MCPサーバー入門&社内サービス連携で日常業務を圧縮する
初めに
色々話題になっているMCPですが皆さん使っていますか?
コーディングや開発周りでも既に色々なところで採用事例が紹介されており、かくいう私も採用前後で開発体験や実装スピードに顕著な変化を感じています。
とはいえ、日々の仕事においては幸か不幸か”開発”以外のタスクが多いのも事実であり、特に現職では情報が
- 日々のやりとり => Slack
- 社内の規定や情報 => Kibela
- プロジェクトや一般的な資料 => GoogleDrive
- チケット管理 asana or Jira
のようになっており、ブックマークや拡張機能などを駆使しながらも必要な情報を探すのに一苦労という状況になっていました。
ここで「あ、全部1つのインターフェースからアクセスできれば楽じゃね?」と閃きました。
MCP自体の説明などは公式サイトのドキュメントに譲ることにし、早速作っていきたいと思います
作っていく(成果物)
先に成果物を展開しておきます。
できること
- braveAPIを使用したweb検索
- googleDriveへのファイルアクセスと検索
- kibelaへのアクセス、記事検索やコンテンツ内検索
- 手元のPCのObsidianに対するファイル検索とコンテンツ検索
- Slackワークスペースに対する各種機能
とりあえずざっと必要そうな機能を搭載してみました。asanaやJIRAに対するMCPは などすでに存在しており、GoogleDriveやSlackに対するベーシックな機能もサンプルが存在します。
実装自体も公式ドキュメントを読みつつ、ClineやClaudeに聞きながら進めることで特に詰まることなく実装できるとおもいますがおおまかなフローとサンプルをいくつかみていくことにしましょう。
本リポジトリはTypescriptのSDKを使用しています。
基本形はSDKの提供しているMcpServerかより詳細に設定が可能なServerを使うことになるようです。
const server = new McpServer({...
});
or
const server = new Server(
...
);
今回はMcpServerを使います。
実際に動作をさせるのは今回index.ts(js)になるので、実際に実行する関数をそこに定義&実行までを書きます。
import { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js'
import { StdioServerTransport } from '@modelcontextprotocol/sdk/server/stdio.js'
import { configureServer as ObsidianConfigureServer } from './obsidianMcpServer'
import { configureServer as KibelaConfigureServer } from './kibela'
import { configureServer as SlackConfigureServer } from './slack'
import { configureServer as BraveSearchConfigureServer } from './braveSearch'
import { configureServer as GoogleDriveConfigureServer } from './googleDrive'
async function main() {
const server = new McpServer({
name: 'multi-tool-mcp-server',
version: '1.0.0',
})
ObsidianConfigureServer(server)
KibelaConfigureServer(server)
BraveSearchConfigureServer(server)
SlackConfigureServer(server)
await GoogleDriveConfigureServer(server)
const transport = new StdioServerTransport()
server.connect(transport)
process.stdin.resume()
}
main().catch((error) => {
console.error('Fatal error in main():', error)
process.exit(1)
})
現状の構成では、serverという変数でMcpServerを呼び出し、使いたいツールをまとめたconfigureServerという関数にserverを渡すことで登録しています。
具体の実装サンプルも見ていきましょう。
下記はKibelaのAPIを使用したnote検索の例です。
server.tool(
'kibela-search',
{
query: z.string().describe('Search query for Kibela notes'),
limit: z.number().min(1).max(20).default(5).describe('Maximum number of results to return'),
},
async ({ query, limit }, _extra) => {
try {
console.error(`DEBUG: Searching Kibela for: "${query}", limit: ${limit}`)
const graphqlQuery = `
query SearchNotes($query: String!, $first: Int!) {
search(query: $query, first: $first) {
edges {
node {
__typename
title
contentUpdatedAt
contentSummaryHtml
url
author {
id
realName
}
}
}
}
budget {
cost
}
}
`
const result = await executeKibelaQuery<SearchResultData>(graphqlQuery, {
query,
first: limit,
})
const costUsed = result.data?.budget?.cost || 'unknown'
console.error(`DEBUG: Search query cost: ${costUsed}`)
if (!result.data) {
return {
content: [
{
type: 'text',
text: `Error: No data returned from Kibela API for query "${query}".`,
},
],
}
}
const notes = result.data.search.edges.map((edge) => edge.node)
if (notes.length === 0) {
return {
content: [
{
type: 'text',
text: `No notes found matching "${query}".`,
},
],
}
}
let responseText = `Search results for "${query}" in Kibela:\n\n`
notes.forEach((note, index) => {
responseText += `${index + 1}. ${note.title}\n`
if (note.author?.realName) {
responseText += ` Author: ${note.author.realName}\n`
}
responseText += ` URL: ${note.url}\n`
if (note.contentUpdatedAt) {
responseText += ` Updated: ${new Date(note.contentUpdatedAt).toLocaleString()}\n`
}
if (note.contentSummaryHtml) {
const textContent = note.contentSummaryHtml.replace(/<[^>]*>/g, '')
const cleanedText = textContent.replace(/&[^;]+;/g, ' ').trim()
const preview = cleanedText.substring(0, 100)
responseText += ` Preview: ${preview}${cleanedText.length > 100 ? '...' : ''}\n\n`
} else {
responseText += '\n'
}
})
return {
content: [
{
type: 'text',
text: responseText,
},
],
}
} catch (error) {
return {
content: [
{
type: 'text',
text: `Error searching Kibela: ${error instanceof Error ? error.message : 'Unknown error'}`,
},
],
}
}
},
)
McpServerを使用する場合は、
const server = new McpServer(...)
...
server.tool()
のようにtoolを使用します。toolの第一引数に'kibela-search'とありますが、これがtoolの名前です。この名称がtool名として登録されます。

