Firebase で Todoist のクローンを作る
Why
フロントエンドの方に責務を寄せた密結合なアプリケーション・アーキテクチャとして、Firebase を研究してみたい。
What
調べつつ Todoist のクローンを作ってみる。
Reference (随時更新)
thepuskar/todoist-clone
同じく Totoist のクローン。機能はかなりミニマム。使いたいスタックが違うので直接どうこうということはないが、設計のバリデーションに使えるかもしれない。
スタック差分:
- [パッケージ管理] npm -> yarn
- [モジュールバンドラ] webpack -> snowpack
- [言語] JavaScript -> TypeScript
- [CSS] SCSS + BEM -> styled-components
- [Firebase SDK] Fireabse v8 -> Firebase v9(beta)
Nakajima-Foundation/ownplate
お持ち帰り.com ( https://omochikaeri.com/ )のソースコード。UIライブラリは React ではなく Vue だが、上記と違ってちゃんとした実アプリケーションなので参考になる。Firestore, Cloud Functions など Firebase の機能を使い込んでいる。
CSFrequency/react-firebase-hooks: React Hooks for Firebase.
アプリケーションではないが、Firestore などを React Hooks に繋ぎこむときの参考にできる(Firebase v9 にまだ対応してないので直接は使えない)。
Working Log (随時更新)
https://github.com/Altech/todoist-clone/pull/1 で進めてる。
2021/07/24
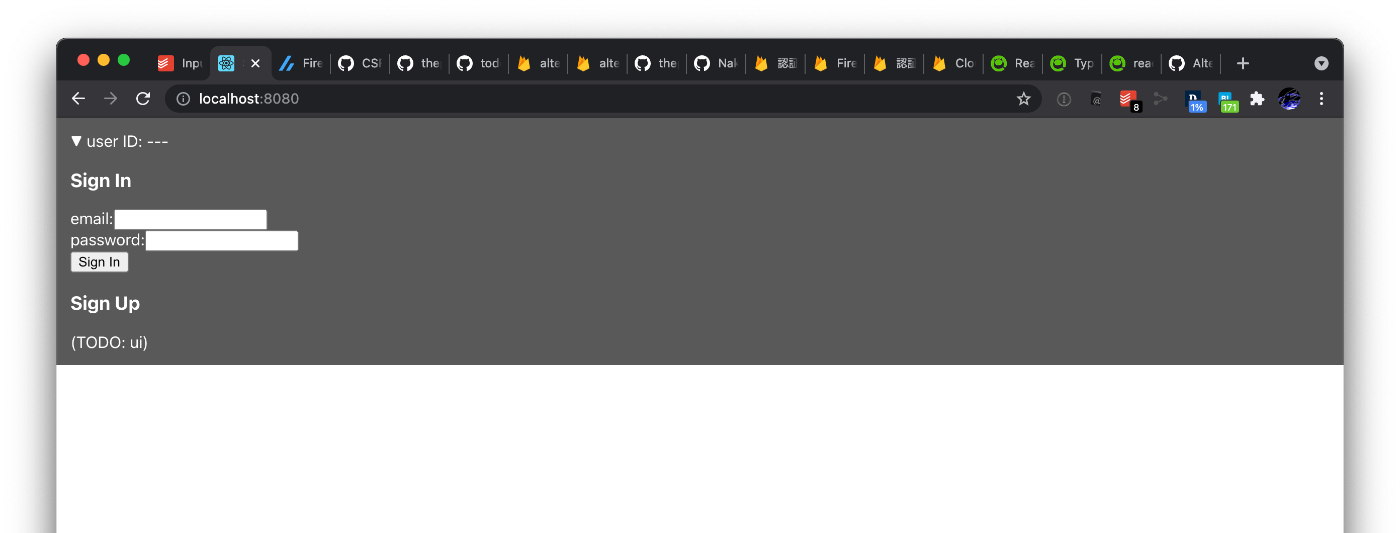

- UI から email ログインをできるようにした。いろいろな下回りの調査をしたのであまり進まなかった。
2021/07/25
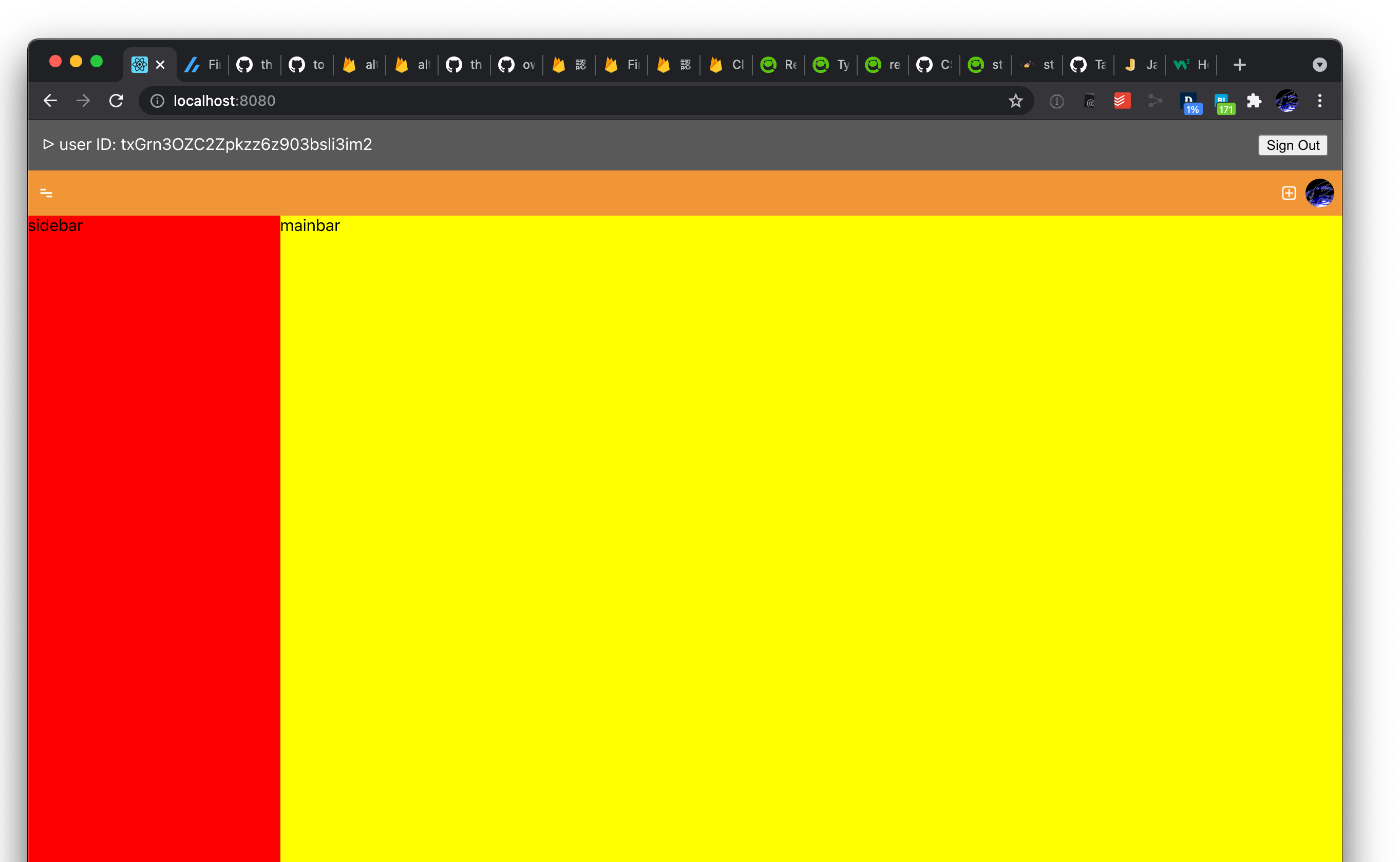
- ヘッダーの基本的な UI を組んだ
- 全体のレイアウトと、サイドバーのトグルをできるようにした
- ログイン状況は邪魔なのでデフォルトでは隠すようにした
- サイドバーとメインバーの基本的な UI を組んだ(データは全部固定)
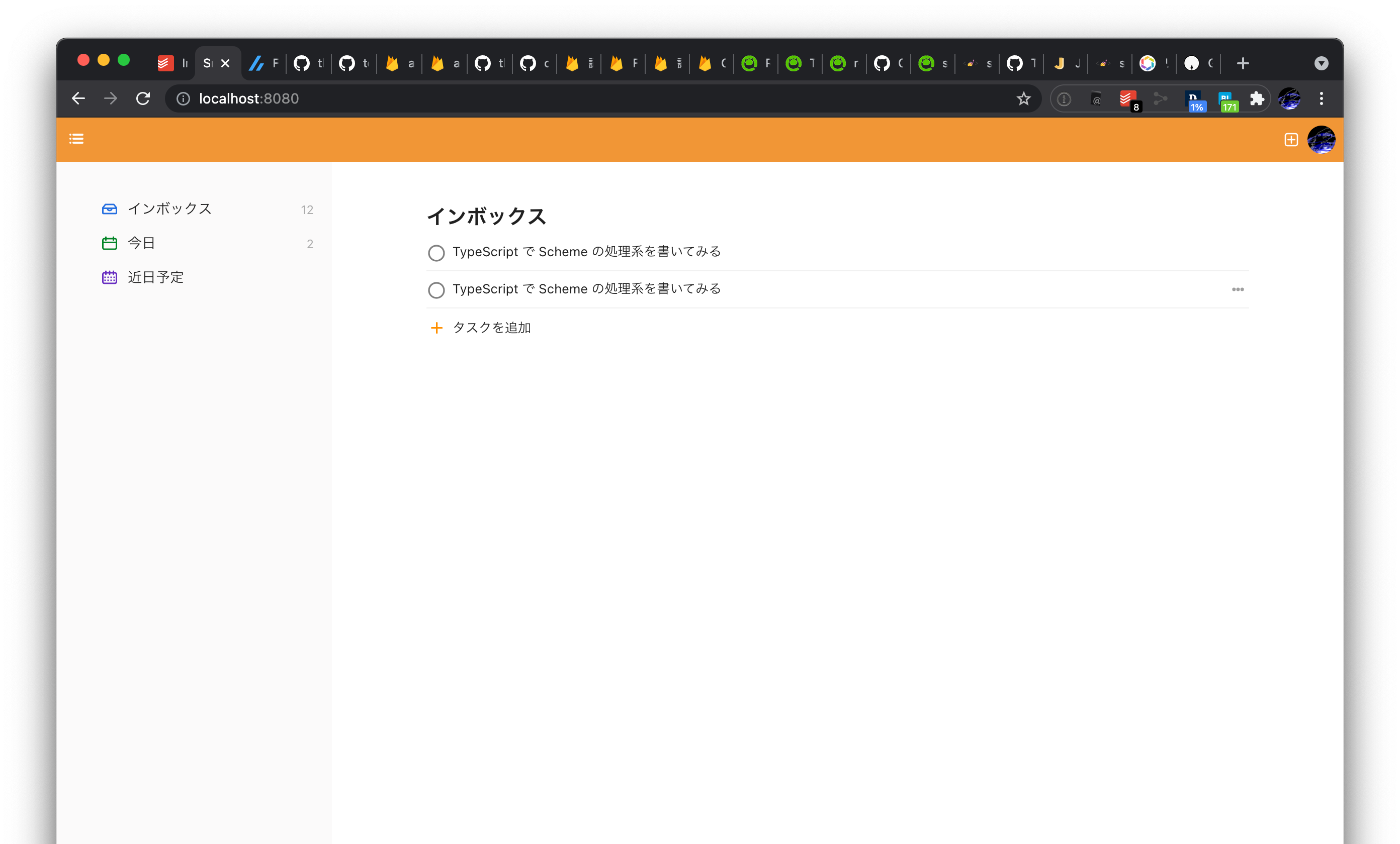
2021/07/26

- ユーザー配下にタスクと言う階層を追加して、適切な権限で書き込めるようにした
