asyncioで並行処理すると本当に速くなるのか、実際にベンチマークしてみた
こんにちわ alivelimb です。
FastAPI などで見える機会が増えたasyncioですが、本当に恩恵があるのかベンチマークテストしてみました。
はじめに
「そもそもasyncioって何?」という方のために簡単に紹介してみます。
詳細は公式ドキュメントまたは@JunyaFffさんのスライドが非常にわかりやすいです。
asyncio とは?
asyncio はその名の通り非同期(async) I/O の実装に活用できます。
ネットワーク通信を含む Input/Ouput の際は処理待ちが発生し CPU を持て余してしまいます。
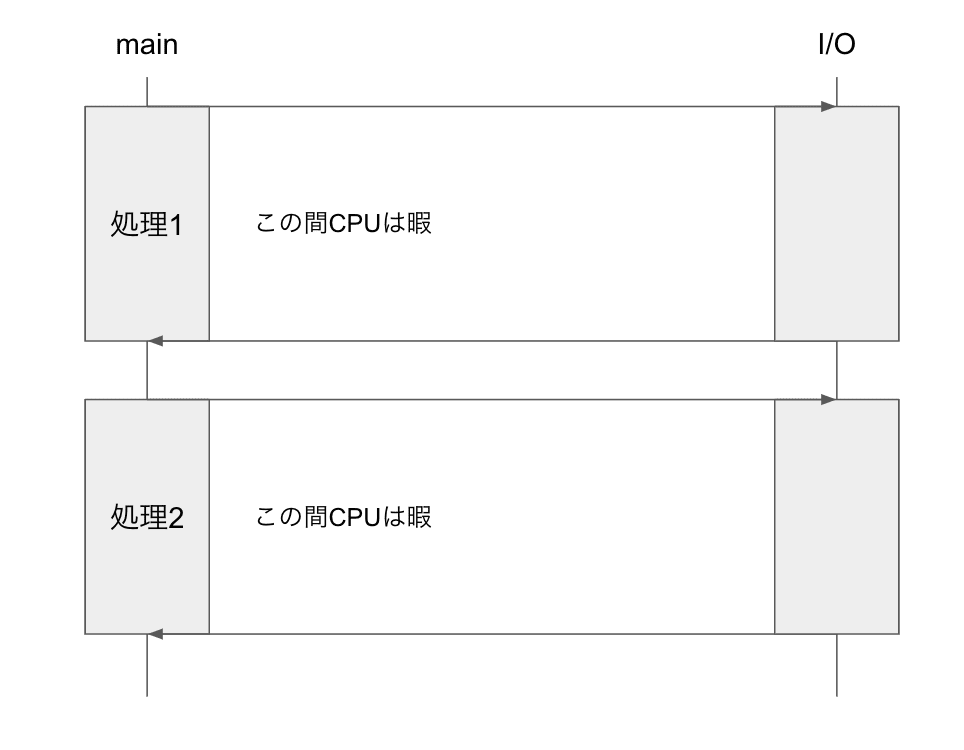
File I/O の間 CPU を別の処理に割り当てることで CPU をフル活用させることができます。

フル活用と言ってもasyncio単体では 1 スレッドの CPU 使用率が 100%ということです。
multiprocessing, joblibなどのマルチプロセスを行う処理では CPU の全ての論理コアで CPU を活用できます。
ではマルチプロセスの方が良いのか?というとそういう訳ではありません。
プログラムの処理速度が CPU 速度に大きく依存する場合(CPU bound と呼んだりします)、マルチプロセスが適しています。使える CPU がたくさんあった方が良いからですね。
逆に I/O 速度に大きく依存する場合(I/O bound と呼んだりします)、非同期 I/O が適しています。CPU がたくさんあっても、CPU が暇を持て余すだけだからですね。
また、マルチプロセスと非同期 I/O は組み合わせることもできますが、本記事ではこちらの検証は行ないません。興味のある方は英語ですが以下の記事を参照してください。
どうやって実装するの?
