エンジニア向けのPerplexityを開発して得た7つの知見
概要
誰もが一度耳にしたことがあるPerplexityのようなWeb検索AIツールの、エンジニアに特化したバージョンを開発した際に得られた知見をまとめてみました。
ちなみに普段は生成AIに助けられっぱなしの私ですが、この記事は全部キーボードをカタカタ打って書いております。(記事を書くのが好きなため楽しみを奪われたく無いのが主な理由です)
なぜ作ったの?
開発した背景としては私自身がPerplexityのヘビーユーザーでした。
今ではChatGPTやGeminiもWeb検索できるようになりリアルタイムの情報に簡単にアクセスできるようになりましたが、以前はリアルタイムの情報を検索する際はPerplexity一強だったかと思います。
そのため最初からUIに慣れ親しんでいたのと、必要最低限の機能で即座に検索結果を出力してくれるUXが好きでずっと使っておりました。
しかし単に検索の用途であれば問題ないのですがエンジニアとして仕事をする際に情報検索をするたびに毎回「〇〇について検索して。参考コードは以下の通りです。」のように同じプロンプトを打つのがしんどくなってきました。
利用する場面はほとんど調査やバグ修正方法を探すなど用途が限られているので、エンジニア向けのUIに特化することでこの手間を省けるような気がしました。
またWeb Browserのように同時並行で複数の項目を検索する際にUIが少し使いづらかったのでタブ切り替えで検索結果を管理したいな、と思いエンジニアに特化した検索ツールの開発を始めました。
作った機能
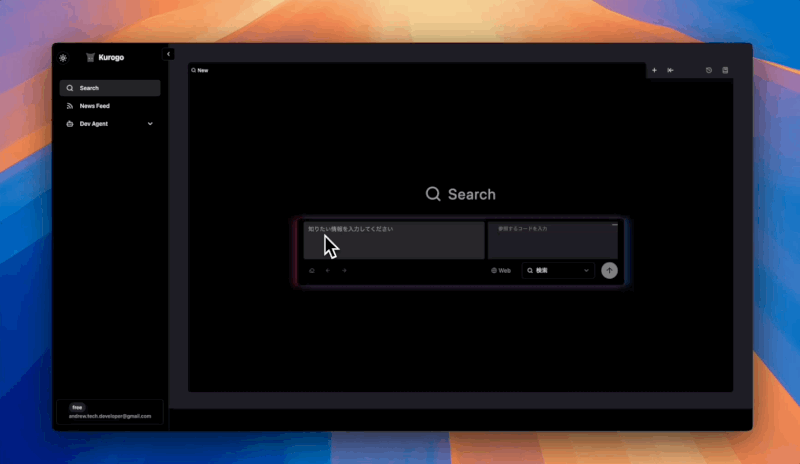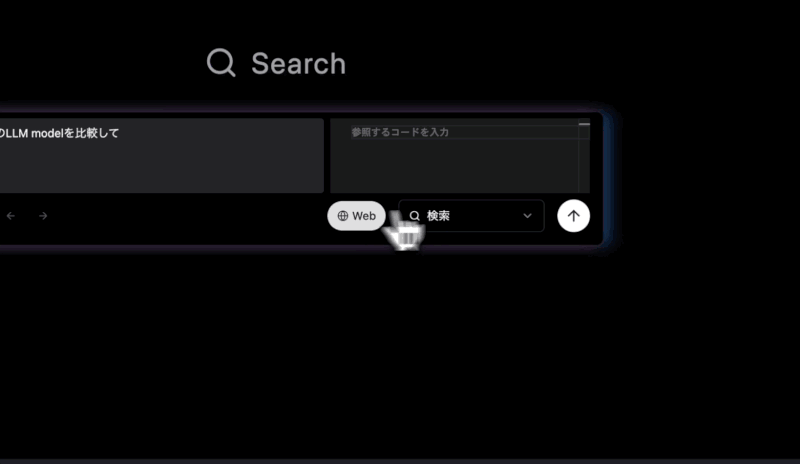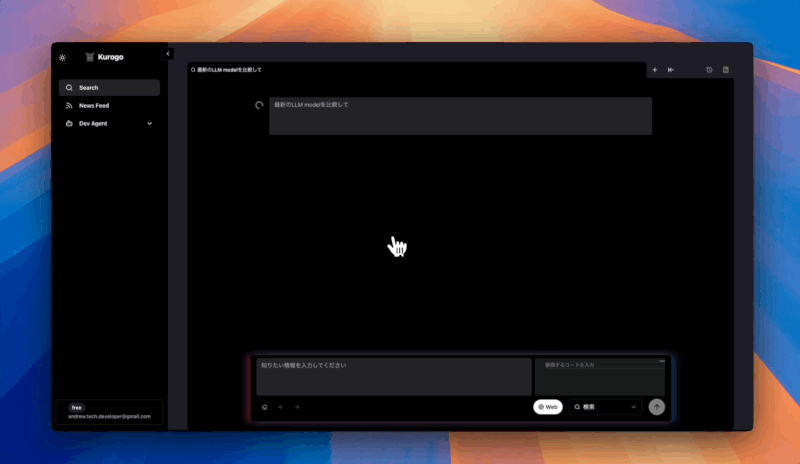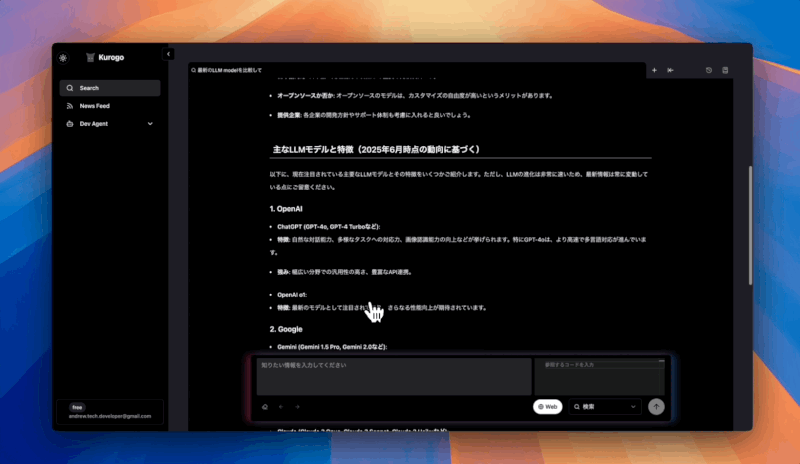
コード専用の入力欄を作成
参照するコードを入力できるように専用の入力欄を用意しました。
使うEditor Packageは色々悩んだのですが拡張性が高かったのでmonaco-editor/reactを利用することにしました。
プルダウンでプロンプト切り替え
用途によってプロンプトを切り替えることができます。
現在のところ「検索」・「エラー修正」・「作業」・「コード自動修正」・「図を作成」の5つをサポートしてます。(もはや検索ツールからはみ出てる気がしますがユーザーからフィードバックをいただき増やしていったらこうなってしまいました...
タブ切り替えで並列検索しやすく
Chrome Browserのようにタブを複数作成して検索することができます。
ちなみにタブはドラッグアンドドロップで並び替えができます。(dnd-kitというPackageを利用してます)
アーキテクチャー
簡単にですが検索周りの処理の流れは以下のようになります。
アプリはRemixで動いており、Web検索としてBraveのAPIを利用しLLMはGeminiを利用しております。
前置きが長くなりましたがここから本題となります。
得られた知見
1. Web検索にはBrave APIが便利
ユーザーの情報をもとに関連度が高いWebサイトを取得するには検索サービスのAPIを利用するか自前でクローラーを作るか大きく二択に分かれるかと思いますが、自前でクローラーを作るのはめちゃめちゃ大変なので既に世にある検索サービスを利用させてもらうことにします。
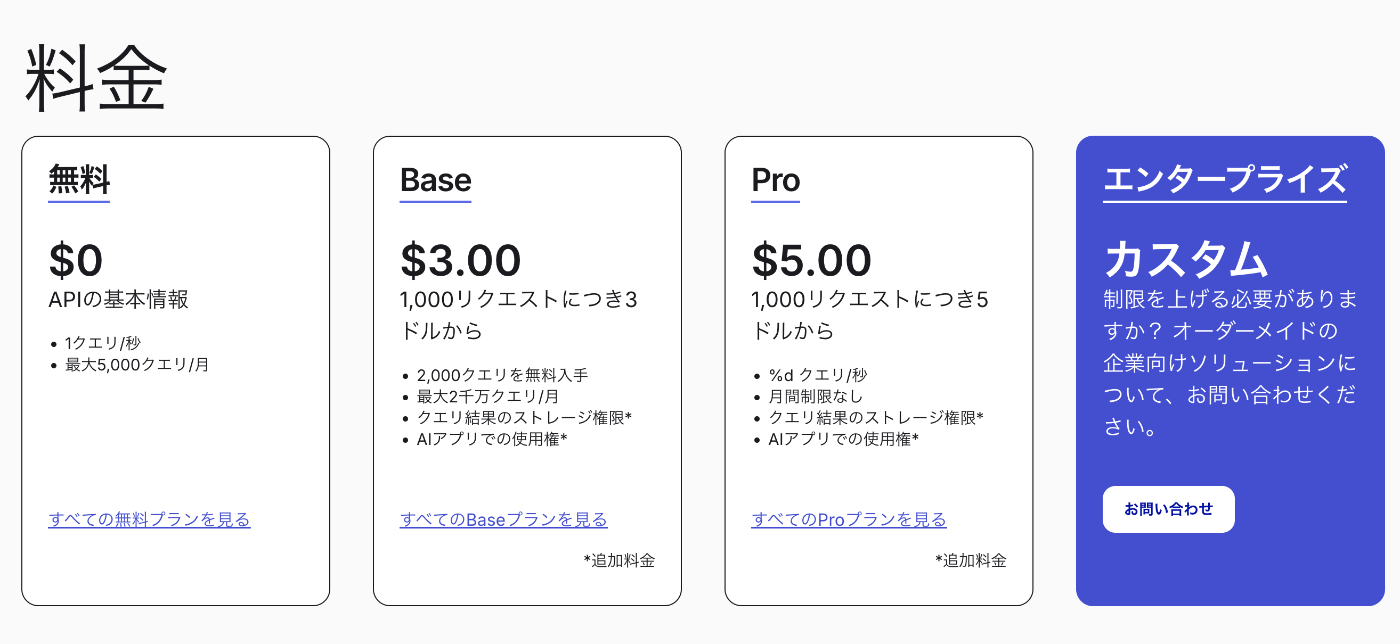
