【何となく理解したい】Apache Kafkaってなに?
覚えたい理由の背景
普段の業務の中でKafkaを扱うことが時々あり、業務に関わる部分以外の知識がないので全体像をざっくりを理解したいと思ったから。DevOpsエンジニアとしての必要スキルでもあるから。
どうやって学ぶ?
以下のUdemyコースを受講し、要点をスクラップにまとめていく。
知らないとまずい最低限の基礎
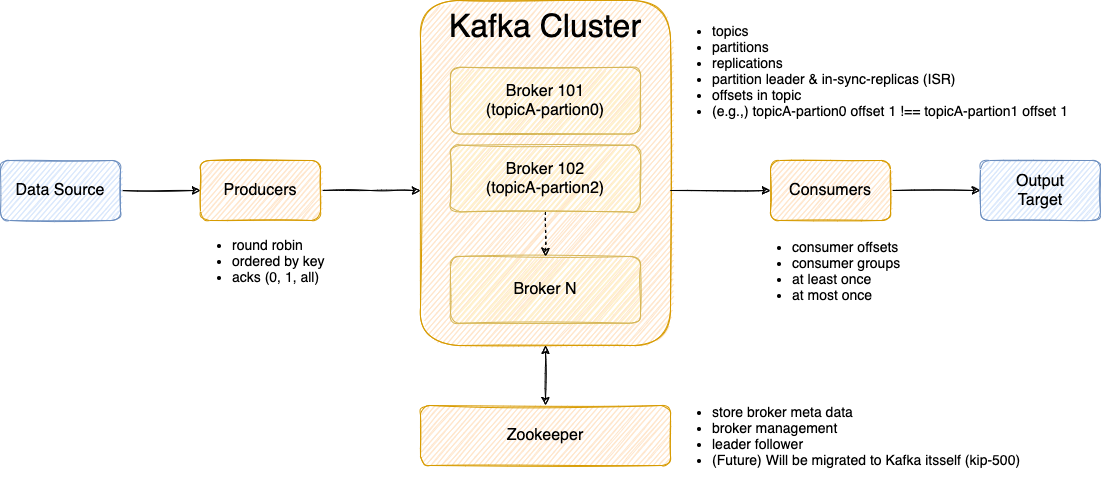
-
Producer (データを受け、Brokerに渡す)
- Round Robin
- Ordered by key
- acks (0, 1, all)
-
Broker (Producerからデータを受け、Consumerに渡す)
- topics
- partitions
- replications
- partition leader & in-sync-replicas (ISR)
- offsets in topic
- (e.g.,) topicA-partion0 offset 1 !== topicA-partion1 offset 1
-
Zookeeper (Brokerをマネジメントするだけ)
- store broker meta data
- broker management
- leader follower
- (Future) Will be migrated to Kafka itsself (kip-500)
-
Consumer (Brokerからデータを受け、データ出力を行う)
- consumer offsets
- consumer groups
- at least once
- at most once
Kafkaって何者?
