[メモ] LM Studio でオフライン LLM 実行環境を手に入れる。ついでに Obsidian copilot で呼んでみる
はじめに
やりたいこと
LM Studio というオフラインLLM実行環境を簡単に作成できるアプリケーションがあります。
オフラインLLM実行環境が欲しい気持ちになったので、試しに使ってみました。
結果、サクッとオフラインLLM実行環境が作成でき[1]、ついでに Obsidian のコミュニティプラグイン obsidian-copilot で動かせました、
やったことをメモとして残しておきます。
LM Studio について
概要
LM Studio 公式 より:
With LM Studio, you can ...
🤖 - Run LLMs on your laptop, entirely offline
👾 - Use models through the in-app Chat UI or an OpenAI compatible local server
📂 - Download any compatible model files from HuggingFace 🤗 repositories
🔭 - Discover new & noteworthy LLMs in the app's home page
雑に翻訳すると、
- お使いの Mac/Windows/Linux で、完全オフラインなLLM実行が可能だよ
- モデルは LM Studio のチャットUI またはローカル API サーバで使えるよ。API は OpenAI 互換だよ
- モデルは Hugging Face リポジトリからダウンロードできるよ(互換性あるものに限る)
- LM Studio のホーム画面で新着&注目のLLMを発見できるよ
らしいです。
