こんにちは!アルダグラムでエンジニアをしているokenakです。
今回は、弊社サービスのKANNAにおける表示速度の低下という問題を解決するために、本番相当のデータ量を用いた負荷検証環境(loadtest環境)を構築した取り組みについてお話ししたいと思います。
なお、loadtest環境の構築自体はTerraformを使用してAWSリソースの作成を行ったため、本記事では主に本番相当のデータを自動同期する仕組みについて解説していきます。
本番に近い環境での検証の必要性
KANNAを利用している企業の中には、大量のデータを保持しているところがあります。そのような企業では、一部機能でデータ表示に時間がかかるという課題が発生していました。私たちは現状のパフォーマンス改善策として、単純にデータ量を増やした検証は行っていましたが、実際のデータ構造を再現することが難しく、効果的な負荷検証ができていませんでした。
そこで、本番データに近い形で検証できるloadtest環境の構築に着手することにしました。
最適なデータ再現方法の選定
loadtest環境で本番と同等のデータ構造を再現するために、以下の2つのアプローチを検討しました。
- Railsのseed機能を使って大量のテストデータを生成する
- 本番環境のデータをクローンしマスク処理を施して大量データを用意する
検討の結果、seedを使用する方法では、実際のデータ量やデータの関連性を再現するために複雑なコードが必要となり、さらに企業ごとに異なるデータパターンを再現しようとすると、準備に非常に手間がかかることがわかりました。
一方、本番データをクローンする方法では、実際のデータをそのまま再現できるため、効果測定が容易になります。特にAWSのAuroraを利用すればデータの複製が簡単に行えるため、こちらの方法を採用することにしました。
AWS Step Functionsで自動同期のフローを実現
AWS SAMとAWS Step Functionsを活用して、本番相当のデータを自動的に同期する仕組みを構築しました。この仕組みにより、検証後のデータリセットや最新データの準備を手動で行う必要がなくなり、本番環境と同じ条件で負荷テストを効率的に行えるようになりました。
AWS Step Functionsを選定した理由
クラスター作成やデータ移行には時間がかかるため、Lambdaのタイムアウト制限(最大15分)が厄介でした。そこで、長時間の処理が可能で、複数ステップのエラーハンドリングや再試行を柔軟に行えるAWS Step Functionsを組み合わせる事にしました。AWS Step Functionsはタイムアウトを気にすることなく長時間のプロセスを管理できるため、大規模なデータ移行や複雑なワークフローの実行に適しています。
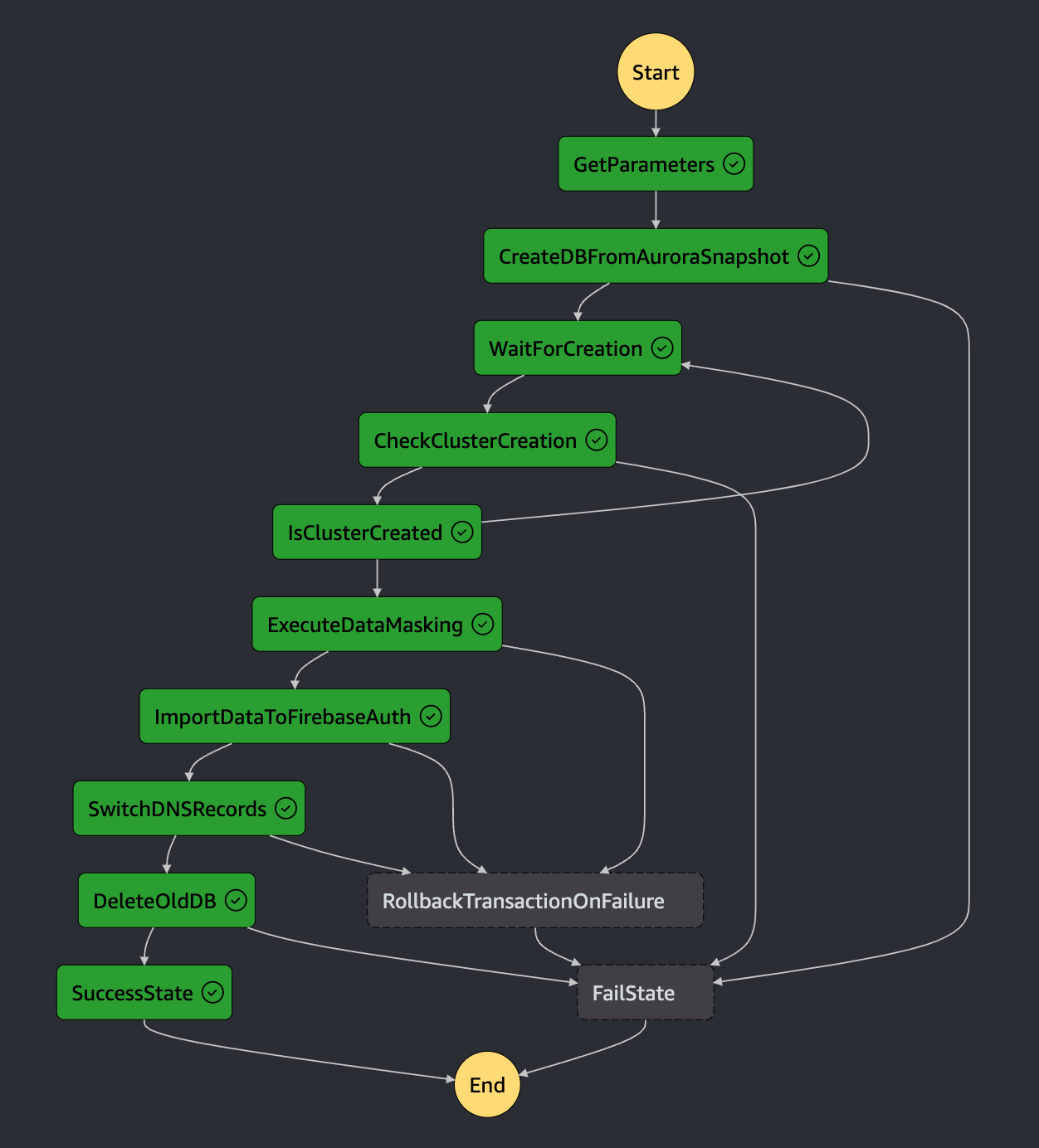
ワークフローの流れ
※ 各ステップの実行では、GolangとAWS SDKを利用したLambda関数を使用しています
-
Auroraクラスターの作成
前日の本番環境のSnapshotを使用して、loadtest環境用のAuroraクラスターを作成します。これにより、最新のデータを含むテスト用データベースを用意します。
-
個人情報のマスク処理
Auroraクラスター内のデータに対して、SQLを使用して個人情報のマスク処理を実行します。
-
FirebaseAuthデータの同期
ユーザーの認証・認可情報を管理するFirebaseAuthのデータを、本番環境からエクスポートし、loadtest環境にインポートします。エクスポートの過程でマスク処理を行い、メールアドレスやパスワード情報はユーザが設定した内容とは異なるものに変更します。
-
DBのCNAMEレコードの切り替え