asyncioを用いて 3 つの sleep を並行処理してみましょう。
まずは普通に書くと以下のようになります。
import time
periods = [1, 2, 3]
for period in periods:
time.sleep(period)
1, 2, 3 秒ずつ sleep するため処理が終了するには合計 6 秒かかります。
次にasyncioを用いると以下のようになります。
import asyncio
# コルーチン関数の定義
async def async_multi_sleep(periods: list[float]) -> None:
for period in periods:
await asyncio.sleep(period)
periods = [1.0, 2.0, 3.0]
# コルーチンの実行
asyncio.run(async_multi_sleep(periods))
上記の通り、大まかの手順としては以下の通りです。
-
async defでコルーチン関数を定義する -
asyncioでコルーチンを実行する
ただし、上記を実行しても合計時間は 6 秒かかります。
コルーチンを並行処理するには Task を作成する必要があります。
import asyncio
# コルーチン関数の定義
async def async_multi_sleep(periods: list[float]) -> None:
tasks = []
# タスクの作成
for period in periods:
task = asyncio.create_task(asyncio.sleep(period))
tasks.append(task)
´# 他のタスクに順番を譲る
for task in tasks:
await task
periods = [1.0, 2.0, 3.0]
# コルーチンの実行
asyncio.run(async_multi_sleep(periods))
上記で実装した場合、3 秒で処理が終了します。
なお、上記の内容はasyncio.gatherを用いて以下のように実装することもできます。
async def async_multi_sleep(periods: list[float]) -> None:
await asyncio.gather(*[asyncio.sleep(period) for period in periods])
periods = [1.0, 2.0, 3.0]
# コルーチンの実行
asyncio.run(async_multi_sleep(periods))
benchmark
ベンチマークテストとして処理時間を計測します。
テスト対象としては以下の通りです。
| No | 内容 | 利用パッケージ |
|---|---|---|
| 1 | スリープ | asyncio.sleep |
| 2 | File I/O | aiofiles |
| 3 | Network I/O - HTTP | aiohttp |
| 4 | Network I/O - DB | aiosqlite |
また、各処理に CPU 処理を組み合わせてテストを行います。
テストツールとしては以下を利用します。
- pytest
- pytest-benchmark
- pytest-asyncio
- pytest-aiohttp
なお、pytest-benchmarkは本記事の執筆時点でasyncioに対応していません。そのためGithub の Issueを参考に以下のような fixture を作成して対応しました。
@pytest.fixture(scope="function")
def aio_benchmark(benchmark):
import asyncio
import threading
class Sync2Async:
def __init__(self, coro, *args, **kwargs):
self.coro = coro
self.args = args
self.kwargs = kwargs
self.custom_loop = None
self.thread = None
def start_background_loop(self) -> None:
asyncio.set_event_loop(self.custom_loop)
self.custom_loop.run_forever()
def __call__(self):
evloop = None
awaitable = self.coro(*self.args, **self.kwargs)
try:
evloop = asyncio.get_running_loop()
except:
pass
if evloop is None:
return asyncio.run(awaitable)
else:
if not self.custom_loop or not self.thread or not self.thread.is_alive():
self.custom_loop = asyncio.new_event_loop()
self.thread = threading.Thread(target=self.start_background_loop, daemon=True)
self.thread.start()
return asyncio.run_coroutine_threadsafe(awaitable, self.custom_loop).result()
def _wrapper(func, *args, **kwargs):
if asyncio.iscoroutinefunction(func):
benchmark(Sync2Async(func, *args, **kwargs))
else:
benchmark(func, *args, **kwargs)
return _wrapper
benchmark: sleep
まずは既に紹介したスリープについてです。
テスト対象コード
import asyncio
from time import sleep
# -----------------------------------------------------------
# 指定された時間スリープする
# -----------------------------------------------------------
def multi_sleep(periods: list[float]) -> None:
for period in periods:
sleep(period)
async def async_multi_sleep(periods: list[float]) -> None:
for period in periods:
await asyncio.sleep(period)
async def async_multi_sleep_gather(periods: list[float]) -> None:
await asyncio.gather(*[asyncio.sleep(period) for period in periods])
テストコード
import pytest
from c001_asyncio import (
async_multi_sleep,
async_multi_sleep_gather,
async_multi_sleep_gather_from_blocking,
multi_sleep,
)
SLEEP_PERIODS = [0.2, 0.2, 0.2]
# -----------------------------------------------------------
# 指定された時間スリープするテスト
# -----------------------------------------------------------
def test_multi_sleep(benchmark):
@benchmark
def _():
multi_sleep(SLEEP_PERIODS)
@pytest.mark.asyncio
async def test_async_multi_sleep(aio_benchmark):
@aio_benchmark
async def _():
await async_multi_sleep(SLEEP_PERIODS)
@pytest.mark.asyncio
async def test_async_multi_sleep_gather(aio_benchmark):
@aio_benchmark
async def _():
await async_multi_sleep_gather(SLEEP_PERIODS)
結果は以下の通りです。
---------------------------------------------------------------------------------------- benchmark: 3 tests ----------------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_async_multi_sleep_gather 201.6565 (1.0) 202.6901 (1.0) 202.3728 (1.0) 0.4125 (1.0) 202.5256 (1.0) 0.3803 (1.0) 1;0 4.9414 (1.0) 5 1
