Brainf**kで湯婆婆を実装してみる
はじめに
背景
3年ほど前に一時話題になったネタですが、Javaで湯婆婆を実装してみるというプログラミングのお題があります。
最近、Brainf**kネタを記事にしていないので、というのと、最近 esolang ネタは zenn でまとめることにしたので、ということで、Brainf**k版を実装して記事にすることにしました。
環境
Brainf**kには様々な実装がありますが、ここではideone.comで採用されているbffを前提とします。特徴としては次の通りです。
- 4バイトセル ( セルに格納できる数値の範囲が事実上無制限 )
- wrap-around ( 0 からのデクリメント、最大値
2^{32}-1 - 開始セルより左側 ( 負のアドレス ) への移動可
- セル数無制限
- 標準入力EOF時の入力値は -1 ( セルの最大値
2^{32}-1
実装
コードおよび実行例
それでは、以下が今回実装した1471bytes版(コメント・改行無し)のコードになります。
+>+>--->+>--->->++>+>+++++++[-<<[---------------<]>++++>++>+>->->-->--->---->>+>+++++<<]<.<<<<<<-.>>.>>>>++.[<]>.[>]<<.>-.<<<<<.<<++++.[>]<---.<---.<<<<+++++.[>]<.<+.<.>>.<--.++.>.<-.<<<<---.[>]<.<.<<<++.>>>>.<.<<<<<++++++.[>]<++.<<<<---.>.>>>.<<+.<.>>>--.<+.<<<++.>>>>+++.<<<<<--.<<.[>]<---.<-.<<.>>>.<.<<<<<-.[>]<.<-.++.>>>+++.>>->>+[,+[->+>[->>>]<[>+++++++++++++++>+>]<<<<]>->+>-[---------------[+[+[+[[+]<[-]>]]<[[-]>>+<<]>]<[[-]>>++<<]>]<[[-]>>+++<<]<[-<+>>>>>>>+<<<<<<]>>>[-[->+<]<<,[-<+>>>>>>+<<<<<]>>>>>[->+<]<[->+<]<]>>+>[[->>>+<<<]<]<<+<]>]>>->-[<[-<+<<]>[<<[->+<]<]>>>-]<[-<<<<<<+>>>>>>]<<<<<[-]<<-<+[-<+]-<<<<.<+.<<<+++.>>>>.<.[<]>-----.[>]<.<---.++.>>>>>>>[.>]>+[->[.>]>+]>+[[[<]<+>>[>]<-]<[<]<-]<[<]-<+[-<+]-<<<<.<-.<<<<<--.[>]<.<.<-----.>>.<.<++.>>.<.<<<<<++++++.[>]<.<.<<--.>>>.<.<--.>>.<-.++.>+++++.[<]>+.>>>>>+.>>--.[<]>--.>>+++++++.[>]<---.<-.<<<<<----.[>]<++.<<<<-----.>++.>>>--.<.<<<<--.[>]<.<.<<<<<+++.[>]<.<.<++.>>.<-.++.>>>.<<+.[<]>+++++++++.>>>>>+++.>>-.<-.<+.>>.<+.<--.>>.<-.<+.>>++.<<-.<.>>>--.<.<<<<<+.[>]<++.<<<<.>.>>>.<<.<.>>>--.<.<<<<<+.[>]>>>>+[->+]>[.>]<[<]-<+[-<+]-<<<<.<.<<<<.[>]<.<-.++.>.<-.+++.>.<---.+++.>.<---.<<--.>>>.<.+++.>.<----.+.>>>>>>+[->+]>[.>]<[<]-<+[-<+]-<<<<.<.<<<<.[>]<.<+.<-.>>.<--.++.>++.<<.--.>>--.<-.<<.>>>.<.<<<<+++.[>]<.<.<<<<----.[>]<.<+.<+++.>>+++++.[<]>++++.>>>++++.>>>>----.[<]>-----.>>>>.>>>-.<.<<<--.>>>>.<-.<<<<------.[>]<.<+.<<.>>>.<.<<<+.>>>>.<-.<<<<+++++++.[>]<.<-.+.>>>>>>+[->+]>[.>]<[<]-<+[-<+]-<--..<.
