンドプロンプトにてpip install ~とすればインストールできてしまうと思います(きっちりインストールされたい方はそれぞれお調べください)。PyTorchのインストールだけは、こちらのページで使用する環境に合わせたコマンドを作ります。
例えば、WindowsでCPUで動かすPytorchをpip3でインストールしたい場合は以下の通り選択し、生成された「pip3 install torch torchvision torchaudio」というコマンドを使います。

XGBoostのインストール
私は以下の記事に従ってインストールしました。
インストールするファイルを、system32にコピーして、コマンドプロンプトにて、実行する方法です。whlファイルは、cp~のところをpythonのバージョンと合わせることにご注意ください。
matplotlibのインストール
グラフ表示にmatplotlibを使います。Windowsの場合pipでインストールできます。
pip install matplotlib
トレーニングデータの準備
事前に、公式からデータセットをダウンロードし、「numerai_training_data_int8.parquet」をモデルを作成するフォルダに置いてください。この記事では、2021/12/05現在の特徴量数1050のデータセットを使います。
コード全体
上記の下準備が全て出来たら、あとは以下のコードをpyファイルにして実行すれば概ね動くと思います。
# インポート
import torch
# ↓ダウンロードした「fast_soft_sort」を同じフォルダに置いてください。
from fast_soft_sort.pytorch_ops import soft_rank, soft_sort
from pathlib import Path
from datetime import datetime as dt
import pandas as pd
import numpy as np
import xgboost as xgb
import scipy.stats
from matplotlib import pyplot as plt
# 定数
TARGET_NAME = 'target'
PREDICTION_NAME = 'prediction'
MODEL_FILE = Path('corr_objective_xgb_example_model.xgb')
PROGRAM_NAME = 'corr_objective_xgb_example'
# main関数
def main():
print(PROGRAM_NAME, dt.strftime(dt.now(), '%m/%d %H:%M:%S'), 'main関数開始')
print(PROGRAM_NAME, dt.strftime(dt.now(), '%m/%d %H:%M:%S'), 'トレーニングデータ読み込み')
# トレーニングデータ
temp_df = pd.read_parquet('numerai_training_data_int8.parquet', engine='fastparquet')
# 省メモリと重なり除外の為、4round間隔でデータを抜き出します。
df = temp_df[pd.to_numeric(temp_df['era']) % 4 == 0]
# 特徴量名
f_names = [f for f in df.columns if f.startswith('feature')]
# 学習データの準備
# early stopping用にeraがera_thの前後でtrainデータとtestデータに分割します。(おおよそ7:3)
era_th = 420
df_train = df[pd.to_numeric(df['era']) < era_th]
df_test = df[pd.to_numeric(df['era']) >= era_th]
eval_set = [(df_train[f_names], df_train[TARGET_NAME]), (df_test[f_names], df_test[TARGET_NAME])]
model = xgb.XGBRegressor(max_depth=5, # 見慣れた設定
learning_rate=0.01, # 見慣れた設定
n_estimators=5000, # 3000くらいでtestがサチります。
n_jobs=-1,
colsample_bytree=0.1, # 見慣れた設定
objective=custom_corr # カスタム目的関数(学習に使う)を設定
)
print(PROGRAM_NAME, dt.strftime(dt.now(), '%m/%d %H:%M:%S'), '学習開始')
evals_result = {}
model.fit(df_train[f_names],
df_train[TARGET_NAME],
eval_set=eval_set,
eval_metric=eval_corr, # こちらはearly stopping用です。
early_stopping_rounds=1000,
callbacks=[xgb.callback.record_evaluation(evals_result)])
# 学習モデル保存
print(PROGRAM_NAME, dt.strftime(dt.now(), '%m/%d %H:%M:%S'), '学習モデル保存')
model._Booster.save_model(MODEL_FILE)
# 学習グラフの出力
plt.plot([-1.0 * n for n in evals_result['validation_0']['corr']], label='train corr')
plt.plot([-1.0 * n for n in evals_result['validation_1']['corr']], label='test corr')
plt.grid()
plt.legend()
plt.xlabel('rounds')
plt.ylabel('corr')
plt.savefig('graph.png') # グラフをpngで保存