- 表示するタスクのリストを、Firestore 経由で取得したデータにするようにした(もちろんリアクティブに反映される)
- (見た目はあんまり変わってないけど)
2021/07/27
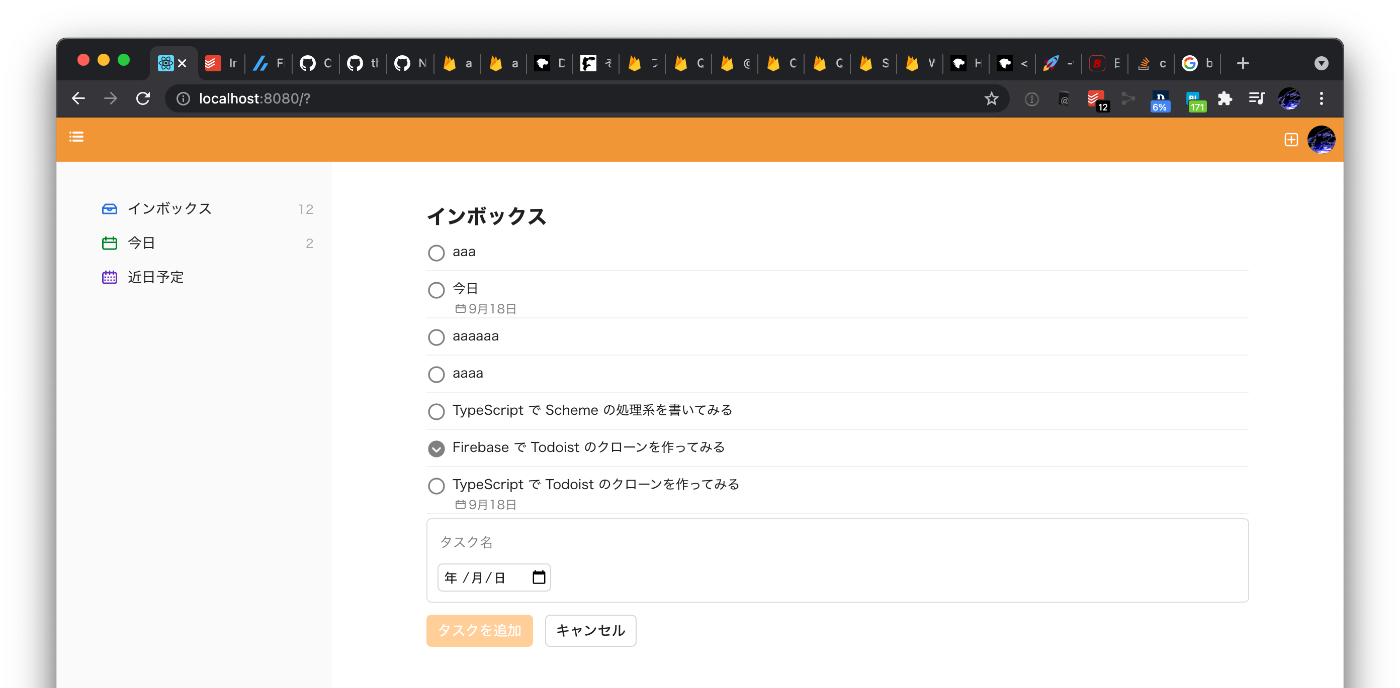
- タスクの追加を UI からできるようにした
- タスクの順番が追加された順になって欲しいので、次回改善する
2021/08/03
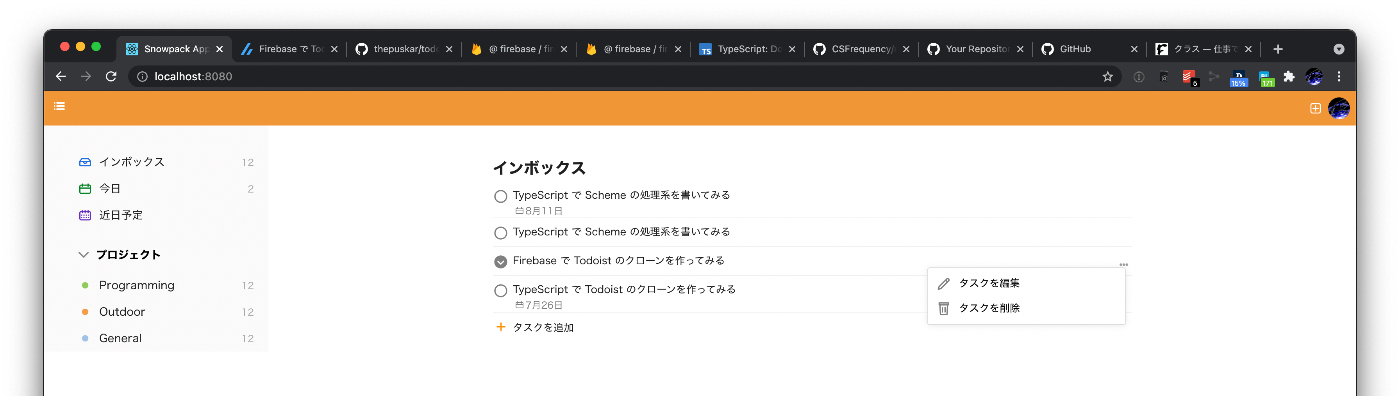
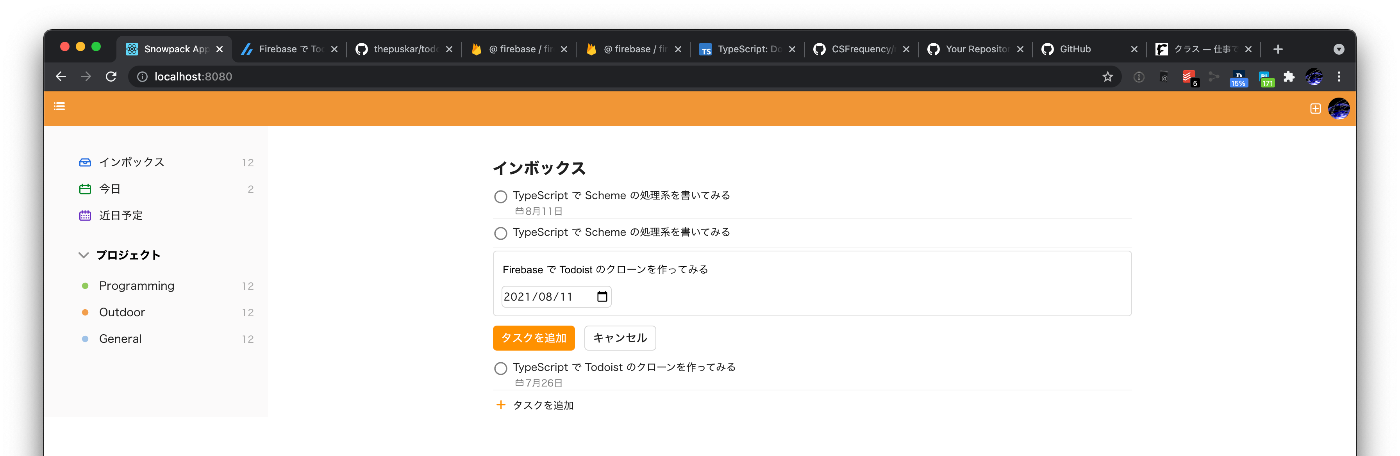
- 既存のタスクの編集・削除をできるようにした
2021/08/04-05
- context, hooks などを使って全体的にリファクタリング
2021/08/06
- タスクを追加した順に表示するようにした
- タスクの完了をできるようにした
- 完了したタスクは表示されないようにした
2021/08/11
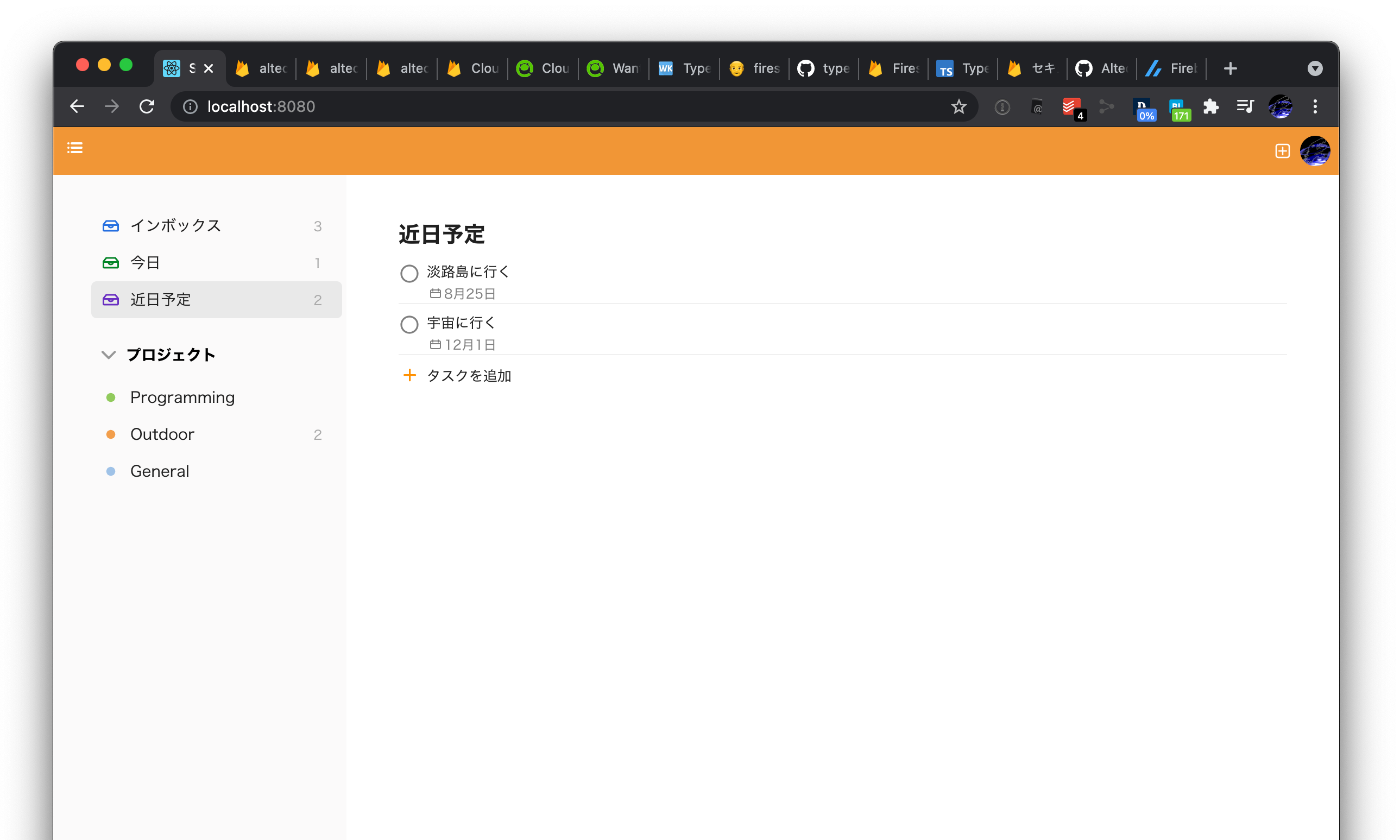
- 「今日」フィルターを動作するように実装した
2021/08/12
- 「近日予定」フィルターを動作するように実装した
2021/08/13
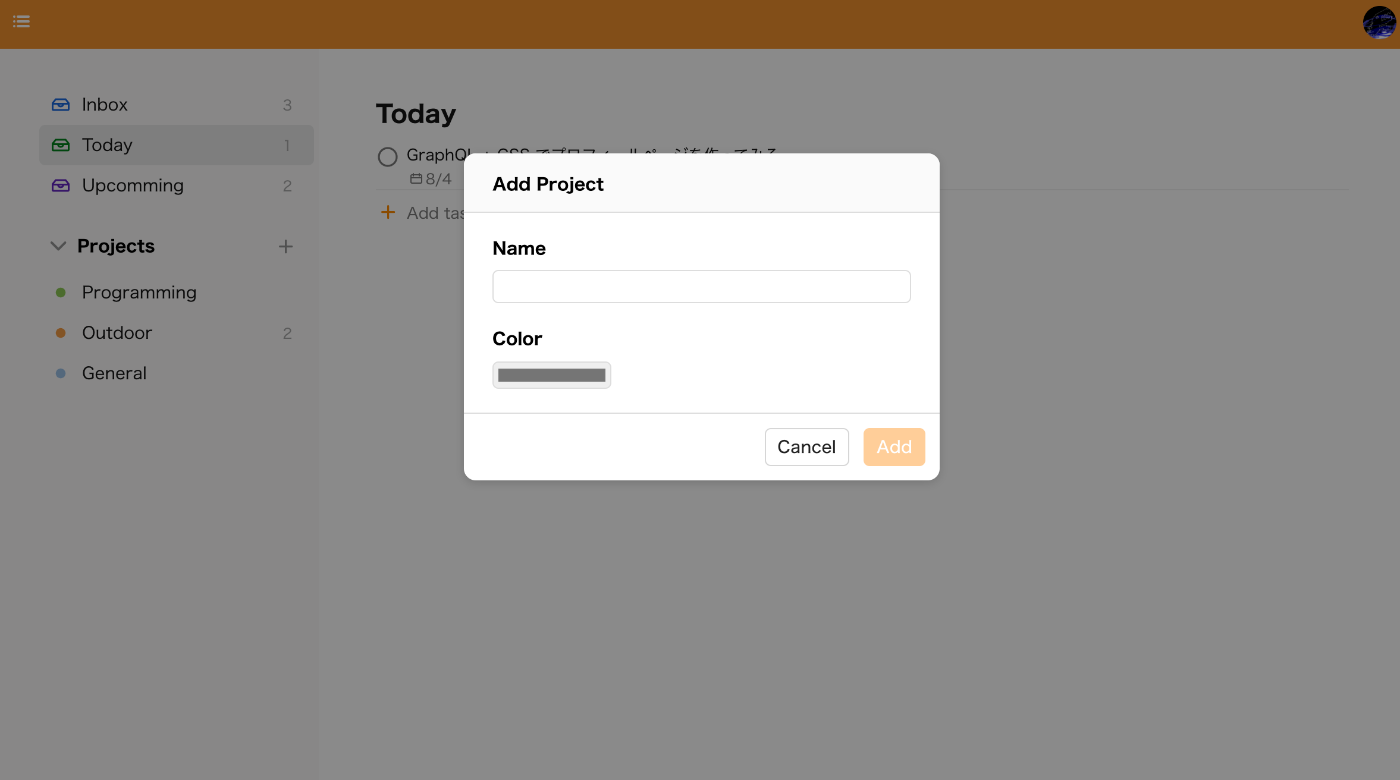
- プロジェクトを追加できるようにした
- ユーザー登録できるようにした
- 英語化した
- 細かいインタラクションが未定義のところを直した
セットアップ(フロントエンド)
Snowpack で React アプリを作る
yarn create-snowpack-app todoist-clone --template @snowpack/app-template-react-typescript
セットアップ(Firebase)
Cloud Firestore でデータベースを作る
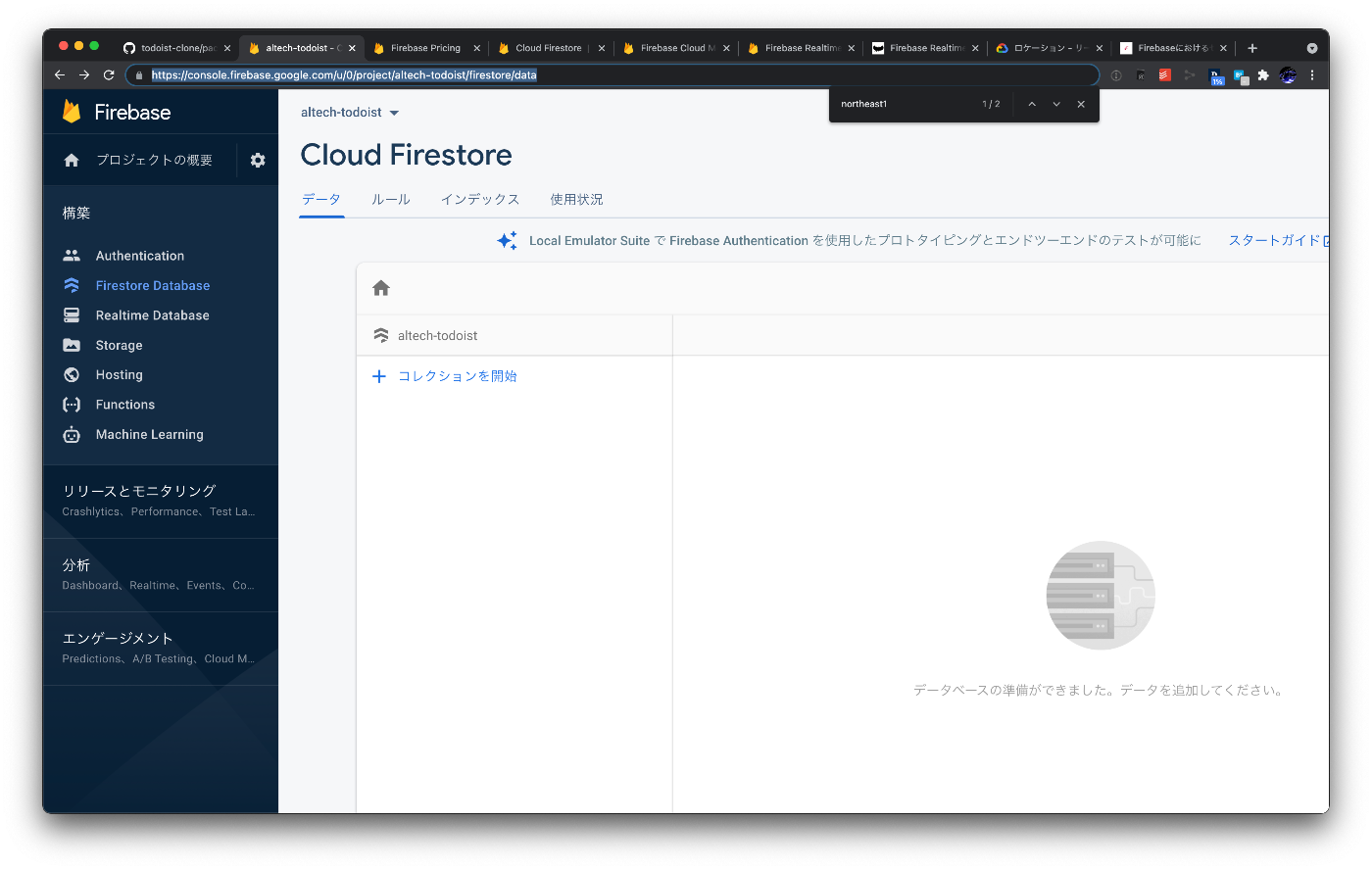
https://console.firebase.google.com/u/0/project/altech-todoist/firestore/data (private)
コンソールからわかること
- コレクションは明示的に管理されている
- ルールはコンソールからも記述可能
- ルールのモニタリングが提供されている
- インデックスは複合インデックスが貼れる(KVS的に自動インデックスもある)
- モニタリングは read, write, delete とリアルタイム更新(スナップショットリスナー)に分かれる

料金プラン的なもの
Firebase アプリも作る
Firestore のデータベースとは別に、アプリがある。アプリは、プラットフォームごとに別々。
| 1 | 2 |
