Mastra + Postgres MCPで自然言語でクエリ飛ばしたら面白かった
✅ この記事を読んだら分かること
📌 自然言語で SQL を生成・実行できる Postgres MCP の使い方
📌 LLM に的確な SQL を生成してもらう、具体的なやり方
📌 LLM × Postgres × MCP の組み合わせで遊べるデモ構成
👤 この記事の対象者
- PostgreSQL のクエリを書かずに、自然言語でデータを扱いたい人
- Model Context Protocol (MCP) に興味があるが、どう活用するかピンと来ていない人
- LLM と Postgres を組み合わせて面白いことをやってみたい人
- ChatGPT API や自作 LLM エージェントを活かしたデータ分析を始めたい人
🌟 自然言語で SQL 叩けるっておもろい
PostgreSQL のクエリを自然言語で飛ばせる Postgres MCP を使って、PostgreSQL に自然言語でクエリを投げてみたら…想像以上に面白かったです。
たとえば以下の様なプロンプトで、この様な出力があります。
📥 プロンプトを入力してください:> Bobっていう従業員はいますか?
✅ 出力: {
summary: 'Bobという名前の従業員が存在します。',
content: 'データベースのpersonテーブルを確認したところ、Bobという名前の従業員が存在しました。彼の情報は以下の通りです。\n' +
'\n' +
'- ID: 2\n' +
'- 名前: Bob\n' +
'- 年齢: 42\n' +
'\n' +
'この情報から、Bobという従業員が確かに存在することが確認できました。',
keywords: [ 'Bob', '従業員', 'personテーブル' ],
sql: [
'SELECT * FROM person LIMIT 1;',
'SELECT * FROM job LIMIT 1;',
"SELECT * FROM person WHERE name = 'Bob';"
]
}
SQL を書かずにここまでできるのはなかなかの感動ものでした...
🚀 Mastra とは?
Mastra は、TypeScript で LLM エージェントを簡単に作れる OSS フレームワークです。
- 現在 Netlify 傘下の Gatsby の元コア開発者が関わるチームによって開発されています。
- 様々な LLM と MCP ツール(Playwright など)をシンプルなコードで統合し、自然言語の指示で処理を実行できます。
- 型安全かつ CLI や GitHub Actions でも扱いやすい構成が特徴です。
🧠 Postgres MCP とは?
Model Context Protocol (MCP) は、自然言語のプロンプトに対して、LLM(大規模言語モデル)を通じて様々な外部ツールと連携できる仕組みです。
Postgres MCP を使うと Postgres に対して LLM が生成した SQL を発行できる MCP LLM が Postgres に SQL を発行し、結果を取得・整形してくれます。
現状 read-only だけに対応との事で INSERT 文の発行などはできないようです。
⚙️ Postgres の準備
あまりここでは詳細には説明しませんが、以下はやっておいてください。
- ローカルマシンに Postgres をインストール
- postgres ユーザーのパスワードを postgres に設定して、以下のコマンドで DB コンソールに入れるようにしておく
$ PGPASSWORD=postgres psql -U postgres
postgres のシェルに入ったら employee データベースを作成
postgres=# create database employee;
employee テーブルに繋いで
postgres=# \c employee
You are now connected to database "employee" as user "postgres".