Requirements
強くないPCでもLLM実行できる、というのが売りなだけあり、要求スペックは高くないですね。
What are the minimum hardware / software requirements?
- Apple Silicon Mac (M1/M2/M3) with macOS 13.6 or newer
- Windows / Linux PC with a processor that supports AVX2 (typically newer PCs)
- 16GB+ of RAM is recommended. For PCs, 6GB+ of VRAM is recommended
- NVIDIA/AMD GPUs supported
やったこと
準備
LM Studio インストール
LM Studio のページからインストーラをダウンロードして実行します。2024年5月6日時点では、トップページにインストーラへのリンクがありますね。
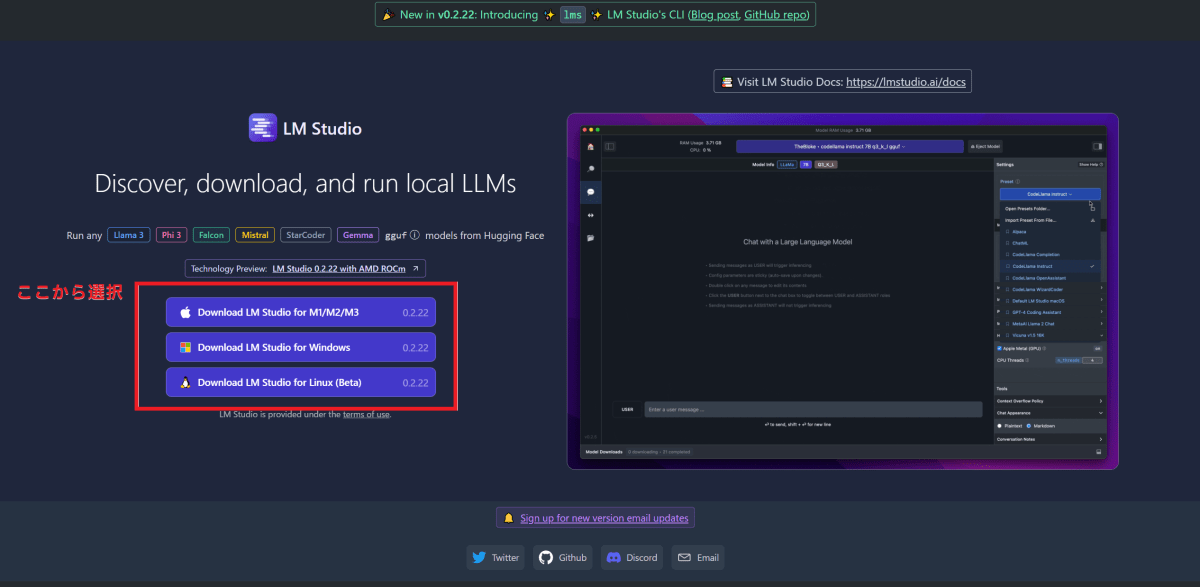
インストールしたところ。
現在のメニューはこんな構成です。
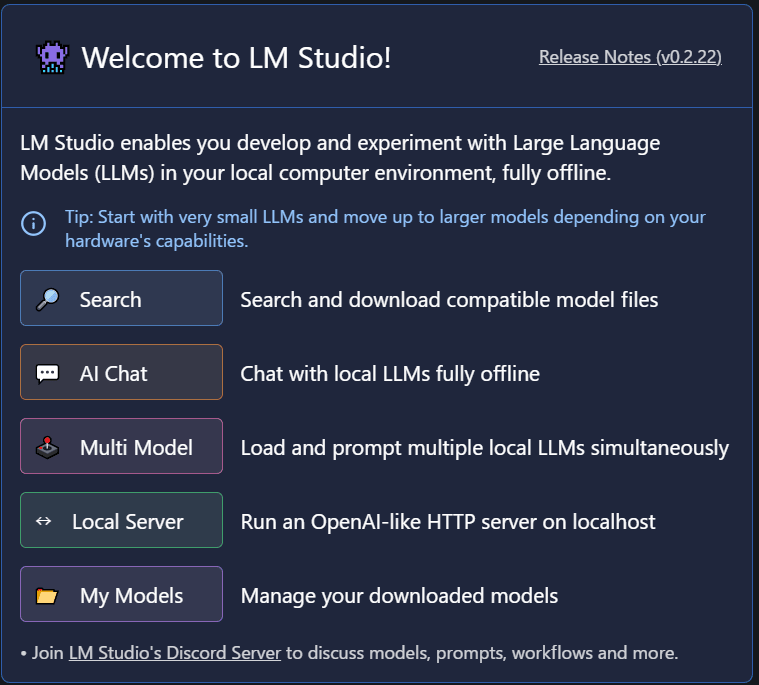
使ってみる
Search:モデルを探す
ホームにある検索欄から、もしくは左側のメニュー「🔍(Search)」からモデルを探すことができる。
試しに Snowflake Arctic を探す。記事からリンクされている Hagging Face のURLは ここ。
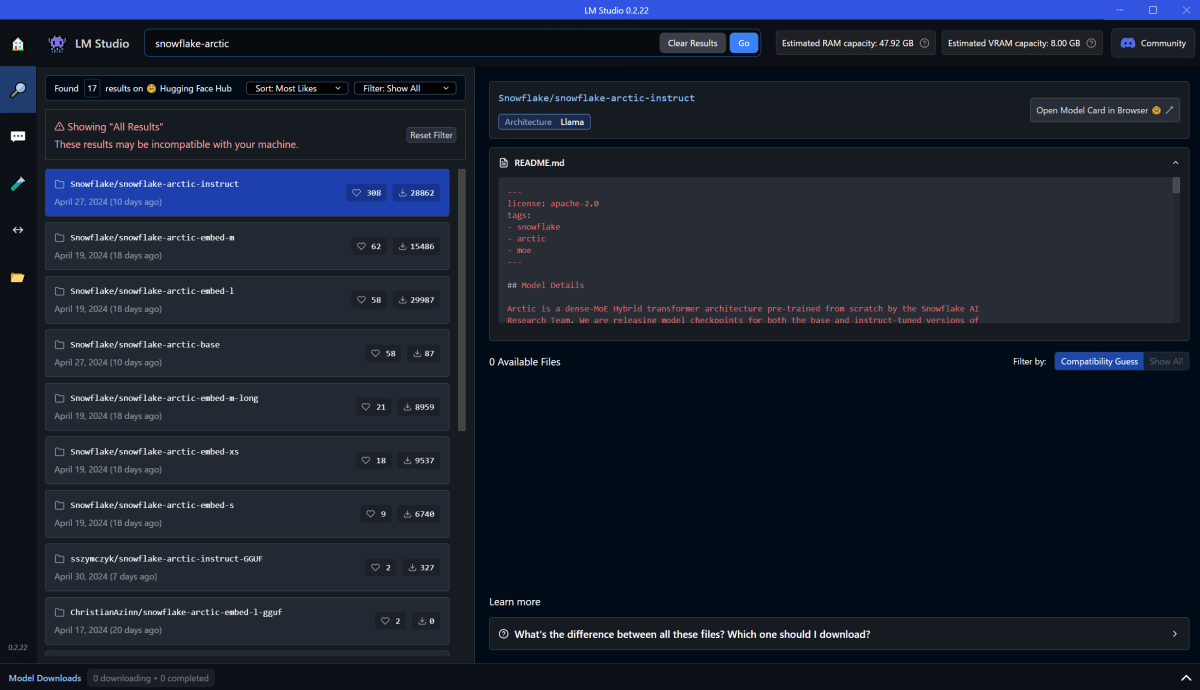
どうやら、公式提供のモデルは対応していないようす。。。[2]
じゃあ他のモデルを探そう。sszymczyk/snowflake-arctic-instruct-GGUFを使ってみる。[3]