|---|---|
 |
 |
これで apiKey とかできるのでもろもろセット。
基本はスタートガイド https://firebase.google.com/docs/firestore/quickstart#web-v9 にしたがって進める。
余談:firebase の beta (v9) だけど型がついてるので嬉しい。
export declare function initializeApp(options: FirebaseOptions, name?: string): FirebaseApp
ドキュメントを追加してみる
注意:コレクションは暗黙的にも作成されうる。
Cloud Firestore はデータをドキュメントに保存します。ドキュメントはコレクションに保存されます。データを初めてドキュメントに追加すると、Cloud Firestore によってコレクションとドキュメントが暗黙的に作成されます。コレクションやドキュメントを明示的に作成する必要はありません。
試しにドキュメントを追加してみる
セキュリティルールによって弾かれる場合
useEffect 内で以下のように記述:
addDoc(collection(db, 'users'), {
first: 'Ada',
last: 'Lovelace',
born: 1815,
count: count,
})
.then((docRef) => {
console.log('Document written with ID: ', docRef.id);
})
.catch((e) => {
console.error('Error adding document: ', e);
});
(正しく)エラーが吐かれた。

これは Firestore のルールが次のように定義されているため。デフォルトでは全てのドキュメントの読み書きを禁止している。
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /{document=**} {
allow read, write: if false;
}
}
}
弾かれない場合
したがって、Firestore のルールを変更する。別で書いたように、コレクションはクライアントから指定して作成することもできるため、それを禁止するのであれば、元のルールは残す必要がある(ルールは、先にマッチしたものが適用される)。
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /users/{userId} {
allow read, write
}
match /{document=**} {
allow read, write: if false;
}
}
}
これでどうだろうか?