以下の CREATE TABLE を流す
-- Drop existing tables if needed
DROP TABLE IF EXISTS job;
DROP TABLE IF EXISTS person;
-- Create tables
CREATE TABLE person (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
age INT NOT NULL
);
CREATE TABLE job (
id SERIAL PRIMARY KEY,
person_id INT REFERENCES person(id),
title TEXT NOT NULL,
company TEXT NOT NULL,
start_year INT NOT NULL,
end_year INT
);
-- Insert sample data
INSERT INTO person (name, age) VALUES
('Alice', 30),
('Bob', 42),
('Charlie', 28),
('Diana', 35),
('Ethan', 50);
INSERT INTO job (person_id, title, company, start_year, end_year) VALUES
(1, 'Software Engineer', 'TechCorp', 2015, 2018),
(1, 'Senior Engineer', 'InnovateX', 2018, 2021),
(1, 'Lead Developer', 'FutureSoft', 2021, NULL),
(2, 'Analyst', 'DataMind', 2005, 2009),
(2, 'Consultant', 'BizGroup', 2009, 2013),
(2, 'Manager', 'InsightCorp', 2013, 2018),
(2, 'Director', 'NextVision', 2018, NULL),
(3, 'Intern', 'Alpha Inc.', 2017, 2018),
(3, 'Developer', 'CodeHouse', 2018, 2020),
(3, 'Engineer', 'Softline', 2020, NULL),
(4, 'UX Designer', 'CreativeLabs', 2010, 2013),
(4, 'Senior Designer', 'StudioX', 2013, 2016),
(4, 'Product Manager', 'PixelCo', 2016, 2020),
(4, 'Design Director', 'Visionary', 2020, NULL),
(5, 'System Admin', 'NetSecure', 1995, 2000),
(5, 'IT Manager', 'CompuLink', 2000, 2010),
(5, 'CTO', 'InfraTech', 2010, NULL);
🚿 Postgres MCPの流れ
LLM と Postgres MCP のデータの流れをシーケンス図で表現すると以下の様になります。
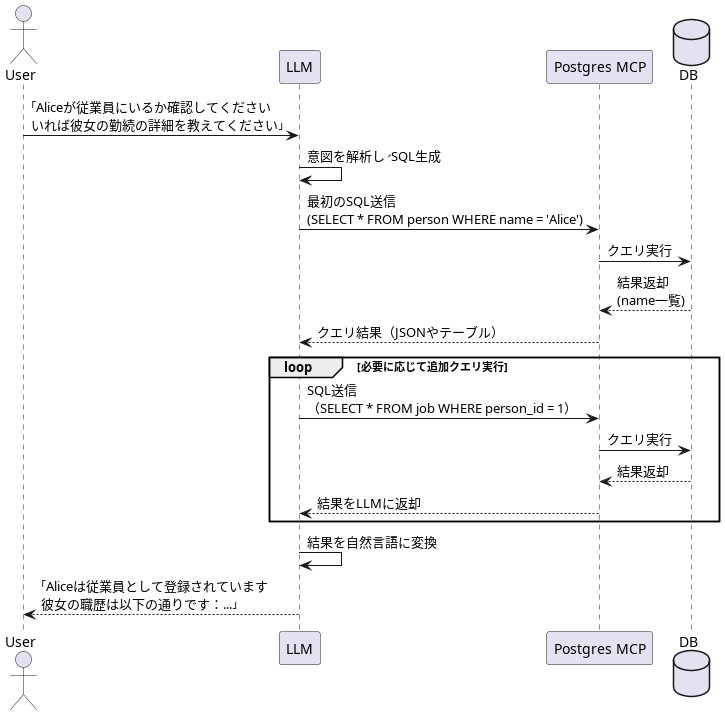
Playwright MCP ではnavigate_browser などの Playwright MCP 用のコマンドを使いますが、Postgres MCP では LLM が SQL を生成したものを使っていますね。
🧾 runPostgres.ts の詳細
サンプルコードはこちらからダウンロードできます。
実行方法
.env に自分の OpenAI API Key を設定
OPENAI_API_KEY=sk-xxxxx
以下のコマンドで実行
$ npx tsx src/runPostgres.ts
プロンプトが出ます:
📥 プロンプトを入力してください:>
スクリプトの内容(抜粋)
export const mcp = new MCPClient({
servers: {
postgres: {
command: "npx",
args: [
"-y",
"@modelcontextprotocol/server-postgres",
"postgres://postgres:postgres@localhost:5432/employee",
],
},
},
});
ここで Postgres MCP を有効にして、ローカルのデータベースを読みにいっています。
const agent = new Agent({
name: "Postgres Agent",
tools: await mcp.getTools(),
instructions: `
あなたはPostgresのデータベースに接続して、SQLクエリを実行するエージェントです。
employeeデータベースの中のテーブルの関係を理解しておいてください。
employeeデータベースの中にはpersonとjobテーブルしかありません。
SQLを生成し、必ずその結果を本文(content)に詳しく日本語で含めてください。
出力には summary、content(人間が読む用の自然文)、keywords(重要語)、sql(実行したすべてのSQL)の4つを含めてください。
必ずpersonとjobテーブルを先に読みに行って、存在するカラムだけでSQLクエリを生成してください。
複数のSQLが必要な場合は、すべてのSQLを配列形式で出力してください。
例: ['SELECT ...', 'JOIN ...'] のようにsqlフィールドには配列を返してください。
出力は全部日本語でお願いします。
`,
model: openai("gpt-4o"),
});
最初は LLM はどうやらテーブル名とか何も考えず persons とか存在しないテーブルやカラム使って SQL のクエリを作ってエラーが出ていたので instructions 内で指摘したらうまく動くようになりました。
SQL 文は複数作られる事が多いので、ここで指定して全部後で出力するようにお願いしています。
