こんにちは、アルダグラムでSREを担当している okenak です。
今回は、2024年末に実施した KANNA の AWS インフラ基盤の全面リプレースについてご紹介します。
このプロジェクトは、昨年下期に実施した大規模な基盤移行であり、構成の見直しから段階的な切り替え、本番移行に至るまで、多くの検討と労力が求められました。
本記事では、移行に至った背景、当時直面していた課題、具体的な取り組み内容、そして移行を通じて得られた学びについてまとめています。どこか一部でもご参考になれば幸いです。
▶️ KANNAのサービス紹介ページはこちら
🏗️ なぜ今、インフラ基盤のリプレースが必要だったのか?
急速に成長を続けるSaaSサービスに対し、初期に構築したインフラでは、柔軟性・拡張性・運用効率の面で徐々に限界が見え始めていました。
さらに、弊社自身もグロース期に差し掛かり、将来的なスケーラビリティと信頼性を見据えた基盤への移行が、避けては通れない課題となっていました。
課題① ネットワークアドレスの枯渇
旧インフラでは、各サブネットが /27 で設計されており、AWSによる予約分を除くと、実際に利用可能なIPアドレスは1サブネットあたり最大27個に限られていました。ローンチ当初はこの規模でも十分に対応できていましたが、サービスの拡大とともにIPアドレスの枯渇が、現実的な制約として顕在化してきました。
既存のCIDRブロックを段階的に拡張する案も検討しましたが、既存構成との整合性や、将来的なスケール戦略との整合を考慮すると、継ぎ足すような対応ではかえって運用負荷や技術的負債が増すリスクがあると判断しました。
そのため、ネットワーク設計そのものを抜本的に見直すことを選択しました。
課題② インフラ構成の断片化と技術的負債
継続的な運用と機能追加を重ねる中で、インフラ構成は部分的に更新・拡張され続けてきました。
その結果、全体としての整合性や一貫性が徐々に損なわれ、構成全体が複雑化している状態にありました。
具体的には、リソース命名規則の不統一、インスタンスタイプのばらつき、非推奨設定の残存、不要となった機能の放置などが見られ、可読性・保守性の低下を招いていました。
こうした問題は開発基盤にも波及し、リソースが断片的に増加した結果、コスト最適化の観点からも見直しが必要な状況となっていました。
課題③ CloudFormationの運用限界と生産性の低下
旧基盤では、構成管理に AWS CloudFormation を採用していました。マネージドなIaCツールとして信頼性は高く、多くのユースケースで安定して機能していた一方で、運用規模の拡大に伴い、次第に運用上の限界が顕在化していきました。
たとえば、スタック更新時の依存関係の制御やテンプレート構造の複雑化により、可読性や保守性の低下、自動化の柔軟性が不足するといった課題が表面化してきました。
また、複数環境にまたがるリソースを扱う際には、テンプレートの再利用や環境差分の管理が困難で、構成の一貫性を維持するための運用負荷も増加していました。
さらに、CloudFormationではドリフト検出が非対応の項目が存在し、コードと実環境との乖離が発生し得ることも、運用上のリスクとして無視できませんでした。
