重すぎるdbt docs generateを動かす試行錯誤
この記事はdbtアドベントカレンダー2024に寄稿しています。
皆さんのdbtプロジェクトでは、dbt docs generateコマンドを問題なく実行できていますか? スムーズに実行できている貴方は幸運の持ち主です。
残念ながら私が直近運用しているプロジェクトでは、モデルが多すぎてローカルで実行してもメモリを食い尽くしてしまう状態です。
なんとか実行できるという場合でも10分以上掛かることが多いため、ヘビーユーザーであればあるほど、dbt docs関連で悩むことが増えてくるのではないでしょうか。
今回は
- dbtのドキュメント機能の仕組みと問題点
- それでも頑張ってdbt docsコマンドを実行する方法
を整理します。
dbt docs generateとは
dbt docs generateは、dbtのモデルやソースの情報を元に、データカタログとなるドキュメントのソースを生成するコマンドです。
ドキュメント機能の構成要素は、以下の3ファイルです。
- manifest.json
- index.html
- catalog.json
manifest.jsonはdbtでrunやbuildしている際のパースやコンパイル時に作成されるファイルで、モデルやソースに関するメタデータが含まれています。dbt docs generateコマンド実行時もデフォルトでは追加でコンパイルが実行されます。
また、フロントエンドのソースであるindex.htmlは元々dbt-core内に存在するファイルをtargetディレクトリにコピーしています。
最後のcatalog.jsonを生成する過程では、DWH側にクエリを投げてデータを追加で取得しています。生成されるSQLのソースコードは、macroとして定義されており、BigQueryではINFORMATION_SCHEMAからデータを取得する仕組みになっています。
INFORMATION_SCHEMAへのクエリはデータセット単位で発行されますが、このクエリからデータを取得して加工する一連のプロセスが重さの原因になっています。
パフォーマンス向上のための改修
dbt docs generateコマンドが重いというのは昔から言われており、パフォーマンス改善や効率化を目的とした改修がdbt core 1.6~1.7辺りでいくつか行われています。
不要なデータを取得しないようにする改修
過去のバージョンのdbt coreでは、sourceやmodelが入っているデータセットが巨大かつ、そのデータセットのごく一部のテーブルしかdbtでは使用していないという場合、本来不要なテーブルのメタデータまで大量に取得してしまうという課題がありました。
この問題点については、dbt core 1.7で修正されており、現在ではdbtで定義されているリソースだけ取得するようなフィルター処理が追加されています。[1][2]
このように、16,17行目のデータセット名とテーブル名のANDフィルターがループ処理で作成されています。
ただし、この方法にもやや問題があり、
- 完全一致でのフィルタリングとなっているため、sourceでワイルドカードを使用する日付シャーディングテーブルは対象から除外される
- 同一データセット内に大量にsourceやmodelを定義していると、クエリ自体のbyte数がBigQueryの制限を超える可能性がある
という課題が残っています。
また、同一データセット内に大量にテーブルを存在している(数十万件単位)と、INFORMATION_SCHEMAに対するクエリが実行できる上限値を超えてしまうため、巨大なデータセットがある場合は運用を見直す必要があるかもしれません。
オプションの追加
dbt docs generateコマンドのオプションも処理の高速化や利便性向上のために、いくつか新しく追加されています。
--no-compile
docs generate時に実行されるコンパイル処理をスキップします。既にmanifest.jsonにデータがある場合を除き、コンパイル済のクエリが見れなくなるという比較的大きなデメリットはあるのですが、DWHの認証情報なしでdbt docsが作成できるようになります。
--empty-catalog
DWHに対してクエリを投げる処理がスキップされ、以下のような空のcatalog.jsonが作成されます。
{
"metadata": {
"dbt_schema_version": "https://schemas.getdbt.com/dbt/catalog/v1.json",
"dbt_version": "1.8.x",
"generated_at": ...
"invocation_id": ...