ざっくり言うと、色んな形式(e.g., TCP, UDP等複数のプロトコル)のデータを受け取って、データロスを防ぎつつ次のシステムへとアウトプットできる優れたソフトウェア。現代では銀行や主要システムなど多くの場所で使われている非常に重要な技術の1つ。
Producer (データを受け、Brokerに渡す)
色んなデータ入力を受け付け、Brokerに渡す役割がProducer。複数のProducerを持つことが可能。
Round Robin
特に指定がない場合、Broker 1, 2, 3のようにラウンドロビン形式でデータを渡していく。
Ordered by key
キーを指定することで特定のパーティションに必ずそのキーが入るように出来る。(e.g., key=book_id -> topicA-partion0: book_id)
acks (0, 1, all)
データロスを防ぐための施策として以下の条件が設定可能。
-
acks=0:ProducerはBrokerの応答(ack)無しでデータを渡す (データロスの可能性あり) -
acks=1:ProducerはBroker Leaderの応答を待ち、データを渡す (限定的なデータロス) -
acks=all:ProducerはBroker Leader + Replicasの応答を待ち、データを渡す (データロス無し)
実運用的には1, allが妥当と考えられる。
Broker
BrokerはProducerからデータを受け取り、保存する。各Brokerにはtopic-partion単位でデータが保存される。
各Brokerはbootstrap serverとも呼ばれ、データ書き込みの際には任意のBroker 1つに接続するだけで良い (理由は後述のReplicas, Zookeeperを参照のこと)
topics
データの一部。
- データベースのテーブルに近い存在
- 好きな数だけ作成可能
- ユニークネームで特定 (e.g., topic-a)
partitions
1つのtopicが複数のpartionに分割される。
-
各Partionは0, 1, 2 .. N の数字付与されソートされる
-
各Partionには0, 1, 2 .. N の Offsetが付与されメッセージが保管される
TopicA: Partion 0 - offset 0, 1, 2, 3, 4TopicA: Partion 1 - offset 0, 1, 2TopicA: Partion 2 - offset 0, 1, 2, 3, 4, 5, 6
-
各々のPartionは別のデータであり、例えば、topicA-partion0-offset0 と topicA-partion1-offset0 は全くの別データである。
replications
topicの発行時にreplication factor(何個まで複製を用意するか)を決めることが出来る。最低は1で通常は2か3が妥当。
partition leader & in-sync-replicas (ISR)
各topicはデータを読み書きするLeaderと単にLeaderからデータを複製するISRの2つの役割がある。例えば以下の図の通り、topic-Aが存在し、それぞれpartion0, 1のデータがあると仮定する。
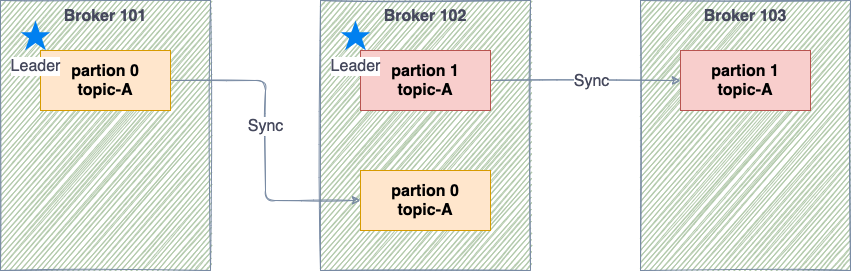
topic-partion単位でLeaderが決定され、各Brokerに配置される。上記の場合 replication factorは2であり、仮に上記Brokerのいずれか1つがダウンしたとしても特に問題は無い。
一言メモ: 実際の運用では、メンテナンス用 + 予期しないダウンに備えて、replication factorは3にしておくと吉かもしれない。
Zookeeper
Brokerを管理するためのもの。各topic-partionのLeaderを管理し、Brokerに割り当てる。そのため全Brokerのメタデータを所持する。ただし肝心のデータはBrokerに保存されているのでZookeeperがダウンしてもデータロスとはならない。
KafkaはZookeeper無しでは動かないが、余りにも冗長すぎる設計のため、今後新しいKafkaではBroker自身にメタデータを持たせ、Zookeeperを廃止しようとするプロジェクトKIP-500が始動している (時期未定)
ちなみに2021/07/07時点でアーリーアクセス段階の利用は可能。[1]
Consumer
Brokerからtopic-partion単位でデータを読み取り、対象システムへデータ出力を行うもの。
- BrokerとConsumerはN対Nの関係でBrokerの方が数が多い場合、inactiveになるConsumerが出てくる→Consumerが多すぎても少なすぎても微妙ってこと。
- 各
topic-partionのoffset番号順に読み込んでいき、どこまで読み込んだかはデフォルトの__consumer_offsetsトピックで管理される- 仮にConsumerがデータ読み込みの途中でダウンしても続きから読み込み可能。
データ書き込みにおいて以下の方式(semantics)が採用可能。
-
At most once (MO):(最大1回)- データロスするかもしれないが、データ重複なし
- 処理中に問題が起きたらデータロスに繋がる
-
At least once (LO):(少なくとも1回)- データ重複するかもしれないが、データロスなし
- プログラム側で重複あり前提の処理実行を心がける必要あり (べきとう性: idempotent)
-
Exactly once (EO):(正確に1回)- データロス・重複なし
お手軽さで言えばLOが1番好ましい。
-