第二引数にはクエリなどが入っています。
{
query: z.string().describe('Search query for Kibela notes'),
limit: z.number().min(1).max(20).default(5).describe('Maximum number of results to return'),
},
今回zodを使用していますが、必須ではありません。クエリとバリデーションを設定しています。
第三引数には実際の処理を行う関数を記載しています。
async ({ query, limit }, _extra) => {
try {
....
基本形はこれだけです。思っていたよりも普通にAPIを実装している時と変わりませんね。これでLLMが適宜呼び出してくれるのですからとてもありがたいことです。
Claudeで動作するようにする
使用する側のインターフェースにはClaudeを使用しましょう。Cursorでもよいのですが、Cursorの有料プランには自分は入っていないのと、バージョン: 0.47.8 (Universal)だと
args: ['-y', '@おれおれ/ライブラリ']
のように使う方法だと
Connection failed. If the problem persists, please check your internet connection or VPN
(Request ID: xxxxxxxxxxxxxxxxxxxxxxxx)
のように接続できない状態でした。
Claudeで使用するためには、
Claude/claude_desctop_config.jsonという形で設定のjsonファイルを用意し、Claudeに「俺のMCPサーバーがあるぞ」ということを主張せねばなりません。
{
"mcpServers": {
"your-tool-name": {
"command": "/your/node/path/to/node",
"args": [
"/your/path/to/this/repository/product-dir/build/index.js"
],
"env": {
"OBSIDIAN_VAULT_PATH": "/your/path/to/Obsidian/vault/path/dir",
etc...{他のは.env.exampleにキーがあるよ}
}
}
},
}
のようにします。argsに使用しているパスはコンパイルした出力先のファイルを指定しています。
今回の成果物を試してみたい場合は
npm run build
とかでコンパイルしておきましょう。
諸々準備が整ったら、いざClaudeへ。もし起動している状態であれば再起動してください。



このように、ハンマーのマークがでて、押下で今回のツールがリストに出てきていれば成功です!
試しに当たり障りない感じで、toolの動作確認をしてみましょう

はい、ばっちりですね!
他のツールも同様に使用して、
- 〇〇のPJの予定表を教えて
- 直近の▲▲の進行状況を教えて
- XXのファイルってどこにある?
- 今日Slackで自分にメンションされていて返事してないメッセージはある?
みたいな質問でClaude経由で色々探しに行ってくれます
デバッグ方法
デバッグには、公式ドキュメントに推奨のinspectorツールが存在しているので、それを使うのが良さそうです。
npx @modelcontextprotocol/inspector node build/index.js
このように対象のファイルを指定して、inspectorを呼び出します。
呼び出した後、指定のportにアクセスすることでデバッグ用の画面がでてきます。