test_async_multi_sleep 603.5638 (2.99) 616.0021 (3.04) 606.5454 (3.00) 5.3204 (12.90) 604.3013 (2.98) 4.1270 (10.85) 1;1 1.6487 (0.33) 5 1
test_multi_sleep 606.8920 (3.01) 611.6967 (3.02) 608.6299 (3.01) 1.8088 (4.39) 608.0931 (3.00) 1.4615 (3.84) 1;1 1.6430 (0.33) 5 1
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Mean 列に注目すると、想定通りtest_async_multi_sleep_gatherのみ並行処理の恩恵を受けて約 200ms で終了しています。ただ、実際のプロダクトで sleep することはあまりないと思うので、別のパターンも見ていきましょう。
benchmark: aiofiles
次は File I/O です。
非同期の File I/O にはaiofilesを用います。
今回は 512MB のデータを 10 個のファイルに書き込む処理でベンチマークをしてみます。
テスト対象コード
import asyncio
from pathlib import Path
import aiofiles
# -----------------------------------------------------------
# 指定されたデータをファイルに書き込む
# -----------------------------------------------------------
def create_file_with_data(path: Path, data: bytes) -> None:
with path.open("wb") as f:
f.write(data)
async def async_create_file_with_data(path: Path, data: bytes) -> None:
async with aiofiles.open(path.as_posix(), "wb") as f:
await f.write(data)
# -----------------------------------------------------------
# 指定されたデータを指定された数だけファイルに書き込む
# -----------------------------------------------------------
def create_multi_files_with_data(paths: list[Path], data: bytes) -> None:
for path in paths:
create_file_with_data(path, data)
async def async_create_multi_files_with_data(paths: list[Path], data: bytes) -> None:
await asyncio.gather(*[async_create_file_with_data(path, data) for path in paths])
テストコード
from pathlib import Path
from tempfile import NamedTemporaryFile
import pytest
from c002_aiofiles import (
async_create_file_with_data,
async_create_multi_files_with_data,
create_file_with_data,
create_multi_files_with_data,
)
CREATE_FILE_SIZE = 2**28
CREATE_FILE_NUM = 10
@pytest.fixture(scope="function")
def named_tempfile():
fw = NamedTemporaryFile("w")
yield fw
fw.close()
@pytest.fixture(scope="function")
def named_tempfiles():
files = [NamedTemporaryFile("w") for _ in range(CREATE_FILE_NUM)]
yield files
for fw in files:
fw.close()
@pytest.fixture(scope="module")
def huge_bytes():
return b"\0" * CREATE_FILE_SIZE
# -----------------------------------------------------------
# 指定されたデータをファイルに書き込むテスト
# -----------------------------------------------------------
def test_create_file_with_data(benchmark, named_tempfile, huge_bytes):
@benchmark
def _():
create_file_with_data(Path(named_tempfile.name), huge_bytes)
@pytest.mark.asyncio
async def test_async_create_file_with_data(aio_benchmark, named_tempfile, huge_bytes):
@aio_benchmark
async def _():
await async_create_file_with_data(Path(named_tempfile.name), huge_bytes)
# -----------------------------------------------------------
# 指定されたデータを指定された数だけファイルに書き込むテスト
# -----------------------------------------------------------
def test_create_multi_files_with_data(benchmark, named_tempfiles, huge_bytes):
@benchmark
def _():
create_multi_files_with_data(
[Path(named_tempfile.name) for named_tempfile in named_tempfiles],
huge_bytes,
)
@pytest.mark.asyncio
async def test_async_create_multi_files_with_data(aio_benchmark, named_tempfiles, huge_bytes):
@aio_benchmark
async def _():
await async_create_multi_files_with_data(
[Path(named_tempfile.name) for named_tempfile in named_tempfiles],
huge_bytes,
)
結果は以下の通りです
--------------------------------------------------------------------------------------------------- benchmark: 4 tests --------------------------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_async_create_file_with_data 92.4087 (1.0) 198.6375 (1.07) 127.5377 (1.0) 37.2938 (1.10) 108.2839 (1.0) 61.2919 (1.15) 3;0 7.8408 (1.0) 11 1
test_create_file_with_data 99.5028 (1.08) 185.3546 (1.0) 150.5592 (1.18) 37.0968 (1.09) 158.6906 (1.47) 63.7308 (1.19) 1;0 6.6419 (0.85) 5 1
test_async_create_multi_files_with_data 1,171.8733 (12.68) 1,254.7769 (6.77) 1,219.3601 (9.56) 33.9193 (1.0) 1,231.4451 (11.37) 53.3607 (1.0) 2;0 0.8201 (0.10) 5 1
test_create_multi_files_with_data 1,175.0913 (12.72) 1,327.1361 (7.16) 1,242.5917 (9.74) 67.4861 (1.99) 1,232.8131 (11.39) 122.8071 (2.30) 2;0 0.8048 (0.10) 5 1
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
!?