Document written with ID: BM86Xn58ijiGWlaIsJCu
成功。
ref.
セキュリティ ルール言語 | Firebase
ownplate/firestore.rules at master · Nakajima-Foundation/ownplate
ID について
ここではあたかも userId がある前提で進めたが、うまくいった。概念的に ID がパスに含まれるようになっているようだ。ちなみに、ID はクライアントから指定することも、自動生成に任せることもできる。同一性の追跡がオブジェクトの保存よりも先んじて必要となるようなケースで前者が有効だろう。
ref.
Cloud Firestore にデータを追加する | Firebase
コンソールからわかること
コンソールを見ると、次のように実際にドキュメントが追加されていた。ちょっと楽しい。
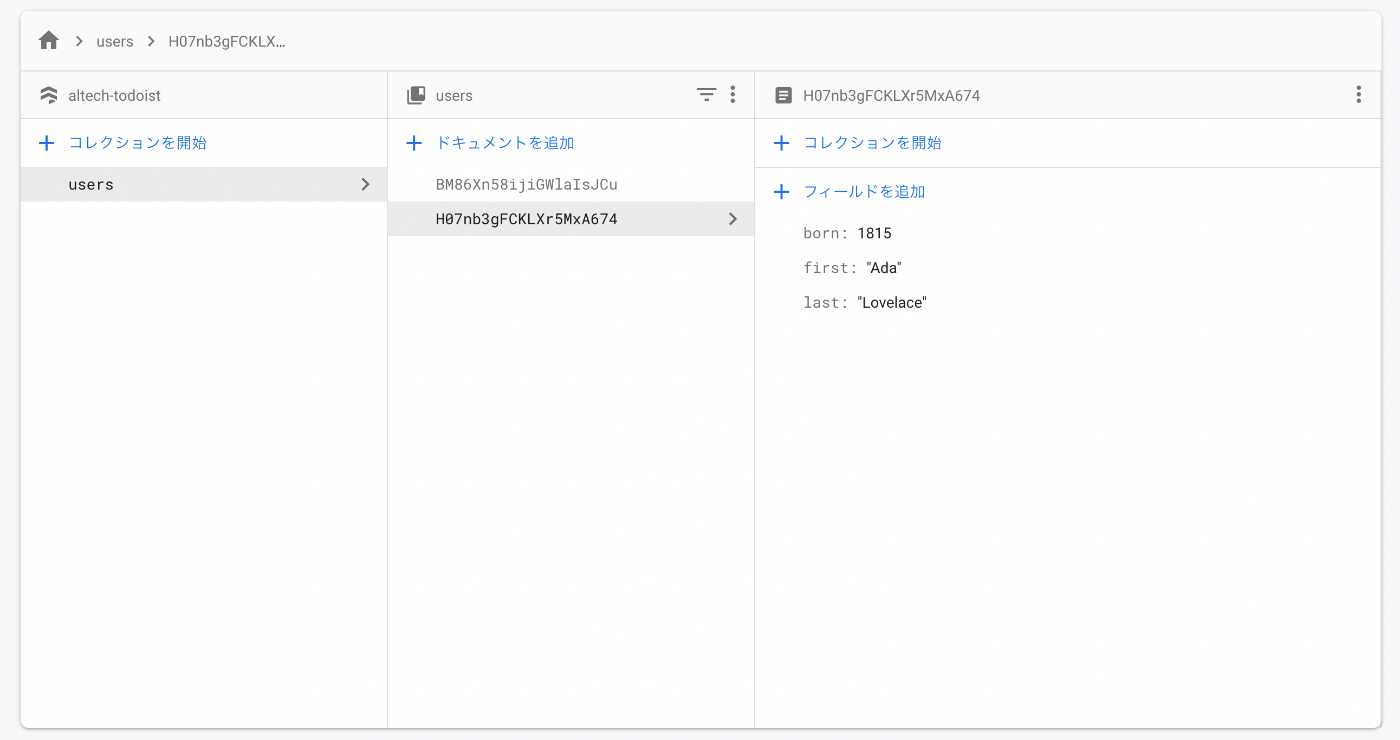
ここでいくつか。
わかること:
- 「+コレクションを追加」が左のカラム(database 直下)にも右のカラム(users 直下)にもあることから、ドキュメントが階層的に構築できることがわかる。この利点は純粋に探索だろう(言い換えれば、どのような探索が必要かを考慮して階層を設計する必要がある)。
- コレクションの名前は複数形にするのがお作法のようだ。そちらの方が一般的なのでわかりやすい。
疑問:
- 階層構造はパフォーマンスに影響を与えるだろうが、セキュリティルールとはどのような関係を持つか?例えば、上位の階層の権限が下位の階層の権限のデフォルトとなるだろうか?(予想:ならない)
- 探索と構造の設計については、おそらく研究の余地がある。
- ただし、単一フィールドのインデックスについては全て自動的に貼られるので(余談:これは素晴らしい設計だと思う)、かなりの部分についてはあまり考えることなく解決するのではないか。
デフォルトでは、Cloud Firestore はドキュメント内のフィールドおよびマップ内のサブフィールドごとに単一フィールド インデックスを自動的に維持します。Cloud Firestore では単一フィールド インデックスに次のデフォルト設定が使用されます。
Cloud Firestore のインデックスの種類 | Firebase
型をつける
Firestore のドキュメントには任意の key を含めることができる。これはクライアントのできることを制約しないという点において優れている(そのように自由に追加された key の全てに自動でインデックスがつくことでパフォーマンス面のトレードオフを解決しているのであれば尚更)。
実際には、スキーマはあるが、それは後付けで良いということだ。だから、クライアントでアプリケーションを構築するにあたっては、スキーマは欲しい。ちょうど JavaScript が TypeScript によって漸進的型付けを得たように。
ちょうど addDoc は次のような型定義になっている。T を定義すればよさそうだ。
/**
* Add a new document to specified `CollectionReference` with the given data,
* assigning it a document ID automatically.
*
* @param reference - A reference to the collection to add this document to.
* @param data - An Object containing the data for the new document.
* @returns A Promise resolved with a `DocumentReference` pointing to the
* newly created document after it has been written to the backend (Note that it
* won't resolve while you're offline).
*/
export declare function addDoc<T>(reference: CollectionReference<T>, data: T): Promise<DocumentReference<T>>;
ということで、こうする。
interface User {
first: string;
last: string;
born: number;
count: number;
}
addDoc<User>(collection(db, 'users'), {
first: 'Ada',
last: 'Lovelace',
born: 1815,
count: count,
})
しかし、これだと第一引数 collection(db, 'users') が通らない。
-
Userを型パラメータに含めたことでaddDocは第一引数にCollectionReference<User>を要求する。 - 一方、
collection(db, 'users')はCollectionReference<DocumentData>を返す。 -
DocumentDataとUserでは型が解決しないため、エラー。
オブジェクトのキーの型を限定する
ところで、この DocumentData の型は TypeScript に慣れていない自分からするとちょっと面白かった。
export declare interface DocumentData {
/** A mapping between a field and its value. */
[field: string]: any;
}
これは、オブジェクトの任意のキーが文字列型で、バリューが any 型だということを表すようだ。field となっているところはなんでもよくて、ググった感じだと key とかもよくある。こういうことができるということは・・・、いろいろできるね。
話を戻して。
API を全体的に眺める
@firebase/firestore | Firebase
(TBD)
ドキュメントに型をつける
addDoc には型パラメータがある
Firestore のドキュメントには任意の key を含めることができる。これはクライアントのできることを制約しないという点において優れている(そのように自由に追加された key の全てに自動でインデックスがつくことでパフォーマンス面のトレードオフを解決しているのであれば尚更)。
実際には、スキーマはあるが、それは後付けで良いということだ。だから、クライアントでアプリケーションを構築するにあたっては、スキーマは欲しい。ちょうど JavaScript が TypeScript によって漸進的型付けを得たように。
ちょうど addDoc は次のような型定義になっている。T を定義すればよさそうだ。
/**
* Add a new document to specified `CollectionReference` with the given data,
* assigning it a document ID automatically.
*
* @param reference - A reference to the collection to add this document to.
* @param data - An Object containing the data for the new document.
* @returns A Promise resolved with a `DocumentReference` pointing to the
* newly created document after it has been written to the backend (Note that it
* won't resolve while you're offline).
*/
export declare function addDoc<T>(reference: CollectionReference<T>, data: T): Promise<DocumentReference<T>>;
型パラメータをつける
ということで、こうする。
interface User {
first: string;
last: string;
born: number;
count: number;
}
addDoc<User>(collection(db, 'users'), {
first: 'Ada',
last: 'Lovelace',
born: 1815,
count: count,
})
しかし、これだと第一引数 collection(db, 'users') が通らない。
-
Userを型パラメータに含めたことでaddDocは第一引数にCollectionReference<User>を要求する。 - 一方、
collection(db, 'users')はCollectionReference<DocumentData>を返す。 -
DocumentDataとUserでは型が解決しないため、エラー。
メモ:オブジェクトのキー全体の型を限定することができる
ところで、この DocumentData の型は TypeScript に慣れていない自分からするとちょっと面白かった。
export declare interface DocumentData {
/** A mapping between a field and its value. */
[field: string]: any;
}
これは、オブジェクトの任意のキーが文字列型で、バリューが any 型だということを表すようだ。field となっているところはなんでもよくて、ググった感じだと key とかもよくある。こういうことができるということは・・・、いろいろできるね。
collection には型パラメータがない
addDoc と同じように collection にもドキュメントの型を指定するパラメータがあるかな?と思って探したけどなかった。
なんでないんだろう?不親切だな、と一瞬思ったけど、あとで試行錯誤しながら思ったこととして、たぶんここに型パラメータがないのは、本当に任意の型が入っている可能性があるからだと思う。
(とここまで考えたが、しかし、だとすれば addDoc の第一引数の型も T ではなく DocumentData になっているべきではないだろうか??)
addDoc<T>(reference: CollectionReference<DocumentData>, data: T)
まあそこは言っても仕方がないので、別の方法で解決を探る。
変数にして型をつける
これを解決しようとして最初以下のようにしたけど、これだと = の右辺と左辺で型エラーになる。
const usersCollection: CollectionReference<User> = collection(db, 'users');
addDoc<User>(usersCollection, ...)
