Jellyfish版FizzBuzz 92bytes実装(後日87に更新)
はじめに
導入
これは、Qiitaの「多言語FizzBuzz Advent Calendar 2022」の一環(12/1分)として、esolangの1つであるJellyfishでFizzBuzzを「golf的に(なるべく短く)」実装したものです。
結果、コード文字数92bytesを実現しました。
※2022/12/31追記: その後87bytesに更新したため、その差分についても章を追加しました。
なお、本記事に先駆けてこのコードはStackExchangeにも投稿しています。
Jellyfishとは
以前に「Jellyfish(esolang)の紹介」で紹介した、2次元的にノードを配置してネットワークを構成することで処理を実現するという特徴を持つ、一種の関数型言語です。
ある程度の処理の流れを把握していないと以降の説明を読み解くのは厳しいと思いますので、先に同記事の「プログラムの実行」の章を一読されることをお勧めします。
また、コード内で使用している組み込み関数等のリファレンスとしては公式の"Standard Library"ページをご覧ください。
FizzBuzz実装
コード全容
まずはコード全容です。
P
L,L, v"Buzz
1 1v"Fizz
E $X$,,S
LvLjXX *4
1 0*rE101b6
$R * E4
,1N1b19252
100
このコードはtio.runでの実行ページで実行させることができます。
ただ、このままでは見辛いので、制御文字を解釈してネットワークまで構成した段階の図を次に示します。記号の意味は上述の「Jellyfish(esolang)の紹介」での説明に合わせています。

短く実装するために、なるべく少ないノードで構成するというのもあるのですが、同じノードをオーバーラップして ( 複数の処理で使いまわすように ) 配置する、すきまを埋めるように詰めて配置する ( 今回は制御文字Xによる複数ブロックのすれ違い接続が典型 ) といったことが基本的な心がけとなります。
基本構造
では、FizzBuzzの処理を実現するにあたっての基本方針です。
Jellyfishは殊に配列の一括処理に長けており、+(加算)や*(乗算)といった基本関数はそれ自身配列のベクトル処理機能を持っていますし、そうでない関数も、他言語でのmapに類した機能を持つL演算子によって処理をベクトル対応させることが可能です。
※本コードでは各所にL演算子が出てきますし、逆に他の演算子は使っていない実装になっています。
今回着目したのは、L演算子と,(連結)関数の組み合わせによる文字列配列同士の結合です。
次の図にあるように、連結が配列の各文字列同士に作用し、「文字列同士を結合した配列」を作ることができます。
※なお、内部的に文字列は文字配列として扱われており、Lの作用を「配列同士」にするため、第一引数に「要素同士」の 0 ではなく 1 を指定する必要があります。
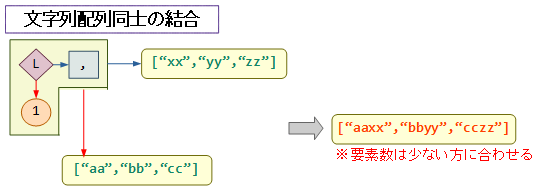
この文字列配列同士の結合を活用し、3つの文字列配列、数文字列配列、fizz配列、buzz配列を結合し、文字列単位で改行付き出力を行うP(matrix-print)関数で一括出力するのが、今回のコードの基本構造です。

各配列は、FizzBuzzで出力する内容を数字、Fizz、Buzzで分類して分解したものになります。該当しない部分は空文字列で埋めることになります。つまり、各配列は次の通りになります。
- 数文字列配列
["1","2","","4","","","7,",…] という、3,5の倍数部分を空文字列にした、数字の連番を構成します。 - fizz配列
["","","Fizz","","","Fizz",…] という、空文字列2つにFizzを繰り返す配列を構成します。 - buzz配列
["","","","","Buzz","","","","","Buzz",…] という、空文字列4つにBuzzを繰り返す配列を構成します。
なお、結合の際に要素数(文字列の数)は最も少ない配列に合わせられます。そのため一部に100個以上の要素の配列があっても問題ありません。実際、後述するfizz配列・buzz配列は敢えて101個の要素の配列として作成しています。
fizz配列・buzz配列生成部
ここからは、上記「基本構造」で説明した各配列を構成する話です。
先に簡易な方から、ということでfizz配列・buzz配列をまとめて取り上げます。
これには、v(drop)関数で丁度対応できるためです。
次の図のように、数値配列と文字列を引数に取るv関数は、「元の文字列から各数値分の文字数をdropした文字列配列」を作ることができます。