テンプレートはYAMLベースで記述できる一方で、プログラマブルな柔軟性に乏しく、開発者体験としても改善の余地があると感じていました。
基盤が抱えていた複雑さとその背景
こうした課題が生まれた背景には、SREチームが発足する以前の運用体制も大きく関係しています。
スタートアップ立ち上げ当初は、エンジニアの人数も限られており、明確にインフラを担う体制は整っていませんでした。そのため、インフラ構築や運用は、業務委託の方や、専任でない社員が兼務で対応していたという経緯があります。
現在では、当時の担当者はすでに在籍しておらず、設計意図の継承が難しい構成が一部残っていたことも、保守性や可視性の課題につながっていました。
こうした背景を踏まえ、SREチームの発足以降は、将来的な拡張や保守のしやすさを見据えた再設計を進める必要があると判断し、今回のリプレースに至りました。
🎯 今回の移行で目指したゴール
今回のプロジェクトは、単なるリソースのリプレースではなく、以下の3つの観点から、事業の成長と今後の運用に耐えうる基盤の再構築を目的として進めました。
- スケーラビリティの確保:IP枯渇やVPC構成の制約を解消し、将来的な拡張に対応できる構成へ
- 技術的負債の解消:設計・命名・リソース配置のばらつきを是正し、標準化された構成へ移行
- 保守性・運用性の向上:ツール選定や構成管理を見直し、効率的かつ安全に運用できる体制を整備
🛠️ 実施した主な内容
1. VPCおよびサブネット構成の再設計
将来的なスケールに備え、VPCおよびサブネットのCIDR設計を見直しました。
IP枯渇が起きないよう十分なレンジを確保するとともに、環境間でアドレスが重複しないよう配慮しています。
2. 開発環境ごとに分かれていたVPCの統合と共有リソース化
旧基盤では開発環境を増やすたびに個別のVPCやRDSが必要となり、コストが増大していました。
新基盤では開発環境を1つのVPCに統合し、RDSやALBなどの共通リソースを集約。
具体的には、RDSは1ホストに複数DBを相乗りさせ、ALBはホストベースルーティングによりECSサービスごとに分離せず構成を一本化しています。
3. 各種リソースの最新化および設定の見直し
bastionやECSタスクのインスタンスタイプを最新化し、ElastiCache(Redis)も新バージョンへ移行。
セキュリティ・性能・コストのバランスを見直し、持続可能な構成へ最適化しました。
4. IAM設計の再構築
IAMポリシーやロールを用途別に整理し、最小権限の原則に基づいてリソースごとに個別設定が可能な構成に再設計。これにより、セキュリティ制御の粒度と管理性の両立を実現しました。
5. 命名規則およびタグ設計の標準化
従来は一部でプロジェクトコード名などが使われており、識別が困難なケースもありました。
これを明確な命名ルールに統一し、タグ設計も標準化することで、可読性・トレーサビリティ・自動化対応を強化しました。
6. 不要・非推奨リソースの廃止
過去の暫定対応や構成変更の名残で残っていた不要なリソースや、意図が不明な設定を精査。
現行の運用実態に即した、シンプルで保守しやすい構成へ整理しました。
7. 複数環境への展開を前提としたモジュール設計
Terragruntを活用し、環境単位の分離と共通化を両立できる構成を設計。