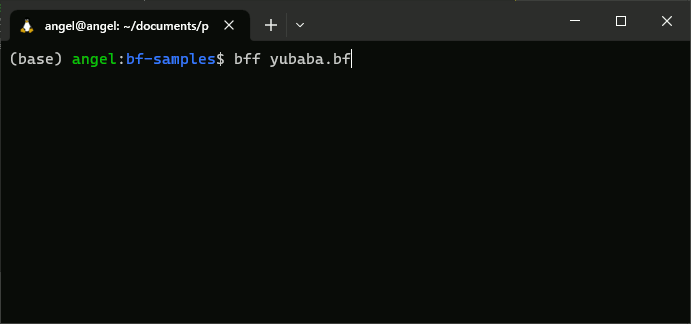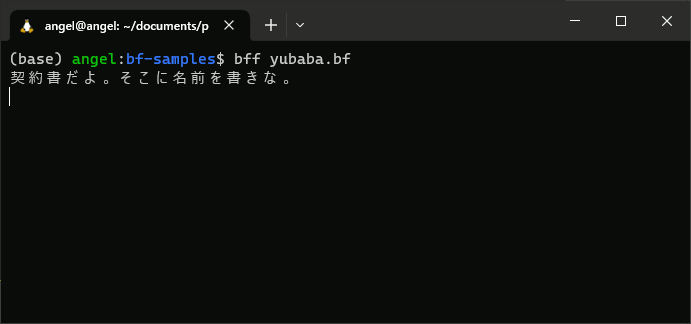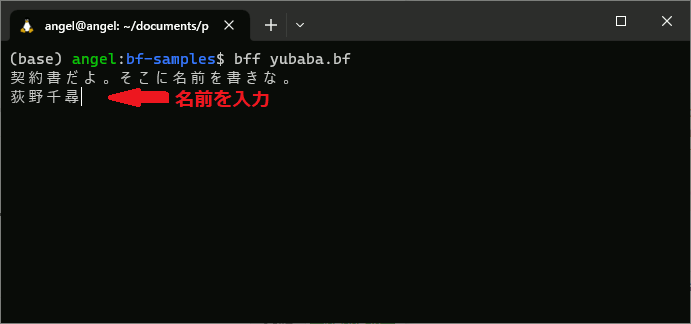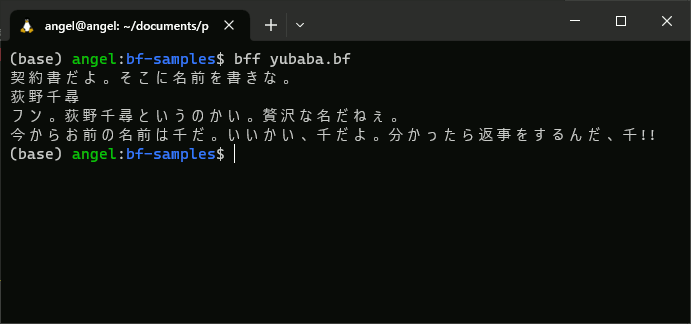
次のように、WSLターミナル上で実行すると、湯婆婆を再現できていることが分かります。
対話実行ではありませんが、https://ideone.com/LFGrMr でも挙動を確認することができます。
仕様
ところで、オリジナルの仕様では、湯婆婆の決定する文字はランダムに選ぶことになっているのですが、Brainf**kでは乱数生成の仕組みがありません。
以前、ズンドコキヨシを実装した時は、標準入力から文字列を受け取ってSEED値とするPRNGを実装したのですが、今回名前を既に読み込むことが決まっているところ、それ以外を入力させるのは少し気がひけます。
そこで、今回は「名前の文字コードの合計 - 1 を文字数で割った余りの位置の文字」を選ぶ実装としました。つまり、入力により選ぶ文字は固定なのですが、何文字目を選ぶかは色々変わるということです。
例えば上の例にある「荻野千尋」だと、文字コードとしてはUTF-8で3byte×4文字の e8,8d,bb e9,87,8e e5,8d,83 e5,b0,8b で、文字コード合計(10進) 2115、-1 して 4 で割ると余りは 2 のため、0 開始で文字位置を見て「千」が選ばれるという寸法です。
※敢えて -1 しているのは、もちろん原作準拠を目指したためです。
なお、今の世の中UTF-8が当然なので、もちろん可変バイト数対応もしっかりです。
一般的な日本語の3byte文字のみならず、ASCII(1byte文字), 2byte文字(ギリシャ文字等が該当), 4byte文字(絵文字等が該当)が来ても大丈夫です。
※画像の最後の例は U+1F49 のハートで、f0,9f,92,97 の4byte文字です。
解説
コード全容
では、解説に移るのですが、流石に上のコードでは構造を把握し辛いので、元のコメント付き整形コードに従って進めていきます。
※長いので折りたたんでいます。なお、Brainf**kはコードに無関係な文字は全て無視されますので、この整形コードでも同じように動作します。
コメント付き整形コード
** setup **
+>+>--->+>--->->++>+>+++++++[-
<<[---------------<]
>++++>++>+>->->-->--->---->>+>+++++
<<]<
** phase 1 **
(契).<<<<<<-.>>.>>>>
(約)++.[<]>.[>]<<.>
(書)-.<<<<<.<<++++.[>]<
(だ)---.<---.<<<<+++++.[>]<
(よ).<+.<.>>
(。).<--.++.>
(そ).<-.<<<<---.[>]<
(こ).<.<<<++.>>>>
(に).<.<<<<<++++++.[>]<
(名)++.<<<<---.>.>>>
(前).<<+.<.>>>
(を)--.<+.<<<++.>>>>
(書)+++.<<<<<--.<<.[>]<
(き)---.<-.<<.>>>
(な).<.<<<<<-.[>]<
(。).<-.++.>
(NL)>>+++.
** input **
>>->>+[
* read the 1st byte of a char ( possibly multi byte ) and div by 16 *
,+[->+>[->>>]<[>+++++++++++++++>+>]<<<<]
>->+>-[
* if not a newline: detect the number of bytes of the char *
---------------[
+[
+[+[[+]<[-]
* other(1byte) *
>]]<[[-]
* 2byte UTF8 *
>>+<<
]
>]<[[-]
* 3byte UTF8 *
>>++<<
]
>]<[[-]