1番有名なのはGoogleのSearch APIかと思いますが、無料枠が1日あたり100件なのと有料プランでも1日あたり1万クエリまでしか使用できないので、将来の拡張性を見越して別のツールを検討しました。
そこで見つけたのがBraveのSearch APIです。
BraveはGoogleに代わる次世代の検索エンジンとしてBrave Software, Inc.により開発されている検索エンジンで、個人情報の保護に特化しているのが特徴です。
採用した理由としては月額3ドルで月2,000万クエリ利用ができてコスパが良かったのと、月額5ドルのProプランにすれば上限がなくなるのが魅力的だったからです。
参考: https://brave.com/ja/search/api/
またAPIドキュメントも充実しており開発しやすかったのでおすすめです。
2. 現時点でコスパが最もいいLLMはGemini Flash 2.5
2025年7月初旬の現在においてパフォーマンスとコストのバランスが1番良いのはGemini Flash 2.5であると感じました。
検索結果をmarkdownで出力する際にGemini Flash 2.5より精度の低いモデルだとコードのインデントが崩れるなどしたので出力速度や安定性、価格を加味してこのmodelを利用することにしました。
ですが移り変わりが激しいので、新しいmodelが出たら利用して採用できないか都度チェックしております。
vellum.aiというサイトで簡単に比較できたので気になるモデルがあったら比較してみてください。

3. 検索ではエラーハンドリングが重要
Brave Search APIで返却されるURLをもとに各websiteのコンテンツを取得しにいくのですが、サイトによってはjsが動作する環境でないと動かない場合やブラウザ以外でのアクセスを遮断してる場合はrequestがtimeoutするまでユーザーが待たされるケースが発生します。
なので返却されるHTMLからjavascript is not availableなどの文字が含まれている場合に検索結果から除外する実装や、ある一定の時間responseが返却されない場合強制timeoutさせる必要があります。
TypeScriptでの実装の場合AbortSignalを利用したり、以下のようなtimeoutを設定できるPromiseを返却する関数を作って対応しました。
function promiseWithTimeout<T>(
promise: Promise<T>,
timeoutMs: number,
): Promise<T | undefined> {
const timeoutPromise: Promise<undefined> = new Promise((resolve) => {
const id = setTimeout(() => {
clearTimeout(id);
resolve(undefined);
}, timeoutMs);
});
return Promise.race([promise, timeoutPromise]);
}
またWebサイトの情報を取得する場合、高頻度でリクエストを送り負荷をかけるような仕組みは避ける必要がありその点は注意が必要です。
著作権に関しても、Webサイトの情報をそのまま利用したり参照元の表示がないと問題となるケースがあるので注意が必要です。
4. LLMの扱いはVercelのai sdkが便利