これは想定とは異なります。
File I/O 段階では sleep と同様に待ちが発生するため、並列処理を行なった方が 10 倍近く早くなる想定でしたが結果は異なり、処理速度に大きな違いは見られませんでした。
aiofiles の Issueを見ると「処理が早くはならないかも知れないが、メインスレッドで別の処理を行えることが出来るのが利点だ」との記述があります。腑に落ちないですが、CPU 処理も組み合わせてみましょう。
組み合わせる前に、まずは CPU 処理のベンチマークをとってみましょう。
CPU 処理は以下の通り、単純な数列和(高校数学で習うシグマ)です。
1000 万までのシグマを 3 回計算します。
# -----------------------------------------------------------
# 指定された整数までの総和を計算する
# -----------------------------------------------------------
def sigma(num: int) -> int:
v = 0
for i in range(num + 1):
v += i
return v
async def async_sigma(num: int) -> int:
v = 0
for i in range(num + 1):
v += i
return v
# -----------------------------------------------------------
# 指定された各整数までの総和を計算する
# -----------------------------------------------------------
def multi_sigma(nums: list[int]) -> list[int]:
return [sigma(num) for num in nums]
async def async_multi_sigma(nums: list[int]) -> list[int]:
return await asyncio.gather(*[async_sigma(num) for num in nums])
テストコード
from c002_aiofiles import (
async_multi_sigma,
async_sigma,
multi_sigma,
sigma,
)
N_SIGMA = 10**7
V_SIGMA = 50000005000000
N_SIGMA_TIMES = 3
# -----------------------------------------------------------
# 指定された整数までの総和を計算するテスト
# -----------------------------------------------------------
def test_sigma(benchmark):
@benchmark
def _():
assert sigma(N_SIGMA) == V_SIGMA
@pytest.mark.asyncio
async def test_async_sigma(aio_benchmark):
@aio_benchmark
async def _():
assert await async_sigma(N_SIGMA) == V_SIGMA
# -----------------------------------------------------------
# 指定された各整数までの総和を計算するテスト
# -----------------------------------------------------------
def test_multi_sigma(benchmark):
@benchmark
def _():
result = multi_sigma([N_SIGMA for _ in range(N_SIGMA_TIMES)])
assert result == [V_SIGMA for _ in range(N_SIGMA_TIMES)]
@pytest.mark.asyncio
async def test_async_multi_sigma(aio_benchmark):
@aio_benchmark
async def _():
result = await async_multi_sigma([N_SIGMA for _ in range(N_SIGMA_TIMES)])
assert result == [V_SIGMA for _ in range(N_SIGMA_TIMES)]
結果は以下の通りです。
------------------------------------------------------------------------------------------ benchmark: 4 tests -----------------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_async_sigma 480.9756 (1.0) 499.0507 (1.0) 492.1004 (1.0) 6.7240 (1.0) 493.6568 (1.0) 6.3340 (1.0) 2;0 2.0321 (1.0) 5 1
test_sigma 500.9957 (1.04) 519.9479 (1.04) 511.1150 (1.04) 7.5248 (1.12) 512.2812 (1.04) 11.8297 (1.87) 2;0 1.9565 (0.96) 5 1
test_async_multi_sigma 1,466.5203 (3.05) 1,494.5071 (2.99) 1,479.8562 (3.01) 10.9483 (1.63) 1,481.6104 (3.00) 16.4346 (2.59) 2;0 0.6757 (0.33) 5 1
test_multi_sigma 1,492.3126 (3.10) 1,547.9187 (3.10) 1,523.0065 (3.09) 27.9279 (4.15) 1,534.3684 (3.11) 53.7643 (8.49) 2;0 0.6566 (0.32) 5 1
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
並列処理によって処理速度に違いはありませんが、こちらは想定通りです。今回の処理は CPU bound なため、CPU に待ちが発生せず並列処理の恩恵を受けられません。では I/O 処理と組み合わせるとどうでしょうか?
テスト対象コード
# -----------------------------------------------------------
# File I/O と CPUタスクを行う(データ指定)
# -----------------------------------------------------------
def mix_io_cpu_with_data(paths: list[Path], data: bytes, nums: list[int]) -> list[int]:
create_multi_files_with_data(paths, data)
return multi_sigma(nums)
async def async_mix_io_cpu_with_data(paths: list[Path], data: bytes, nums: list[int]) -> list[int]:
result = await asyncio.gather(
async_create_multi_files_with_data(paths, data),
async_multi_sigma(nums),
)
return result[1]
テストコード
from c002_aiofiles import (
async_mix_io_cpu_with_data,
mix_io_cpu_with_data,
)
# -----------------------------------------------------------
# File I/O と CPUタスクを行うテスト(データ指定)
# -----------------------------------------------------------
def test_mix_io_cpu_with_data(benchmark, named_tempfiles, huge_bytes):
@benchmark
def _():