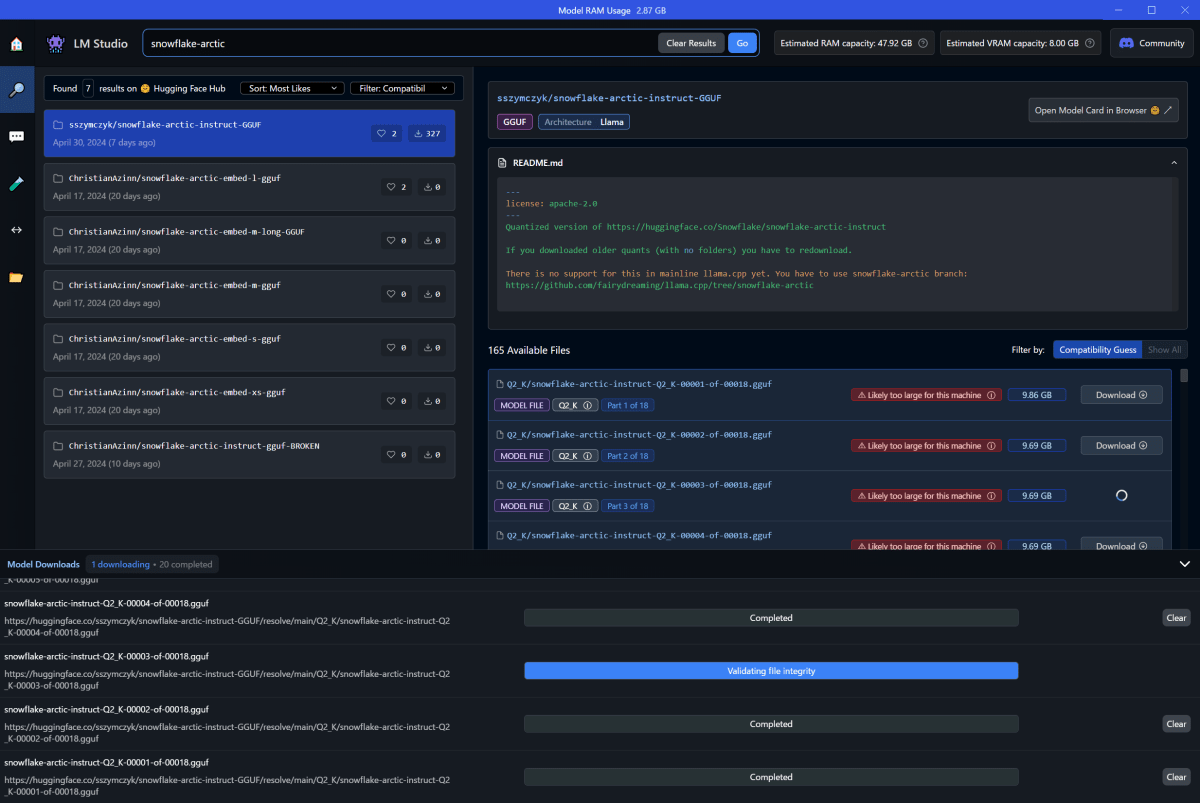
ダウンロードが完了したら、左側メニュー「💭(AI Chat)」または「↔(Local Server)」に移動して、モデルを使うことができる。
AI Chat:モデルと対話する(オフライン)
ダウンロードしたモデルを対話形式で使用できる。
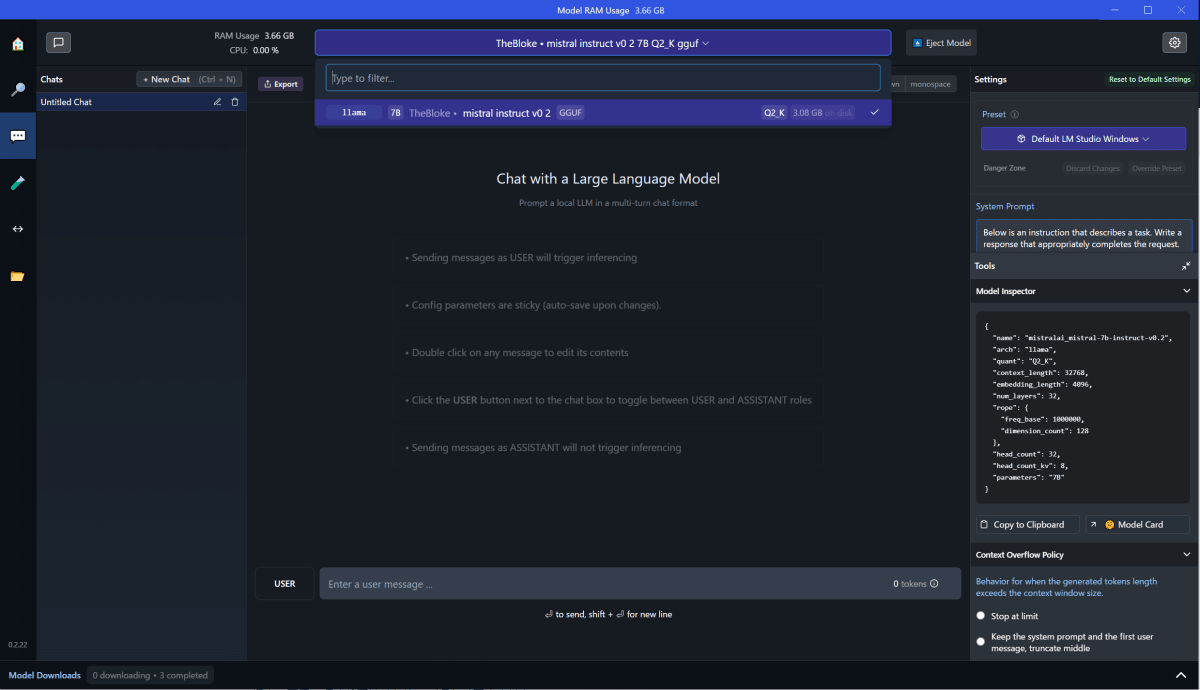
というわけで、さっそく使ってみましょうね。[5]
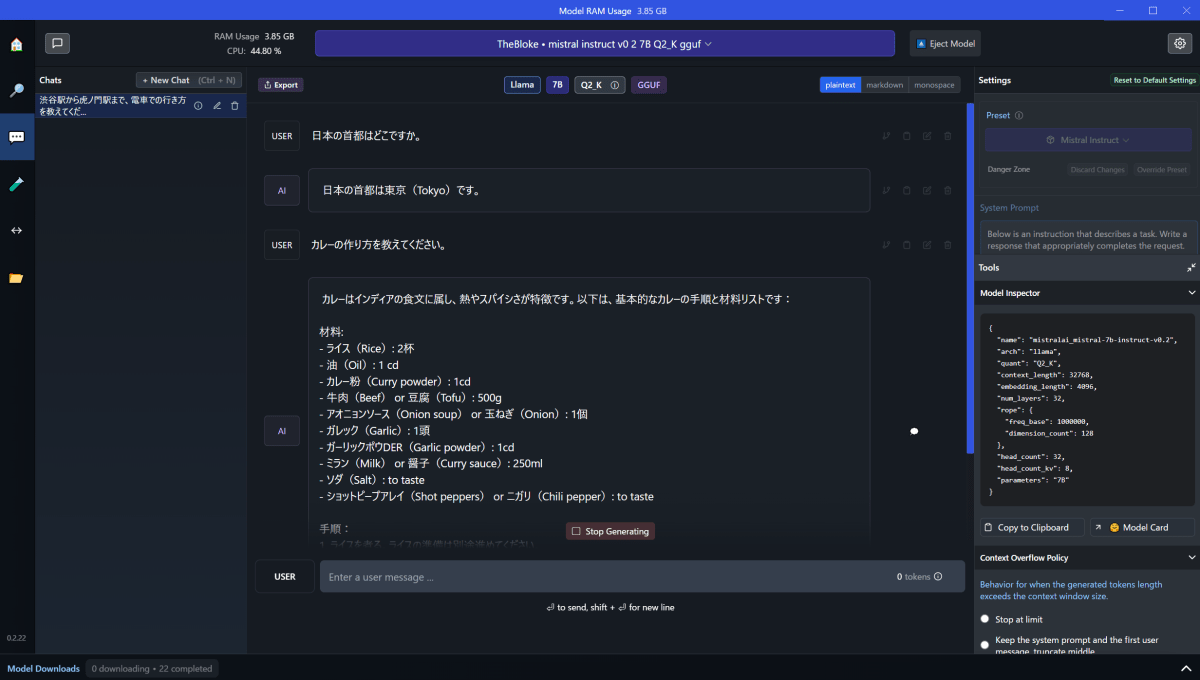
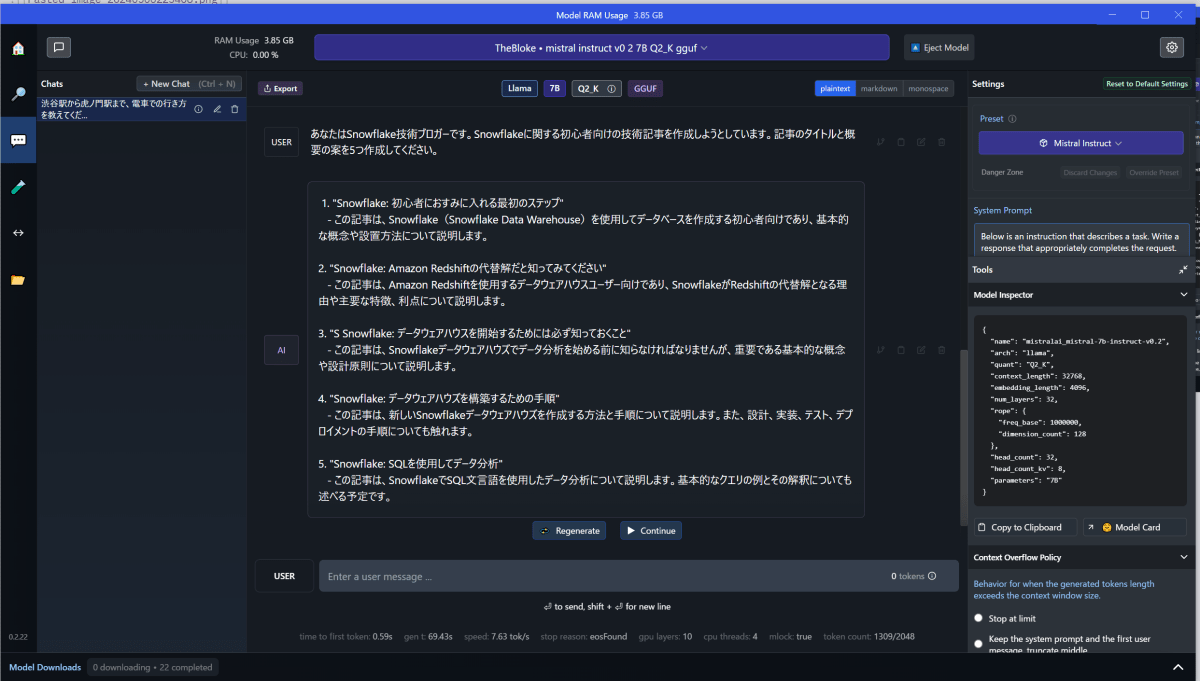
実行中は、CPUがブンブン言います。頑張ってください。
(未遂)Snowflake Arctic を使おうとした
さて、ダウンロードした sszymczyk/snowflake-arctic-instruct-GGUF を使ってみます。まずは「AI Chat」でチャレンジ。
おおっと、だめな予感...まあ「Load Model Anyway」しちゃう。

アイエエエ、だめでした。今回は諦め。。
{
"title": "Failed to load model",
"cause": "llama.cpp error: 'error loading model architecture: unknown model architecture: 'arctic''",
"errorData": {
"n_ctx": 2048,
"n_batch": 512,
"n_gpu_layers": 10
},
"data": {
"memory": {
"ram_capacity": "47.92 GB",
"ram_unused": "22.99 GB"