利用するLLMのAPIを直接呼び出すことも可能ですがai sdkなどのLLMをwrapしてくれるツールを使うとmodelの切り替えが楽になりおすすめです。
自分で実装するには面倒なretry処理やresponseのschemaを指定するのもai sdkを利用すれば以下のように簡単に実装できます。
import { openai } from '@ai-sdk/openai';
import { streamObject } from 'ai';
import { notificationSchema } from './schema';
import { z } from 'zod';
// define a schema for the notifications
export const notificationSchema = z.object({
notifications: z.array(
z.object({
name: z.string().describe('Name of a fictional person.'),
message: z.string().describe('Message. Do not use emojis or links.'),
}),
),
});
// Allow streaming responses up to 30 seconds
export const maxDuration = 30;
export async function POST(req: Request) {
const context = await req.json();
const result = streamObject({
model: openai('gpt-4-turbo'),
schema: notificationSchema,
maxRetries: 3, // retryの回数を指定
prompt:
`Generate 3 notifications for a messages app in this context:` + context,
});
return result.toTextStreamResponse();
}
参考: https://ai-sdk.dev/docs/ai-sdk-ui/object-generation
5. tokenを減らすには前処理が大事
LLMにWebsiteの情報を要約してもらう際にHTMLからできるだけ不要な情報を削ぎ落としLLMに渡すことで費用を下げ、かつoutputの精度を向上させることができるのでとても重要です。
具体的にはHTMLをregexなどを用いて<script>tagや<img>などの不要な要素を除外することが肝心です。
const formatHtml = htmlString
.replace(/<script[^>]*>[\s\S]*?<\/script>/gi, "")
.replace(/<head[^>]*>[\s\S]*?<\/head>/gi, "")
.replace(/<style[^>]*>[\s\S]*?<\/style>/gi, "")
// 他にも適宜追加
6. プロンプトは英語でAIに考えてもらう
プロンプトを考える際、様々なformatがあり人の手で書くのが大変なのでAIに指示して作らせるのが楽です。
また英語での学習データが多いためか英語で指示した方が体感精度がよかったので以下のようにまず雑にLLMに指示して英語でプロンプトを作成してもらい、結果を見て追加で指示を加えて作り上げていくのがおすすめです。
Webのコンテンツを要約するシステムプロンプトを英語で書いてください。