* 4byte UTF8 *
>>+++<<
]
* read the rest bytes of the char and add each code to the sum value *
<[-<+>>>>>>>+<<<<<<]>>>[-
[->+<]
<<,[-<+>>>>>>+<<<<<]>>>>>[->+<]<[->+<]
<]
* prepare for the next char *
>>+>[[->>>+<<<]<]
<<+<]
>]
* divide the sum by the number of chars and save the remainder as the index of the limited name *
>>->-[<[-<+<<]>[<<[->+<]<]>>>-]<[-<<<<<<+>>>>>>]
<<<<<[-]<<-<+[-<+]-<<<<
** phase 2 **
(フ).<+.<<<+++.>>>>
(ン).<.[<]>-----.[>]<
(。).<---.++.>
** full name **
* print the full name *
>>>>>>[.>]>+[->[.>]>+]
* search and mark the cell with the saved index *
>+[
[[<]<+>>[>]<-]
<[<]
<-]
<[<]-
<+[-<+]-<<<<
** phase 3 **
(と).<-.<<<<<--.[>]<
(い).<.<-----.>>
(う).<.<++.>>
(の).<.<<<<<++++++.[>]<
(か).<.<<--.>>>
(い).<.<--.>>
(。).<-.++.>
(贅)+++++.[<]>+.>>>>>+.>>
(沢)--.[<]>--.>>+++++++.[>]<
(な)---.<-.<<<<<----.[>]<
(名)++.<<<<-----.>++.>>>
(だ)--.<.<<<<--.[>]<
(ね).<.<<<<<+++.[>]<
(ぇ).<.<++.>>
(。).<-.++.>
(NL)>>.<<
(今)+.[<]>+++++++++.>>>>>+++.>>
(か)-.<-.<+.>>
(ら).<+.<--.>>
(お).<-.<+.>>
(前)++.<<-.<.>>>
(の)--.<.<<<<<+.[>]<
(名)++.<<<<.>.>>>
(前).<<.<.>>>
(は)--.<.<<<<<+.[>]<
** limited name **
* move to the mark and print 1 char *
>>>>>+[->+]>[.>]<[<]-<+[-<+]-<<<<
** phase 4 **
(だ).<.<<<<.[>]<
(。).<-.++.>
(い).<-.+++.>
(い).<---.+++.>
(か).<---.<<--.>>>
(い).<.+++.>
(、).<----.+.>
** limited name **
* move to the mark and print 1 char *
>>>>>+[->+]>[.>]<[<]-<+[-<+]-<<<<
** phase 5 **
(だ).<.<<<<.[>]<
(よ).<+.<-.>>
(。).<--.++.>
(分)++.<<.--.>>
(か)--.<-.<<.>>>
(っ).<.<<<<+++.[>]<
(た).<.<<<<----.[>]<
(ら).<+.<+++.>>
(返)+++++.[<]>++++.>>>++++.>>>>
(事)----.[<]>-----.>>>>.>>>
(を)-.<.<<<--.>>>>
(す).<-.<<<<------.[>]<
(る).<+.<<.>>>
(ん).<.<<<+.>>>>
(だ).<-.<<<<+++++++.[>]<
(、).<-.+.>
** limited name **
* move to the mark and print 1 char *
>>>>>+[->+]>[.>]<[<]-<+[-<+]-<
** phase 6 **
(!!NL)--..<.