},
"gpu": {
"type": "NvidiaCuda",
"vram_recommended_capacity": "8.00 GB",
"vram_unused": "6.94 GB"
},
"os": {
"platform": "win32",
"version": "10.0.19045",
"supports_avx2": true
},
"app": {
"version": "0.2.22",
"downloadsDir": "D:\\LLM_MODELS"
},
"model": {}
}
}
Local Server:モデルのAPIサーバを起動
「Embedding Model Setting」で先ほどダウンロードしたモデルを選択。
選択したら「Start Server」押下で、API サーバが開始します。
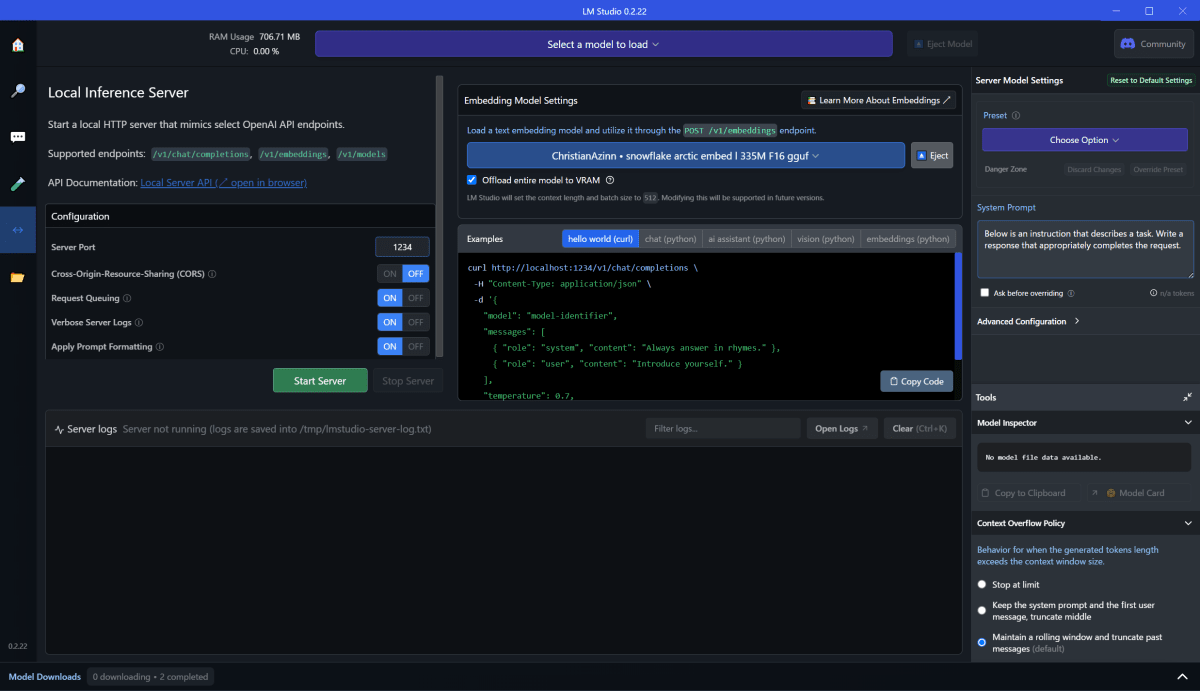
Windows なので、いつものが出ます。
起動したらしい。
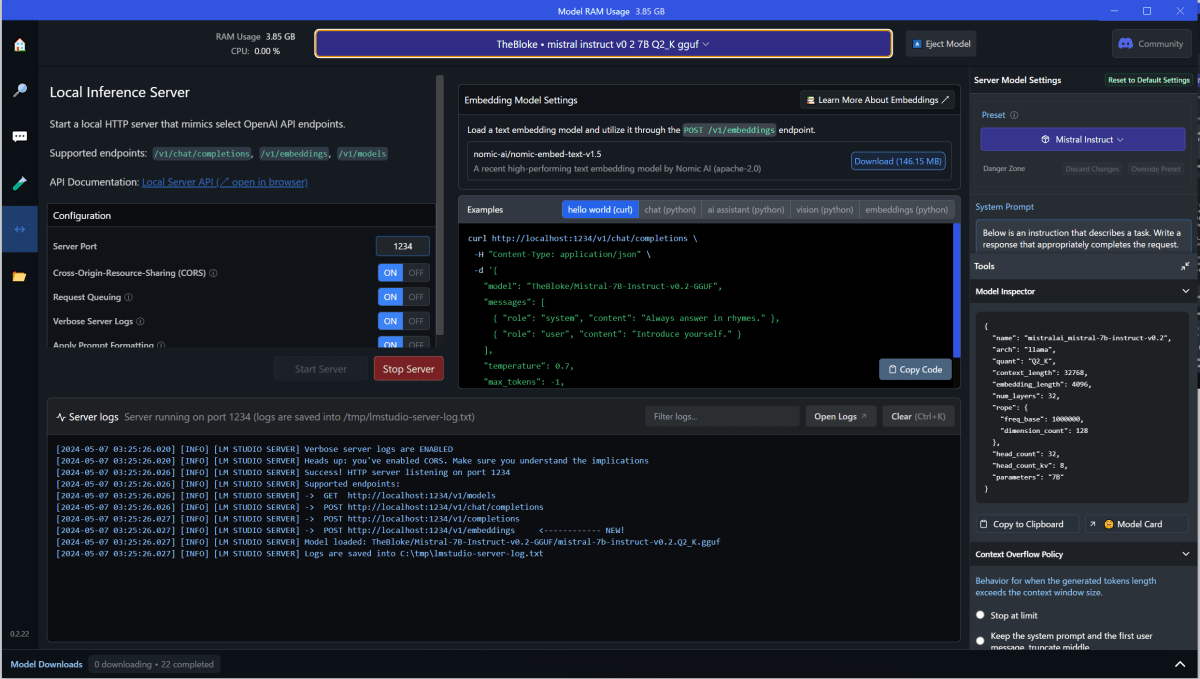
とりあえず呼んでみよう。
$ curl http://localhost:1234/v1/models
{
"data": [
{
"id": "TheBloke/Mistral-7B-Instruct-v0.2-GGUF/mistral-7b-instruct-v0.2.Q2_K.gguf",
"object": "model",
"owned_by": "organization-owner",
"permission": [
{}
]
}
],
"object": "list"
}
自己紹介してもらいましょうか。