これを利用すれば、配列の要素として 0 を指定した分は元の文字列がそのまま残りますし、十分大きな数を指定した分は空文字列が残ります。
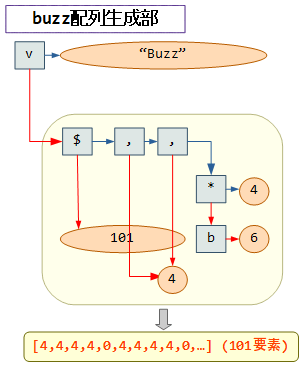
例えば、fizz配列を生成する部分のコードブロックは次の図で示す部分となります。

v関数に対して、[4,4,0,4,4,0,…] と、4を2つに0を1つ繰り返す101要素の配列と、文字列Fizzを渡すことでfizz配列を作ります。ちなみに、敢えて101要素にしているのは、後述する数文字列配列の作成で出てくる101とノードをオーバーラップさせるためです。
そして101要素分の配列については、$(reshape)関数が有用です。reshapeの名の通り配列の形状を変化させる機能を持ちますが、元の配列の要素数が少ない場合、「同じパターンの繰り返しで要素数を拡大する」という効果を持っているためです。
そのため、b,*で作成した [4,4,0] という3要素の配列を拡大することで目的の101要素分の配列を作成することができます。
※b,*の機能については、後の「数文字列配列生成部」で具体的に説明します。
buzz配列についてもほぼ同じ構成になります。
buzz配列を生成する部分のコードブロックは次の通りです。
fizz配列生成の時と同様、$関数で101要素の配列を作り、v関数に文字列Buzzと共に渡します。
$で拡大する元になるのは [4,4,4,4,0] という5要素の配列で、これはfizz配列生成時に作った [4,4,0] に、,で更に4を付け加えることで作成します。
数文字列配列生成部
残りは数文字列配列の部分となります。
しかし、次の図に示すように全体から見てほぼ南半分を占めるコードで実現しており、fizz配列・buzz配列よりも若干複雑な構造になっています。
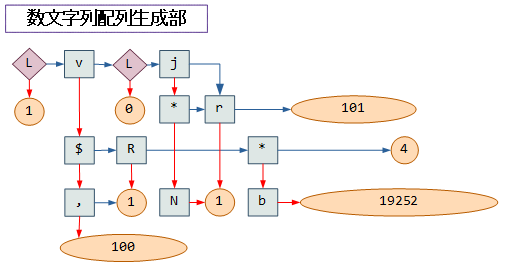
数文字列配列の概要
数文字列配列がより複雑となるのは、fizz配列・buzz配列がFizzもしくはBuzzという同一の文字列からのdropで済むのに対し、["1","2","3",…] というばらばらの文字列の一部のみを空文字列に置き換える必要があるためです。
そのため、単一のvでは機能的に不十分なのですが、ここでもL演算子を組み合わせることで、個別のdropを行い対応させることができます。
おおまかには次の図のようなコードになります。