湯婆婆の処理としては、大半が固定文字列の出力になっていて、その合間々々に別の処理が挟まっている感じになっています。そこで、固定文字列出力を phase 1 ~ 6 に分けています。
その他は、初期処理 setup の他、名前の入力 input、フルネームの出力 full name、1文字の制限された名前を出力する limited name ( 3回 ) という構成です。
初期処理および固定文字出力
さて、では処理の大半を占める固定文字出力ですが、文字コードの数値がかなりばらつきがあるため、少数のセルでやりくりするとセルの値を増減させる手間がかさみます。
そこで、幾つかのセルで担当する数値範囲を決めておいて、そこで値を細かく増減させながら出力する文字コードにする、という管理にします。
その初期値を配置するのが setup の部分の処理です。
なお、UTF-8多バイト文字なので 128~ のコードを扱うわけですが、Brainf**kで出力する場合は mod 256 で見ますので、例えば 230 なら代わりに -26 を使う方が楽です。そのため、初期値はほぼマイナスの数値となります。
そうして、以下の画像は実際に使ったものに補足説明を入れたものですが、このようなチャートに従って、セルの移動と値の増減を管理していきます。

基準となるセルは、今回使う 3byte UTF-8 の文字として必ず最初に現れる -24~-29 の範囲の数値を扱うところにしています。-8, +1 は空として一括移動の目印代わりに使います。
長くなるので折りたたんでいますが、実際のチャートの全体は次のようになります。
文字出力チャート
| p | 文字 | コード | -8 空 |
-7 -76 |
-6 -90 |
-5 -101 |
-4 -111 |
-3 -115 |
-2 -120 |
-1 -124 |
基準 -27 |
+1 空 |
+2 7 |
+3 35 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 契 | -27 | +0 | |||||||||||
| 1 | -91 | -1 | ||||||||||||
| 1 | -111 | +0 | ||||||||||||
| 1 | 約 | -25 | +2 | |||||||||||
| 1 | -76 | +0 | ||||||||||||
| 1 | -124 | +0 | ||||||||||||
| 1 | 書 | -26 | -1 | |||||||||||
| 1 | -101 | +0 | ||||||||||||
| 1 | -72 | +4 | ||||||||||||
| 1 | だ | -29 | -3 | |||||||||||
| 1 | -127 | -3 | ||||||||||||
| 1 | -96 | +5 | ||||||||||||
| 1 | よ | -29 | +0 | |||||||||||
| 1 | -126 | +1 | ||||||||||||
| 1 | -120 | +0 | ||||||||||||
| 1 | 。 | -29 | +0 | |||||||||||
| 1 | -128 | -2 | ||||||||||||
| 1 | -126 | +2 | ||||||||||||
| 1 | そ | -29 | +0 | |||||||||||
| 1 | -127 | -1 | ||||||||||||
| 1 | -99 | -3 | ||||||||||||
| 1 | こ | -29 | +0 | |||||||||||
| 1 | -127 | +0 | ||||||||||||
| 1 | -109 | +2 | ||||||||||||
| 1 | に | -29 | +0 | |||||||||||
| 1 | -127 | +0 | ||||||||||||
| 1 | -85 | +6 | ||||||||||||
| 1 | 名 | -27 | +2 | |||||||||||
| 1 | -112 | -3 | ||||||||||||
| 1 | -115 | +0 | ||||||||||||
| 1 | 前 | -27 | +0 | |||||||||||
| 1 | -119 | +1 | ||||||||||||
| 1 | -115 | +0 | ||||||||||||
| 1 | を | -29 | -2 | |||||||||||
| 1 | -126 | +1 | ||||||||||||
| 1 | -110 | +2 | ||||||||||||
| 1 | 書 | -26 | +3 | |||||||||||
| 1 | -101 | -2 | ||||||||||||
| 1 | -72 | +0 | ||||||||||||
| 1 | き | -29 | -3 | |||||||||||