$ curl http://localhost:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "TheBloke/Mistral-7B-Instruct-v0.2-GGUF",
"messages": [
{ "role": "system", "content": "Always answer in rhymes." },
{ "role": "user", "content": "Introduce yourself." }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}'
data: {"id":"chatcmpl-di0ntv0tbepzzqfs6htk4","object":"chat.completion.chunk","created":1715020115,"model":"TheBloke/Mistral-7B-Instruct-v0.2-GGUF/mistral-7b-instruct-v0.2.Q2_K.gguf","choices":[{"index":0,"delta":{"role":"assistant","content":" In"},"finish_reason":null}]}
data: {"id":"chatcmpl-di0ntv0tbepzzqfs6htk4","object":"chat.completion.chunk","created":1715020115,"model":"TheBloke/Mistral-7B-Instruct-v0.2-GGUF/mistral-7b-instruct-v0.2.Q2_K.gguf","choices":[{"index":0,"delta":{"role":"assistant","content":" a"},"finish_reason":null}]}
data: {"id":"chatcmpl-di0ntv0tbepzzqfs6htk4","object":"chat.completion.chunk","created":1715020115,"model":"TheBloke/Mistral-7B-Instruct-v0.2-GGUF/mistral-7b-instruct-v0.2.Q2_K.gguf","choices":[{"index":0,"delta":{"role":"assistant","content":" world"},"finish_reason":null}]}
:(中略)
data: {"id":"chatcmpl-di0ntv0tbepzzqfs6htk4","object":"chat.completion.chunk","created":1715020115,"model":"TheBloke/Mistral-7B-Instruct-v0.2-GGUF/mistral-7b-instruct-v0.2.Q2_K.gguf","choices":[{"index":0,"delta":{},"finish_reason":"stop"}]}
data: [DONE]
たぶん、韻を踏む感じで答えてくれていると思う。
Snowflake Arctic Text Embeding モデルを使ってみる

Text Embeding に特化したモデル ChristianAzinn/snowflake-arctic-embed-l-gguf を使ってみます。
モデルをダウンロードしたのち、「Embedding Model Setting」にsnowflake-arctic-embed-... と表示されているモデルを指定して、Start Serverしてみます。
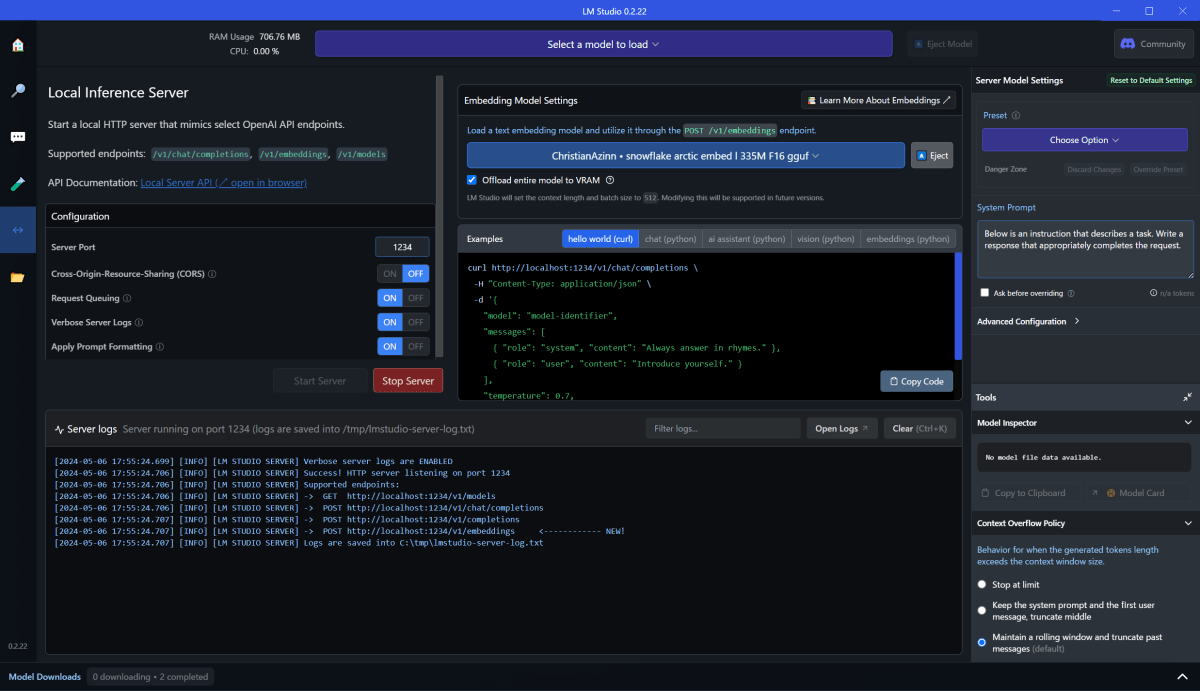