# numeraiのDiagnostic用ファイル作成
print(PROGRAM_NAME, dt.strftime(dt.now(), '%m/%d %H:%M:%S'), 'validデータ読み込み')
# validデータ読み込み
df_valid = pd.read_parquet('numerai_validation_data_int8.parquet', engine='fastparquet')
# 予測
df_valid[PREDICTION_NAME] = model.predict(df_valid[f_names])
# csv出力
df_valid[PREDICTION_NAME].to_csv('valid_pred.csv', header=True)
def custom_corr(target, pred):
# 参考リンク) paulitoさんの投稿
# https://forum.numer.ai/t/differentiable-spearman-in-pytorch-optimize-for-corr-directly/2287/19
n_pred = pred.shape[0]
n_target = target.shape[0]
th_pred = torch.tensor(pred.reshape(1, n_pred), requires_grad=True)
th_target = torch.tensor(target.reshape(1, n_target))
# 1ラウンド目でpredがすべて0.5に近すぎる場合にエラーになる場合があるようです。
# 例外処理要検討ですが、以下の様にfloat64を使うと動くときもあります。
# th_pred = torch.tensor(pred.reshape(1, n_pred), requires_grad=True, dtype=torch.float64)
# th_target = torch.tensor(target.reshape(1, n_target), dtype=torch.float64)
corr = spearman(th_target, th_pred)
# rmse(参考用)
# rmse = np.sqrt(np.sum(np.square(pred - target)) / len(pred))
# print('corr:', float(corr), ' rmse(参考用):', rmse)
corr_grad = torch.autograd.grad(corr, th_pred)[0]
corr_grad = -1.0 * corr_grad.detach().numpy()
return corr_grad[0], np.ones(corr_grad.shape)[0]
def spearman(target, pred):
pred = soft_rank(pred,
regularization='l2', # 設定箇所
regularization_strength=0.01 # 設定箇所
)
if len(pred[0]) > 0:
corr = corrcoef(target, pred / len(pred[0]))
else:
corr = 0.0
return corr
def corrcoef(target, pred):
# 参考リンク
# https://forum.numer.ai/t/differentiable-spearman-in-pytorch-optimize-for-corr-directly/2287/19
# np.corrcoef in torch from @mdo
# https://forum.numer.ai/t/custom-corr-functions-for-xgboost-using-pytorch/960
pred_n = pred - pred.mean()
target_n = target - target.mean()
if pred_n.norm() == 0.0:
pred_n = pred_n / 0.000001
# 学習の最初のラウンドでpred_n.norm()が0になることがあるようなので回避。
else:
pred_n = pred_n / pred_n.norm()
target_n = target_n / target_n.norm()
return (pred_n * target_n).sum()
def eval_corr(target, pred):
# こちらはearly_stoppingの判定に使われます。
corr = scipy.stats.spearmanr(target, pred.get_label())[0]
# corr = np.corrcoef(target, pred.get_label())[0][1]
return 'corr', -1.0 * corr # 最小を目指すためマイナス
main() # main関数実行
コードの補足
コメントとして記述しておりますが、学習の一番最初のラウンドにてpredが全て0.5で始まってエラーが出る場合があるようで、小手先の方法で回避しています。また、soft_rankのregularizationやregularization_strengthの設定については、詳しく調べられておりません。引用元をご参照ください。
学習曲線(参考)
「graph.png」というファイル名で学習曲線が出力されます。上記設定だと、3000ラウンドくらいでサチります。
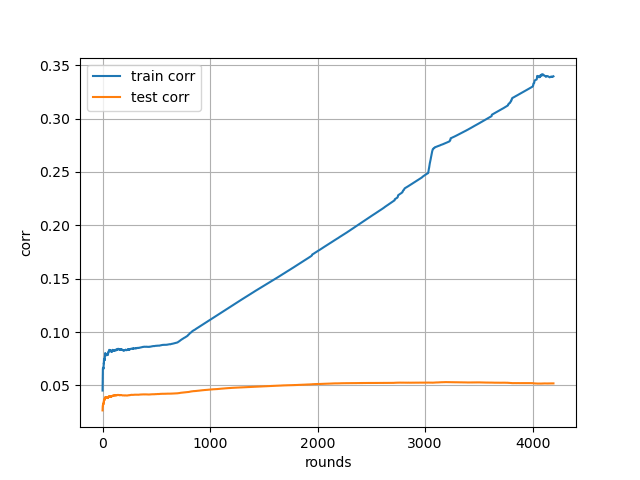
trainとtestの乖離が凄いです。個人的には良くない形です。モデルの表現力がありすぎるんですね。depthを減らすとよいかもしれません。
注)この記事では動かすだけが目的なので、パラメータチューニングは行いません。
Validataion Diagnostics(参考)
以下はDiagnosticsです。そんなに悪くも無いように思います。
All Predictions

TB200

カスタム目的関数
カスタム目的関数は色々と試しているのですが、それだけでスコアが劇的に良くなるというものでもないようです。個人的なお気に入りはLog-Coshです(外れ値に寛容になるので)。以下の記事の最後にコードが紹介されています。
終わりに
ご指摘などありましたらTwitterの方にご連絡ください。
Discussion