"env": {}
},
"nodes": {},
"sources": {},
"errors": null
}
空のカタログを作るとドキュメントにも何も表示されないのでは? と思うかもしれませんが、前述のとおり、ドキュメントの情報ソースとしてはmanifest.jsonもあるため、そちら由来の以下のようなメタデータはそのまま見ることができます。
- データリネージ
- カラム名
- カラムの説明文
- テスト
- コンパイル済のクエリ(コンパイルが実行済の場合)
一方で
- カラムのデータ型
- テーブルの行数
といった情報は欠落します。[3]
manifest.jsonにはデータ型の情報もあるので、追加することは理論上は可能そうですが、現状はフロントエンド側で無視する仕様になっているようです。
--select
以前はdbt docs generateでは--selectオプションは使えませんでしたが、このオプションもdbt core 1.7で追加されました。
特定のパイプラインだけのcatalog.jsonが必要であれば、このオプションを使うことで、必要な箇所の情報だけを取得することができます。
ただこのselectオプションも若干まだバグがあるようで、まれに指定していないnode以外にも反応してしまう挙動が見られました。[4]
状況に合わせた使い方
このように様々な改修は行われていますが、根本的な重さの解消には至っていません。解決のためには、おそらくアーキテクチャの抜本的な見直しが必要になりますが、現状はdbt cloud側のデータカタログであるdbt explorerに開発リソースが割かれているため、すぐに何かが劇的に変わることは期待できないでしょう。
データ変換処理のrunやbuildとは無関係な処理なため、使わないという選択肢ももちろんあります。しかし、dbtで苦労して定義したメタデータを使ってデータカタログを低コストで作成する方法として、このドキュメント機能に勝る選択肢がまだ少ないというのも現状です。
また、dbtのメタデータを取り込めるサードパーティのデータカタログも増えていますが、こちらもdbt docs generateコマンドの実行を前提としている場合が多いです。
dbt explorerについても、jobの実行結果など様々なリソースからデータカタログの情報を取得していますが、カラム情報についてはdbt docs generateコマンドの実行が必須となっています。
ということで、dbtのメタデータをフル活用するためには、dbt docs generateコマンドを実行しなければいけない状況はまだまだ多いため、ここまで紹介したオプションと組み合わせることで、どうすれば効率的に実行できるかを考えていきます。
テーブルの行数など、一部の情報は欠落しても良いdbt coreユーザー
--empty-catalogオプションを使うと、最も重いDWHからのメタデータ取得とcatalog.jsonの作成処理をスキップできるため、非常に高速になります。
高速化が達成できることに加えて、manifest.jsonにあるカラムのdescriptionやテスト等の主要な情報は残るので、dbt coreユーザーであれば、これで十分という方も多いかもしれません。
また、github actionなどのCI環境でコマンドを実行しており、DWHの認証情報を持たせたくない場合は、--no-compileオプションも合わせて使用することで、認証情報なしでドキュメントが作成できます。
dbt Explorer向けにcatalog.jsonが必要なdbt cloudユーザー
--empty-catalogオプションは一見万能なように見えますが、使えない場合もあります。dbt cloudでは--empty-catalogオプション付けてdbt docs generateを実行しても、dbt explorer側にカラム情報が追加されないため、catalog.jsonに実際のデータを入れる必要があります。
なんとかして実データを持つcatalog.jsonを生成する必要がありますが、考慮すべきポイントとして、dbt explorerはcataolog.jsonの形式でデータを生成することを求めているだけで、単一の巨大なcatalog.jsonを作る必要はありません。
そのため、--selectオプションを使い、複数のjobで小さなcatalog.jsonを生成しても、個別にdbt explorerに取り込まれます。
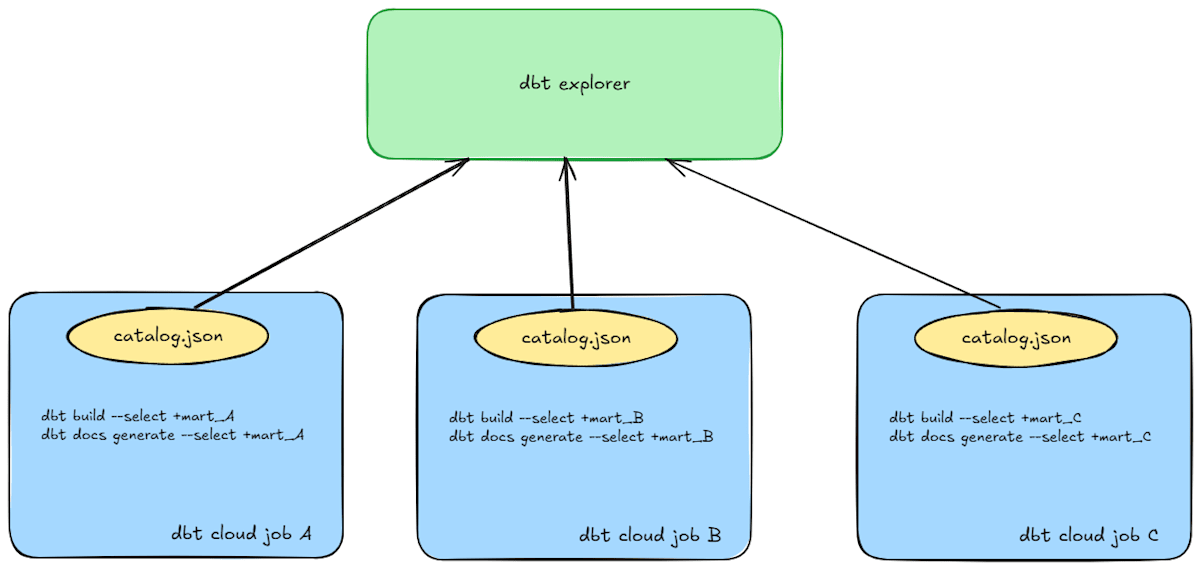
各パイプラインの実行と一緒に同じ範囲のdocs generateも実行する例
--selectオプションを使って範囲を絞ることで、DWHのクエリ発行数や扱うデータ量も大幅に減らせるため、巨大なdbtプロジェクトであればあるほど、処理が高速になります。
最後に
直近追加されたコマンドのオプションを組み合わせることで、一部は妥協しつつも、dbt docs generateコマンドの実行を軽くすることができました。
また、最近ではdbt-osmosis等メタデータもDWHと同期させつつ自動生成するのが主流なので、データカタログを作る際にわざわざ追加でSQLを実行しない方法も将来的には可能になっていくかもしれません。
その他参考資料
-
ソースコードやログを見ても今のところ原因不明ですが、どういった条件で発生するのか特定できればissueを立てる予定です。 ↩︎
Discussion