| 1 | -127 | -1 | ||||||||||||
| 1 | -115 | +0 | ||||||||||||
| 1 | な | -29 | +0 | |||||||||||
| 1 | -127 | +0 | ||||||||||||
| 1 | -86 | -1 | ||||||||||||
| 1 | 。 | -29 | +0 | |||||||||||
| 1 | -128 | -1 | ||||||||||||
| 1 | -126 | +2 | ||||||||||||
| 1 | NL | 10 | +3 | |||||||||||
| 2 | フ | -29 | +0 | |||||||||||
| 2 | -125 | +1 | ||||||||||||
| 2 | -107 | +3 | ||||||||||||
| 2 | ン | -29 | +0 | |||||||||||
| 2 | -125 | +0 | ||||||||||||
| 2 | -77 | -5 | ||||||||||||
| 2 | 。 | -29 | +0 | |||||||||||
| 2 | -128 | -3 | ||||||||||||
| 2 | -126 | +2 | ||||||||||||
| 3 | と | -29 | +0 | |||||||||||
| 3 | -127 | -1 | ||||||||||||
| 3 | -88 | -2 | ||||||||||||
| 3 | い | -29 | +0 | |||||||||||
| 3 | -127 | +0 | ||||||||||||
| 3 | -124 | -5 | ||||||||||||
| 3 | う | -29 | +0 | |||||||||||
| 3 | -127 | +0 | ||||||||||||
| 3 | -122 | +2 | ||||||||||||
| 3 | の | -29 | +0 | |||||||||||
| 3 | -127 | +0 | ||||||||||||
| 3 | -82 | +6 | ||||||||||||
| 3 | か | -29 | +0 | |||||||||||
| 3 | -127 | +0 | ||||||||||||
| 3 | -117 | -2 | ||||||||||||
| 3 | い | -29 | +0 | |||||||||||
| 3 | -127 | +0 | ||||||||||||
| 3 | -124 | -2 | ||||||||||||
| 3 | 。 | -29 | +0 | |||||||||||
| 3 | -128 | -1 | ||||||||||||
| 3 | -126 | +2 | ||||||||||||
| 3 | 贅 | -24 | +5 | |||||||||||
| 3 | -76 | +1 | ||||||||||||
| 3 | -123 | +1 | ||||||||||||
| 3 | 沢 | -26 | -2 | |||||||||||
| 3 | -78 | -2 | ||||||||||||
| 3 | -94 | +7 | ||||||||||||
| 3 | な | -29 | -3 | |||||||||||
| 3 | -127 | -1 | ||||||||||||
| 3 | -86 | -4 | ||||||||||||
| 3 | 名 | -27 | +2 | |||||||||||
| 3 | -112 | -5 | ||||||||||||
| 3 | -115 | +2 | ||||||||||||
| 3 | だ | -29 | -2 | |||||||||||
| 3 | -127 | +0 | ||||||||||||
| 3 | -96 | -2 | ||||||||||||
| 3 | ね | -29 | +0 | |||||||||||
| 3 | -127 | +0 | ||||||||||||
| 3 | -83 | +3 | ||||||||||||
| 3 | ぇ | -29 | +0 | |||||||||||
| 3 | -127 | +0 | ||||||||||||
| 3 | -121 | +2 | ||||||||||||
| 3 | 。 | -29 | +0 | |||||||||||
| 3 | -128 | -1 | ||||||||||||
| 3 | -126 | +2 | ||||||||||||
| 3 | NL | 10 | +0 | |||||||||||
| 3 | 今 | -28 | +1 | |||||||||||
| 3 | -69 | +9 | ||||||||||||
| 3 | -118 | +3 | ||||||||||||
| 3 | か | -29 | -1 | |||||||||||