将来的にリージョン展開や環境追加が必要になった際にも、拡張・展開しやすいモジュール構成を意識しています。
8. Terraform & Terragruntの導入
旧構成で使用していた CloudFormation から脱却し、Terraform ベースでの構成管理へ移行。
Terragrunt により環境ごとの差分管理を抽象化しつつ、コードの再利用性と構成の一貫性を向上させました。
もともと一部環境で Terraform の運用実績があったことから、全面的な移行も無理なく実施可能でした。新基盤では新規リソースの作成を基本としつつ、S3 バケットなどは import により取り込み、RDS はスナップショットからの復元によって安全に移行を行いました。
Terragrunt を使った構成設計や詳細については、以下の記事で詳しく解説しています
作業ボリュームとロードマップ感
今回の基盤移行は、Terraform による構成をすべてゼロから作り直す必要があり、約半年をかけて段階的に進めました。スコープの広さに加え、既存サービスへの影響を最小限に抑えるため、各工程を慎重に設計・実行しています。
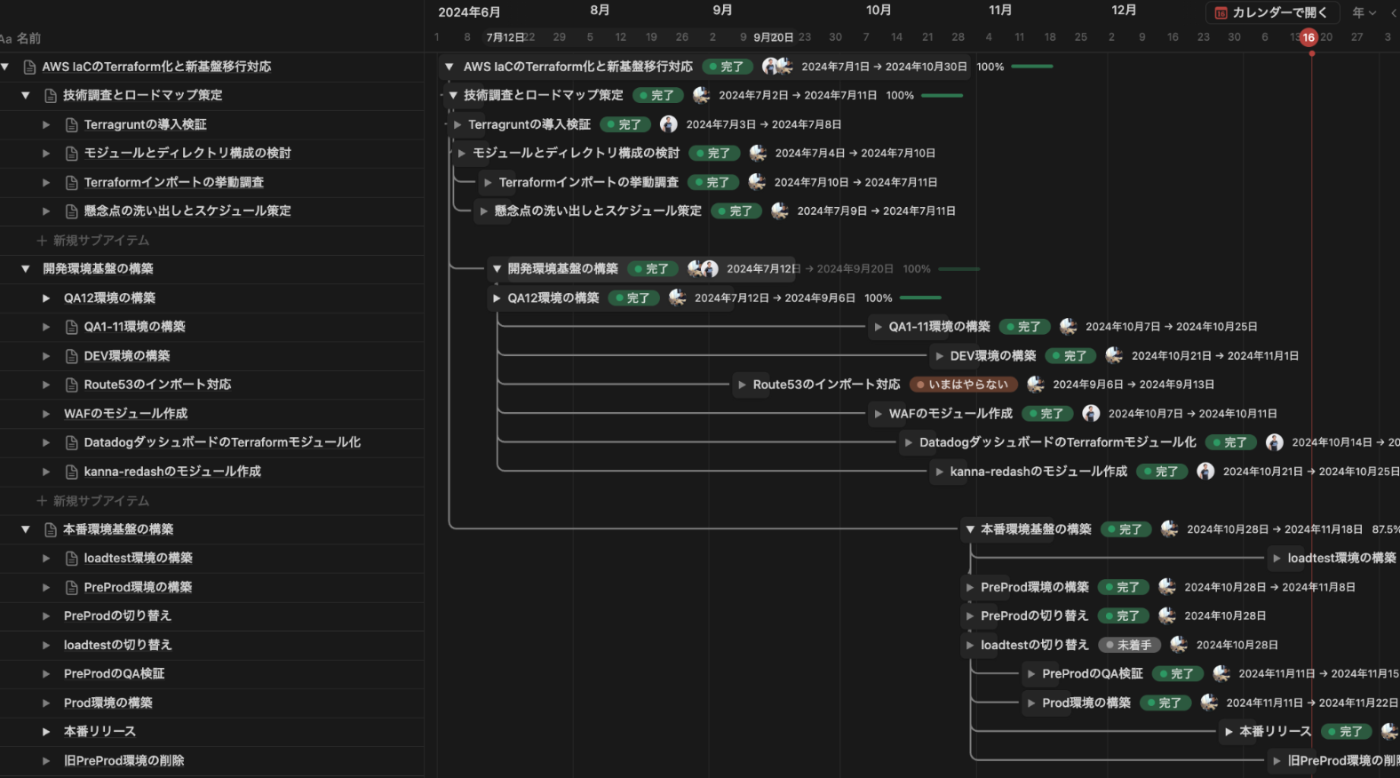
本移行では、既存基盤と新基盤を並行で構築し、段階的にリソースを切り替える方式を採用しました。Terraform によるゼロベースの構成定義を新たに作成しつつ、RDS や S3 などは import やスナップショット復元を用いて段階的に移行しました。
本番移行時には、旧基盤と新基盤を一時的に並列稼働させ、Route53 の DNS 切り替えによって最終的なトラフィック移行を実施。万が一のトラブルにも迅速に対応できるよう、即時切り戻しが可能な状態で本番切替を行うことで、安全かつ確実に新構成への完全移行を完了しました。
🔍 リスク管理とメンテナンス調整における取り組み
インフラ基盤の全面移行は、その性質上、技術的な実装のみならず、事業への影響を最小限に抑えるためのリスク管理とスケジュール調整が極めて重要でした。特に、サービスを一時停止する必要があることから、関係各所と連携し、入念な準備を進めました。
リスクの洗い出しと対策検討
移行に伴う潜在的なリスクを事前に洗い出し、関係者と連携しながら技術的・運用的な対策を検討・整理しました。特に各部署のリーダーにはユーザー視点での影響確認を依頼し、レビュー体制を強化することで、見落としを最小限に抑える工夫を行いました。
手順書整備とリハーサルの実施
メンテナンス当日の作業ミスを防ぐため、手順書を整備し、複数回の事前リハーサルを実施。重大な問題が発生した際には移行を中止し、迅速にロールバックできる体制を構築しました。
事業サイドとの調整
メンテナンス作業の実施日時については、業務影響を最小化するため、事業部門の責任者と連携して調整を行いました。また、深夜作業中のQA対応に備え、開発メンバーからも有志を募り、必要な体制を確保しました。
ユーザーへの事前周知
セールスチームおよびカスタマーサクセスチームを通じて、計画停止に関する情報をユーザーへ事前に案内。信頼性への不安を最小限に留めるよう配慮しました。
これらの取り組みにより、技術・運用・事業それぞれの視点から万全の体制を整え、移行当日を安全かつ円滑に乗り越えることができました。