ここでClaudeなどを介す前に実装したtoolなどが動作するか確認することができます。
左部にあるConnectを押下し、Connectedとなれば接続に成功したことになります。
今回はtoolを主に作成しているので、上部のタブからToolsを選択します。
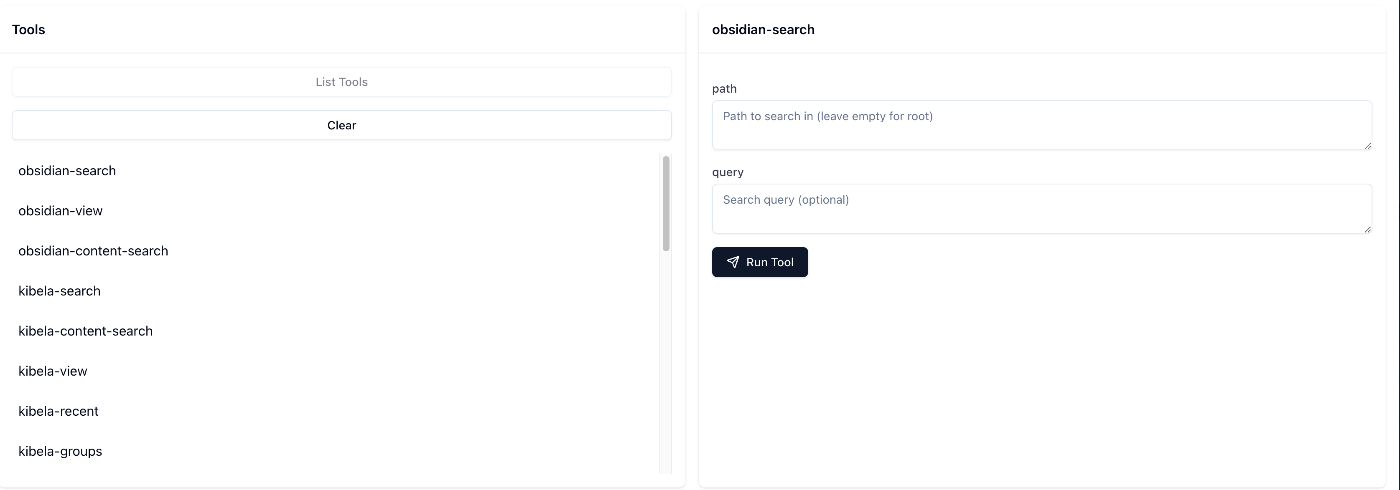
ListToolsを選択することで実装したツールの一覧と、実際に引数などを入れて試すことができます。
このRun Toolの実行を行うことで実装したtoolが動作するかどうか、という部分までをチェックできるので、Claude上で動作しなかった場合に設定ファイルの問題なのか、実装自体に問題があるのかを切り分けることができます。
Claudeでの実行ログを見る
インスペクタツールで実行が確認できても、実際にClaude上で動作させてみると、うまく動かないことがあるかもしれません。そのような場合には、実際に動作させたtoolの中身をみる
という方法と、より詳細に実際にログをみる方法があります。
Claudeの場合
~/Library/Logs/Claude/xxxx.log
という形でlogを確認することができると思います。

まとめ
複数のtoolを呼び出せるようにすることで日常業務や今まで検索でロストしていた時間が短縮され、とてもテンションの上がる環境になりました。
他方でこれを展開する、というようなケースにおいては課題感が残っており、MCPでコールできる権限と操作者の権限を細かく制御したいときにもう少し作り込みが必要そうだったり、雑な依頼だとトークンを無駄に消費してそうな挙動をしたりしていたので
- 適切なpromptを設定する(どのツールを使うべきかのルールを付与する)
- 最適なtoolを実装する (ファイルタイトル検索とファイルコンテンツの読み取りの2ツールで検索をさせるよりも、ファイル内検索のtoolを専用で実装したほうが消費が少ないケースが多そう)
のような工夫が必要に思いました。
引き続き便利なツールになるようにちょこちょこ作り込んでいこうと思います。
Discussion