こんにちは!アルダグラムのKANNAの開発お手伝いをさせて頂いているoubakiouです。
本記事は株式会社アルダグラム Advent Calendar 2023 6日目の記事です。
この記事を読めば以下のTypeScript(JavaScript)のテストコードがなぜこけるのかが分かったような気持ちになります。また最後に「細かい理屈はいいからいけてる感じに動くlengthやtruncateがほしい!」という方向けの付録もついています。
it('surrogate pair', () => {
// 2
expect('😊'.length).toEqual(1)
})
it('variation selectors', () => {
// 4
expect('👍🏿'.length).toEqual(1)
})
it('combining character', () => {
// 2
expect('パ'.length).toEqual(1)
})
it('ZWJ', () => {
// 8
expect('👨👩👦'.length).toEqual(1)
})
it('region indicator character', () => {
// 8
expect('🇦🇿🇿🇦'.length).toEqual(2)
})
it('emoji tag sequences', () => {
// 14
expect('🏴'.length).toEqual(1)
})
それではいってみましょう。
サロゲートペア(Surrogate pair)
it('surrogate pair', () => {
// 2
expect('😊'.length).toEqual(1)
})
JavaScript処理系で内部的に使われているUTF-16では全ての文字が2バイトまたは4バイトのどちらかで表現されていますが、絵文字などは2バイトではなく4バイトを使って表現されている事がありこれをサロゲートペアと呼びます。漢字であれば例えば𩸽(ホッケ)なんかもサロゲートペアです。
JavaScriptにおけるStringのlengthプロパティは内部でのコード単位(2バイト単位)を数えるメソッドのため4バイト文字を2つと数えてしまい、こういった場合には意図したlengthになりません。またlengthだけではなくsubstringのようなメソッドもこれは同様で、内部コード単位で1文字分を切り出してしまうのでサロゲートペアが真ん中でカチ割られた孤立サロゲートになってしまいます
"😊".substring(0, 1)
"😊".substring(0, 1).isWellFormed()

ですが最近のJavaScriptではスプレッド演算子を使うと文字列を内部コード単位ではなくサロゲートペアを考慮したCode Point単位での文字に分割できるため、その結果の配列を数えたり操作したりする事で意図した結果になります。めでたしめでたし。
[...'😊'].length

異体字セレクタ(Variation Selectors)
it('variation selectors', () => {
// 4
expect('👍🏿'.length).toEqual(1)
})
全ての文字が2バイトまたは4バイトのどちらかで表現されていると言ったがあれは嘘です。

元となる文字に続けて異体字セレクタと呼ばれる文字を並べた場合は元文字の派生文字をレンダリングするという仕組みがあります。例えばワタナベの"邊󠄆"シリーズや、東京都葛飾区と奈良県葛城市の"葛"などもそうです。
文字とは、1文字とは何なのか。意味上最小単位の1文字、表示上の1文字。grapheme clusterとは。
結合文字(Combining character)
it('combining character', () => {
// 2
expect('パ'.length).toEqual(1)
})
こういうパターンもあります。パとパは違うのです。「全部同じじゃないですか!?」「これだからしろうとはダメだ!もっとよく見ろ!」

基底文字+結合文字で構成されているパに対して、よく使われている一体化したパは合成済み文字と呼ばれます。
ゼロ幅接合子(Zero-width joiner)
it('ZWJ', () => {
// 8
expect('👨👩👦'.length).toEqual(1)
})
合成されているのが2文字とは限りません。そして3文字を合成してそうな絵文字だから内部コード単位で2*3の6になるんじゃ?と思われるかもしれませんが8が返ってきます。

文字の接合にゼロ幅接合子(ZWJ)が使われている場合、Code Pointを数えた場合にはその分も加算されます。余談ですが文字の接合ができるという事は
'👨👩👦'.replace('👨', '')
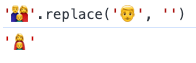
こういう事もできます。
国旗絵文字(Regional indicator symbol)
it('region indicator character', () => {
// 8
expect('🇦🇿🇿🇦'.length).toEqual(2)
})
2桁で表現される国コードというものがあって例えばアゼルバイジャンはAZ、南アフリカはZAです。これに対して🇦という文字と🇿という文字を2つ続けて書くと🇦🇿という風に国旗をレンダリングする(Windowsなど一部環境では対応していないけど)というのが国旗絵文字です。🇦、🇿、🇿、🇦と続けて書いた場合には国旗が2つ、2文字と見做された方が都合の良い事が多いでしょう。

ところで奇数個の場合にはどう表示されるのが正しいのでしょうか。試しにVSCodeなどで🇦🇿🇿🇦の前に🇦を一つ追加してみましょう。
地域旗絵文字(emoji tag sequences)
it('emoji tag sequences', () => {
// 14
expect('🏴'.length).toEqual(1)
})
国旗絵文字と似たような発想で🏴(WAVING BLACK FLAG)の後ろにメタ文字でg、b、e、n、g、終端記号(CANCEL TAG)のように並べると地域旗絵文字を表示する仕組み(Windowsなど一部環境では対応していないけど)があります。