本当は DB の構造全部をここに突っ込んだ方が SQL 文作成の精度があがるかもですが、リクエストが増えた場合の API のレートリミットに達さないようにする工夫が必要ですね。
const schema = z.object({
summary: z.string(),
content: z.string(),
keywords: z.array(z.string()),
sql: z.string(),
});
ここで出力の内容を指定しています。SQL も指定しているので、LLM がどんな SQL を作ったかを見れるようにしています。
async function main() {
const prompt = await readPrompt();
try {
const result = await agent.generate(
[
{
role: "user",
content: prompt,
},
],
{
experimental_output: schema,
}
);
console.log("✅ 出力:", result.object);
} catch (error) {
console.error("❌ エラーが発生しました:", error);
} finally {
await mcp.disconnect();
}
}
最後のここでプロンプトの内容をエージェントに飛ばしています。
🧪 実際に動かしてみよう
📥 プロンプトを入力してください:> Aliceっていう従業員はいますか?いれば彼女の経歴の詳細を教えてください。
✅ 出力: {
summary: 'Aliceの経歴を確認しました。',
content: 'Aliceという名前の従業員は存在します。彼女の詳細は以下の通りです。\n' +
'\n' +
'- **名前**: Alice\n' +
'- **年齢**: 30歳\n' +
'\n' +
'彼女の職歴は以下の通りです:\n' +
'1. **職位**: Software Engineer\n' +
' - **会社**: TechCorp\n' +
' - **勤務期間**: 2015年から2018年\n' +
'2. **職位**: Senior Engineer\n' +
' - **会社**: InnovateX\n' +
' - **勤務期間**: 2018年から2021年\n' +
'3. **職位**: Lead Developer\n' +
' - **会社**: FutureSoft\n' +
' - **勤務期間**: 2021年から現在\n' +
'\n' +
'Aliceは現在、FutureSoftでLead Developerとして働いています。',
keywords: [ 'Alice', '従業員', '経歴', '職歴', 'TechCorp', 'InnovateX', 'FutureSoft' ],
sql: [
"SELECT * FROM person WHERE name = 'Alice';",
'SELECT * FROM job;',
"SELECT column_name FROM information_schema.columns WHERE table_name = 'person';",
"SELECT column_name FROM information_schema.columns WHERE table_name = 'job';"
]
}
📥 プロンプトを入力してください:> 各従業員の名前と合計勤続人数をリストにしてまとめてください
✅ 出力: {
summary: '各従業員の名前と合計勤続年数を取得しました。',
content: 'データベースから各従業員の名前とその合計勤続年数を取得しました。以下はその結果です。\n' +
'\n' +
'- Alice: 合計勤続年数 6年\n' +
'- Bob: 合計勤続年数 13年\n' +
'- Charlie: 合計勤続年数 3年\n' +
'- Diana: 合計勤続年数 10年\n' +
'- Ethan: 合計勤続年数 15年\n' +
'\n' +
'このリストは、各従業員が過去にどれだけの期間働いていたかを示しています。',
keywords: [ '従業員', '名前', '合計勤続年数', 'personテーブル', 'jobテーブル' ],
sql: [
"SELECT column_name FROM information_schema.columns WHERE table_name = 'person';",
"SELECT column_name FROM information_schema.columns WHERE table_name = 'job';",
'SELECT p.name, SUM(j.end_year - j.start_year) AS total_years FROM person p JOIN job j ON p.id = j.person_id GROUP BY p.name;'
]
}
🔺 まとめ
- Mastra + Postgres MCP の組み合わせは、コードを書かずに自然言語でデータベース操作を実現できる新しい体験でした。
- SQL をある程度理解している LLM と MCP のようなプロトコルを組み合わせることで、非エンジニアでも本格的なデータ活用が可能になります。
- たとえば「従業員のキャリアの要約を時系列で見たい」といった要求も、視覚的で分かりやすいレポートとして自然言語で返してくれるのは強力です。
- 現時点では SELECT クエリのみ対応ですが、将来的に INSERT や UPDATE にも対応すれば、業務利用の幅はさらに広がると感じました。
今回のスクリプトを API にしてフロントエンドアプリに繋げれば特定のDBの中身をプロンプト経由でクエリできるようなwebアプリも簡単に作れますね。いろいろアイデアは膨らみます...
📎 参考リンク
👨💻 著者について
東京とアムステルダムを拠点に活動中。
東欧・南アジアのエンジニアと連携しながら、QA コンサル・テスト自動化・フルスタック開発・PM 業務まで幅広く担当しています。
Cucumber・Playwright・ChatGPT などを活かした効率的なテスト運用や開発基盤づくりのご相談も歓迎です!
Discussion