DuckDB Update & Blog reading #4:DuckDB × Streamlit
まえがき
個人的にDuckDBをPythonで使用することは多い。
ただDuckDBを使用して可視化をする時に、Streamlitを使用する...という用途が個人的に少なかった。
今回の公式ブログではStreamlitとの連携ネタということで面白そうだったのでやってみました🙌
今回の公式ブログ
目的
オランダの鉄道データを使用して、データベース接続だったり、地図表示をStreamlitで行う。
(なぜオランダかというと、DuckDBはオランダのアムステルダムにDuckDB Labsという会社があって開発しているため...!)
具体的にはcsvやgzですでに存在している鉄道データにhttpsでアクセスしてデータを取ってきて、キャッシュを利用した接続やPlotyを使用した可視化、Streamlitのコンポーネントを使用した地図上での可視化を行う。
⓪冒頭のインポート部分
import datetime
import duckdb
import streamlit as st
import uuid
import plotly.express as px
①データロード
最初にWebにあるデータを取得する関数を作成しています。
個人的にduckdbはあまり関数を作成して使用などを行なっていなかったので結構新鮮でした。
おそらくこの後のStreamlitのキャッシュ接続などの仕組みのために必要になるからというのもあると思います。
def prepare_duckdb(duckdb_conn):
duckdb_conn.sql("""
create table if not exists services as
from 'https://blobs.duckdb.org/nl-railway/services-2024.csv.gz'
""")
duckdb_conn.sql("""
create table if not exists stations as
from 'https://blobs.duckdb.org/nl-railway/stations-2023-09.csv'
""")
servicesテーブル:
URLにある圧縮された形式(.gz)のCSVファイルから直でテーブルを作成してます。(こういう使い方ができるのがすごいところですね。)
このファイルには2024年の列車運行についてのデータが入ってるらしいです。
stationsテーブル:
今度はcsvファイルを直でテーブルにしています。(2023年9月時点の駅情報)
接続方法はいろいろ提示されているのですが、インメモリでやってみました。
②Streamlitのキャッシュ接続を利用してDuckDBでデータに接続する。
インメモリ接続だとデータソースに接続するたびにデータを全部メモリに読み込むことになる。単一の場合なら良いが今回の場合のように複数のデータソースに接続するというケースも多いと思う。
(1つ目のデータ接続→処理→二つ目のデータ接続→処理...のようになる。)
特にWeb上のデータソースを取得しているので接続状況などにも速度依存してしまう。
その問題を解決するために二つの接続をキャッシュする方法が提示されていました。
-
グローバルキャッシュ
アプリケーション全体で一つのDuckDB接続を共有する方法(ファイルに接続用の記述をしてそれを全ファイルで共有して使う場合など。)
すべてのユーザーが同じ接続を使用 = メモリ効率が良い
※複数ユーザーが同時にアクセスすると競合が発生する可能性が... -
セッションキャッシュ
ユーザーごとに別々のDuckDB接続を作成してキャッシュする方法
各ユーザーは独自の接続を持つため、競合が少ない
ただし、多くのユーザーがいる場合はメモリ使用量が増加
今回はおそらくStreamlitのセッションキャッシュで接続しています。
(Streamlitにも接続のキャッシュ機能なんてあったんですね...)
@st.cache_resource(ttl=datetime.timedelta(hours=1), max_entries=2)
def get_duckdb_memory(session_id):
duckdb_conn = duckdb.connect()
prepare_duckdb(duckdb_conn=duckdb_conn)
return duckdb_conn
二つの異なる接続をキャッシュ&キャッシュは1時間有効という設定みたいです。
そしてここでこの後出てくるprepare_duckdbを呼んで接続用の変数を渡しています。
とりあえずこの時点で動作確認したくて、get_duckdb_memory()を呼ぼうと思ったのですがsession_idが無い...このidなんだろう?と思ったのですが、
「session_idはユーザーセッションを識別するID。Streamlitでは通常、各ユーザーセッションを区別するために一意の識別子を使用」...とのことでした。
なのでsession_idを用意して接続します。
あとブログのst.cache_resourceが自分のバージョンではサポートされていなかった(!)みたいなので今回はst.experimental_singletonを使用しました。
@st.experimental_singleton
# (ttl=datetime.timedelta(hours=1), max_entries=2)
def get_duckdb_memory(session_id):
duckdb_conn = duckdb.connect()
prepare_duckdb(duckdb_conn=duckdb_conn)
return duckdb_conn
if 'session_id' not in st.session_state:
st.session_state['session_id'] = str(uuid.uuid4())
# セッションIDを使って接続を取得
conn = get_duckdb_memory(st.session_state['session_id'])
st.write("DuckDB接続が確立されました")
# テーブル一覧を取得して表示
tables = conn.sql("SHOW TABLES").fetchall()
st.write("テーブル一覧:", [table[0] for table in tables])
if 'session_id' not in st.session_state:
st.session_state['session_id'] = str(uuid.uuid4())
# セッションIDを使って接続を取得
conn = get_duckdb_memory(st.session_state['session_id'])
結果何とかつながりました🙌

③stasionsとserviceテーブルから必要なデータを取得
- station
駅(stations)テーブルからデータを選択して取得しています。(駅名、緯度、経度、コード、name_longをstation_nameに変更)
あとクエリ結果にエイリアスをつけてます。(こういう付け方もできるんですね...)