年末の深夜メンテナンスのタイムライン
当日は以下のような流れで作業を行なっていましたが、大きなトラブルはなく、メンテナンス作業を予定より1時間早く完了し、トラブルなく基盤切替に成功しました。

🌟 得られた学び
今回の基盤移行プロジェクトを通じて、以下のような実践的な学びを得ることができました。
事前準備は「やりすぎ」くらいがちょうどいい
リスクの洗い出し、手順書の整備、複数回にわたるリハーサルの実施、そして入念なQAによって、本番当日はトラブルなく移行を完了することができました。予測可能なリスクは準備によってすべて潰し込む、という姿勢の重要性を再認識しました。
特に今回のような基盤移行に失敗した場合、サービス停止やデータ整合性の問題が事業全体に直結するリスクがあり、“多少の手戻り“では済まない可能性があります。そのため、コストや時間が多少かかっても、事前準備は「やりすぎ」と感じるくらいでようやく適切な水準だと改めて実感しました。
スケジュールの余白が品質を支えた
当初は「なるはや」でのリリースを目標としており、自分の中でも“早く出すことこそ正義”という意識が強く、時間をかけすぎるとSREとして仕事をこなせていないのでは──という疑念すらありました。
しかし、事業サイドや開発部長と相談する中で、周知や説明期間の確保、ユーザー影響の最小化といった現実的な観点を踏まえ、スケジュールに余白を持たせる判断がなされました。結果として、十分な検証・準備期間を確保することができ、リスクを抑えた安定的な移行につながりました。
振り返ってみると、これは単なる“慎重な判断”というより、関係者との合意形成によって実現した“現実的かつ効果的な進め方”だったと感じています。スケジュールに余白を持たせることで、結果的に移行の品質も大きく向上しました。
SREだけでは無理だった全社連携の重要性
今回の移行は、SREチーム単独で完遂できるようなものではありませんでした。技術的な対応だけでなく、お客様へのご案内・影響の整理・問い合わせ対応など、表には見えにくい裏方的な役割を多くのメンバーが担ってくれたことが、移行成功の大きな要因でした。
事業・開発・QA・カスタマーサクセス・セールスといった多方面のチームが、基盤移行の重要性を理解し、それぞれの各部署からの協力をいただけたことにより、ユーザーとのトラブルもなくスムーズなリリースを実現することができました。
大規模な基盤移行では、SREの技術的な努力だけでなく、組織全体で“移行を成功させる”という共通意識を持つことが何より重要であると、改めて実感しました。
🌱 おわりに
インフラはユーザーからは見えにくい存在ですが、サービスの信頼性・成長性を支える極めて重要な土台です。今回のリプレースは、技術的負債の解消にとどまらず、KANNAがさらに進化するための 見えない競争力 を整える一歩となりました。
今後もこうした改善を積み重ね、プロダクトの価値を支える基盤をより強固にしていきたいと考えています。

株式会社アルダグラムのTech Blogです。 世界中のノンデスクワーク業界における現場の生産性アップを実現する現場DXサービス「KANNA」を開発しています。 採用情報はこちら: herp.careers/v1/aldagram0508/
Discussion