それはまあ考えてみるとそうで、もしこれが通るのであれば、最初からエラーにはなっていない、のだと思う。DocumentData という型は User という型よりも「広い」から、usersCollection という値に User 型が期待するものが入っていることは保証できない(この理解を確かめるために、usersCollection の型を any として通ることを確認した)。例えば生まれた年に文字列が入っている、ということがありえる。
とても初歩的な理解を得た。
解決:強制的に型をつける
実際にはそういうデータであるということがなんらかの根拠によって確信できる場合にその型を指定する、ということができるだろうと思って調べた。as を使って以下のように書けば良い。
addDoc<User>(collection(db, 'users') as CollectionReference<User>, {
first: 'Ada',
last: 'Hoge',
born: 1815,
count: count,
})
当面はこれでよさそうだ。
補足:もっと考えると
厳密にはこの方法にも穴があって、例えば Chrome の console から変なデータを入れられたら、users というコレクションに想定しない形のデータが入ることはあり得る。上記のように wirte するケースであれば実害はないかもしれないが、read するケースでは痛い目を見る可能性はある。
ちょっと調べて、同じようなこと考えた記事があったのでメモしておく。一応、Firebase のセキュリティルールでバリデーションを行うことで最終防衛線を貼ることは可能ということだ。
Firestore のデータを TypeScript と Security Rules で安全に扱う話 - GiXo Ltd.
こう考えると、スキーマが後付けで済むというのは、開発をスケールする上では対応をシフトしていくことになるのだろう。
サービスの開発初期はスキーマは柔軟でアプリケーションコードの側にあり、安定してきたらストレージの方にスキーマのマスターがありエラーをより確実に排除する、というのが理想的な開発のコントールなのかもしれない。
API を全体的に眺める
データ設計
ざっくり書き出し
アプリを見て存在するオブジェクトとオブジェクト間の関連を書き出した(書き出した、と言ったけど、この中で多くの選択をしたため、ある程度この時点で設計意図を持っている)。
// Basic objects and associations:
// ユーザーがある。
// ユーザー以外のすべてのデータは、ただ一人のユーザーに必ず紐づく(少なくとも当面の間)。
// プロジェクトは0個以上のセクションを持つ.
// タスクはセクションに属しているかもしれないし、属していないかもしれない
// タスクは、
// 名前を持つ
// 完了ステータスを持つ
// 優先度を持つ
// スケジュールを持つ期限を持つかもしれない
// 0個以上のコメントを持つ
// プロジェクトまたはプロジェクトのセクションのいずれかに属しているかもしれない
// 0個以上のタグに紐づけられているかもしれない。
// スケジュールは、
// 期限を持つ。
// 期限は繰り返すかもしれない(不完全な定義)
// プロジェクトは、
// ビューを持つ
// ビューは、
// 並び替え方法を持つ
// レイアウト方法を持つ
// フィルタがある。
// フィルタは、いろいろな条件によってタスクを抜き出し、一つの画面に並べる
// 「インボックス」という削除不可能な特別なフィルタがある。これは、プロジェクトに属していない全てのタスクを抜き出す
// そのほかにも、「今日」「近日予定」という特別なフィルタがある。
// フィルタもビューを持つ。
// タグがある。
// 名前のみを持つ。
// アクティビティがある。(ログ的なもの)
// 例:あるタスクを追加した
上記をベースに、以下を行う。
-
Model.tsxというファイルに TypeScript の型を表現する - Firestore の階層に落とし込む
コンポーネント設計
ユーザー認証
丸ごとセクションが用意されているのでそれに沿って忠実に進めればよさそう。
選択肢
UI まで用意している方と、SDK までにとどめている方の二つがある(もちろん前者は後者に依存)。
- FirebaseUI Auth
- Firebase SDK Authentication
今回は FIrebase を使うことでどこまで簡単になるか?に興味があるため、FirebaseUI Auth を使ってみる。
コンソールでの操作
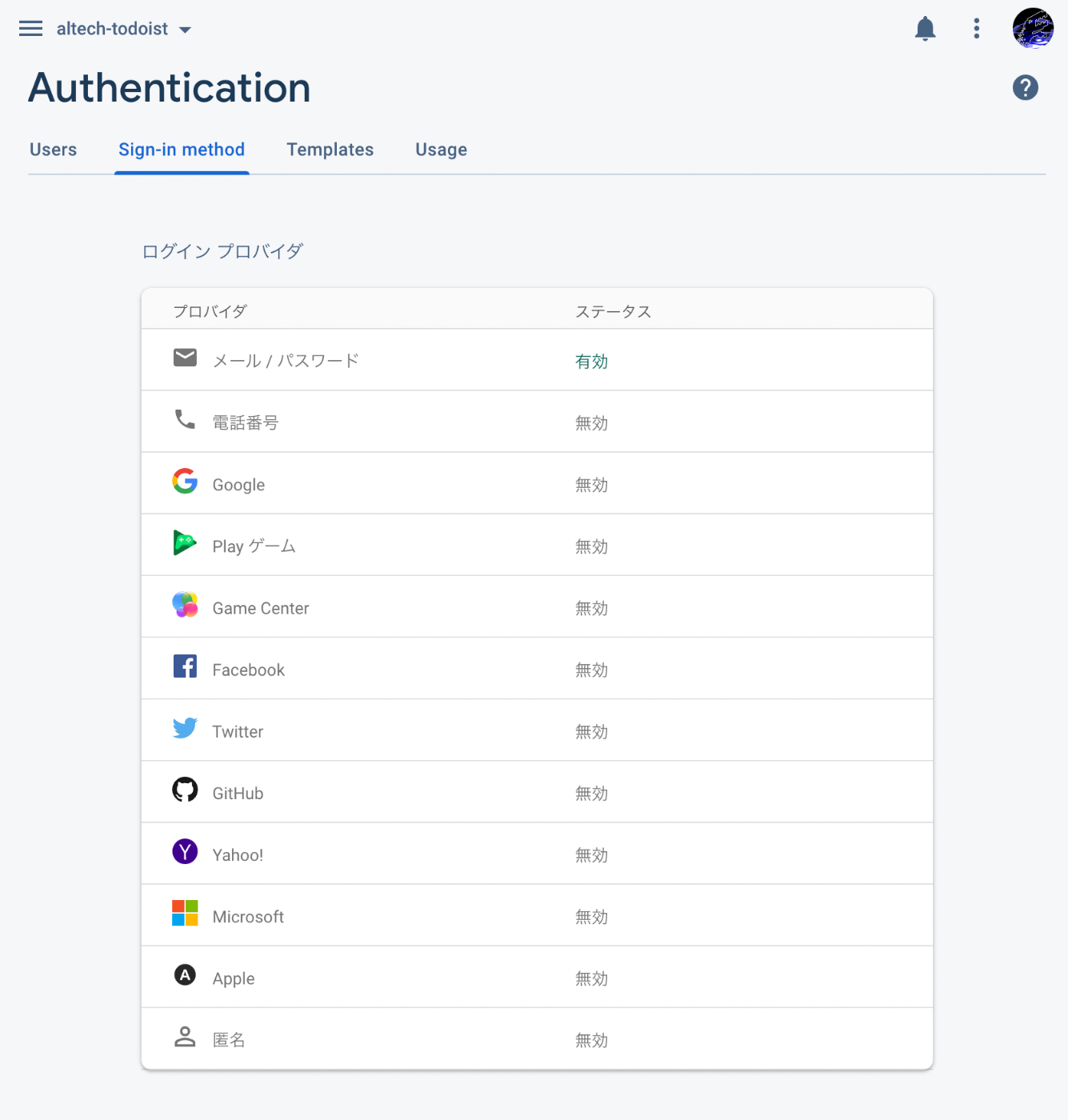
Authentication 機能を有効にする
Firestore 機能を有効にしたときと同じように、コンソールから Authentication 機能を有効にする。
ログイン方法の選択
| 1 | 2 |
|---|---|
 |
 |
デフォルトでパスワードリセットとかの機能も付いてくる。便利。
firebaseui は firebase v9 (beta) と一緒に動かなかった。。。
実はこれまでせっかくならと思って firebase の v9 (beta版) を使っていたのだが、ここにきて firebaseui がまだ対応していないことが、コンパイルエラーの調査過程で分かった。。(かなしみ)
注: FirebaseUI は v9 モジュラー SDK と互換性がありません。v9 互換レイヤー(特に app-compat および auth-compat-exp パッケージ)では、v9 とともに FirebaseUI を使用できますが、その場合、アプリのサイズ削減などの v9 SDK のメリットを得ることはできません。
FirebaseUI でウェブアプリに簡単にログイン機能を追加する
イシュー https://github.com/firebase/firebaseui-web/issues/837 を見ると対応する方向ではあり直近 draft PR も出ている。ウォッチだけしておいて一旦 v8 の方を使って動作するところまで確かめることにする。
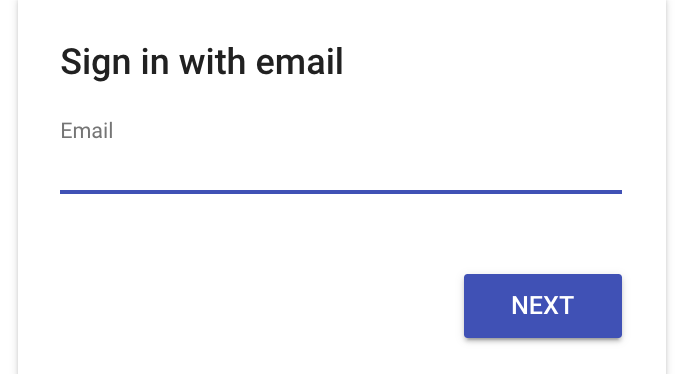
firebaseui on firebase v8 での email ログイン
もろもろ v8 の方式で書き換えて、こんな感じで表示できた。material-design-lite というマテリアルUIのライブラリが使われているため、見た目も良い感じ。
| 1 | 2 |
|---|---|
 |
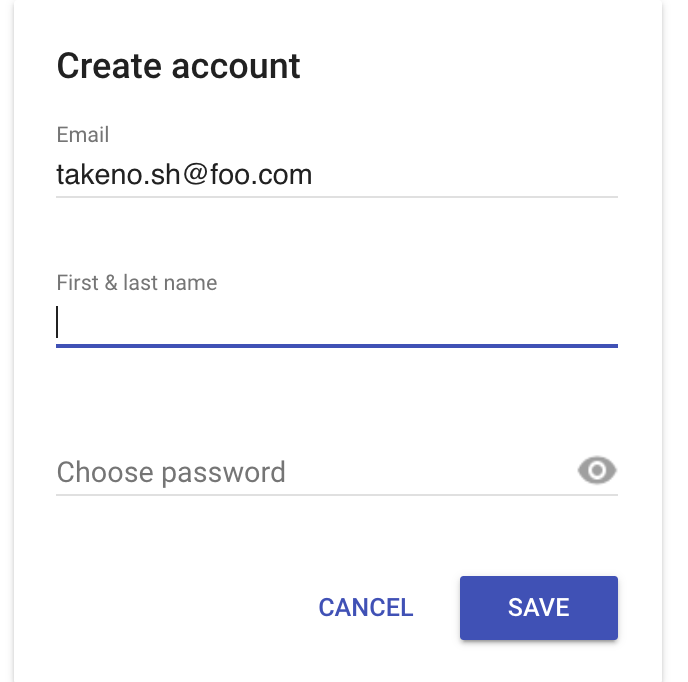 |
Authentication のコンソールの方にもユーザー登録されていることがわかる。
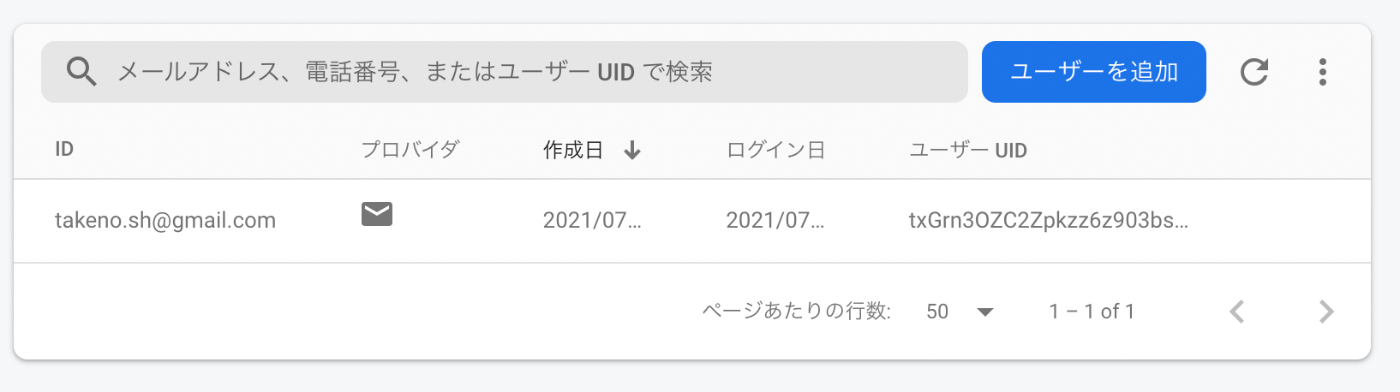
これでミニマムのユーザー認証はできた事になる。これをどうやっって使うか?というと、リクエスト時の変数に格納されるので、セキュリティルールなり処理なりで利用できる。
セキュリティルールでは、Firebase Authentication から提供される認証情報を利用することができます。提供された認証情報は
request.authという変数に格納されます。
Firestoreセキュリティルールの基礎と実践 - セキュアな Firebase活用に向けたアプローチを理解する - Flatt Security Blog
- これをフックにして Firestore に書き込んだりしたい。Cloud Function でできる気がするのでどこかで調べる。
firebase v8 より v9 の方がイケてる
ところで v8 と v9 の auth および firestore のインターフェイスを見てみたが、v9 のほうがイケてると思った(特に firestore は結構I/F違う)。
これから覚えるのであれば v9 の方が良さそうなので、ちょっとどこかで以下をやる。
-
Authentication SDK +
material-design-liteで組んでみる。
React と Firebase を連携させる場合のデータの取り回し
TBD
メモ:
- 非同期になるので、直接状態をセットするのではなく、Firebase の状態を subscribe (observe) する形になることが多いかも?
認証状態の取り回し
認証状態は、Authentication オブジェクト(firebaseAuth)の管理下にある。
firebaseAuth.currentUser というプロパティを介して取ることもできるのだが、このオブジェクトは User | null である。もう少し言うと、最初は null でありセッションなどでサインインしている状態であれば User に変化する。そうでなければ、null のまま。このままだと、