すなわち、L,vを組み合わせ、「dropする文字数の2次元配列」と「drop元の文字列」から、「個別にdropされた文字列の2次元配列」を作るということです。
次の図のように、3,5の倍数に対応したところに大きな数 ( 今回は4 ) をセットした2次元配列と、["1","2","3",…] という連番の文字列の配列とを組み合わせることで、数文字列配列を作成します。
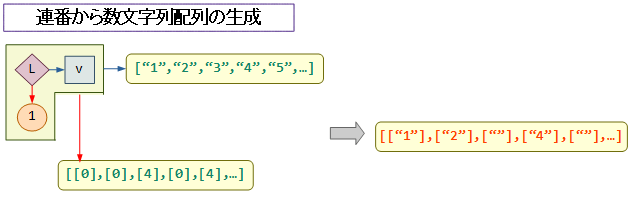
なお、本来の目的は「文字列の配列の作成」であって、このコードでできる「文字列の2次元配列」は微妙に合っていないのですが、実際には配列結合の時に影響が出ないため、このコードのままで問題ありません。
drop用の配列の整備
では、連番をdropしていく際の2つの配列の生成についてです。
まず、dropする文字数の2次元配列を生成するのは、次のコードブロックが該当します。
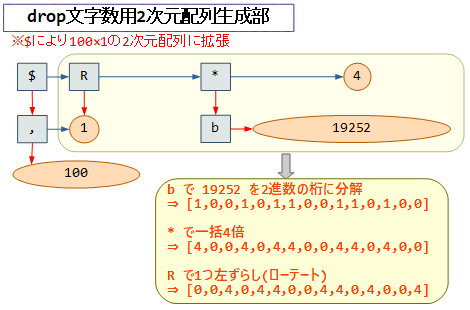
fizz配列・buzz配列の時と同じように、最終的に$(reshape)関数で拡大するのですが、その元になるパターンは15要素の配列です。
このような配列を作る時に便利なのがb(base encode)関数であり、1引数の場合は元の数字から2進数展開した各桁(0,1)の配列にしてくれます。それを*(乗算)で4倍にしています。
※このb,*の組は、fizz配列の時に 6 → [4,4,0] という配列生成でも使っています。
ただ、「2進数展開」ですから、先頭の要素が必ず1になってしまい、0から始まる配列を直接作ることができません。そこを補うのがR(rotate)関数で、1要素左にずらすことで 0から始まる配列に直しています。
そして$による拡張ですが、こちらは [100,1] という配列を指定することで、拡大しつつ 100×1 の2次元配列を作り出します。これで目的の2次元配列の完成です。
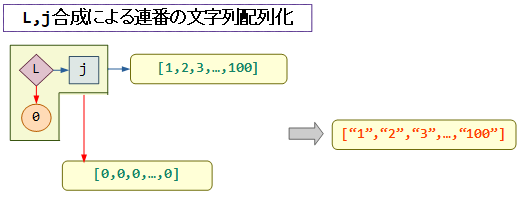
残りは ["1","2","3",…] という連番の文字列を生成する部分です。
次の図のコードブロックが該当します。
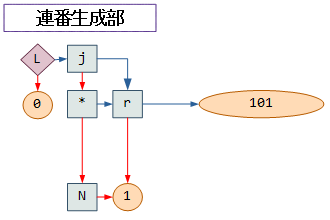
これは、次の図のように j関数に第一引数として 0 を指定した場合の uneval(文字列化) 機能を、Lによって配列に一括適用する構成となっています。
r(range)関数により生成した [1,2,3,…,100] という連番の配列と、それに N(negation)関数から得られた 0 を * で乗じて作り出した 0 のみの配列、この2つを渡す形となります。
以上で、FizzBuzzを実現するための各コードの説明を網羅したことになります。
87bytesへの短縮(2022/12/31追加)
本記事投稿後、短縮できるポイントがあったことに気付き、更に5bytes記録を更新しました。
実は、12/13時点でもう更新はしていたのですが、他の記事との兼ね合いもあって解説を書くのが先延ばしになっていたような状況でした。
では、87Bの更新版のコードですが、次のようになります。
P
L,L, v"Buzz
1 1v"Fizz
E $X$ S
LvLjXX v*4
1 0*rES2b30
$R *'e
,1N1b'䬴
'd
ネットワーク構成後の状況は、次に示す図のようになっています。

変更点は主に次の2点です。
- Fizz配列/Buzz配列生成用の数値配列生成のコンパクト化(2B分)
従来、v(drop関数)に渡す数値配列として、Fizz配列用に[4,4,0]という3要素の配列を作ってから、2回 4 を付け足して Buzz配列用の[4,4,4,4,0]を作っていたところ、逆にBuzz配列用の[4,4,4,4,0]を作ってから2要素dropして Fizz配列用の[4,4,0]を作るように組み替えました。
これにともない、コード中央部にあった 101 を一段下に追いやり、スペースを詰めています。( 後述しますが、101 は'eという単一の文字定数ノードに置き換えています )
なお、数文字配列で出てくる*(乗算) の引数 4 のノードを無くしていますが、ここは 4 でなくても適度に大きい数なら何でも良いので、既存の 101 のノードを使いまわすようにしています。
更新後のFizz/Buzz配列生成部を抜き出した図は次の通りです。


- 文字定数ノードによる数値の代替(3B分)
従来のコードには、南西部分に 100、南東部分に 19252、中央に 101 という3つの数値定数のノードがありました。
しかし、実は Jellyfish では文字定数を指定しても、多くの場面でその文字コードを数値の代替として使うことができ、コードの短縮につなげられるケースが多いことに気付いたため、本コードにも適用しました。
100 は、ASCIIコード100のdに、101はその次のeに、そして 19252 はユニコード 19252 の䬴に置き換えています。( 文字定数なので、先頭に'が付きます )
なお、ノードの東西位置を計算する上での文字数としては全て共通で1文字 ('も入れると2文字 ) という扱いになるのですが、コード長自体は ASCII/UTF-8 文字でのバイト数で換算しますので、今回それぞれ 1byte ずつの短縮になっています。
おわりに
StackExchangeに投稿した折に検索してみたのですが、Jellyfishのコードを書いている人は、特に今回ほどの規模となると見つかりませんでした。しかし、2次元的に実装するところにも面白さがある言語であるため、これを機に実装に挑戦する人が増えると幸いです。
Discussion