| 3 | -127 | -1 | ||||||||||||
| 3 | -117 | +1 | ||||||||||||
| 3 | ら | -29 | +0 | |||||||||||
| 3 | -126 | +1 | ||||||||||||
| 3 | -119 | -2 | ||||||||||||
| 3 | お | -29 | +0 | |||||||||||
| 3 | -127 | -1 | ||||||||||||
| 3 | -118 | +1 | ||||||||||||
| 3 | 前 | -27 | +2 | |||||||||||
| 3 | -119 | -1 | ||||||||||||
| 3 | -115 | +0 | ||||||||||||
| 3 | の | -29 | -2 | |||||||||||
| 3 | -127 | +0 | ||||||||||||
| 3 | -82 | +1 | ||||||||||||
| 3 | 名 | -27 | +2 | |||||||||||
| 3 | -112 | +0 | ||||||||||||
| 3 | -115 | +0 | ||||||||||||
| 3 | 前 | -27 | +0 | |||||||||||
| 3 | -119 | +0 | ||||||||||||
| 3 | -115 | +0 | ||||||||||||
| 3 | は | -29 | -2 | |||||||||||
| 3 | -127 | +0 | ||||||||||||
| 3 | -81 | +1 | ||||||||||||
| 4 | だ | -29 | +0 | |||||||||||
| 4 | -127 | +0 | ||||||||||||
| 4 | -96 | +0 | ||||||||||||
| 4 | 。 | -29 | +0 | |||||||||||
| 4 | -128 | -1 | ||||||||||||
| 4 | -126 | +2 | ||||||||||||
| 4 | い | -29 | +0 | |||||||||||
| 4 | -127 | -1 | ||||||||||||
| 4 | -124 | +3 | ||||||||||||
| 4 | い | -29 | +0 | |||||||||||
| 4 | -127 | -3 | ||||||||||||
| 4 | -124 | +3 | ||||||||||||
| 4 | か | -29 | +0 | |||||||||||
| 4 | -127 | -3 | ||||||||||||
| 4 | -117 | -2 | ||||||||||||
| 4 | い | -29 | +0 | |||||||||||
| 4 | -127 | +0 | ||||||||||||
| 4 | -124 | +3 | ||||||||||||
| 4 | 、 | -29 | +0 | |||||||||||
| 4 | -128 | -4 | ||||||||||||
| 4 | -127 | +1 | ||||||||||||
| 5 | だ | -29 | +0 | |||||||||||
| 5 | -127 | +0 | ||||||||||||
| 5 | -96 | +0 | ||||||||||||
| 5 | よ | -29 | +0 | |||||||||||
| 5 | -126 | +1 | ||||||||||||
| 5 | -120 | -1 | ||||||||||||
| 5 | 。 | -29 | +0 | |||||||||||
| 5 | -128 | -2 | ||||||||||||
| 5 | -126 | +2 | ||||||||||||
| 5 | 分 | -27 | +2 | |||||||||||
| 5 | -120 | +0 | ||||||||||||
| 5 | -122 | -2 | ||||||||||||
| 5 | か | -29 | -2 | |||||||||||
| 5 | -127 | -1 | ||||||||||||
| 5 | -117 | +0 | ||||||||||||
| 5 | っ | -29 | +0 | |||||||||||
| 5 | -127 | +0 | ||||||||||||
| 5 | -93 | +3 | ||||||||||||
| 5 | た | -29 | +0 | |||||||||||
| 5 | -127 | +0 | ||||||||||||
| 5 | -97 | -4 | ||||||||||||
| 5 | ら | -29 | +0 | |||||||||||
| 5 | -126 | +1 | ||||||||||||