- ロード中と未ログインの区別がつかない
- ロード中から未ログインに遷移した時点での React の状態への反映と再レンダリングができない
と言う問題がある。これを解決するために、onAuthStateChanged を使ってイベントハンドラーを登録することができる。Hooks を使うと次のようになる。
const [loading, setLoading] = useState<boolean>(true);
const [user, setUser] = useState<User | null>(null);
useEffect(() => {
const unsubscribe = onAuthStateChanged(firebaseAuth, (user) => {
setLoading(false);
setUser(user);
});
return unsubscribe;
}, [firebaseAuth]);
これを関数として切り出すことで(カスタムフックス化)、こういう使い心地になる。
const [user, loading] = useAuthState();
エラー系も実装したらこうなる。
const [user, loading, error] = useAuthState();
ネットワークリソースを活用したアプリケーションを React Hooks を使って作っていく場合、適宜こういった Hooks のデザインが必要になりそうだ。
(もう少し言うと、GraphQL の Apollo クライアントなど Hooks が事前に充実している場合はこの手間が不要になるため楽になる ... とはいえ個人で使う場合は Firestore の API に慣れるという点でもデザインの「議論」にならない点でも Hooks がないことはそこまで問題にならないだろう)
Firebase の React Hooks サードパーティライブラリ
一応、このようなものがあった。現在は v9 の SDK には対応していないのでそのまま使えないが、Hooks デザインの参考にはなりそう。
CSFrequency/react-firebase-hooks: React Hooks for Firebase.
Support for firebase 9? · Issue #105 · CSFrequency/react-firebase-hooks
雑に UI にアイコンを当てていく
ソース
(TBD)
色を調整する
- svg 画像には fill と stroke があり、どちらも CSS で直接指定できる
- (これはCSSの知識だが)
currentColorと言うキーワードがあるので、fill や stroke にも使える - 変更できるのはインラインで記述されているもののみで、img タグで読み込まれたものには適用できない

<DivHeader>
<div></div>
<div style={{ fill: 'currentColor' }}>
<svg
xmlns="http://www.w3.org/2000/svg"
viewBox="-2 -2 24 24"
width="24"
height="24"
preserveAspectRatio="xMinYMin"
>
<path d="M4 2a2 2 0 0 0-2 2v12a2 2 0 0 0 2 2h12a2 2 0 0 0 2-2V4a2 2 0 0 0-2-2H4zm0-2h12a4 4 0 0 1 4 4v12a4 4 0 0 1-4 4H4a4 4 0 0 1-4-4V4a4 4 0 0 1 4-4zm7 11v4a1 1 0 0 1-2 0v-4H5a1 1 0 0 1 0-2h4V5a1 1 0 1 1 2 0v4h4a1 1 0 0 1 0 2h-4z"></path>
</svg>
<img src={plusIcon} />
</div>
</DivHeader>
タスクの追加・表示・編集・削除
追加
実験
interface Task {
done: boolean;
name: string;
scheduleDate: Date | null;
}
// ...
setDoc<Task>(
doc(
db,
'users',
user.uid,
'tasks',
'testuidtestuidWithScheduledDate',
) as DocumentReference<Task>,
{
done: false,
name: 'TypeScript で Scheme の処理系を書いてみる',
scheduleDate: new Date(2021, 7 - 1, 26),
},
)
.then((docRef) => {
console.log('Document written.');
})
.catch((e) => {
console.error('Error adding document: ', e);
});
で、以下が得られる。
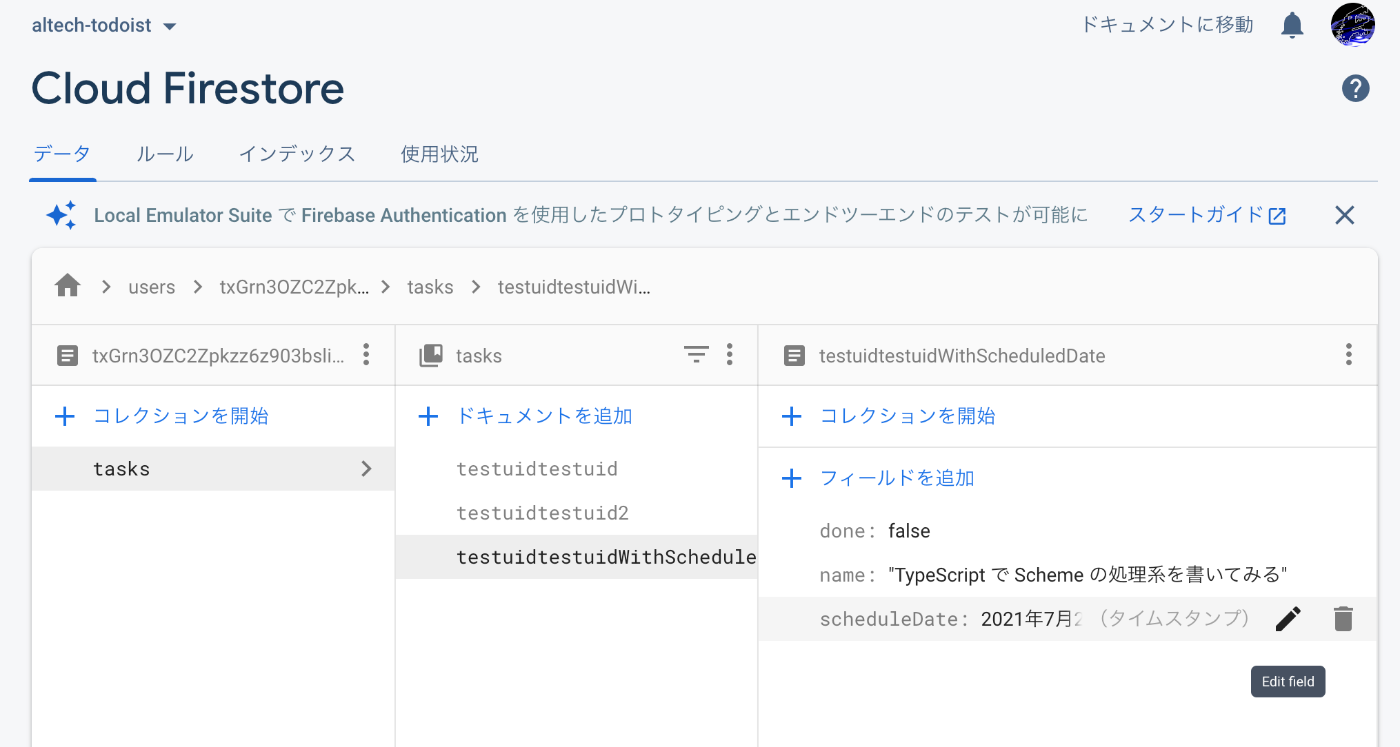
備忘:
- Firestore の型
- Date はなく Timestamp のみがある。
- null はある。
- 同じカラムに異なる型を入れることができる(従ってカラムに型はない:上で書いたことはやや間違い)
- JavaScript の Date オブジェクトを入れればそのまま Timestamp として入る
- 余談
- エディタでファイルを保存したら即座に Firestore のコンソールのデータも増えるのすごい
- ファイル保存 -> HMR によって再実行 -> Firestore に反映 -> (おそらく subscribe によって) コンソールに反映
- すべてがリアクティブな世界
Firestore API 備忘
ドメイン用語
まずドメイン用語としてのドキュメントとコレクションがある。ドキュメントは Firestore に格納されるオブジェクトの一つ一つを表す。おそらく任意のドキュメントはあるコレクションに属す。コレクションはパスを持ち、Firestore の階層のどこかに位置する。
セキュリティルールもコレクションに対して適用される。コレクションに属することを通じて、ドキュメントも階層に属しており、従ってセキュリティルールも適用される。
クラス
DocumentReference、CollectionReference などの参照クラスがある。前者は型パラメータを指定することで、データの形を制約できる。
より基底的なクラスとして、Query がある。これは読み込んだり変更を監視したりでき、かつ絞り込みを行なったり、並び替えを行なったりできる。実は、CollectionReference は Query の拡張なので、同じ操作がこれに対しても可能である。
関数
これはクラスをあまり用いないという JavaScript の慣習に起因するものと思われるが、起点となる操作は全て関数になる。
例えば、コレクションに対応するオブジェクトを宣言する場合、まずもって collection と言う関数を import して、collection(db, '/users/') のように呼び出す。同じようなことが、ドキュメントに対しても言える。
この延長として、addDoc setDoc deleteDoc など C(R)UD 操作が提供されている。
onSnapshot
R = Read に関しては、リアクティブにするためにもう少し高級な概念に基づいている。具体的には、onSnapshot (と onSnapshotsInSync) がある。
まず snapshot と言う用語だが、これはデータは刻々と変化するものであり、その中のある時点の状態を写しとったもの、という風に理解すると良いだろう。この前提で、DocumentSnapshot、QuerySnapshot のような各ドメインの「もの」を写しとったクラスが存在する。
これは基本的に第二引数(ソースコード上は observer と言っているようだ)でコールバックを渡してコントロールする。ovserver は next, error, complete と言う三つで成り立っている(余談だが、next と言う名前にも、Firestore の計算モデルは状態遷移であると言う気持ちが見て取れる)。
onSnapshot は多数のシグネチャパターンを持つが、大きくはドキュメントに対するものとクエリ(コレクション)に対するものというふうに分かれている。
以上が覚えておくべきベーシックな関数だろう。
クエリ言語
TBD.