loadtest環境のアプリケーションが最新のデータを使用するように、DBエンドポイントとして登録しているCNAMEのレコードを新しいクラスターに切り替えます。
-
旧Auroraクラスターの削除
新しいクラスターが正常に稼働していることを確認した後、不要になった旧loadtest環境のAuroraクラスターを削除します。
実際のステートマシンのフローは以下の通りとなります。
EventBridgeを用いた定期的な自動実行
データ同期ワークフローをEventBridgeと連携させ、週1の間隔で自動実行されるように設定しました。これにより手動での実行は不要となり、常に最新のデータを用いた負荷テストが利用できる状態になりました。また、手動での実行も可能なため必要に応じてデータのリセットと同期が行えるようになっています。
取り組みの成果
loadtest環境を構築したことで、以下のような様々な改善効果が得られました。
- 大量データ準備作業の自動化で検証工数が大幅に削減された
- これまで手動で行っていたテストデータの準備作業が自動化されたことで、開発メンバーは本来の開発タスクに集中できるようになりました。
- 本番環境への影響を気にせずに各種検証が行えるようになった
- バッチ処理やDB設計変更の影響調査など、本番相当のデータでないと再現が困難だった問題の検証作業がloadtest環境上で簡単に実行できるようになりました。
- 企業・ユーザー固有の不具合データを使った調査が容易になった
- 不具合の原因となったデータもloadtest環境に同期されるため、問題の再現性を高め、原因特定と修正を迅速に進められるようになりました。
- パフォーマンス改善の精度が向上した
- 本番さながらのデータ量とアクセスパターンに基づいて性能改善策の効果を検証できるようになったため、改善の質が格段に向上しました。
- 開発メンバーがloadtest環境を活発に利用するようになった
- 実際のサービス環境に近い状態でのテストが日常的に行われるようになったため、潜在的な問題を早期に発見し、迅速に対応できるようになりました。
このようにloadtest環境の構築は開発チームの生産性を大きく向上させ、サービスのクオリティアップに貢献しています。今後もこの環境をフル活用しながら、継続的な改善を進めていきたいと考えています。
今後の課題ついて
loadtest環境の運用には、まだいくつかの課題が残されています。以下に関しては限定的なものですが、今後の改善策を検討していきたいと考えています。
-
データ同期ワークフローの実行時間
ワークフローの完了に45分前後の時間がかかっていますが、週1回深夜に自動同期する設定にしているため、現在のところ問題になっていません。
-
マスク対象項目の増加による保守運用
機能改修によりマスク対象項目が増えた場合、保守運用の工数が発生します。ただし、個人情報などを含む項目の追加頻度は高くないため、現時点では大きな負担にはなっていません。
-
ストレージデータの同期未対応
S3などのストレージサービスに保存されている画像や資料等のバイナリデータについては、マスクが難しいため、現在はloadtest環境への同期を行っていません。
まとめ
loadtest環境を構築したことで、本番環境と同等の負荷を再現し、効率的なパフォーマンス検証が可能になりました。これにより、KANNAのサービス品質の向上に大きく寄与できたと考えています。今後もこの環境を活用し、さらなる改善を行い、ユーザーの期待に応え続けていきたいと思います。
もっとアルダグラムエンジニア組織を知りたい人、ぜひ下記の情報をチェックしてみてください!

株式会社アルダグラムのTech Blogです。 世界中のノンデスクワーク業界における現場の生産性アップを実現する現場DXサービス「KANNA」を開発しています。 採用情報はこちら: herp.careers/v1/aldagram0508/
Discussion