stations_selection = duckdb_conn.sql("""
select name_long as station_name, geo_lat, geo_lng, code
from stations
""").set_alias("stations_selection")
- service
services_selection = (
duckdb_conn.sql("from services")
.aggregate("""
station_code: "Stop:Station code",
service_date: "Service:Date",
service_date_format: strftime(service_date, '%d-%b (%A)'),
num_services: count(*)
""")
.set_alias("services")
)
このコードも見た時🫠となったが、最初にsqlでテーブル指定してその後はaggregateというメソッドで普段sqlでやってるような処理をpythonで書いてるようです。
やってることは、
- 「Stop code」列を「station_code」という名前で取得
- 「Service」列を「service_date」という名前で取得
- サービス日を「日-月(曜日)」形式にフォーマットしている。
- 各グループに含まれるレコード数をカウント
- このクエリに「services」という名前(エイリアス)を設定
④テーブルの結合と使用データの選択
先ほど定義したstations_selectionとservices_selectionを使用してテーブルをジョインします。
(キーは"services.station_code = stations_selection.code")
関数全体は以下みたいになってます。
def get_stations_services_query(duckdb_conn):
# create a relation for the station selection
stations_selection = ...
# create a relation for the services selection
services_selection = ...
# return the query and the duckdb_conn
return (
stations_selection
.join(
services_selection,
"services.station_code = stations_selection.code"
)
.select("""
service_date,
service_date_format,
station_name,
geo_lat,
geo_lng,
num_services
""")
), duckdb_conn
選択列はサービス日,フォーマットされたサービス日,駅名,緯度,経度,サービス数みたいです。
関数の呼び出し元が、同じデータベース接続を使用して追加のクエリを実行できるようにduckdb_connの接続も返しています。
この関数を呼び出したらデータ接続するのか...というとどうもブログによるとそうで無いようです。
「遅延評価」といってクエリが定義された時点では実際に実行されず、データが必要になった時点で初めて実行されるらしくたとえばこのクエリでdfを作成した時にクエリが実行されるみたいです。
(こういった時:stations_query.df())
これで接続の遅延が軽減されます。
⑤毎月の最も混雑する列車駅トップ5をデータフレームにする
いよいよデータ取得になりますね。
ここでは先ほど作成したjoinなどを行うクエリで接続を行いウインドウ関数の処理のようなメソッドを行なっています。(ちょっとこの記法は慣れないですね。)
stations_query, _ = get_stations_services_query(conn)
top_5_query = (
stations_query.aggregate("""
station_name,
service_month: monthname(service_date),
service_month_id: month(service_date),
num_services: sum(num_services)
""")
.select("""
station_name,
service_month,
service_month_id,
num_services,
rn: row_number()
over (
partition by service_month
order by num_services desc
)
""")
.filter("rn <= 5")
.order("service_month_id, station_name")
)
この後に使用するデータフレームを定義しています。
stations_df = stations_query.aggregate(
"geo_lat, geo_lng, num_services: sum(num_services)"
).df()
⑥plotlyで棒グラフ&マップ表示
ここで可視化を行なっていますがちょっと混乱してきたので一旦ここまでのコードを以下に示します。
import datetime
import duckdb
import streamlit as st
import uuid
import plotly.express as px
def prepare_duckdb(duckdb_conn):