https://issues.apache.org/jira/browse/KAFKA-9119 - The upcoming Kafka 2.8 release now supports running in KRaft (kip-500) mode as an early access feature. Thanks to everyone who helped push this over the finish line! ↩︎
CLIハンズオン
今回は https://kafka.apache.org/quickstart の2.8.0 shell版を利用。インタラクティブにメッセージを見るために以下のコマンドを使用。
- bin/kafka-console-producer.sh
- bin/kafka-console-consumer.sh
気付き
- Partionが0しかない場合、Consumer Groupを作っても分散されない
-
config/server.properties: num.partitions=3にしておこう。
-
- Consumer Groupで特に指定のない場合は、ランダムに割り振られる[1]
- LAG → 処理されてないメッセージ数
$ bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group my-app --describe
Consumer group 'my-app' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
my-app first_topic 0 2 3 1 - - -
my-app first_topic 1 2 3 1 - - -
my-app first_topic 2 2 4 2 - - -
- key=valueの形でメッセージを発行可能
$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic first_topic --property parse.key=true --property key.separator=,
>key,value
>this is a pen
org.apache.kafka.common.KafkaException: No key found on line 2: this is a pen
at kafka.tools.ConsoleProducer$LineMessageReader.readMessage(ConsoleProducer.scala:292)
at kafka.tools.ConsoleProducer$.main(ConsoleProducer.scala:51)
at kafka.tools.ConsoleProducer.main(ConsoleProducer.scala)
$ bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic first_topic --property parse.key=true --property key.separator=,
>this is a pen,then?
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first_topic --property print.key=true --property key.separator=,
key,value
this is a pen,then?
Java Programming ハンズオン
気付き
- 例え複数のPartitionがあったとしてもSendする毎にDelayが無い場合、同じPartitionに毎回格納されることが判明。
partition.assignment.strategyをRoundRobinに変えても同じ挙動。
実践Tips (デバッグ編)
どういったデバッグ手法があるのかを以下の通りまとめます。
Consoleツールでゴリゴリ
kafkaには以下の通りツール群が用意されています。その中でも「console」と名のついたやつを使います。
$ kafka-
kafka-acls.sh kafka-dump-log.sh kafka-run-class.sh
kafka-broker-api-versions.sh kafka-features.sh kafka-server-start.sh
kafka-cluster.sh kafka-get-offsets.sh kafka-server-stop.sh
kafka-configs.sh kafka-leader-election.sh kafka-storage.sh
kafka-console-consumer.sh kafka-log-dirs.sh kafka-streams-application-reset.sh
kafka-console-producer.sh kafka-metadata-shell.sh kafka-topics.sh
kafka-consumer-groups.sh kafka-mirror-maker.sh kafka-transactions.sh
kafka-consumer-perf-test.sh kafka-producer-perf-test.sh kafka-verifiable-consumer.sh
kafka-delegation-tokens.sh kafka-reassign-partitions.sh kafka-verifiable-producer.sh
- 特定のトピックをListenしてデバッグするのがオススメです。
kafka-console-consumer.sh --bootstrap-server <kafkaHost:9092> --topic <topic>
更にログレベルも変更可能です。https://docs.cloudera.com/runtime/7.2.10/kafka-managing/topics/kafka-manage-cli-loglevel.html
Kowlを使う