1文字のように見えますが内部コード単位では圧巻の14。お前の前にいるのは28バイトの絵文字だ。
どうでしょうか。だんだん文字コードの事がわかった気持ちになってきたでしょうか?私は全然わかりません。
いけてる感じに動くlengthやtruncateがほしい!
最近のJavaScriptではIntl.Segmenterというものがあります。これを使うとCode Point基準よりも割といけてる感じ(個人差、要件差があります)に文字列を分割する事ができます。
export const toGraphemes = (str: string, locales = undefined) => {
const segmenter = new Intl.Segmenter(locales, { granularity: 'grapheme' })
const segItr = segmenter.segment(str)
return Array.from(segItr, ({ segment }) => segment)
}
export const length = (str: string) => {
const graphemes = toGraphemes(str)
return graphemes.length
}
export const truncate = (str: string, size: number, suffix = '...') => {
const graphemes = toGraphemes(str)
return `${graphemes.slice(0, size).join('')}${
graphemes.length > size ? suffix : ''
}`
}
このlengthを冒頭のテストにかけると以下のようになります
it('surrogate pair', () => {
// 1
expect(length('😊')).toEqual(1)
})
it('variation selectors', () => {
// 1
expect(length('👍🏿')).toEqual(1)
})
it('combining character', () => {
// 1
expect(length('パ')).toEqual(1)
})
it('ZWJ', () => {
// 1
expect(length('👨👩👦')).toEqual(1)
})
it('region indicator character', () => {
// 2
expect(length('🇦🇿🇿🇦')).toEqual(2)
})
it('emoji tag sequences', () => {
// 1
expect(length('🏴')).toEqual(1)
})
ところでIntl.Segmenter、Nodeの場合はv16以降で使う事ができますがブラウザの場合のPolyfillについてはどうなんでしょう。めちゃめちゃ複雑そうな事をしてそうなので実装とかバンドルサイズとか色々と難しそうな気はしますが識者の情報求む。
どこまで対応するべきなのか
影響が大きく対応も容易なサロゲートペアの考慮はさておき、異体字セレクタ他にも本当に対応する必要があるのかどうかは用途によると思います。異体字セレクタ等は絵文字を使わなければ影響がないというものでもありません(例えばワタナベの"邊󠄆"シリーズとか)が、場合によっては対応しないという選択も十分にありえると思います。ちなみにzodのmaxはこういう実装になっています。
it('a', () => {
// true
expect(z.string().max(1).safeParse('a').success).toEqual(true)
})
it('あ', () => {
// true
expect(z.string().max(1).safeParse('あ').success).toEqual(true)
})
it('surrogate pair', () => {
// false
expect(z.string().max(1).safeParse('😊').success).toEqual(true)
})
it('variation selectors', () => {
// false
expect(z.string().max(1).safeParse('👍🏿').success).toEqual(true)
})
it('combining character', () => {
// false
expect(z.string().max(1).safeParse('パ').success).toEqual(true)
})
it('ZWJ', () => {
// false
expect(z.string().max(1).safeParse('👨👩👦').success).toEqual(true)
})
it('region indicator character', () => {
// false
expect(z.string().max(2).safeParse('🇦🇿🇿🇦').success).toEqual(true)
})
it('emoji tag sequences', () => {
// false
expect(z.string().max(1).safeParse('🏴').success).toEqual(true)
})
しかし対応しないという選択をする場合であっても、何に対応できていないのかをある程度説明できると嬉しいこともあるんじゃないでしょうか。
なおIntl.Segmenter(のgrapheme分割)が万能かというと、作ろうと思えば無限長の書記素クラスタ(1文字)が作れるのでバリデーションの目的によっては不適切になる可能性もあります。そういうあからさまな攻撃をアプリケーションのレイヤで防ごうとする事が適切なのか、そのシステムのその経路で本当にDoSが成立しうるのか、といった議論もまたありえます。
references
- String - JavaScript | MDN
- JavaScript における文字コードと「文字数」の数え方 | blog.jxck.io
- Regional Indicator (国旗絵文字)
- みんな🙋大好き💖絵文字の㊙️ヒミツ🕵️♀️|快技庵 高橋政明
- Unicode IVS/IVDについて | 一般社団法人 文字情報技術促進協議会
もっとアルダグラムエンジニア組織を知りたい人、ぜひ下記の情報をチェックしてみてください!

株式会社アルダグラムのTech Blogです。 世界中のノンデスクワーク業界における現場の生産性アップを実現する現場DXサービス「KANNA」を開発しています。 採用情報はこちら: herp.careers/v1/aldagram0508/
Discussion