- markdown形式で出力して
- 内容に沿ってheadingsをつけて
- 結果のみ日本語で出力して
7. できるだけ並列実行&StreamでResponse返却
検索結果をできるだけ速くユーザーに表示するためPromise.allを使った並列実行やStreamでResponseを返却することがUXを上げるために重要になってきます。
LLMの出力をStreamで返却するには前述したai sdkを使えば簡単に実装することができます。・
import { openai } from '@ai-sdk/openai';
import { generateId, createDataStreamResponse, streamText } from 'ai';
export async function POST(req: Request) {
const { messages } = await req.json();
// immediately start streaming (solves RAG issues with status, etc.)
return createDataStreamResponse({
execute: dataStream => {
dataStream.writeData('initialized call');
const result = streamText({
model: openai('gpt-4o'),
messages,
onChunk() {
dataStream.writeMessageAnnotation({ chunk: '123' });
},
onFinish() {
// message annotation:
dataStream.writeMessageAnnotation({
id: generateId(), // e.g. id from saved DB record
other: 'information',
});
// call annotation:
dataStream.writeData('call completed');
},
});
result.mergeIntoDataStream(dataStream);
},
onError: error => {
// Error messages are masked by default for security reasons.
// If you want to expose the error message to the client, you can do so here:
return error instanceof Error ? error.message : String(error);
},
});
}
参考: https://ai-sdk.dev/docs/ai-sdk-ui/streaming-data
宣伝
最後に開発したサービスの宣伝をさせてください。
「Kurogo AI」というサービスでKurogoにした理由としては、歌舞伎などで裏方で演者をサポートする「黒衣」から来ており、AIの力でエンジニアの裏方としてサポートするツールを作りたいという思いで開発しております。
PerplexityやDevinのような開発支援ツールが海外でたくさん生まれている一方で日本ではまだまだ少ないように感じているので、日本の生成AIコミュニティを盛り上げられるサービスを開発できるよう、今後も機能追加していきます。
ぜひこの機会に利用してみていただけると嬉しいです。
Discussion