Flow Q-Learning
本記事では、Flow Q-Learning の概要とその技術的特徴、そして実験結果について解説します。
元論文
Flow Q-Learning
公式のサイト
公式のgithub
概要
Flow Q-Learning (FQL) は、Flow Policy を蒸留して One step Policy を作ることで、複数ステップのノイズ除去を回避し高速な推論を実現しています。また、蒸留モデルを用いた Q 学習で安定性を向上させ、D4RL や OGBench のタスクで既存手法を上回る性能を示しました。
先行研究との違いは
Diffusion Policy:
Diffusion Policyはロボティクスや制御の分野で注目を集める一方で、学習の不安定さや多くのdenoisingステップが必要という課題があります。
そこでFlow Matching を用いることで、学習の安定性が向上します。また、蒸留により 1 step の denoising が可能となり、Diffusion Policy に比べ推論速度が大幅に改善されます。
TODO
Consistency-AC
SRPO
技術のキモは?
FQLの最終的な損失関数は以下の通りです。
ここで、Flow Policy のパラメータを
本手法では、Q学習の安定性を向上させるため、actor critic の更新は蒸留モデル
学習は以下の図のように表されます。
- flow policyで
\mu_{\theta} - distillでone stepのpolicyの
\mu_{\omega} - Q学習で、報酬が高い行動分布のみを学習できる(図の上から下への矢印)

Flow Matching
まず、Flow Matching を用いて Policy を学習します。本論文では Rectified flow に基づき、初期分布

この直線上で、
これにより、モデル
学習済みのモデル
蒸留
Flow Policy は複数のノイズ除去ステップを必要とするため計算時間がかかり、またアクションが定まりにくいため Q 学習時の Q 値が不安定になりやすいという課題があります。これを解決するため、Flow Policy から蒸留するモデル

Offline RL
actor criticの式は次のように書ける
critic lossはQ学習から次のように書ける。
このときのnext action:
actor clossは次のように書ける
Q値を最大にするような行動aを最適化する際、aは蒸留モデル
結果
シミュレータ上で実施した多様な実験により、FQL の有効性が確認されました。

結果として、FQL は BC や Diffusion Policy などと比較して最も高い性能を示しました。図からも、Gaussian Policies や Diffusion Policies に比べ、Flow Policies のほうが全体的に精度が高いことが分かります。また、Offline RL 手法である BRAC と Flow Policy を組み合わせた FBRAC よりも、FQL のほうが精度が向上しており、蒸留手法が大きな役割を果たしていると考えられます。
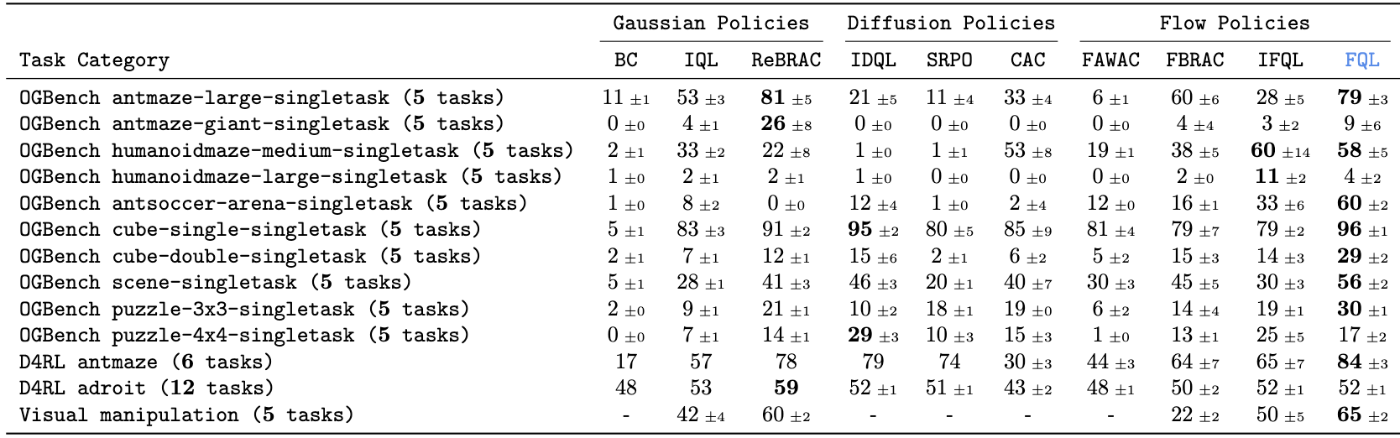
※ 著者によると、蒸留損失の係数
まとめ
Flow Q-Learning は、Flow Matching と蒸留技術を組み合わせた新しい手法であり、Offline RL の学習不安定性を大幅に改善しました。さらに、Diffusion Policy と比べ、Flow Matching はシンプルな数式で表現できるにも関わらず、十分な精度を確保しており、今後ますます注目されると考えられます。
Discussion