とりあえず呼ぶ。
$ curl http://localhost:1234/v1/models
{
"data": [
{
"id": "ChristianAzinn/snowflake-arctic-embed-l-gguf/snowflake-arctic-embed-l-f16.GGUF",
"object": "model",
"owned_by": "organization-owner",
"permission": [
{}
]
}
],
"object": "list"
}
Embedding ではこんな感じに動く。
$ curl http://localhost:1234/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"input": "Your text string goes here",
"model": "model-identifier-here"
}'
{
"object": "list",
"data": [
{
"object": "embedding",
"embedding": [
0.02100854553282261,
-0.06295901536941528,
-0.020170504227280617,
:(中略)
-0.015627235174179077,
-0.015828527510166168
],
"index": 0
}
],
"model": "ChristianAzinn/snowflake-arctic-embed-l-gguf/snowflake-arctic-embed-l-f16.GGUF",
"usage": {
"prompt_tokens": 0,
"total_tokens": 0
}
Multi Model
今回は使ってないのでノーコメント
My Models:モデルのダウンロードフォルダ
お好きなフォルダを指定してください。
Obsidian Copilot Chat で使ってみる
Obsidian のコミュニティプラグイン obsidian-copilot で、LM Studio で起動したモデルを使ってみます。
サーバのポート設定が 1234 のままなら、そのまま「LM STUDIO(LOCAL)」を選ぶだけで使えます。
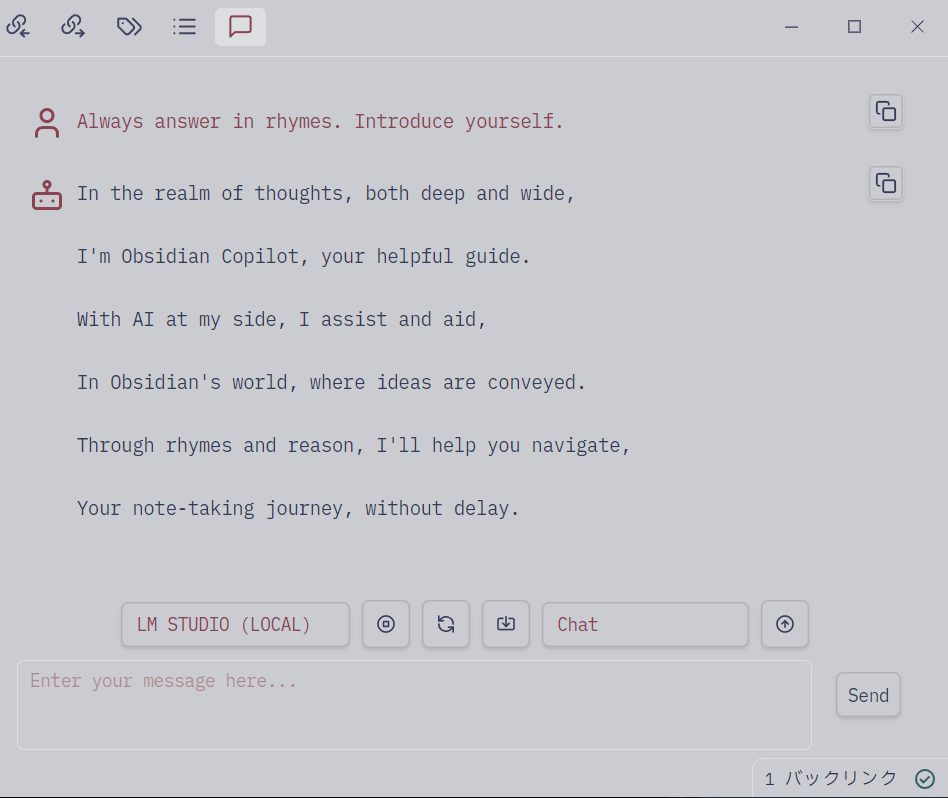
自分を説明してもらいました。


-
ストレージに余裕があり、かつllama.cpp に対応しているファイル形式でモデルが配布されていれば、という条件付き ↩︎
-
LM Studio supports any ggml Llama, MPT, and StarCoder model on Hugging Face (Llama 2, Orca, Vicuna, Nous Hermes, WizardCoder, MPT, etc.)なので。。。 llama.cpp にある convert.py で変換すればいいんだろうか? ↩︎
-
GGUFとは、モデルの読み込みと保存を高速化し、読みやすくするために設計されたバイナリフォーマットで、GGMLよりも拡張性の高いフォーマットらしいです。Hagging Faceにおける扱いはこちらを参照: https://huggingface.co/docs/hub/gguf ↩︎
-
ラベルで「このモデルはデカいから空き容量出来にきついんちゃうか」「このモデルならGPUのメモリに乗るで」的な情報がわかる。 ↩︎
-
チャットの入力欄が「Model Downloads」の下に隠れちゃうので、焦らず隠しましょう ↩︎
Discussion