result = mix_io_cpu_with_data(
[Path(named_tempfile.name) for named_tempfile in named_tempfiles],
huge_bytes,
[N_SIGMA for _ in range(N_SIGMA_TIMES)],
)
assert result == [V_SIGMA for _ in range(N_SIGMA_TIMES)]
@pytest.mark.asyncio
async def test_async_mix_io_cpu_with_data(aio_benchmark, named_tempfiles, huge_bytes):
@aio_benchmark
async def _():
result = await async_mix_io_cpu_with_data(
[Path(named_tempfile.name) for named_tempfile in named_tempfiles],
huge_bytes,
[N_SIGMA for _ in range(N_SIGMA_TIMES)],
)
assert result == [V_SIGMA for _ in range(N_SIGMA_TIMES)]
結果は以下の通りです。
------------------------------------------------------------------------------------- benchmark: 2 tests -------------------------------------------------------------------------------------
Name (time in s) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_async_mix_io_cpu_with_data 2.4868 (1.0) 2.6220 (1.0) 2.5505 (1.0) 0.0528 (1.0) 2.5410 (1.0) 0.0798 (1.0) 2;0 0.3921 (1.0) 5 1
test_mix_io_cpu_with_data 2.6234 (1.05) 2.9007 (1.11) 2.8053 (1.10) 0.1114 (2.11) 2.8472 (1.12) 0.1423 (1.78) 1;0 0.3565 (0.91) 5 1
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
asyncio を使った方が、やや早くなっていますが劇的な変化は見られませんでした。。。
私自身、腑に落ちる理由が分かっていないので、心当たりのある方はコメントで教えていただけると幸いです。
benchmark: aiohttp
次にaiohttpを用いたネットワーク I/O (HTTP)のベンチマークを行ってみましょう。まずアクセスされたら指定の時間だけスリープする API を作成します。
def create_app() -> web.Application:
async def handle(request: Any) -> web.Response:
period = float(request.rel_url.query["period"])
await asyncio.sleep(period)
return web.Response()
app = web.Application()
app.add_routes([web.get("/sleep", handle)])
return app
if __name__ == "__main__":
app = create_app()
web.run_app(app)
これとは別プロセスで HTTP リクエストを行います。
# -----------------------------------------------------------
# /sleepリソースに停止時間を指定してHTTPリクエストを行う
# -----------------------------------------------------------
def sleep_request(url: str, period: float) -> int:
with urllib.request.urlopen(f"{url}/sleep?period={period}") as response:
return response.status
async def async_sleep_request(url: str, period: float) -> int:
async with aiohttp.ClientSession() as session:
async with session.get(f"{url}/sleep?period={period}") as response:
return response.status
# -----------------------------------------------------------
# /sleepリソースに停止時間を指定した数だけHTTPリクエストを行う
# -----------------------------------------------------------
def multi_sleep_requests(url: str, periods: list[float]) -> list[int]:
return [sleep_request(url, period) for period in periods]
async def async_multi_sleep_requests(url: str, periods: list[float]) -> list[int]:
return await asyncio.gather(*[async_sleep_request(url, period) for period in periods])
これまでのようにベンチマークを実施してみましょう。
SERVER_URL = "http://0.0.0.0:8080"
def test_sleep_request(benchmark):
@benchmark
def _():
status = sleep_request(SERVER_URL, 0.2)
assert status == 200
@pytest.mark.asyncio
async def test_async_sleep_request(aio_benchmark):
@aio_benchmark
async def _():
status = await async_sleep_request(SERVER_URL, 0.2)
assert status == 200
def test_multi_sleep_requests(benchmark):
@benchmark
def _():
status = multi_sleep_requests(SERVER_URL, [0.2, 0.2, 0.2])
assert status == [200, 200, 200]
@pytest.mark.asyncio
async def test_async_multi_sleep_requests(aio_benchmark):
@aio_benchmark
async def _():
status = await async_multi_sleep_requests(SERVER_URL, [0.2, 0.2, 0.2])
assert status == [200, 200, 200]
結果は以下の通りです。
----------------------------------------------------------------------------------------- benchmark: 4 tests -----------------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_sleep_request 202.4012 (1.0) 203.9504 (1.0) 203.4526 (1.0) 0.6106 (1.38) 203.6606 (1.0) 0.5861 (1.0) 1;0 4.9151 (1.0) 5 1
test_async_sleep_request 205.5099 (1.02) 207.0953 (1.02) 206.3653 (1.01) 0.7193 (1.63) 206.6543 (1.01) 1.2889 (2.20) 2;0 4.8458 (0.99) 5 1