| 5 | -119 | +3 | ||||||||||||
| 5 | 返 | -24 | +5 | |||||||||||
| 5 | -65 | +4 | ||||||||||||
| 5 | -108 | +4 | ||||||||||||
| 5 | 事 | -28 | -4 | |||||||||||
| 5 | -70 | -5 | ||||||||||||
| 5 | -117 | +0 | ||||||||||||
| 5 | を | -29 | -1 | |||||||||||
| 5 | -126 | +0 | ||||||||||||
| 5 | -110 | -2 | ||||||||||||
| 5 | す | -29 | +0 | |||||||||||
| 5 | -127 | -1 | ||||||||||||
| 5 | -103 | -6 | ||||||||||||
| 5 | る | -29 | +0 | |||||||||||
| 5 | -126 | +1 | ||||||||||||
| 5 | -117 | +0 | ||||||||||||
| 5 | ん | -29 | +0 | |||||||||||
| 5 | -126 | +0 | ||||||||||||
| 5 | -109 | +1 | ||||||||||||
| 5 | だ | -29 | +0 | |||||||||||
| 5 | -127 | -1 | ||||||||||||
| 5 | -96 | +7 | ||||||||||||
| 5 | 、 | -29 | +0 | |||||||||||
| 5 | -128 | -1 | ||||||||||||
| 5 | -127 | +1 | ||||||||||||
| 6 | ! | 33 | -2 | |||||||||||
| 6 | ! | 33 | +0 | |||||||||||
| 6 | NL | 10 | +0 |
入力処理
続いて、最も面倒なのが名前の文字列を入力する部分です。
UTF-8は1文字1文字が可変長なので、先頭となる文字を見て判断した上で、それぞれを塊として保存しておく必要があります。
実行例に挙げた「荻野千尋」の場合は、「千」の文字を選ぶところまで含め、次のようなセル状況を作り出します。

固定文字用のセルの右側の領域に、-1 で区切りを設け、UTF-8の多バイト文字の塊を2セルずつ空けて配置します。また、後の処理のために、選んだ文字の逆インデクス(末尾からの文字数)を付け加えておきます。( 0 なら最後の文字、この例のような 1 だと最後の1つ前の文字 )
各文字の入力処理ですが、先頭の文字を読み込んだら、16で割った商を見てUTF-8で何バイトの文字になるかを判断します。ちなみに、入力終了 ( 改行 … 商 0 ) の判断も兼ねています。
そこまで厳密ではないので、15なら4byte文字、14なら3byte文字、12,13なら2byte文字、あとは 0 以外なら1byte文字(ASCII)とざっくりした判断です。
この判断により「あと何文字読み込めば良いか」が決まるので、コード数値を配置していくと同時に合計を更新します。
「荻野千尋」の場合の2文字目「野」( 先頭バイトが 233 ) を処理する場合、次の図のように推移します。
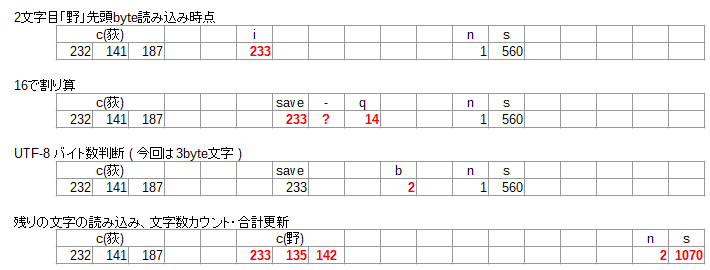
図中、n は文字数、s はコード合計を管理する数値として、読み込みに合わせ場所をずらしていきます。16で割り算した時の章が q です。隣の ? となっているセルは余りに対応するわけですが、特に使わないので具体的な数値は載せてません。で、b が「残りのバイト数」で、UTF-8 3byte文字なので残り2byteという状況を反映しています。
最後、名前を全部読み込んで改行によってループを抜けたら、合計÷文字数の余りを元に、逆インデクスの数値を割り出します。
名前の出力
最後に名前の出力部分です。
しかし、こちらについては入力処理で既に塊毎に配置ができていますので、まずはフルネームとして順々に塊をなめていくだけです。
一度フルネームを出力してしまえば、後は選んだ文字だけになります。そのため、フルネーム出力直後に、下の図のように、逆インデクスをもとに選んだ文字のすぐ左にマークとして -1 を記しておきます。
※この処理は、塊を単位とした可変距離指定移動の応用です。
これで、このマークを探して移動すれば、目的の文字に辿り着けるようになるということです。

これで各処理の説明は以上となります。
おわりに
可変長への対応等、Brainf**kをちゃんと使うのに必要な要素が盛り込まれているので、結構いい問題になっているのではないかと思います。細かい処理の説明は端折っていますが、ポイントでのセルの状況の推移を載せていますので、実際にBrainf**kで実装する際の参考にどうぞ。
Discussion