duckdb_conn.sql("""
create table if not exists services as
from 'https://blobs.duckdb.org/nl-railway/services-2024.csv.gz'
""")
duckdb_conn.sql("""
create table if not exists stations as
from 'https://blobs.duckdb.org/nl-railway/stations-2023-09.csv'
""")
@st.experimental_singleton(ttl=datetime.timedelta(hours=1), max_entries=2)
def get_duckdb_memory(session_id):
duckdb_conn = duckdb.connect()
prepare_duckdb(duckdb_conn=duckdb_conn)
return duckdb_conn
if 'session_id' not in st.session_state:
st.session_state['session_id'] = str(uuid.uuid4())
# セッションIDを使って接続を取得
conn = get_duckdb_memory(st.session_state['session_id'])
# st.write("DuckDB接続が確立されました")
# # テーブル一覧を取得して表示
# tables = conn.sql("SHOW TABLES").fetchall()
# st.write("テーブル一覧:", [table[0] for table in tables])
def get_stations_services_query(duckdb_conn):
# create a relation for the station selection
stations_selection = duckdb_conn.sql("""
select name_long as station_name, geo_lat, geo_lng, code
from stations
""").set_alias("stations_selection")
# create a relation for the services selection
services_selection = (
duckdb_conn.sql("from services")
.aggregate("""
station_code: "Stop:Station code",
service_date: "Service:Date",
service_date_format: strftime(service_date, '%d-%b (%A)'),
num_services: count(*)
""")
.set_alias("services")
)
# return the query and the duckdb_conn
return (
stations_selection
.join(
services_selection,
"services.station_code = stations_selection.code"
)
.select("""
service_date,
service_date_format,
station_name,
geo_lat,
geo_lng,
num_services
""")
), duckdb_conn
conn = get_duckdb_memory(st.session_state['session_id'])
stations_query, _ = get_stations_services_query(conn)
top_5_query = (
stations_query.aggregate("""
station_name,
service_month: monthname(service_date),
service_month_id: month(service_date),
num_services: sum(num_services)
""")
.select("""
station_name,
service_month,
service_month_id,
num_services,
rn: row_number()
over (
partition by service_month
order by num_services desc
)
""")
.filter("rn <= 5")
.order("service_month_id, station_name")
)
stations_df = stations_query.aggregate(
"geo_lat, geo_lng, num_services: sum(num_services)"
).df()
month_order = ["January", "February", "March", "April", "May", "June",
"July", "August", "September", "October", "November", "December"]
st.subheader("月ごとの上位5駅")
top_5_df = top_5_query.df()
fig_top5 = px.bar(
top_5_df,
x="service_month",
y="num_services",