test_async_multi_sleep_requests 208.4528 (1.03) 209.4410 (1.03) 208.8828 (1.03) 0.4413 (1.0) 208.6549 (1.02) 0.7507 (1.28) 1;0 4.7874 (0.97) 5 1
test_multi_sleep_requests 609.3281 (3.01) 623.3630 (3.06) 613.3552 (3.01) 5.7904 (13.12) 610.7264 (3.00) 5.9304 (10.12) 1;0 1.6304 (0.33) 5 1
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
こちらは想定通りの動きをしています。HTTP リクエストをしている間に並行処理が走っているため、200ms x 3 = 600msではなく、1 回分の 200ms で処理が終わっています。
ではクライアント側で重めの CPU 処理を回している場合はどうでしょうか。
N_SIGMA = 10**5
V_SIGMA = 5000050000
N_SIGMA_TIMES = 3
# -----------------------------------------------------------
# Network I/O と CPUタスクを行う
# -----------------------------------------------------------
def mix_network_io_cpu(url: str, periods: list[float], nums: list[int]) -> list[int]:
multi_sleep_requests(url, periods)
return multi_sigma(nums)
async def async_mix_network_io_cpu(url: str, periods: list[float], nums: list[int]) -> list[int]:
result = await asyncio.gather(
async_multi_sleep_requests(url, periods),
async_multi_sigma(nums),
)
return result[1]
こちらもベンチマークを回してみましょう。
# -----------------------------------------------------------
# Network I/O と CPUタスクを行うテスト(サイズ指定)
# -----------------------------------------------------------
def test_mix_network_io_cpu(benchmark):
@benchmark
def _():
result = mix_network_io_cpu(
SERVER_URL,
[1, 1, 1],
[N_SIGMA for _ in range(N_SIGMA_TIMES)],
)
assert result == [V_SIGMA for _ in range(N_SIGMA_TIMES)]
@pytest.mark.asyncio
async def test_async_mix_network_io_cpu(aio_benchmark):
@aio_benchmark
async def _():
result = await async_mix_network_io_cpu(
SERVER_URL,
[1, 1, 1],
[N_SIGMA for _ in range(N_SIGMA_TIMES)],
)
assert result == [V_SIGMA for _ in range(N_SIGMA_TIMES)]
結果は以下の通りです。
------------------------------------------------------------------------------------ benchmark: 2 tests ------------------------------------------------------------------------------------
Name (time in s) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_async_mix_network_io_cpu 1.0208 (1.0) 1.0343 (1.0) 1.0253 (1.0) 0.0053 (1.0) 1.0243 (1.0) 0.0053 (1.0) 1;0 0.9753 (1.0) 5 1
test_mix_network_io_cpu 3.0221 (2.96) 3.0393 (2.94) 3.0311 (2.96) 0.0072 (1.37) 3.0341 (2.96) 0.0119 (2.23) 2;0 0.3299 (0.34) 5 1
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
こちらも想定通り、並行処理の効果が効いていますね。
aiohttp を用いた Network I/O では、並行処理の恩恵で実際に処理が早くなることが確認できました。
ちなみに aiohttp ではaiohttp_clientという fixture を利用することが出来るため、本来であれば別プロセスでアプリを起動せず、pytest のみで完結するはずです。しかし以下の実装で試すとRuntimeError: Task got Future attached to a different loop.というエラーが出たため、今回は別プロセスでアプリを起動する方法で迂回しました。
# ※エラーが発生するコード
@pytest.mark.asyncio
async def test_sleep_request(aiohttp_client, aio_benchmark):
@aio_benchmark
async def _():
app_client = await aiohttp_client(create_app())
period = 1
response = await app_client.get(f"/sleep?period={period}")
assert response.status == 200
benchmark: aiosqlite
最後は aiosqlite を用いた DB 接続です。
これまで通り、まずはスリープから検証していきましょう。
DB にはスリープ関数がないため、自作関数を作成してスリープを実装します
# -----------------------------------------------------------
# DBにアクセスして指定した時間だけスリープする
# -----------------------------------------------------------
def sleep_db_request(period: float) -> None:
with sqlite3.connect(":memory:") as db:
db.create_function("sleep", 1, time.sleep)
cur = db.cursor()
cur.execute(f"SELECT sleep({period})")
async def async_sleep_db_request(period: float) -> None:
async with aiosqlite.connect(":memory:") as db:
await db.create_function("sleep", 1, time.sleep)
cur = await db.cursor()
await cur.execute(f"SELECT sleep({period})")
# -----------------------------------------------------------
# DBにアクセスして指定した時間の数だけスリープする
# -----------------------------------------------------------
def multi_sleep_db_requests(periods: list[float]) -> None:
for period in periods:
sleep_db_request(period)