実装タスクの管理
今まで高頻度で書き換えるタスクの管理は Emacs でやっていたのだが、こんな感じで Todoist で管理してみている(これはホンモノの Todoist)。
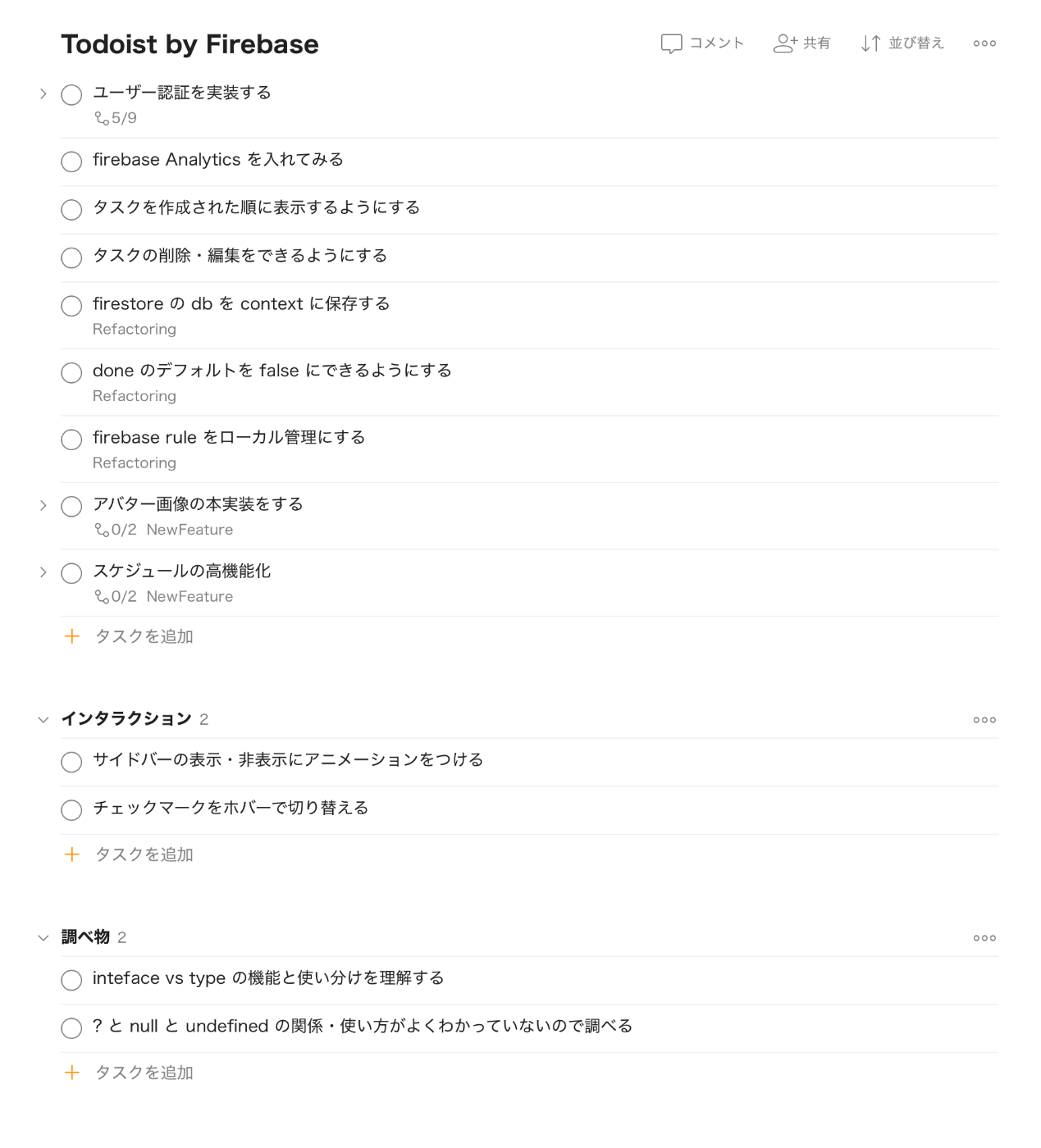
初めは VSCode で管理しても良いかなと思ったけど、冷静に考えてタスク管理とエディタは密結合しない方が良いなと思った。他の IDE とか使うことになった時に使えなくなるので。
組み込みのデータ型周り
日付を扱いたい
- Firestore:
- setter:
DateオブジェクトまたはTimestampクラス - getter:
{nanoseconds: 0, seconds: 1627225200}... Timestampクラス
- setter:
- HTML要素(input 要素を
type="dateで利用した場合):- setter:
"2019-01-01"的な文字列 - getter:
"2019-01-01"的な文字列
- setter:
null と undefined
JavaScript
-
undefinedはオブジェクトの存在しないプロパティにアクセスした時、初期化していない変数、明示的に値を返していない関数の戻り値などで現れる。未定義。 - 一方で
nullはオブジェクト。 -
===で比較した場合にはきちんと区別される。
TypeScript
-
foo?: Timestampのように書くとundefined | Timestampという型になる -
foo: Timestamp | nullは略記法は存在しない
GraphQL の Apollo クライアント、Firestore の SDK のどちらでも、データ的にフィールドが空な場合は null が採用されていることを覚えておくと良い。
唯一、ID をどうするかはやや悩ましいところ。これは Firestore 上で初期化されるという点で、「未定義」と考えても間違ってはいない。
export type Task = {
__type: 'task';
id?: string;
done: boolean;
name: string;
scheduledAt: Timestamp | null;
createdAt: Timestamp | null;
}
``Firestore との繋ぎこみ:hooks and contexts
基本的には複数の箇所で参照が必要になったら即座に context にしていくのが正解。
例えば、認証状態(user)を context にした上で、以下のような hooks を考える。これはプロジェクトのリストを onSnapshot で監視するコードを hooks として切り出したものだが、これを複数の箇所で使ってしまうと、監視するリスナーが各コンポーネントに散らばってしまい、アプリケーション内でも「プロジェクトのリスト」という値にタイミングによってズレが生じてしまう。
これを回避するには、hooks を使うのではなく、useState により作成した状態 projects を全ての直接関与しないコンポーネントまで含めて持ち回す必要がある。そうすることによってわかりやすくなるものは正直何もないので(Firestore のどのデータに自分と子供のコンポーネントが関与しているか、というのがインターフェイス上見えることのメリットはない)、これは無駄。
よって、複数の箇所で利用する=再利用性を必要とする場合には積極的に context にするのが良い。
const useProjects = (): ProjectModel[] => {
const user = useUserValue();
const [projects, setProjects] = useState<ProjectModel[]>([]);
useEffect(() => {
if (!user) setProjects([]);
const projectsRef = collection(
db,
`users/${user!.uid}/projects`,
) as CollectionReference<ProjectModel>;
const unsubscribe = onSnapshot(projectsRef, {
next: (snapshot) => {
const newProjects: ProjectModel[] = [];
snapshot.forEach((obj) => {
const project = obj.data();
project.id = obj.id;
project.__type = 'project';
newProjects.push(project);
});
setProjects(newProjects);
},
});
return unsubscribe;
}, [user]);
return projects;
};
context のインターフェイス
いくつかパターンが考えられるが、ProjectsProvider と ProjectsContext がミニマムで、これが良いとお思う。値を使うときは、useContext(ProjectsContext) と書く。
これを、useContext(ProjectsContext) を useUserValue ないし useUserContext などと抽象化することは可能だが、これはあまり意味がない割に覚える規約が一つ増えるので、よほど多くの箇所で使うのでタイプ数を減らしたいとかでない限り導入しなくて良いと思う。プリミティブを組み合わせて使うという React のスタイルからも離れてしまう。
Firestore のクエリ
追加した順番に表示されるようにする
新しく追加されたら一番下に追加されるようにしたい。そのために、createdAtのようなフィールドを追加して、次のようにクエリを構築する。
const tasks = collection(db, collectionPath) as CollectionReference<Task>;
const q = query(
orderBy('createdAt'),
);
これは書いたらそのまま動いた。
終了したタスクは表示しないようにする
クエリに1行足して、次のようにクエリを構築する。
const tasks = collection(db, collectionPath) as CollectionReference<Task>;
const q = query(
where('done', '==', false),
orderBy('createdAt'),
);
するとコンソールに以下のようなエラーが出る。

インデックスを構築する必要があるということで、表示されているURLをクリックしてみる。するともうインデックスの追加モーダルが準備されていて、ボタンを押すだけだった(すごい)。

インデックスの構築は3分くらい時間がかかった。データは数件しかないけど、裏がすごいシステムになっていてあんまりデータ量に綺麗に比例するものではないのかもしれない。
ドキュメントを流し見した感じ、基本的には単一のフィールドではないクエリは全部インデックスを作る、という考え方のように見える。
規約周りメモ:
進めつつ、都度考えることが面倒になってきたら適宜導入。随時更新。
- default export v.s. named export
- 基本的には named export を使う。
- ただし、明らかに一つしか export しない場合は、ファイル名 = エクポート名 = インポート名。
- ディレクトリ構成(src 以下):
-
./context/.. コンテキスト。{Name}Contextと{Name}Providerの二つをエクスポートする、{name}.tsxというファイルが配置される。 -
./hooks/... カスタムフックス。 -
./... 上記以外のファイル。ほとんどはコンポーネント。
-
- styled-components の名前は、
DivHeaderAnchorSubmitなど、HTML 要素名を先頭につける。- 理由1) 最低限のセマンティックコーディングを担保するため
- 理由2) スタイルだけがついたコンポーネントと、(明示的にファイルを分けて作成した)ロジックを持つ React コンポーネントとでは、持っている意味の量が違う。それを見分けられるようにするため。
React コンポーネントの1ファイル内の構成:
import React from 'react'; // サードパーティライブラリのインポート群
import Project from './Project' // プロジェクト内のインポート群
type Props = {}
// その他、State などで使う型定義があればここに追記
export const Task: React.FC<Props> = (props) => {
return <DivContainer>...</DivContainer>; // 最も外側の要素は Container と呼ぶ
}
// styled-components による CSS 定義群
// 補助的なルーチン、定数
観点:
- 依存の検索性
- リファクタリング容易性
- 特にコンポーネント名。
上記のルールに従うと、コンポーネント名 TaskDropdown の検索結果は以下のようになる。

これは、export 行、import 行、使用箇所、でそれぞれ最小になっているので、よく凝集されていると思う。default export だと、この辺りが少しいまいちになる。また最も外側の styled component にも Container というコンポーネントに依存しない名前をつけることで、名前が凝集されるようにしている。
React アプリケーションで一般的に使える方針として、「積極的にコンポーネントを分割する&コンポーネントごとにファイルを分ける、という慣習を最大限レバレッジして利用する」 というふうにするのが良さそうだ。特に、そのファイル内では、その名前を所与のスコープとして名前づけに活用すること。DivContainer などはその例。
変数周り:
以下は、ライフタイムが短かくて(定義箇所と使用箇所が極端に近い)、省略した方が良いもの。
-
document->doc(これは SDK もそうしている) -
snapshot->sne.gdocumentSnapshot->docSn -
collection->col
型を付ける(最終版)
firestore の入出力に型をつける
FirestoreDataConverter interface | Firebase
a2c09a811696271eaf3a8a0b8ab2ec58f3fe71d3
ActiveRecord がやっていることではあるが、オブジェクトのライフサイクルをデータベースの保存前からにすることで、見通しがシンプルになる。
結論、React Hooks の見通しが圧倒的に良くなるのと、型が自動的につくので早めに入れた方が良い。
Firestore データ設計
- 大前提、Firestore は階層構造である
- 例:
/users/526865/projects/319541/tasks/32323
ここまでの経験を踏まえて、Firestore でどのようにデータ設計をすると良いか、一定の判断材料と指針を示す。これは、単純なことをやるには単純な記述と構造ででき、複雑なことをやるには複雑な記述と構造を漸進的に追加すれば良いようなエンジニアリング・プロセスとなるように意図している。
ポイント:セキュリティルール
階層構造は、「所有」の関係を表すと考えることは有用だ。所有しているものは、多くの操作が許可される。
Firestore のセキュリティルールは、上位のパスに含まれるドキュメント ID をルール定義の中から参照できる。以下は、タスク管理アプリケーションのようなユーザーごとに完全にデータが相互参照・相互更新が起きえないものに対して、userID を活用してセキュリティルールを明快に定義している例だ。
service cloud.firestore {
match /databases/{database}/documents {
match /users/{userId} {
allow read, write: if request.auth.uid == userId;
match /tasks/{taskID} {
allow read, write: if request.auth.uid == userId;
}
match /projects/{projectID} {
allow read, write: if request.auth.uid == userId;
}
}
}
}
ポイント:削除処理
親子関係は、親の存在を前提としているということを、データのライフサイクルの管理のために時には活用すると良い。
例えば、タスク管理アプリケーションであれば、「タスク」と「プロジェクト」というデータがあり、タスクはプロジェクトに属しているかもしれないし、属していないかもしれない。

この場合、「タスク」と「プロジェクト」を並列に並べるか、親子関係を許すか、という二つの設計パターンが大きく考えられるだろう。
ここで、アプリケーションとしては「プロジェクト」を削除するということは、そこに紐づけられている「タスク」も同時に全て削除される、という関係がある。親子関係にすることで、この関係を完全かつ自動的に保障することができる。以下は、そのようにした例だ。
service cloud.firestore {
match /databases/{database}/documents {
match /tasks/{taskID} { // プロジェクトに属さないタスクは「インボックス」に入る
allow read, write: if request.auth.uid == userId;
}
match /projects/{projectID} {
allow read, write: if request.auth.uid == userId;
match /tasks/{taskID} {
allow read, write: if request.auth.uid == userId;
}
}
}
}
}
ポイント:取得処理
大前提ではあるが、Firestore の階層関係は「親から子へ辿る」ことが容易である。従って、基本的な取得処理をここに寄せて考えることは重要だ。例えば、「あるプロジェクトのタスク一覧を表示する」ということは collection("/users/526858/projects/1/tasks") というクエリで直接的にできる。これは最も基本的な視点だ。
とにかく、コレクションがクエリ対象としての基本単位である。とはいえ、あらゆるパターンの取得・絞り込み・検索に対応しようとすると、コレクションに横断的になり、コレクションを階層構造にするということができなくなる。例えば、「すべてのプロジェクトに横断的に、今日中に予定されているタスクの一覧を取得する」というように。
しかし、このような場合にわざわざ階層構造を解散して、リレーショナルデータベースのようにフラットにする必要はないし、するべきではないと考える。というのは、階層構造には自由度が低いが故の利点があり(それはすでにここまでに述べた)、同時にそれは UI とある程度近い構造にすることで Firestore の生産性向上の恩恵を受けやすいということだからだ。これは捨てたくない。ではどうするか?
ポイント:検索処理
コレクションのタイプさえ同じであれば、コレクションに横断的な検索というのが可能である。タイプというのは、tasks や projects のようなパスに含まれるコレクション名のことだ。collectionGroup('tasks') と書くことで、Firestore 中の全てのタスクが対象となる。
しかし、これを実行しても、権限がないと言われる。これは、このままだと他のユーザーのタスクも対象となってしまうためだ(逆に言えば、サービス運営者がサービス上の全てのデータを集計する場合にはそれが使えるということだ)。
そういうわけで、where 条件によって userID を絞り込みたくなるのだが、絞り込み対象にできるのは対象となるドキュメントに含まれるフィールドのみである。こういうことがあるので、やや迂遠ではあるが、すべてのドキュメントには userId のような絞り込みと権限チェックに必要なフィールドを個別に埋め込んで置くこと、が解決方法となる。
残念ながら、この場合、セキュリティルールも僅かに複雑化してしまう。異なるユーザーIDをセットすることができないように、リソースの作成・更新処理においてバリデーションを行う必要がある。
match /tasks/{taskID} {
allow read, delete: if request.auth.uid == userId
allow create, update: if request.auth.uid == userId && request.resource.data.userId == userId;
}
とはいえ階層構造によって得られる分かりやすさを考えれば、僅かな手間だろう。
ポイント:作成・更新処理
実はここに関してはあまりいうことがない。
ちょっと複雑なケースで言えば、あるタスクを、あるプロジェクトから別のプロジェクトの配下に移動する場合は、トランザクションを張ってコピーして元を削除すれば良い。
その他
- バリデーション:セキュリティルールのところで頑張ることはできるが、ロジックが分散してしまうのでクライアントの Converter でしばらくはやるのが良さそう
WIP: サブスクリプションはアプリケーション開発の何を変えるか?
プロジェクトの配下に、セクションのような階層構造を入れるとする。どういうデータ設計になるか?
現状のままだと、以下のどちらか?
方針1
- プロジェクト直下ののタスクを読み込む
- プロジェクト配下のセクションを読み込む
- 上記に依存して、セクションは以下のタスクを読み込む
方針2
- collection group を使って全体のタスクを見つつ、絞り込む。
--
話を Todoist 的なものに絞って考える。
Firestore は常に onSnapshot で同期されるので、データ量が多すぎるというケースでなければ、全部投機的に読み込んでしまっても構わない気がする。
そもそも、なぜ普段画面遷移時に読み込んでいるのかといえば、主要な理由の一つは、最新のデータを取得したいから。しかし onSnapshot があればそこは問題ない。
あとは、
- サーバーのコストとスケーラビリティ
- サーバーとクライアントの通信量
- クライアントのメモリ量
あたり。
1はスケーラビリティは問題ないのと、コストは結果の監視自体にかかるわけではないので、特段不利な部分はない(むしろデータさえ変わらなければ読み取らないという点で有利とさえ言える)。
2, 3はアプリケーション特性次第だから、どこまでを投機的にやるかという話だろう。例えば、Todoist であっても、過去に行った全てのタスクを投機的に取得してオンメモリで保持しているわけではないはず。だから、ここは自由に設定でき、ユーザー体験を十分に高められる程度に投機的に行えば良い。
--
こういう理解はどうだろうか。
GraphQL で Apollo クライアントを使った開発を考える(query ベースで、subnscription は使わないとする)。これは直近自分のところでやっているものだ。
この場合、インメモリのグローバルストアがあるような感じで開発はできるし、提供されるカスタムフックスによって、宣言的に記述はできる。しかし、データの更新が起こった時に、どのキャッシュをパージするか(クエリの結果をリロードするか)については、明示的な管理が必要になる。
subscription を使うと、こういう複雑性から解放される。この複雑性から解放される結果、思わぬ副産物が手に入る。それは、(現在の画面には表示されないデータに対しての)投機的な読み込みを(複雑性が上がらないので)できるという副産物だ。
だから、次のような出発点から始めることが可能になる。それは、おおよそユーザーにとって必要となるものは全部オンメモリにロードしておくという方針だ。
--
ということで新しい方針。これは体験・複雑性の両面で問題を解決する。
方針3
- 方針1を完全に投機的に行う