Rでiris dataset, titanic datasetをロードする方法
機械学習や、データフレームの操作のために既存のデータセットを用いて、解析または練習することがあります。有名なデータフレームとして,Iris(アヤメ), Titanicのデータがあります。
Iris データセット
Iris データセットは、機械学習で最もよく使われるデータセットの一つです。イギリスの統計学者であるロナルド・エイルマー・フィッシャーが1936年に発表した論文で使用したデータセットで、アヤメの花びらの長さ、幅、深さ、および種の種類を記録したものです。
このデータセットは、教師あり学習における分類タスクのベンチマークとしてよく使用されます。データセットには 150 個のサンプルが含まれ、それぞれ 4 つの属性と 3 つのクラス (Setosa、Versicolor、Virginica) が割り当てられています。
Iris データセットは、教師あり学習のアルゴリズムを理解し、実装するための貴重なリソースです。また、データ分析や可視化の練習にも役立ちます。
Titanic データセット
Titanic データセットは、1912 年に沈没したタイタニック号の乗客に関するデータセットです。このデータセットには、乗客の年齢、性別、社会階級、乗船券の種類、救命ボートに乗っていたかどうかなど、420 人の乗客に関する情報が含まれています。
このデータセットは、機械学習における生存分析タスクのベンチマークとしてよく使用されます。データセットには、生存したか死亡したかが記録されており、乗客の属性に基づいて生存確率を予測するモデルを構築することができます。
Titanic データセットは、機械学習のアルゴリズムを理解し、実装するための貴重なリソースです。また、データ分析や可視化の練習にも役立ちます。
ロード
iris datasetをロードするには以下のコマンドです。
data(iris)
irisという変数にデータフレームが格納されています。
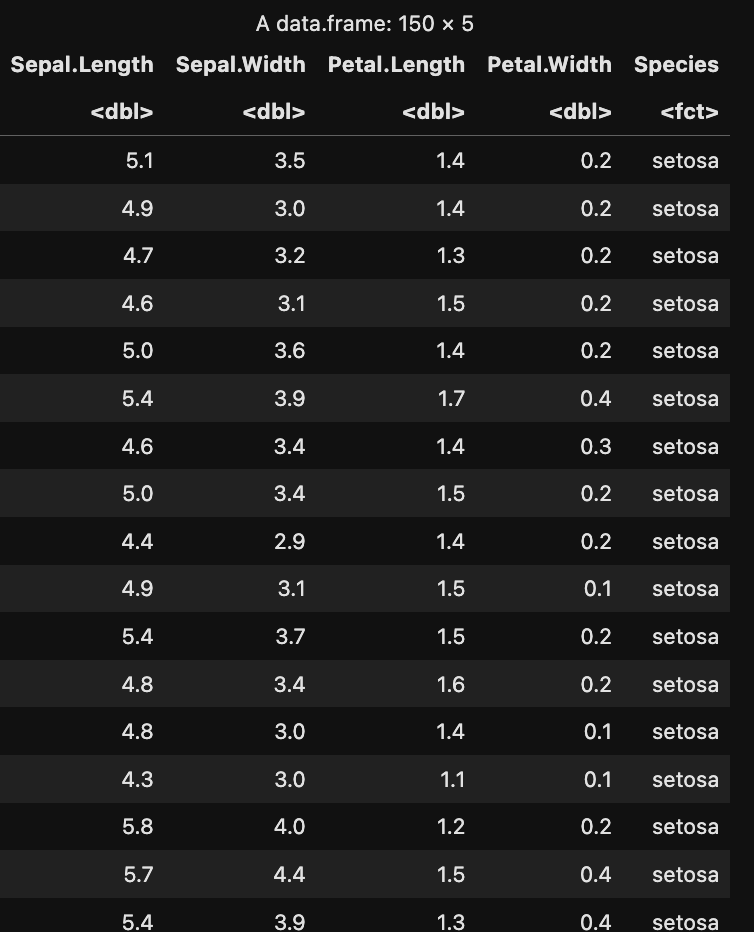
iris
Titanicのdatasetをロードするには以下のコマンドです。
# datasetsパッケージをロード(デフォルトでインストールされているので実行する必要はありません)
library(datasets)
# Titanicデータセットをロード
data("Titanic")
# Titanicデータセットの内容を表示
print(Titanic)

データセットをデータフレーム形式で利用したい場合は、次のコードを使用してください。
titanic_df <- as.data.frame(Titanic)
# データフレームの内容を表示
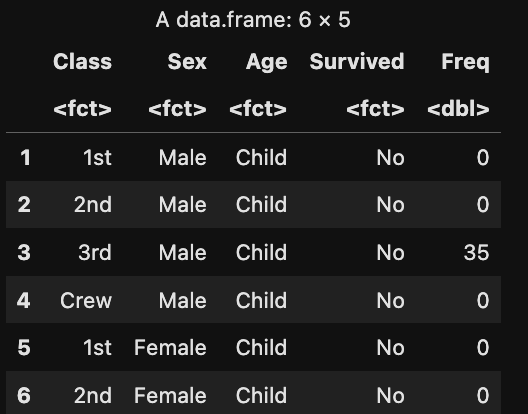
head(titanic_df)
Discussion