async def async_multi_sleep_db_requests(periods: list[float]) -> None:
await asyncio.gather(*[async_sleep_db_request(period) for period in periods])
テストケースも今まで通りです
def test_sleep_db_request(benchmark):
@benchmark
def _():
sleep_db_request(0.2)
@pytest.mark.asyncio
async def test_async_sleep_db_request(aio_benchmark):
@aio_benchmark
async def _():
await async_sleep_db_request(0.2)
def test_multi_sleep_requests(benchmark):
@benchmark
def _():
multi_sleep_db_requests([0.2, 0.2, 0.2])
@pytest.mark.asyncio
async def test_async_multi_sleep_requests(aio_benchmark):
@aio_benchmark
async def _():
await async_multi_sleep_db_requests([0.2, 0.2, 0.2])
結果は以下の通りです。
----------------------------------------------------------------------------------------- benchmark: 4 tests -----------------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_sleep_db_request 201.3555 (1.0) 205.2846 (1.0) 203.7979 (1.0) 1.8179 (1.73) 204.9371 (1.0) 3.0303 (1.87) 1;0 4.9068 (1.0) 5 1
test_async_sleep_db_request 204.7722 (1.02) 207.3065 (1.01) 206.2676 (1.01) 1.0537 (1.0) 206.7830 (1.01) 1.6162 (1.0) 1;0 4.8481 (0.99) 5 1
test_async_multi_sleep_requests 209.6312 (1.04) 214.5691 (1.05) 211.9721 (1.04) 1.8173 (1.72) 212.0738 (1.03) 2.2477 (1.39) 2;0 4.7176 (0.96) 5 1
test_multi_sleep_requests 607.1996 (3.02) 611.5772 (2.98) 609.8215 (2.99) 2.2275 (2.11) 611.2378 (2.98) 4.0439 (2.50) 2;0 1.6398 (0.33) 5 1
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
こちらも aiohttp の時と同様、並列処理の恩恵を受けていますね。
念の為クライアント側で重めの CPU 処理を追加して検証します。
# -----------------------------------------------------------
# DB Network I/O と CPUタスクを行う
# -----------------------------------------------------------
def mix_db_io_cpu(periods: list[float], nums: list[int]) -> list[int]:
multi_sleep_db_requests(periods)
return multi_sigma(nums)
async def async_mix_db_io_cpu(periods: list[float], nums: list[int]) -> list[int]:
result = await asyncio.gather(
async_multi_sleep_db_requests(periods),
async_multi_sigma(nums),
)
return result[1]
テストコードもほとんど変更はありません
# -----------------------------------------------------------
# DB Network I/O と CPUタスクを行うテスト(サイズ指定)
# -----------------------------------------------------------
def test_mix_db_io_cpu(benchmark):
@benchmark
def _():
result = mix_db_io_cpu(
[1, 1, 1],
[N_SIGMA for _ in range(N_SIGMA_TIMES)],
)
assert result == [V_SIGMA for _ in range(N_SIGMA_TIMES)]
@pytest.mark.asyncio
async def test_async_mix_db_io_cpu(aio_benchmark):
@aio_benchmark
async def _():
result = await async_mix_db_io_cpu(
[1, 1, 1],
[N_SIGMA for _ in range(N_SIGMA_TIMES)],
)
assert result == [V_SIGMA for _ in range(N_SIGMA_TIMES)]
結果は以下の通りです。
---------------------------------------------------------------------------------- benchmark: 2 tests ---------------------------------------------------------------------------------
Name (time in s) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_async_mix_db_io_cpu 1.0220 (1.0) 1.0400 (1.0) 1.0344 (1.0) 0.0072 (1.0) 1.0371 (1.0) 0.0076 (1.0) 1;0 0.9668 (1.0) 5 1
test_mix_db_io_cpu 3.0259 (2.96) 3.0451 (2.93) 3.0336 (2.93) 0.0081 (1.13) 3.0320 (2.92) 0.0135 (1.78) 1;0 0.3296 (0.34) 5 1
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
やはり想定通り、aiosqlite でも並列処理の恩恵を受けることを確認できました。
まとめ
今回は 「asyncio で並列処理をすることで本当に処理が早くなるか」をベンチマークテストで確認しました。aiofiles のみ処理が速くなることは確認できませんでしたが、aiohttp, aiosqlite では並列処理の恩恵を受けることが確認できました。
FastAPI をはじめとする ASGI 対応の Web フレームワークでの DB 接続やネットワーク I/O では積極的に asyncio、コルーチンを使っていくことで処理の高速化が図れそうです。
aiofiles を用いたベンチマークで結果が想定通りにならなかった件については、そもそも aiofiles では処理が速くならないのか、それとも実装に問題があるのか、もしわかる方がいればコメント頂けると幸いです。
Discussion
Python と asyncio を使ったのが数年前なので間違っていたらすみません。
今回のケースでは ThreadPoolExecutor の最大ワーカースレッド数に引っかかているのでないでしょうか?
issue の記述とソースをざっと読んだ感じでは aiofiles の
write()はrun_in_executor()をデフォルトのエクゼキューターで使っていると思われます。write()はブロッキング処理になるので、これを多用するとスレッドプールを消費してしまうはずです。ちょっと趣旨は違いますが下記の記事が参考になるかと思います。