color="station_name",
barmode="group",
labels={
"service_month": "Month",
"num_services": "Number of Train Trips",
"station_name": "Station Name"
},
title="Top 5 Busiest Train Stations 2024",
category_orders={"service_month": month_order},
color_discrete_sequence=px.colors.qualitative.Bold
)
# レイアウトの調整
fig_top5.update_layout(
xaxis_tickangle=-45,
legend=dict(
orientation="v",
yanchor="top",
y=0.99,
xanchor="right",
x=0.99
),
template="plotly_dark",
height=600,
margin=dict(l=50, r=50, t=80, b=100)
)
# Y軸の範囲を0から始める
fig_top5.update_yaxes(range=[0, top_5_df ["num_services"].max() * 1.1])
# グラフを表示
st.plotly_chart(fig_top5, use_container_width=True)
# 地図の中心座標(オランダの中心付近)
map_center = {"lat": 52.1326, "lon": 5.2913}
# Plotlyでdensity mapを作成
fig = px.density_mapbox(
stations_df,
lat='geo_lat',
lon='geo_lng',
z='num_services',
radius=20,
center=map_center,
zoom=7,
mapbox_style="open-street-map",
title="オランダの鉄道ネットワーク利用状況",
labels={'num_services': '列車サービス数'},
color_continuous_scale='plasma'
)
# レイアウトの調整
fig.update_layout(
margin={"r": 0, "t": 40, "l": 0, "b": 0},
height=600
)
# Streamlitに表示
st.plotly_chart(fig, use_container_width=True)
でこの後
streamlit run ファイル名
で起動します。
以下のような表示になりました!(自環境では処理2分くらい)
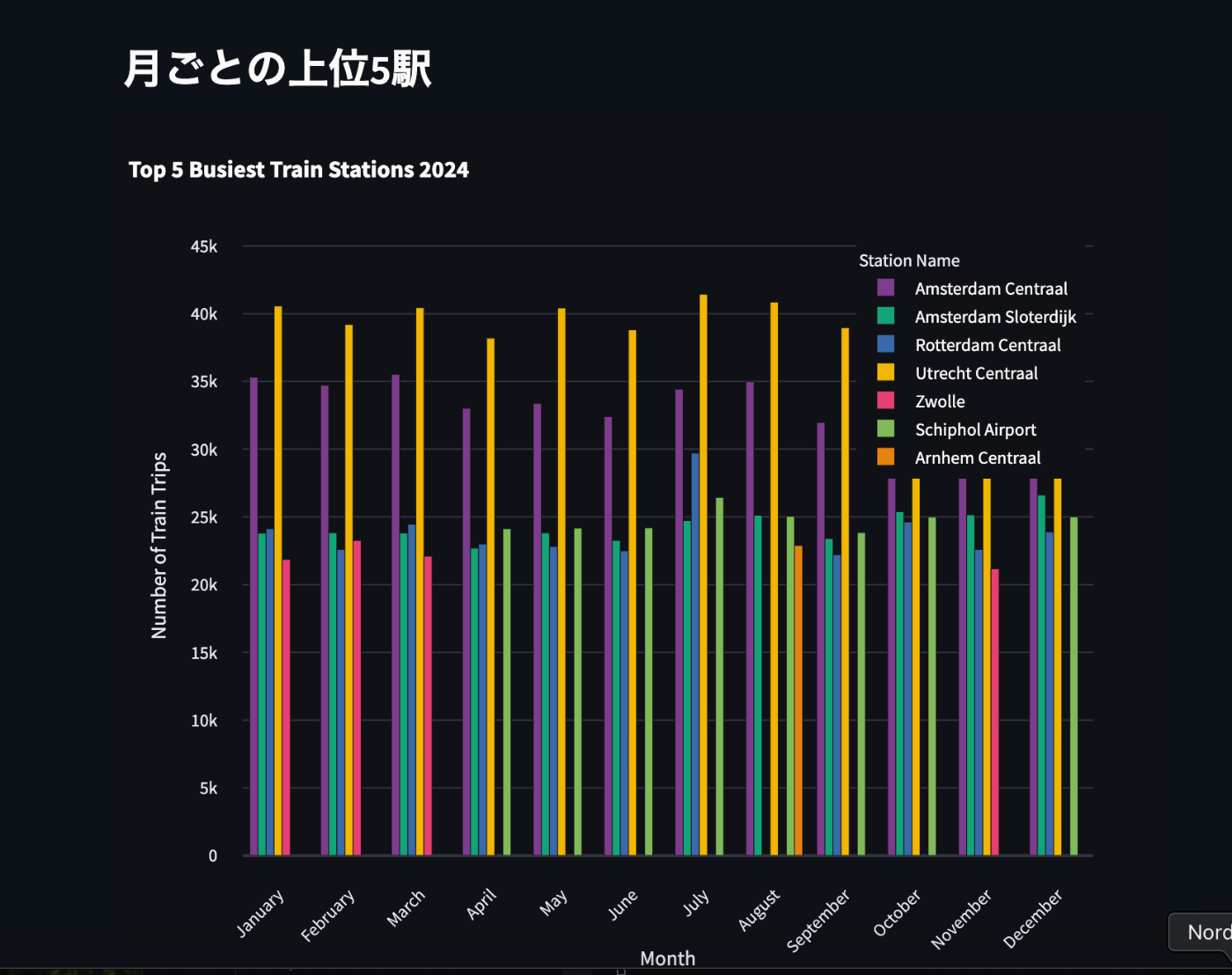

ただ公式と違うのでどこか計算ミスかも...
まとめ
DuckDBとStreamlitの連携でデータ取得と可視化まで、Pythonで行う例を試してみました。
(実は公式ではこのあとヒートマップアニメーションとFoliumを使った近接駅検索...という項があるのですが力尽きました...🫠)
以前DuckDB-wasmで可視化を行ったりしていたのですがもしPythonで可視化までやり切らないといけなかったりする場合はStreamlitを使用するパターンもありかなと思いました。(ブラウザ上でOPFSを使用しない場合はメモリ制限もあるのでStreamlitも有効かも)
データソースがweb上の場合だとやっぱり速度が気になるのでもしかしたらSnowflake上とかで使用したら効果を発揮するのかもしれないなと思いました。
あとこれまで接続にキャッシュを使うという発想がなかったので今度フロントエンドでDuckDBを使用する時にTanstack queryを使用したりしてみるのも面白そうだなと思いました。(効果があるのか試してみたい。)
英語勉強用
-
Using the above open data, in this post we will build an application, in which a user can:英語っぽいリズム重視の文...これの文法は?と言われるとちょっとつらい。
現在分詞:"Using the above open data"
前置詞句: "in this post"
前置詞句: "in which" in whichが以降の英文を指している...と思う
英文は古いものが前に来て新しいものが後に来るがその兼ね合いか?
上のデータを使ってこの記事ではアプリケーションを作るが、できることは以下である...というような意味か -
In Streamlit this behavior is addressed by caching the resource,
この挙動はcaching resourceで対処される...という意味らしいbehavior と addressの用法がわからなかった... -
This is because the query evaluation is lazy, which means that the query is not executed against the database until an execution command is encountered.
which meansは「つまり...」という意味で使える。実際に会話する時に「えーつまり...」という感じで間を埋める時に(時間稼ぎする時に)使えそうな気がする。
- One other use-case
別のユースケースという意味
Discussion