一方で
run_in_executor()には下記のような記述があります。さらに ThreadPoolExecutor の方を見ると、おそらく最新の Python では下記がデフォルトになっていると思われます。
これは、Codespace(CPU 4 コア) で確認すると下記のように最大ワーカースレッド数が 8 ということになります。
もしも測定されている環境での最大ワーカースレッド数に余裕がなさそうでしたら、I/O の並行数をら減らしてみるのはいかがでしょうか?
コメント頂きありがとうございます!
(Pythonのthreadに関する理解が足りておらず、共有いただいた資料などを読ませて頂いていた都合で回答が遅れてしまいました...)
まず私の環境での最大ワーカスレッド数は以下で確認した通り12となります
こちらの「最大ワーカスレッド数に余裕がないか」の検証方法が分からず検証出来ていないのですが、「I/O の並行数を減らしてみる」という部分は以下の記事を参考にSemaphoreを用いて検証してみました。
limit数は12以外にも4, 8でも検証しましたが、結果としては速度は改善せずでした。。。
「hankei6kmさんが想定していた検証方法ではないかも...?」とも思っているので、お時間ある際に再びコメント頂けると幸いです。
ご返答ありがとうございます。
こちらの書き方が曖昧だったばかりにお手間をとらせてしまってすみません。
想定していた通りですが、もう少し単純に「CREATE_FILE_NUM を最大ワーカースレッド数 -3 くらいにしてみたらいかかでしょうか」という意味で書いていました。
(-3 はとくに意味があるわけではなく、メインスレッドの他に pytest が何かスレッドを生成している可能性を考慮しての値です)
今回は予想だけで書いてしまうのも申し訳ないので実際に環境を作って試してみました。
前述の Codespace(最大ワーカースレッド数 8)の環境で
CREATE_FILE_NUM = 5にしてみましたがこちらでも違いは出ませんでした。pytest -k 'multi'で実行しています。I/O 性能の頭打ちかと思い、iotop で様子を眺めていたのですが、同期と非同期どちらも似たような感じになります。
同期処理時
非同期処理時(write にあわせてスレッドが増えています)
スクリーンショットだと非同期の方が良い値ですが、どちらも Current は 200 M/s を前後しています。
それならばと、ためしに書き出すファイルを異なるボリュームに分散させてみましたが、同期と非同期ともに速くなってしまったのでこちらも違いはでませんでした。
(これ以降も
CREATE_FILE_NUM = 5で試しています)偶数のときは
/tmp、奇数のときは/home/vscode/tmpに書き込みます。もっと性能良くないとダメかなということで、続いて tmpfs(メモリー上に作られるファイルシステムと思ってください)をマウントし試してみるとようやく違いがでました。
全部のファイルを tmpfs へ書き込みます。
5 倍まではいきませんが、速くはなったと言える値かと思います。
この状態だと最大ワーカースレッド数を変更すると若干ですが速度に影響がありました。
そのようなわけで当初の「最大ワーカースレッド数に引っかかっているのでは?」はあまり正しくありませんでした。
まとめると以下のようになるかと思います。
高速な同時アクセス性能が良いファイルシステムを使うと速度が向上しスレッド数が影響してくるただし、I/O 性能が原因という決定的な証拠も見つからなかったというのが正直なところです(「I/O 時にはスレッドのロックが開放されるので速くなるけど、やっぱりファイルの操作は遅いよ」という記述が見つかる程度です)。最終的に何がネックなっているのか(Python のスレッド制御なのか、I/O性能なのかなど)はイマイチはっきりしていないのが申し訳ないのですが、試した範囲でわかったことをまとめてみました。下記のコメントに追記しましたが、今回の環境では I/O 性能(同時アクセスの性能)がネックで並行化しても思ったように速くならなかったと考えられます。
小出しになってしまってすみません、追記です。
本当に I/O が頭打ちだったのか気になったので
ddコマンドを使って簡単に試してみました。実行環境は上記のベンチマークを動かした Codespace を使っています。
まず、各ファイルへ順次書き出す処理です。
(
/tmp/test?.tmpへ\0を 2**28 バイト書き出しています)新規でファイル作成すると 900MB/s くらいはでます(後半、なぜ遅くなっているかは不明です)
上書き(削除 & 作成)すると 200MB/s 前後になります。
続いて並行化した場合です。
こちらも最初の 1 回は速くなりますが、5 で割ったような値になります。
上書き(削除 & 作成)すると 200MB/s を 5 で割ったよりかは少し良い値ですが、全体の経過時間では 6.3 秒なのでベンチマークとあまり違いはありません。
以上のように asyncio のベンチマークのときと比べて大きな違いはないようでした。
このことから、開発マシンの
/tmpなどに書き出した場合は asyncio に限らずファイル書き出しの並行化のメリットはあまり受けられないことになるかと思われます。一方で tmpfs の場合は並行化してもパフォーマンスは 5 で割った値にまでは落ち込みませんでした。
順次書き出した場合。
並行して書き出した場合
これは速度的な性能というよりも、ファイルシステムの構成上(メモリー上に作成されるので)「同時アクセスの性能が良い」という感じかと思われます。
よって、asycio などによる並行処理でファイル処理を並行化した場合、このような同時アクセスで性能が落ちないストレージならばある程度の速度向上が見込めると考えられます。
(例、冗長化されたディスクなど)
様々な検証を試して頂きありがとうございます!
読ませて頂いていて「なるほど、こうやって検証する方法があるのか」と非常に勉強になりました。
なるほど、asyncio, aiofilesの問題というよりはファイルシステム側の問題の可能性が高そうですね。記事本文内でも紹介したaiofilesのIssueでは「処理が早くはならないかも知れないが、メインスレッドで別の処理を行えることが出来るのが利点だ」という記述があり、「処理は早くならないの...?なぜ?」という疑問があったのですが、腑に落ちる原因がありそうでスッキリしました。
私も漠然と「ファイル I/O も並行化すればある程度は速くなるだろう」と考えていたので、実際に手を動かして検証できたのは良い体験でした。
ありがとうございました。
ベンチマーク取ってませんが、CPU Boundの
async_sigma関数は内部で待ち状態が発生しないので無意味な比較になっていると思います。内部で待たないのでasyncio.gatherしても別のtaskへの移動は発生せず逐次実行になります。例えば、
async_sigma関数の中にprint関数を追加してgatherしても次のような逐次実行になります。並行(concurrent)処理になるように中で待たせる簡単な方法としては、
await asyncio.sleep(0)をforの中で呼ぶと一時待ち状態になり別のtaskに移動して並行処理になります。これで速くなるかは不明ですが、並行処理として比較するなら必要かと思います。ややこしいんですがgatherだけでは並行にも並列(parallel)にもならないようです。
また、上のコメントで速くなっていたのはシングルスレッドの並行処理でなくマルチスレッド(ThreadPool)による並列(parallel)処理になっているからだと思われます。一方でCPU Boundの処理はProcessPoolに入れると速くなるのでおそらく実感できるはずです。(下記のドキュメント参照)
この
awaitable loop.run_in_executor(executor, func, *args)はおそらく低水準APIに設計されているようなのですがもう少し雑に使える高水準APIとしてcoroutine asyncio.to_thread(func, /, *args, **kwargs)があります。おそらく我々がgatherに求めてるのはこいつで、与えた 関数(コルーチンじゃダメ) がスレッドになり、gatherにまとめて渡すと並列(parallel)実行になります。これでも速度の実感ができるはずです。(
loop.run_in_executor(executor, func, *args)のThreadPoolを使った場合とどういう差があるのかまでは自分もよくわかってませんが)